
本文的首要關注點是RAG的概念和理論。接下來,我們將展示如何利用LangChain、OpenAI語言模型和Weaviate向量資料庫來實作一個簡單的RAG編排系統
檢索增強生成(RAG)這個概念是指透過外部知識來源來為 LLM 提供附加的資訊。這讓 LLM 可以產生更準確和更符合上下文的答案,同時減少幻覺。
在進行內容重寫時,需要將原文改寫為中文,而無需出現原句
當前最佳的LLM 都是使用大量資料訓練出來的,因此其神經網路權重中儲存了大量一般性知識(參數記憶)。但是,如果在透過prompt 讓LLM 產生結果時需要其訓練資料之外的知識(例如新資訊、專有資料或特定領域的資訊),就可能出現事實不準確的在進行內容重寫時,需要將原文改寫為中文,而無需出現原句(幻覺),如下截圖所示:
#因此,重要的是將LLM的一般知識與附加上下文結合起來,以便產生更準確且更符合上下文的結果,並減少幻覺
解決方案
傳統上,我們可以透過微調模型來讓神經網路適應特定領域或專有資訊。儘管這種技術是有效的,但它需要大量的計算資源,成本高昂,並且需要技術專家的支持,因此很難快速適應不斷變化的信息
2020 年, Lewis et al. 的論文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》提出了一種更靈活的技術:檢索增強生成(RAG)。在這篇論文中,研究者將生成模型與一個檢索模組組合到了一起;這個檢索模組可以用一個更容易更新的外部知識來源提供附加資訊。
用大白話來講:RAG 之於 LLM 就像開卷考試之於人類。在開卷考試時,學生可以攜帶教材和筆記等參考資料,他們可以從中找到用於答題的相關資訊。開卷考試背後的想法是:這堂考試考核的重點是學生的推理能力,而不是記憶特定資訊的能力。
同樣,事實上的知識與LLM 推理能力是不同的,並且可以儲存在易於存取和更新的外部知識來源中
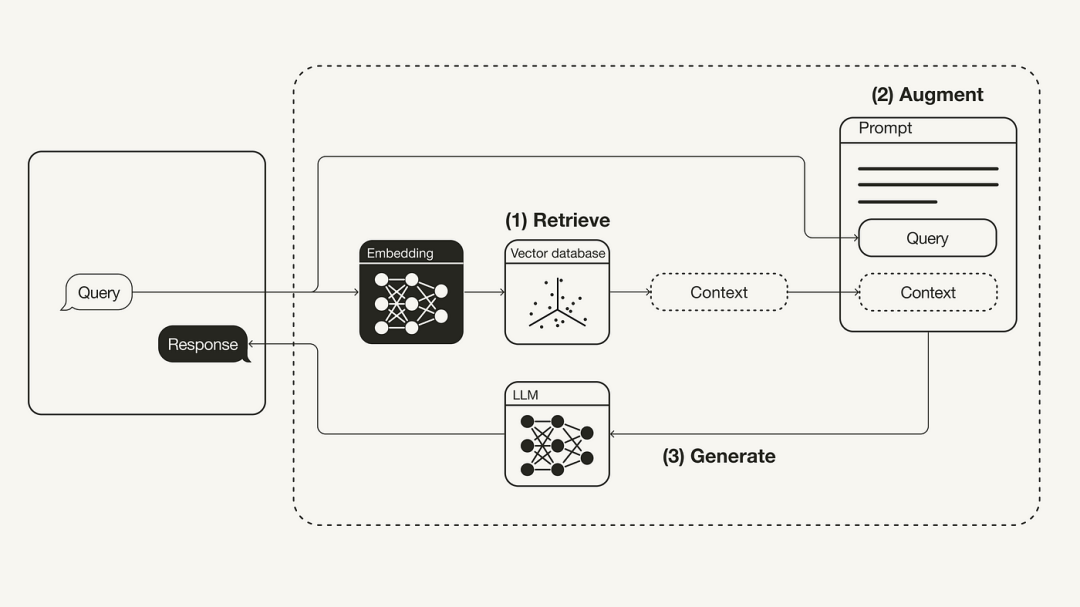
以下圖表展示了最基本的RAG工作流程:
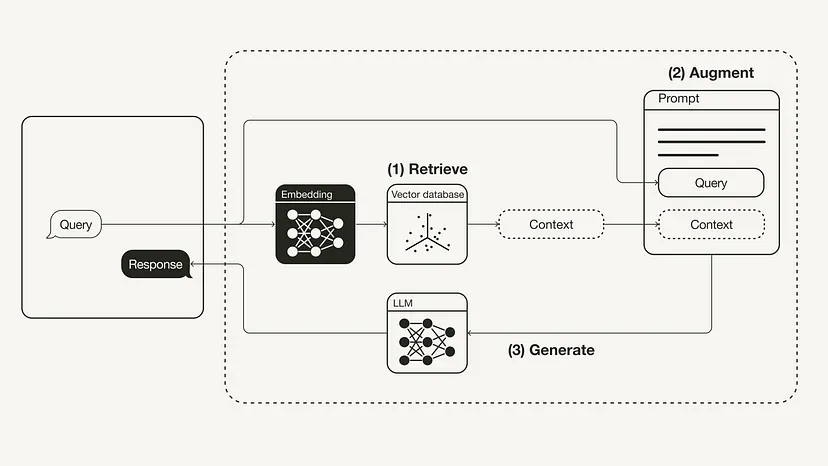
重新編寫的內容:重建檢索增強生成(RAG)的工作流程
以下將介紹如何透過Python 實現RAG 工作流程,這會用到OpenAI LLM以及Weaviate 向量資料庫和一個OpenAI 嵌入模型。 LangChain 的角色是編排。
請重新表達:必要的先決條件
#請確保你已安裝所需的Python 軟體包:
#!pip install langchain openai weaviate-client
另外,在根目錄下用一個.env 檔案定義相關環境變數。你需要一個 OpenAI 帳戶來取得 OpenAI API Key,然後在 API keys(https://platform.openai.com/account/api-keys )「建立新的金鑰」。
OPENAI_API_KEY="<your_openai_api_key>"</your_openai_api_key>
然後,執行以下命令來載入相關環境變數。
import dotenvdotenv.load_dotenv()
準備工作
#在準備階段,你需要準備一個作為外部知識來源的向量資料庫,用於保存所有的附加資訊。這個向量資料庫的建構包含以下步驟:
重寫後的內容:首先,我們需要收集和載入資料。舉個例子,如果我們想要使用拜登總統2022年的國情咨文作為附加上下文,LangChain的GitHub庫提供了該文件的原始文本文件。為了載入這些數據,我們可以利用LangChain內建的多種文件載入工具。一個文檔(Document)由文字和元資料構成的字典。要載入文本,可以使用LangChain的TextLoader工具
原始文件地址:https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/ state_of_the_union.txt
import requestsfrom langchain.document_loaders import TextLoaderurl = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"res = requests.get(url)with open("state_of_the_union.txt", "w") as f:f.write(res.text)loader = TextLoader('./state_of_the_union.txt')documents = loader.load()接下來,將文件分割。因為文檔的原始狀態很長,無法放入 LLM 的上下文窗口,所以就需要將其拆分成更小的文字區塊。 LangChain 也有很多內建的分割工具。對於這個簡單範例,我們可以使用 CharacterTextSplitter,其 chunk_size 設為 500,chunk_overlap 設為 50,這樣可以保持文字區塊之間的文字連續性。
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)
最後,對文字區塊進行嵌入操作並儲存。為了讓語意搜尋能夠跨文字區塊執行,就需要為每個文字區塊產生向量嵌入,並將它們與它們的嵌入保存在一起。為了產生向量嵌入,可以使用 OpenAI 嵌入模型;至於儲存,則可使用 Weaviate 向量資料庫。透過呼叫 .from_documents (),可以自動將文字區塊填入向量資料庫。
from langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Weaviateimport weaviatefrom weaviate.embedded import EmbeddedOptionsclient = weaviate.Client(embedded_options = EmbeddedOptions())vectorstore = Weaviate.from_documents(client = client,documents = chunks,embedding = OpenAIEmbeddings(),by_text = False)
步驟1:檢索
#填入向量資料庫後,我們可以將其定義為檢索器元件,該元件可以根據使用者查詢和嵌入區塊之間的語義相似性來取得附加上下文
retriever = vectorstore.as_retriever()
步驟2:增強
from langchain.prompts import ChatPromptTemplatetemplate = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.Question: {question} Context: {context} Answer:"""prompt = ChatPromptTemplate.from_template(template)print(prompt)接下來,為了使用附加上下文增強prompt,需要準備一個prompt 模板。如下所示,使用 prompt 模板可以輕鬆地自訂 prompt。
步驟3:產生
#最終,我們可以為這個RAG 流程建立一個思維鏈,將檢索器、prompt 模板和LLM 連結在一起。一旦定義完成RAG 鏈,就可以呼叫它
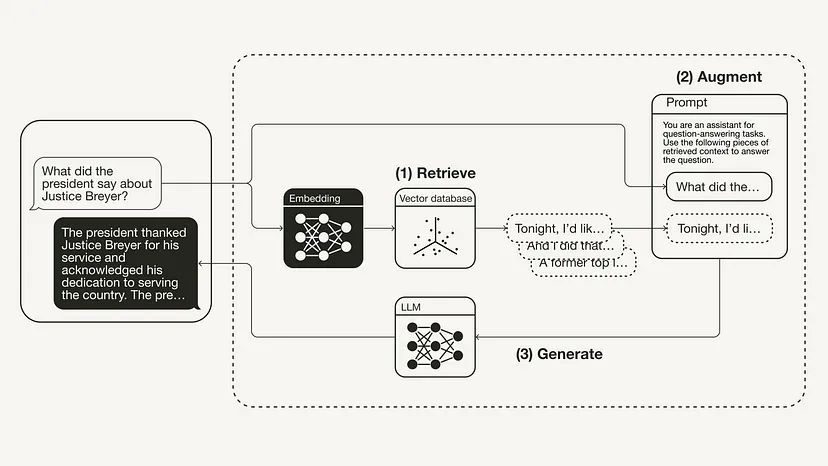
from langchain.chat_models import ChatOpenAIfrom langchain.schema.runnable import RunnablePassthroughfrom langchain.schema.output_parser import StrOutputParserllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)rag_chain = ({"context": retriever,"question": RunnablePassthrough()} | prompt | llm| StrOutputParser() )query = "What did the president say about Justice Breyer"rag_chain.invoke(query)"The president thanked Justice Breyer for his service and acknowledged his dedication to serving the country. The president also mentioned that he nominated Judge Ketanji Brown Jackson as a successor to continue Justice Breyer's legacy of excellence."下圖展示了這個具體範例的RAG 流程:
本文介紹了RAG 的概念,最早來自2020 年的論文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》 。在介紹了 RAG 背後的理論(包括動機和解決方案)之後,本文介紹如何用 Python 實現它。本文展示如何使用 OpenAI LLM 加上 Weaviate 向量資料庫和 OpenAI 嵌入模型來實作一個 RAG 工作流程。其中 LangChain 的作用是編排。
以上是實作Python程式碼以增強大型模型的檢索功能的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















