
需要重寫的內容是:了解監督學習、無監督學習和半監督學習的特徵,以及它們在機器學習專案中的應用方式

在討論人工智慧技術時,監督學習往往是最受關注的一種方法,因為它通常是創建人工智慧模型的最後一步,可以用於圖像識別、更好的預測、產品推薦和潛在客戶評分等方面
相比之下,無監督學習往往在人工智慧開發生命週期的早期在幕後工作:它通常被用來為監督學習的魔力展開奠定基礎,就像讓經理大放異彩的繁重工作一樣。如後面所解釋的,這兩種機器學習模式都可以有效地應用於商業問題。
在技術層面上,監督學習與無監督學習之間的差異在於用於創建演算法的原始資料是預先標記(監督學習)還是未預先標記(無監督學習)。
我們開始吧
在監督學習中,資料科學家會為演算法提供標記過的訓練數據,並定義他們希望演算法評估相關性的變數
演算法的輸入資料和輸出變數都是透過訓練資料來指定的。舉個例子,如果您想要使用監督學習的方法來訓練演算法判斷一張圖片中是否有貓,您可以為每一張在訓練資料中使用的圖片創建一個標籤,來指示這個圖像是否含有貓
正如我們在監督學習的定義中所解釋的那樣:「[A]電腦演算法是在為特定輸出標記的輸入資料上訓練的。該模型經過訓練,直到它能夠偵測到輸入資料和輸出標籤之間的基本模式和關係,使其能夠在呈現前所未見的資料時產生準確的標記結果。監督演算法的常見類型包括分類、決策樹、迴歸和預測建模,您可以在 Arcitura Education 的機器學習教程中了解這些內容。
監督式機器學習技術用於各種業務應用程序,包括以下內容:
#詐欺偵測。
垃圾郵件過濾。
# #什麼是無監督學習?
######在無監督學習中,有一種適用於此方法的演算法(例如K-means聚類),它是在未標記的資料上進行訓練的。該演算法會掃描資料集,尋找其中的任何有意義的關聯。換句話說,無監督學習會確定資料中的模式和相似性,而不是將其與某些外部度量相關聯## ##########當您不知道自己在尋找什麼時,這種方法很有用,而當您知道時,這種方法就不那麼有用了。如果您向無監督演算法展示了數千或數百萬張圖片,它可能會將圖片的子集歸類為人類識別為貓科動物的圖像。相比之下,在貓與犬科動物的標記數據上訓練的監督演算法能夠高度自信地識別貓的圖像。但這種方法有一個權衡:如果監督學習項目需要數百萬張標記圖像來開發模型,那麼機器生成的預測需要大量的人力。########### #有一個中間地帶:半監督學習。############什麼是半監督學習?############半監督學習是將無監督學習和監督學習結合的一種有效方法。它透過一定的工作流程,使用無監督學習演算法自動產生標籤,然後將這些標籤輸入到監督學習演算法中。在該方法中,人類手動標記一些圖像,而無監督學習演算法則猜測其他圖像的標籤,最終將所有的標籤和圖像輸入到監督學習演算法中,從而創建AI模型############半監督學習的一個好處是可以降低在機器學習中使用大規模資料集的成本。根據企業資料目錄平台Alation的共同創辦人兼首席創新長Aaron Kalb的說法,如果能夠讓人類對數百萬個樣本中的0.01%進行標記,電腦就可以利用這些標籤來顯著提高其預測準確度#######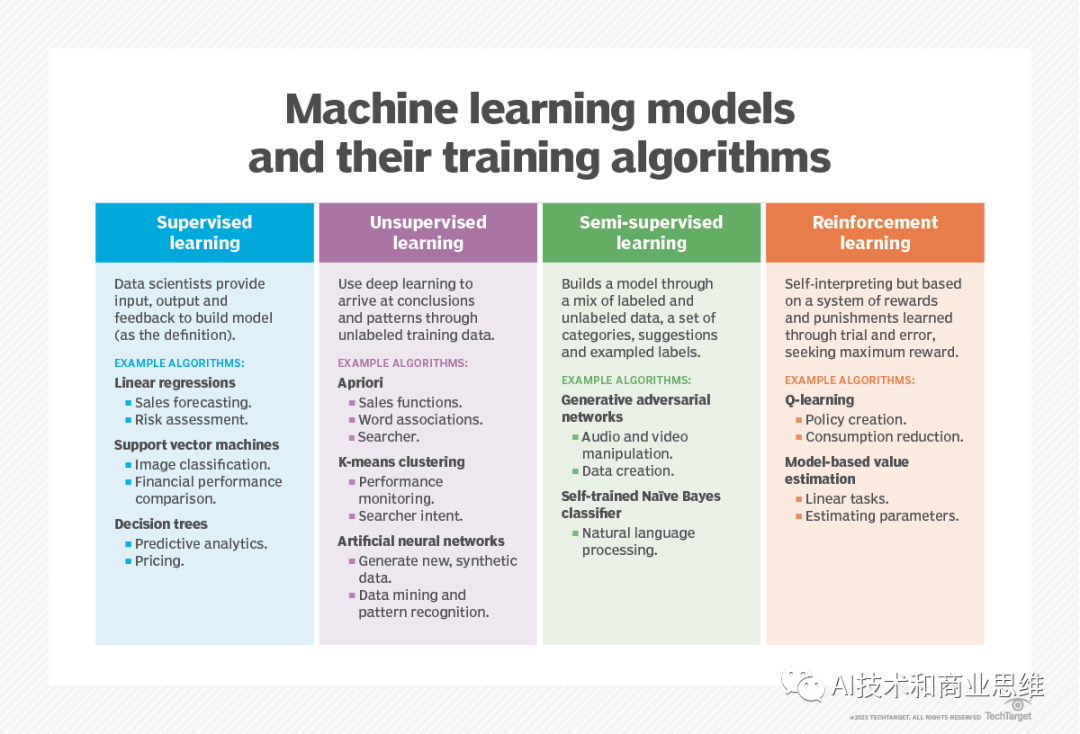
另一種機器學習方法是強化學習。強化學習通常用於教導機器完成一系列步驟,不同於監督學習和無監督學習。資料科學家對演算法進行程式設計來執行任務,在決定如何完成任務時給予正面或負面的線索或強化。程式設計師為獎勵設定規則,但讓演算法自己決定需要採取哪些步驟來最大化獎勵,從而完成任務。
LinkedIn機器學習經理Shivani Rao表示,採用監督或無監督機器學習方法的最佳實踐通常取決於環境,你可以對資料和應用程式做出的假設。
Rao說,使用監督學習與無監督機器學習演算法的選擇也會隨著時間的推移而改變。在模型建構過程的早期階段,資料通常是未標記的,而標記的資料可以在建模的後期階段出現。
舉個例子,對於預測LinkedIn成員是否會觀看課程影片的問題,第一個模型採用無監督技術。在提供這些建議後,記錄某人是否點擊建議的指標將提供新的數據來產生標籤
#LinkedIn 也使用這種技術來標記學生可能想要獲得的技能的線上課程。人工標記者,例如作者、出版商或學生,可以提供課程教授的精確和準確的技能列表,但他們不可能提供此類技能的詳盡列表。因此,可以認為這些數據標記不完整。這些類型的問題可以使用半監督技術來幫助建立一組更詳盡的標記。
數據科學和高級分析專家、諮詢公司科爾尼(Kearney)的合夥人巴拉特·托塔(Bharath Thota)表示,他的團隊選擇使用監督學習或無監督學習時,也常考慮實際因素。
Thota說:「當有可用的標記資料時,我們選擇監督學習作為應用程序,目標是預測或分類未來的觀察結果。當沒有可用的標記資料時,我們使用無監督學習,目標是透過從資料中識別模式或片段來製定策略。」
Kalb說,Alation資料科學家在內部將無監督學習用於各種應用程式.例如,他們開發了一種人機協作流程,用於將晦澀難懂的資料物件名稱翻譯成人類語言,例如,將「na_gr_rvnu_ps」翻譯成「北美專業服務總收入」。在這種情況下,機器猜測,人類確認,機器學習
「你可以把它想像成一個迭代循環中的半監督學習,創造一個提高準確性的良性循環,」Kalb說。
在高層次上,監督學習技術傾向於關注線性迴歸(將模型擬合到一群組資料點以進行預測)或分類問題(影像是否有貓?
非監督學習技術通常採用多種方式對原始資料集進行切片和切塊,以補充監督學習的工作,這些方式包括:
資料聚類。具有相似特徵的資料點組合在一起,以幫助更有效地理解和探索資料。例如,公司可能會使用資料聚類方法根據客戶的人口統計、興趣、購買行為和其他因素將客戶細分為幾組。
##降維。資料集中的每個變數都被視為一個單獨的維度。但是,許多模型透過分析變數之間的特定關係來更好地工作。降維的一個簡單例子是將利潤用作單一維度,它表示收入減去支出-兩個獨立的維度。但是,可以使用主成分分析、自動編碼器、將文字轉換為向量的演算法或T 分佈隨機鄰域嵌入等演算法來產生更複雜的新變數類型。
降維可以幫助減少過度擬合的問題,在這種問題中,模型適用於小數據集,但不能很好地泛化到新數據。該技術還使公司能夠以2D 或3D形式可視化人類可以輕鬆理解的高維度資料。
異常或異常值檢測。無監督學習可以幫助識別常規資料分佈之外的資料點。識別和刪除異常作為資料準備步驟可能會提高機器學習模型的效能。#
遷移學習。 這些演算法利用在相關但不同的任務上訓練的模型。例如,遷移學習技術可以輕鬆微調在維基百科文章上訓練的分類器,以使用正確的主題標記任意類型的新文字。 LinkedIn的Rao表示,這是解決沒有標籤的數據問題的最有效,最快捷的方法之一。
基於圖形的演算法。 Rao說,這些技術試圖建立一個圖表來捕捉數據點之間的關係。例如,如果每個數據點表示具有技能的 LinkedIn 成員,則可以使用圖形來表示成員,其中邊緣表示成員之間的技能重疊。圖形演算法還可以幫助將標籤從已知資料點轉移到未知但密切相關的資料點。無監督學習也可用於在不同類型的實體(來源和目標)之間建立圖形。邊緣越強,源節點與目標節點的親和力越高。例如,LinkedIn 使用它們將成員與基於技能的課程相匹配。
以上是監督學習與無監督學習:專家定義差距的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















