

为了促进分子特性预测,在药物发现领域,学习有效的分子特征表征非常重要。最近,人们通过采用自监督学习技术,预先训练图神经网络(GNN)来克服数据稀缺的挑战。然而,目前基于自监督学习的方法存在两个主要问题:缺乏明确的自监督学习策略和 GNN 的能力有限
近日,来自清华大学、西湖大学和之江实验室的研究团队,提出了知识引导的图 Transformer 预训练(Knowledge-guided Pre-training of Graph Transformer,KPGT),这是一种自监督学习框架,通过显著增强的分子表征学习提供改进的、可泛化和稳健的分子特性预测。KPGT 框架集成了专为分子图设计的图 Transformer 和知识引导的预训练策略,以充分捕获分子的结构和语义知识。
通过对 63 个数据集进行广泛的计算测试,KPGT 在预测各个领域的分子特性方面表现出了卓越的性能。此外,通过鉴定两种抗肿瘤靶点的潜在抑制剂验证了 KPGT 在药物发现中的实际适用性。总体而言,KPGT 可以为推进 AI 辅助药物发现过程提供强大且有用的工具。
该研究以《A knowledge-guided pre-training framework for improving molecular representation learning》为题,于 2023 年 11 月 21 日发布在《Nature Communications》上。

通过实验确定分子特性需要大量时间和资源,鉴定具有所需特性的分子是药物发现领域最重大的挑战之一。近年来,基于人工智能的方法在预测分子特性方面发挥着越来越重要的作用。基于人工智能的分子特性预测方法的主要挑战之一是分子的表征
近年来,基于深度学习的方法的出现成为预测分子特性的潜在有用工具,主要是因为它们具有从简单输入数据中自动提取有效特征的卓越能力。值得注意的是,各种神经网络架构,包括循环神经网络(RNN)、卷积神经网络(CNN)和图神经网络(GNN)擅长对各种格式的分子数据进行建模,从简化的分子输入行输入系统(SMILES)到分子图像和分子图。然而,标记分子的有限可用性和化学空间的广阔限制了它们的预测性能,特别是在处理分布外数据样本时。
随着自监督学习方法在自然语言处理和计算机视觉领域取得的显著成就,这些技术已被应用于预训练 GNN 并改进分子的表征学习,从而在下游分子性质预测任务中取得了实质性的进展
研究人员假设将定量描述分子特征的额外知识引入自监督学习框架可以有效应对这些挑战。分子有许多定量特征,例如分子描述符和指纹,可以通过当前建立的计算工具轻松获得。整合这些额外的知识可以将丰富的分子语义信息引入自监督学习中,从而大大增强语义丰富的分子表征的获取。
通常,现有的自监督学习方法依赖于GNN作为核心模型。然而,GNN的模型容量有限。此外,GNN可能很难捕捉原子之间的远程交互。而基于Transformer的模型已经成为一种改变游戏规则的模型。它的特点是参数数量不断增加,并且能够捕捉到长程相互作用,为全面模拟分子的结构特征提供了有希望的途径
在这项研究中,研究人员引入了一种名为 KPGT 的自监督学习框架,旨在加强分子表征学习,从而推动下游的分子属性预测任务。KPGT 框架由两个主要组件组成:一个被称为 Line Graph Transformer(LiGhT)的主干模型和一个知识引导的预训练策略。KPGT 框架结合了高容量的 LiGhT 模型,该模型专门用于准确建模分子图结构,并利用知识引导的预训练策略来捕捉分子结构和语义知识
研究团队使用ChEMBL29数据集中的约200万个分子,通过知识引导的预训练策略对LiGhT进行了预训练
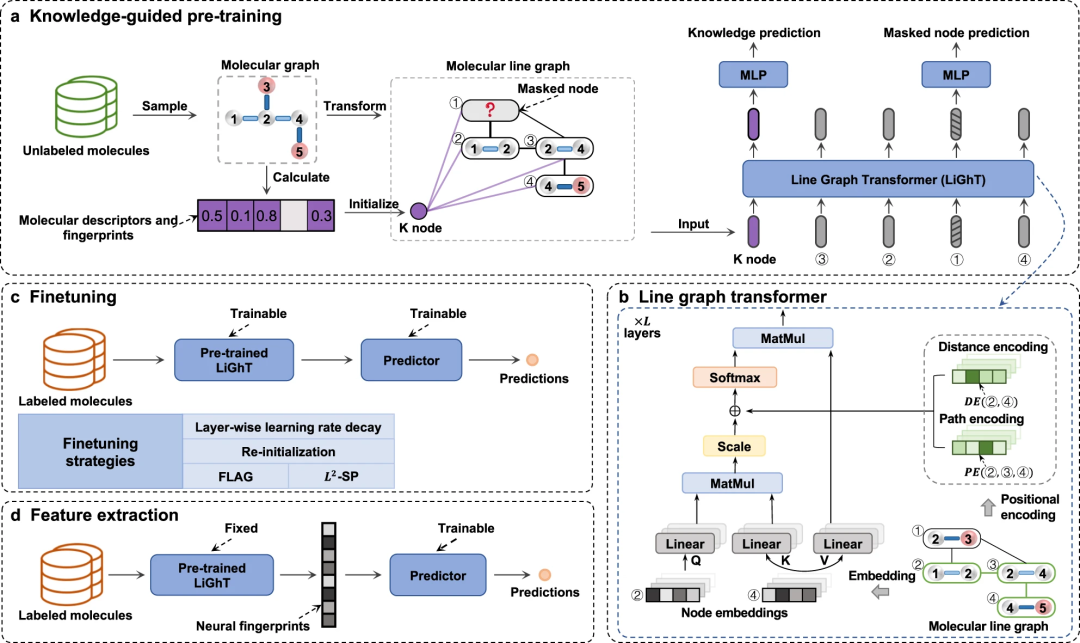
重写内容为:图表:KPGT 概述。(资料来源:论文)
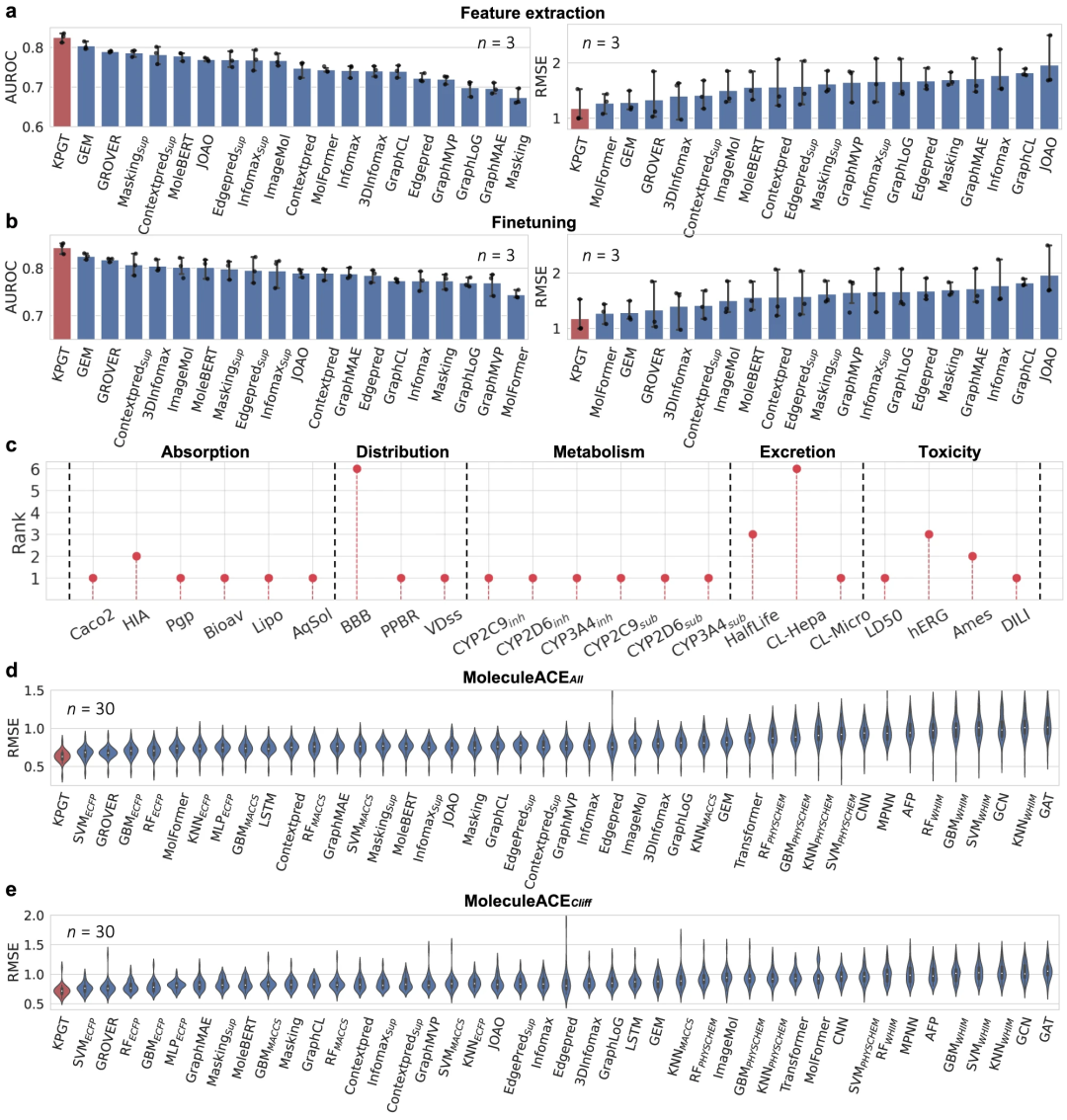
KPGT 在分子性质预测方面优于基线方法。与几种基线方法相比,KPGT 在 63 个数据集上取得了很大的进步。
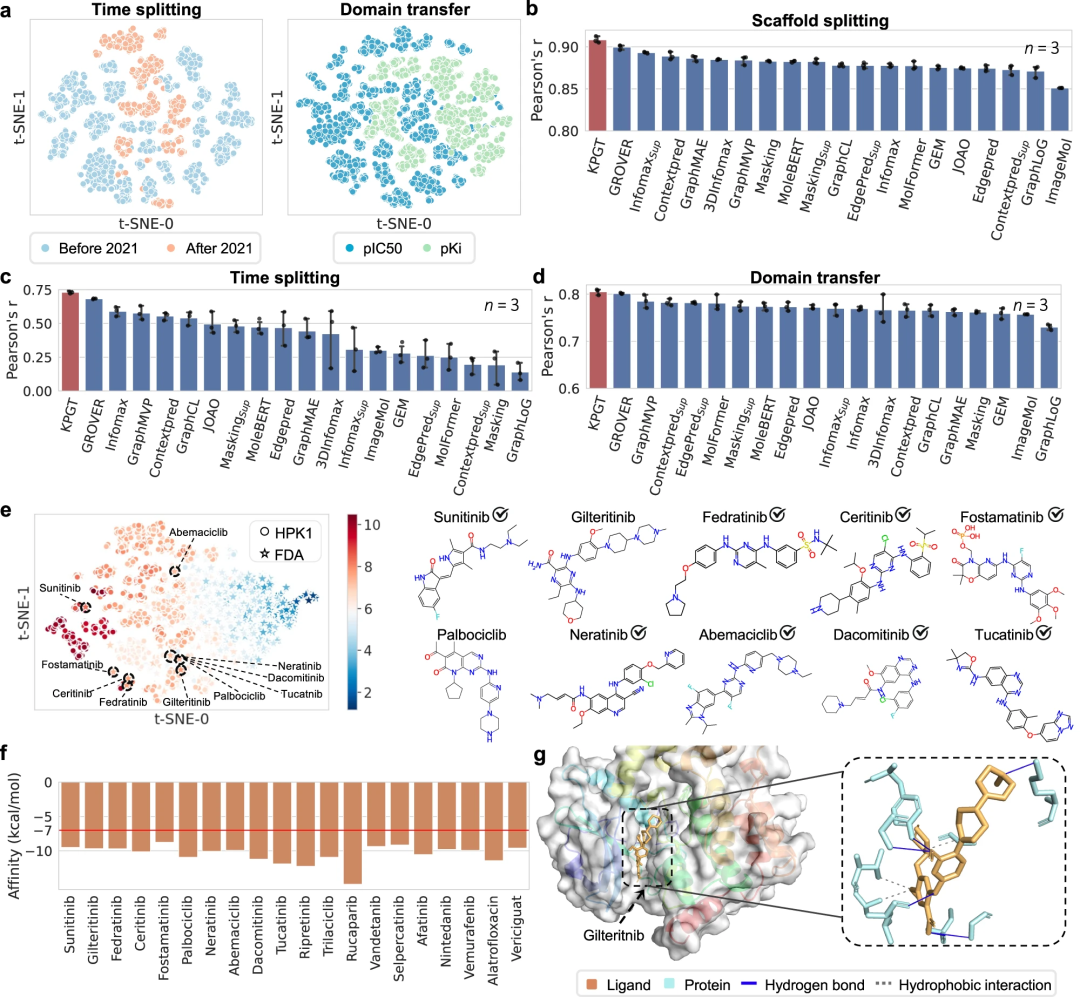
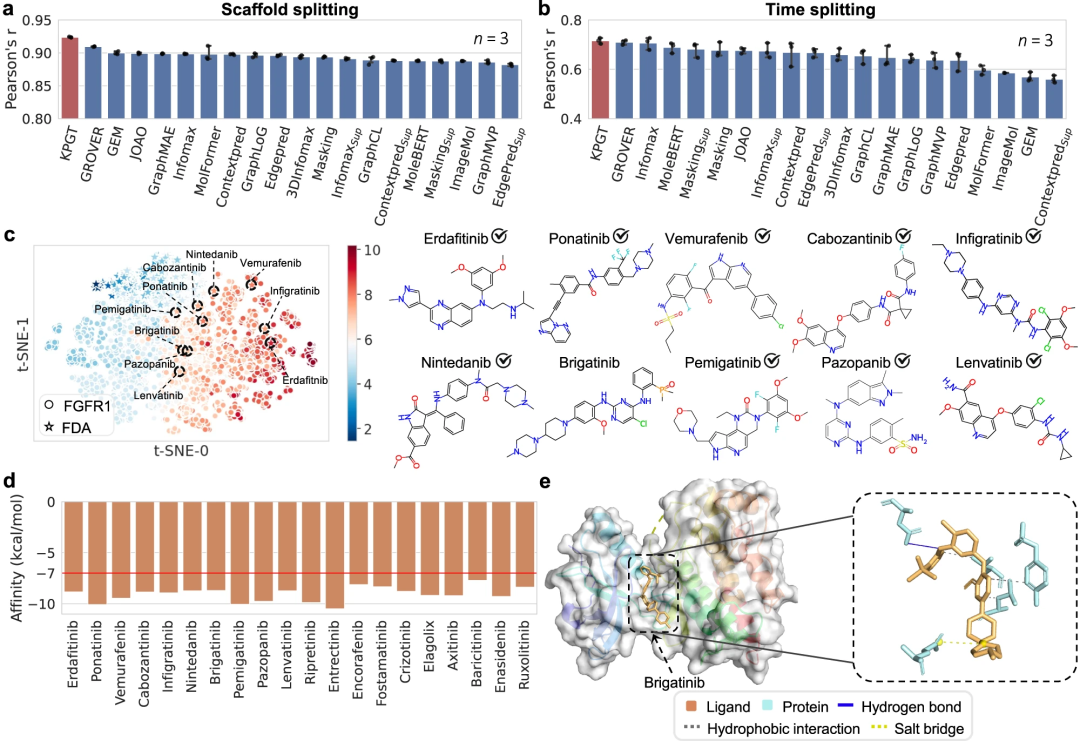
此外,通过成功利用 KPGT 识别造血祖细胞激酶 1 (HPK1) 和成纤维细胞生长因子受体 (FGFR1) 两个抗肿瘤靶点的潜在抑制剂,展示了 KPGT 的实际应用性。
尽管 KPGT 在有效分子特性预测方面具有优势,但仍然存在一些局限性。
总的来说,KPGT 为有效的分子表征学习提供了强大的自监督学习框架,从而推动了人工智能辅助药物发现领域的发展。
论文链接:https://www.nature.com/articles/s41467-023-43214-1
以上是清華團隊提出知識引導的圖 Transformer 預訓練架構:提升分子特性學習的方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

![PHP實戰開發極速入門: PHP快速創建[小型商業論壇]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)





















