
继火爆出圈的Grounded SAM之后,IDEA研究院团队携重磅新作归来:全新视觉提示(Visual Prompt)模型T-Rex,以图识图,开箱即用, 开启开集检测新天地!
开启开集检测新天地!
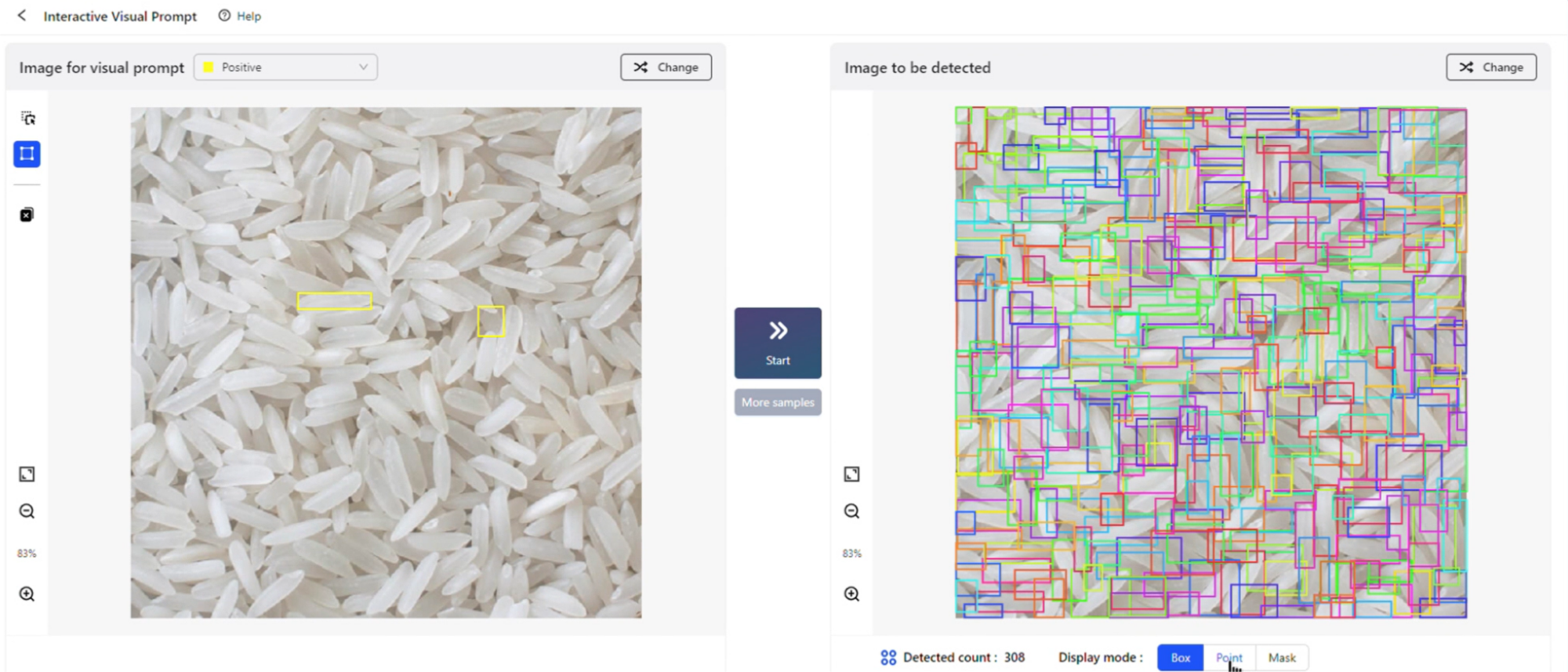
拉框、检测、完成!在刚刚结束的2023IDEA大会上,IDEA研究院创院理事长、美国国家工程院外籍院士沈向洋展示了基于视觉提示的目标检测新体验,并发布了全新视觉提示模型T-Rex的模型实验室(playground), Interactive Visual Prompt(iVP),掀起现场一波试玩小高潮。

在iVP上,用户可以亲自解锁“一图胜千言”的prompting体验:在图片上标记感兴趣的对象,向模型提供视觉示例,模型随即检测出目标图片中与之相似的所有实例。整套流程交互便捷,只需几步操作就可轻松完成。
IDEA研究院4月份发布的Grounded SAM (Grounding DINO SAM) 曾在Github上火爆出圈,至今已狂揽11K星。有别于只支持文字提示的Grounded SAM,此次发布的T-Rex模型提供着重打造强交互的视觉提示功能。
T-Rex具备极强的开箱即用特性,无需重新训练或微调,即可检测模型在训练阶段从未见过的物体。该模型不仅可应用于包括计数在内的所有检测类任务,还为智能交互标注场景提供新的解决方案。
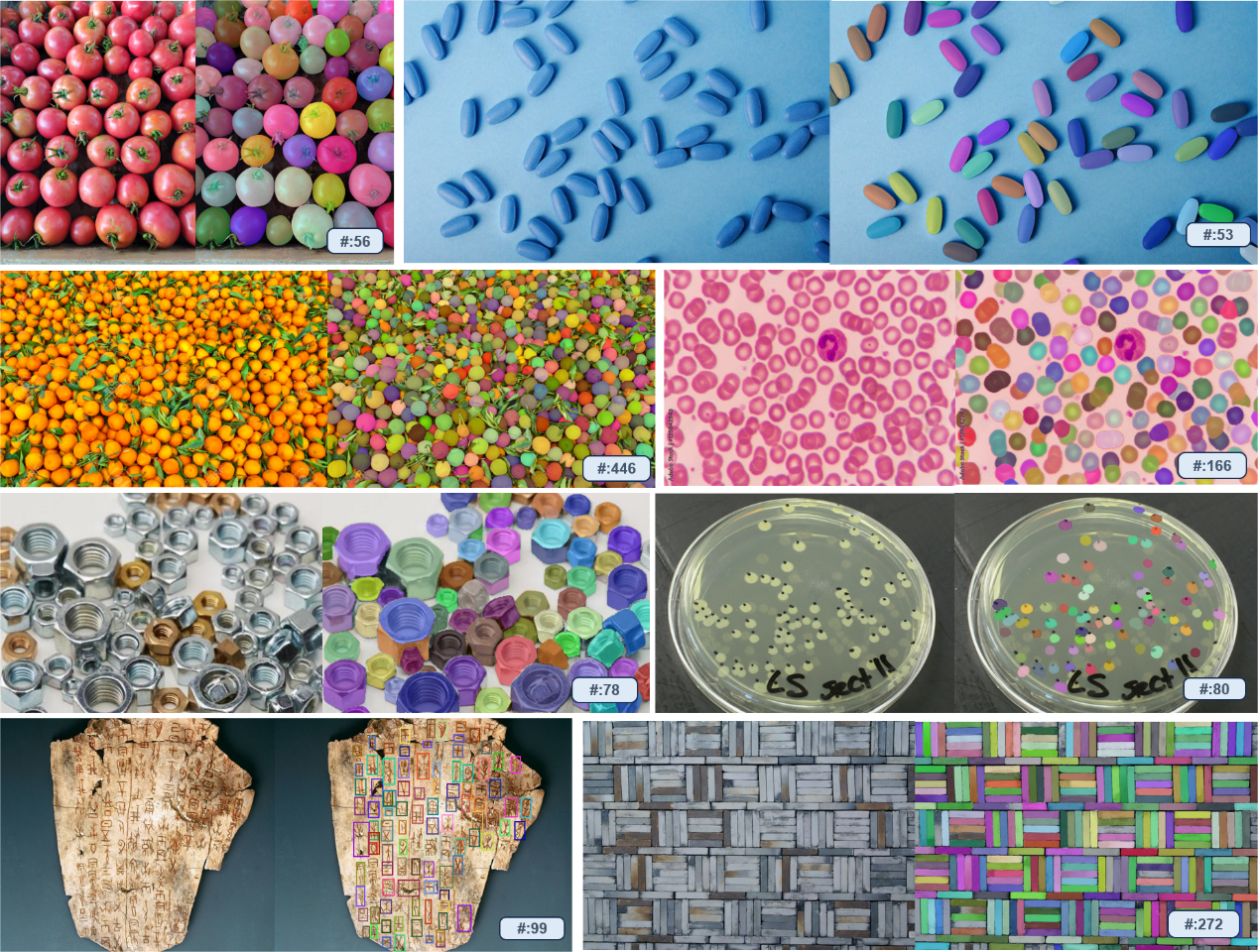
团队透露,研发视觉提示技术是源自对真实场景中痛点的观察。有合作方希望利用视觉模型对卡车上的货物数量进行统计,然而,仅通过文字提示,模型无法单独识别出每一个货物。其原因是工业场景中的物体在日常生活中较为罕见,难以用语言描述。在此情况下,视觉提示显然是更高效的方法。与此同时,直观的视觉反馈与强交互性,也有助于提升检测的效率与精准度。
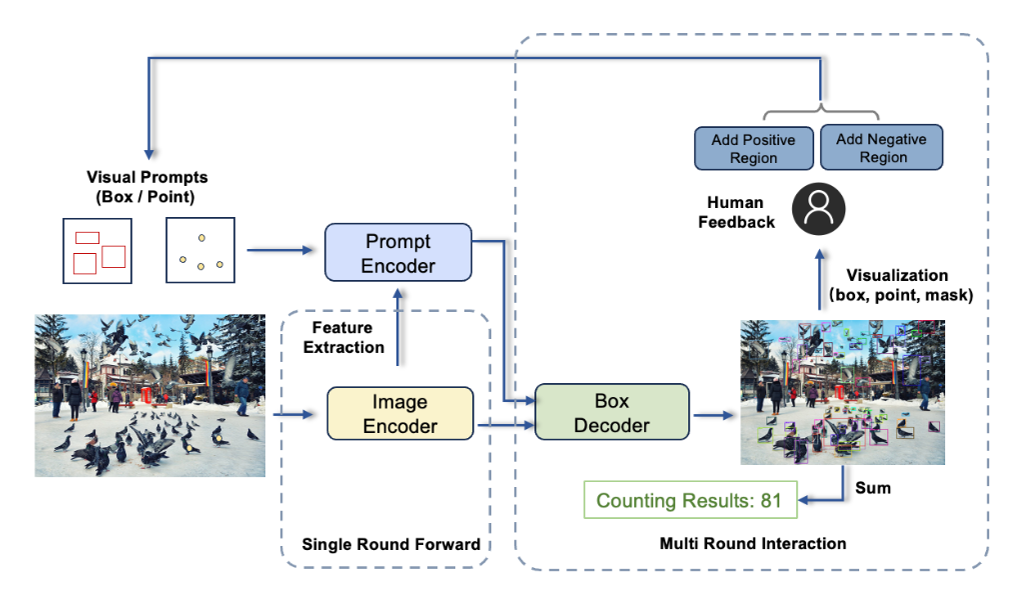
基于对实际使用需求的洞察,团队将T-Rex设计成可接受多个视觉提示的模型,且具备跨图提示能力。除了最基本的单轮提示模式,目前模型还支持以下三种进阶模式.

在同期发布的技术报告中,团队总结了T-Rex模型的四个主要特点:
研究团队指出,在目标检测场景中,视觉提示的加入能够补足文本提示的部分缺陷。未来,两者的结合将进一步释放CV技术在更多垂直领域的落地潜能。
有关T-Rex模型的技术细节,请参考同期发布的技术报告。
iVP模型实验室:https://deepdataspace.com/playground/ivp
Github連結:trex-counting.github.io
這項工作來自於IDEA研究院電腦視覺與機器人研究中心。該團隊先前開源的目標檢測模型DINO是第一個在COCO目標檢測排行榜上取得第一名的DETR類模型;在Github上非常受歡迎的零樣本檢測器Grounding DINO和能夠檢測和分割任何物體的Grounded SAM,同樣是團隊的作品
以上是新技術推出,IDEA研究院發表T-Rex模型,讓使用者能夠直接在影像上選擇「Prompt」提示的詳細內容。更多資訊請關注PHP中文網其他相關文章!


![PHP實戰開發極速入門: PHP快速創建[小型商業論壇]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)





















