

Sparse4D v3來了!推進端到端3D偵測與追蹤

新標題:Sparse4D v3:推進端到端的3D偵測與追蹤技術
論文連結:https://arxiv.org/pdf/2311.11722.pdf
需要重寫的內容為:程式碼連結:https://github.com/linxuewu/Sparse4D
重新寫的內容:作者所屬單位為地平線公司

論文想法:
在自動駕駛感知系統中,3D偵測與追蹤是兩項基本任務。本文基於 Sparse4D 框架更深入地研究了這個領域。本文引入了兩個輔助訓練任務(時序實例去噪-Temporal Instance Denoising和質量估計-Quality Estimation),並提出解耦注意力(decoupled attention)來進行結構改進,從而顯著提高檢測性能。此外,本文使用簡單的方法將偵測器擴展到追蹤器,該方法在推理過程中分配實例 ID,進一步突顯了 query-based 演算法的優勢。在 nuScenes 基準上進行的大量實驗驗證了所提出的改進的有效性。以ResNet50為骨幹,mAP、NDS和AMOTA分別增加了3.0%、2.2%和7.6%,分別達到46.9%、56.1%和49.0%。本文最好的模型在nuScenes 測試集上實現了71.9% NDS 和67.7% AMOTA
主要貢獻:
Sparse4D-v3 是一個強大的3D 感知框架,它提出了三種有效的策略:時序實例去噪、品質估計和解耦注意力
本文將Sparse4D 擴展為端對端追蹤模型。
本文展示了 nuScenes 改進的有效性,在偵測和追蹤任務中實現了最先進的效能。
網路設計:
首先,觀察到與稠密演算法相比,稀疏演算法在收斂方面面臨更大的挑戰,從而影響了最終性能。這個問題已經在2D檢測領域中得到了充分研究[17,48,53],主要原因是稀疏演算法使用了一對一的正樣本匹配。這種匹配方式在訓練初期不穩定,而且與一對多匹配相比,正樣本數量有限,從而降低了解碼器訓練的效率。此外,Sparse4D使用稀疏特徵採樣而不是全域交叉注意力,由於正樣本稀缺,這進一步阻礙了編碼器的收斂。在Sparse4Dv2中,引入了密集深度監督來部分緩解影像編碼器面臨的這些收斂問題。本文的主要目標是透過關註解碼器訓練的穩定性來增強模型效能。本文將去噪任務作為輔助監督,並將去噪技術從2D單幀檢測擴展到3D時序檢測。這不僅保證了穩定的正樣本匹配,而且顯著增加了正樣本的數量。此外,本文也引入了品質評估任務作為輔助監督。這使得輸出的置信度分數更加合理,並提高了檢測結果排名的準確性,從而獲得更高的評估指標。此外,本文改進了Sparse4D中實例自註意力和時序交叉注意力模組的結構,引入了一種解耦注意力機制,旨在減少注意力權重計算過程中的特徵幹擾。透過將錨點嵌入和實例特徵作為注意力計算的輸入,可以減少注意力權重中存在異常值的實例。這樣可以更準確地反映目標特徵之間的相互關聯,從而實現正確的特徵聚合。本文使用連接而不是注意力機制來顯著減少這種錯誤。這種增強方法與條件DETR有相似之處,但關鍵差異在於本文強調查詢之間的注意力,而條件DETR則專注於查詢和影像特徵之間的交叉注意力。此外,本文也涉及獨特的編碼方法
為了提高感知系統的端到端能力,本文研究了將3D多目標追蹤任務整合到Sparse4D框架中的方法,以直接輸出目標的運動軌跡。與基於檢測的追蹤方法不同,本文透過消除資料關聯和過濾的需求,將所有追蹤功能整合到偵測器中。此外,與現有的聯合檢測和追蹤方法不同,本文的追蹤器在訓練過程中無需進行修改或調整損失函數。它不需要提供ground truth IDs,而是實現了預先定義的實例到追蹤的回歸。本文的追蹤實現充分融合了偵測器和追蹤器,無需修改偵測器的訓練過程,也無需額外微調
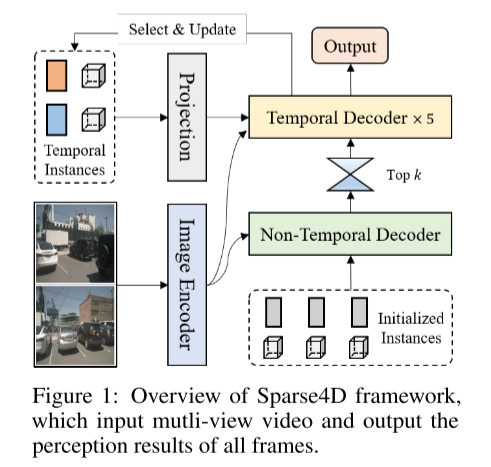
這是一個關於Sparse4D框架概述的圖1 ,輸入是多視圖視頻,輸出是所有幀的感知結果
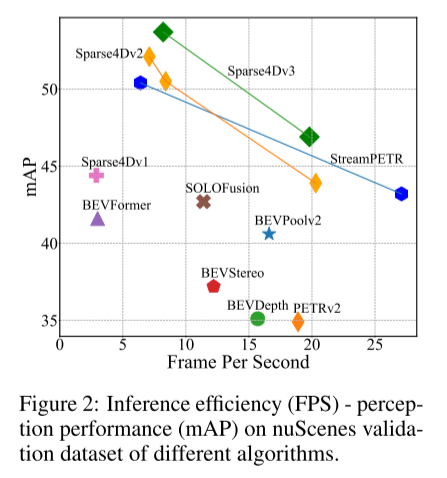
圖2:不同演算法的nuScenes 驗證資料集上的推理效率(FPS) - 感知性能( mAP)。

圖3:實例自註意力中的注意力權重的可視化:1)第一行顯示了普通自註意力中的注意力權重,其中紅色圓圈中的行人顯示出與目標車輛(綠色框)的意外相關性。 2)第二行顯示了解耦注意力中的注意力權重,有效解決了這個問題。
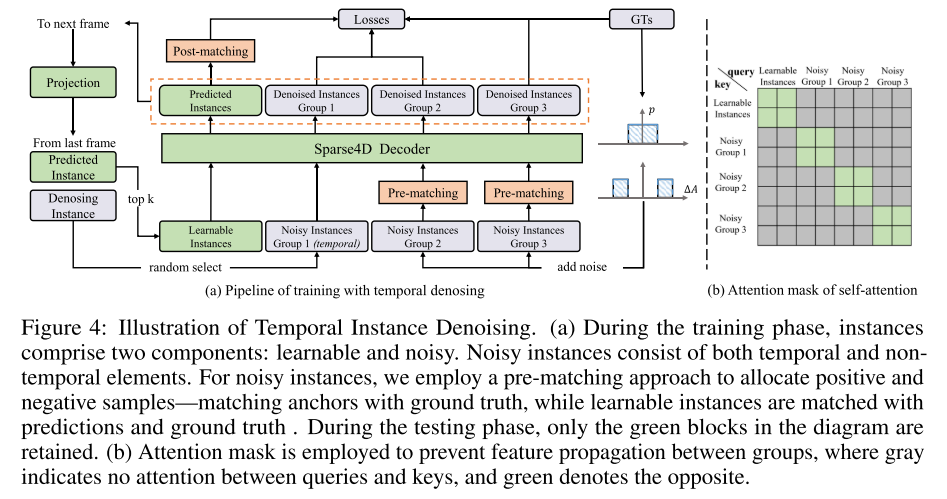
第四張圖展示了時序實例去噪的範例。在訓練階段,實例包括兩個部分:可學習的和噪音的。噪音實例由時間和非時間元素組成。本文採用預匹配方法來分配正樣本和負樣本,即將 anchors 與 ground truth 進行匹配,而可學習實例則與預測和 ground truth 進行匹配。在測試階段,只保留綠色塊。為防止特徵在groups 之間傳播,採用了Attention mask,灰色表示queries 和keys 之間沒有註意力,綠色表示相反
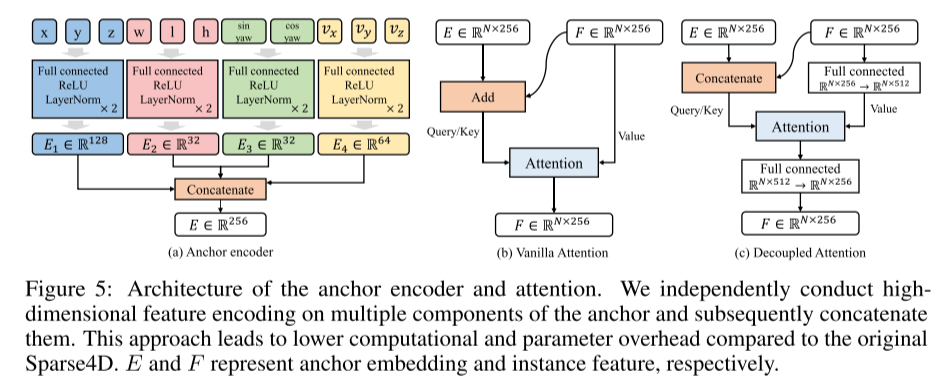
請看圖5:錨點編碼器和注意力的架構。本文獨立地對錨點的多個組件進行了高維特徵編碼,然後將它們連接起來。與原始的Sparse4D相比,這種方法可以減少計算和參數的開銷。 E和F分別表示錨點嵌入和實例特徵

實驗結果:
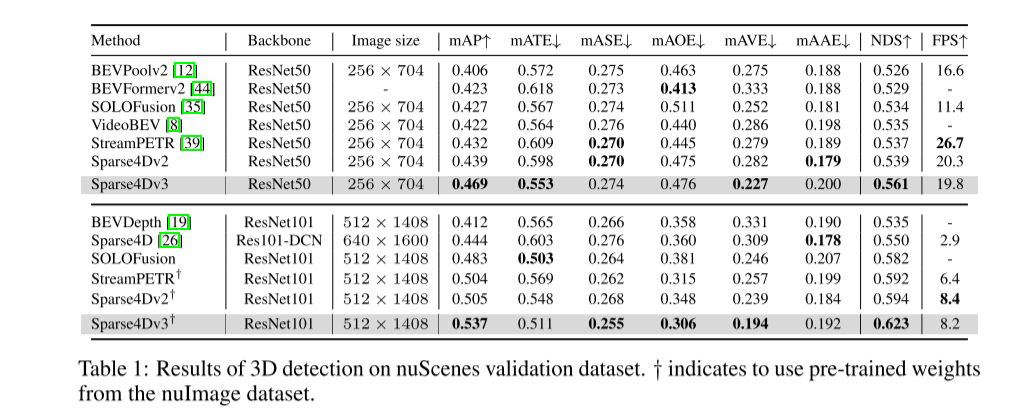
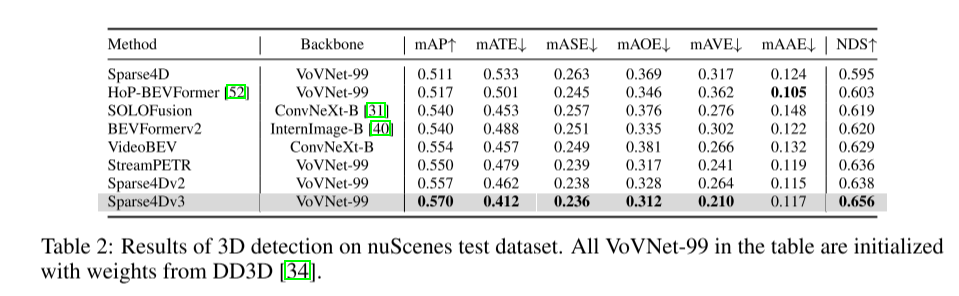
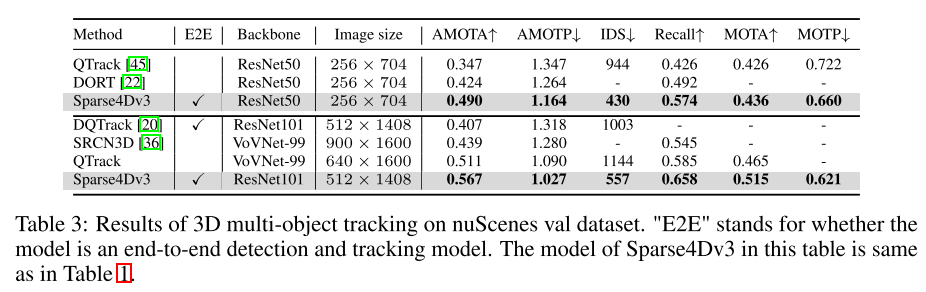
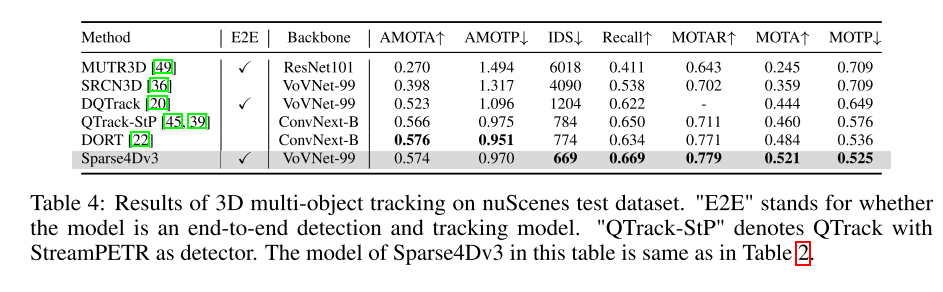
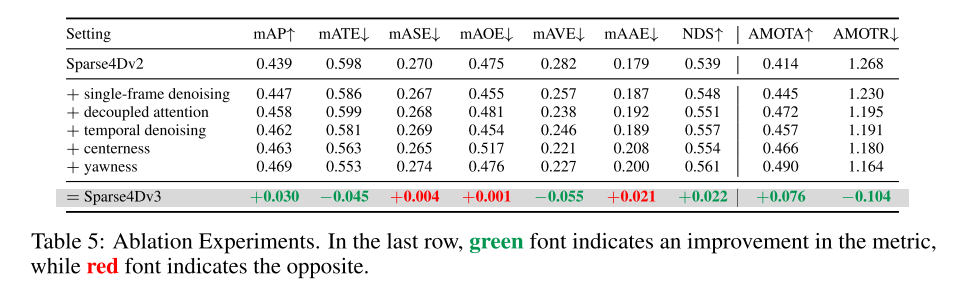
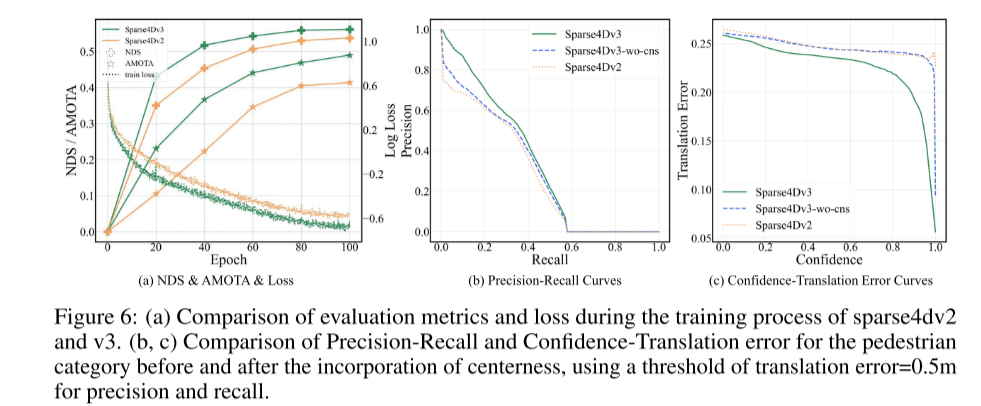
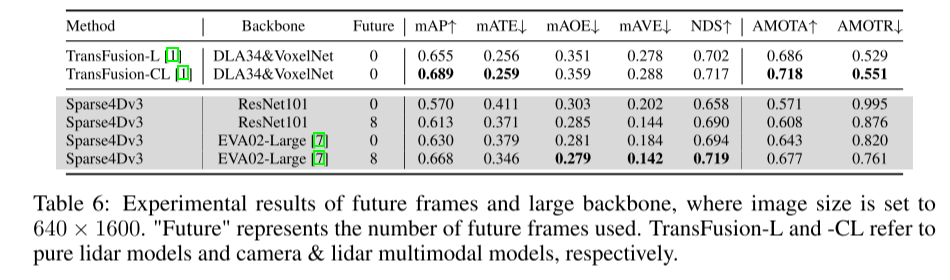
##總結:
#本文首先提出了增強Sparse4D 偵測效能的方法。這項增強主要包括三個面向:時序實例去雜訊、品質估計和解耦注意力。隨後,本文說明了將 Sparse4D 擴展為端到端追蹤模型的過程。本文在 nuScenes 上的實驗表明,這些增強功能顯著提高了性能,使 Sparse4Dv3 處於該領域的前沿。
引用:Lin, X., Pei, Z., Lin, T., Huang, L., & Su, Z. (2023). Sparse4D v3: Advancing End-to-End 3D Detection and Tracking.
###ArXiv. /abs/2311.11722###以上是Sparse4D v3來了!推進端到端3D偵測與追蹤的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
波士頓動力Atlas,正式進入電動機器人時代!昨天,液壓Atlas剛「含淚」退出歷史舞台,今天波士頓動力就宣布:電動Atlas上崗。看來,在商用人形機器人領域,波士頓動力是下定決心要跟特斯拉硬剛一把了。新影片放出後,短短十幾小時內,就已經有一百多萬觀看。舊人離去,新角色登場,這是歷史的必然。毫無疑問,今年是人形機器人的爆發年。網友銳評:機器人的進步,讓今年看起來像人類的開幕式動作、自由度遠超人類,但這真不是恐怖片?影片一開始,Atlas平靜地躺在地上,看起來應該是仰面朝天。接下來,讓人驚掉下巴
 快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
什麼?瘋狂動物城被國產AI搬進現實了?與影片一同曝光的,是一款名為「可靈」全新國產影片生成大模型。 Sora利用了相似的技術路線,結合多項自研技術創新,生產的影片不僅運動幅度大且合理,還能模擬物理世界特性,具備強大的概念組合能力與想像。數據上看,可靈支持生成長達2分鐘的30fps的超長視頻,分辨率高達1080p,且支援多種寬高比。另外再劃個重點,可靈不是實驗室放出的Demo或影片結果演示,而是短影片領域頭部玩家快手推出的產品級應用。而且主打一個務實,不開空頭支票、發布即上線,可靈大模型已在快影
 FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的距離感知相對來說研究較少。由於徑向畸變大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述描述,我們探索了擴展邊界框、橢圓、通用多邊形設計為極座標/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形形狀的模型fisheyeDetNet優於其他模型,並同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP
 聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
聊聊端到端與下一代自動駕駛系統,以及端到端自動駕駛的一些迷思?
Apr 15, 2024 pm 04:13 PM
最近一個月由於眾所周知的一些原因,非常密集地和業界的各種老師同學進行了交流。交流中必不可免的一個話題自然是端到端與火辣的特斯拉FSDV12。想藉此機會,整理當下這個時刻的一些想法和觀點,供大家參考和討論。如何定義端到端的自動駕駛系統,應該期望端到端解決什麼問題?依照最傳統的定義,端到端的系統指的是一套系統,輸入感測器的原始訊息,直接輸出任務關心的變數。例如,在影像辨識中,CNN相對於傳統的特徵提取器+分類器的方法就可以稱之為端到端。在自動駕駛任務中,輸入各種感測器的資料(相機/LiDAR
 超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂煉大模型,一網路的資料不夠用,根本不夠用。訓練模型搞得跟《飢餓遊戲》似的,全球AI研究者,都在苦惱怎麼才能餵飽這群資料大胃王。尤其在多模態任務中,這問題尤其突出。一籌莫展之際,來自人大系的初創團隊,用自家的新模型,率先在國內把「模型生成數據自己餵自己」變成了現實。而且還是理解側和生成側雙管齊下,兩側都能產生高品質、多模態的新數據,對模型本身進行數據反哺。模型是啥?中關村論壇上剛露面的多模態大模型Awaker1.0。團隊是誰?智子引擎。由人大高瓴人工智慧學院博士生高一鑷創立,高
 全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陳丹琦團隊提出簡單偏好優化SimPO,也煉出最強8B開源模型
Jun 01, 2024 pm 04:41 PM
為了將大型語言模型(LLM)與人類的價值和意圖對齊,學習人類回饋至關重要,這能確保它們是有用的、誠實的和無害的。在對齊LLM方面,一種有效的方法是根據人類回饋的強化學習(RLHF)。儘管RLHF方法的結果很出色,但其中涉及了一些優化難題。其中涉及訓練一個獎勵模型,然後優化一個策略模型來最大化該獎勵。近段時間已有一些研究者探索了更簡單的離線演算法,其中之一就是直接偏好優化(DPO)。 DPO是透過參數化RLHF中的獎勵函數來直接根據偏好資料學習策略模型,這樣就無需顯示式的獎勵模型了。此方法簡單穩定
