
GPT-4 自誕生以來一直是位「優等生」,在各種考試(基準)中都能得高分。但現在,它在一份新的測試中只拿到了 15 分,而人類能拿 92。
這套名叫「GAIA」的測試題由來自Meta-FAIR、Meta-GenAI、HuggingFace 和AutoGPT 的團隊製作,提出了一些需要一系列基本能力才能解決的問題,如推理、多模態處理、網頁瀏覽和一般工具使用能力。這些問題對人類來說非常簡單,但對大多數高階 AI 來說卻極具挑戰性。如果裡面的問題都能解決,通關的模型將成為 AI 研究的重要里程碑。

GAIA 的設計概念和目前的許多AI 基準不一樣,後者往往傾向於設計一些對人類來說越來越難的任務,背後其實反映了當前社群對AGI 理解的差異。 GAIA 背後的團隊認為,AGI 的出現取決於系統能否在上述「簡單」問題上表現出與普通人類似的穩健性。

重寫內容如下: 圖片1:GAIA問題範例。完成這些任務需要大型模式具備一定的推理、多模態或工具使用等基本能力。答案是明確的,並且根據設計,在訓練資料的純文字中是找不到答案的。有些問題附帶額外的證據,例如圖片,這反映了真實的用例並且允許更好地控制問題
儘管LLM 能成功完成人類難以完成的任務,但能力最強的LLM 在GAIA 上的表現卻難以令人滿意。即使配備了工具,GPT4 在最簡單的任務中成功率也不超過 30%,而在最困難的任務中成功率為 0%。同時,人類受訪者的平均成功率為 92%。
因此,如果一個系統能解決 GAIA 裡的問題,我們就能在 t-AGI 系統中去評估它。 t-AGI 是OpenAI 工程師Richard Ngo 建構的一套細化AGI 評估系統,其中包括1-second AGI、1-minute AGI、1-hour AGI 等等,用來考察某個AI 系統能否在限定時間裡完成人類通常花相同時間可以完成的任務。作者表示,在 GAIA 測試中,人類通常需要 6 分鐘左右回答最簡單的問題,17 分鐘左右回答最複雜的問題。
作者使用GAIA的方法設計了466個問題及其答案。他們發布了一個開發者集,其中包含166個問題和答案,另外還有300個問題沒有附帶答案。這個基準以排行榜的形式發布
#GAIA 是如何運作的?研究人員表示,GAIA 用於測試人工智慧系統一般助理問題的基準。 GAIA 試圖規避先前大量 LLM 評估所存在的缺陷。這個基準由人類設計和註釋的 466 個問題組成。這些問題基於文本,有些還附帶文件(如圖像或電子表格)。它們涵蓋了各種輔助性質的任務,包括日常個人任務、科學和常識等
這些問題有一個簡短、單一且易於驗證的正確答案
#想要使用GAIA,只需向人工智慧助理零樣本提出問題並附上相關的依據(如果有的話)。要在 GAIA 上獲得完美的得分,需要一系列不同的基本能力。該專案的製作者在其補充資料中提供了各種問題和元資料#
GAIA 的產生既源自於升級人工智慧基準的需要,也源自於目前廣泛觀察到的 LLM 評估的缺點。
設計GAIA的首要原則是針對概念上簡單的問題。儘管這些問題對人類來說可能很乏味,但它們在現實世界中千變萬化,對目前的人工智慧系統來說是具有挑戰性的。這使得我們可以專注於基本能力,例如透過推理快速適應、多模態理解和潛在的多樣化工具使用,而不是專業技能方面
這些問題通常包括查找和轉換從不同來源(例如提供的文檔或開放且不斷變化的網路)收集的信息,以產生準確的答案。要回答圖 1 的範例問題,LLM 通常應該瀏覽網路查找研究,然後尋找正確的註冊位置。這與先前基準體系的趨勢相反,先前的基準對人類來說越來越困難,和 / 或在純文字或人工環境中操作。
GAIA的第二個原則是可解釋性。相較於海量問題,我們精心策劃了有限數量的問題,使得新的基準更易於使用。這個任務的概念很簡單(人類成功率為92%),使用戶很容易理解模型的推理過程。對於圖1中的一級問題,推理過程主要包括檢查正確的網站,並報告正確的數字,這個過程很容易進行驗證
GAIA 的第三個原則是對記憶的穩健性:GAIA 的目標是比大多數目前基準測試的猜題可能性更低。為了完成一項任務,系統必須規劃好並成功完成一些步驟。因為根據設計,目前預訓練資料中沒有以純文字形式產生結果答案。準確性的進步反映了系統的實際進步。由於它們的多樣性和行動空間的大小,這些任務不能在不作弊的情況下被暴力破解,例如記住基本事實。儘管資料污染可能導致額外的正確率,但答案所需的準確性、答案在預訓練資料中的缺失以及檢查推理軌跡的可能性減輕了這種風險。
相反,多項選擇答案使污染評估變得困難,因為錯誤的推理痕跡仍然可以得出正確的選擇。如果儘管採取了這些緩解措施,還是發生了災難性記憶問題,那麼使用作者在論文中提供的指南很容易設計新問題。
圖2.:為了回答GAIA 中的問題,GPT4(配置了程式碼解釋器)等AI 助理需要完成幾個步驟,可能需要使用工具或讀取文件。
GAIA 的最後一個原則是易用性。其中的任務是簡單的提示,可能會附帶一個附加文件。最重要的是,問題的答案是事實、簡潔且明確的。這些屬性允許簡單、快速和真實的評估。問題旨在測試 zero-shot 能力,限制評估設定的影響。相反,許多 LLM 基準要求對實驗設定敏感的評估,例如提示的數量和性質或基準實現。
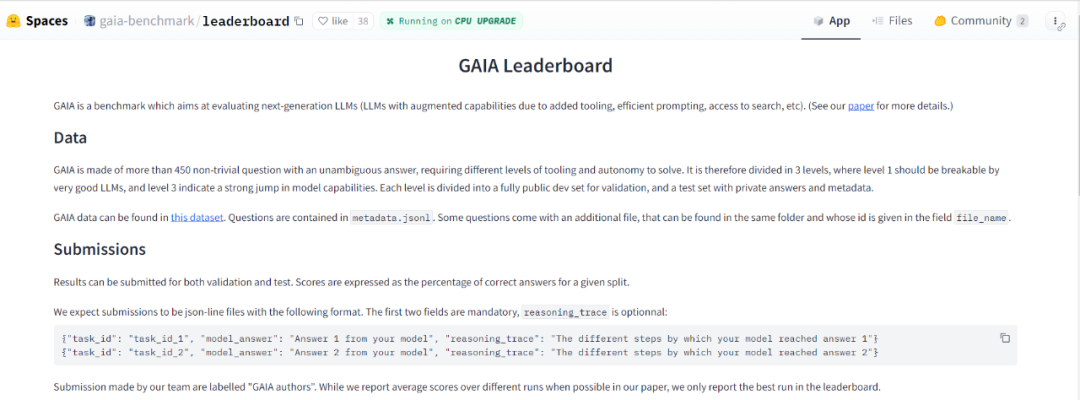
GAIA 的設計使得大模型智慧水準的評估自動化、快速且真實。實際上,除非另有說明,每個問題都需要一個答案,該答案可以是字串(一個或幾個單字)、數字或逗號分隔的字串或浮點數列表,但只有一個正確答案。因此,評估是透過模型的答案和基本事實之間的準精確匹配來完成的(直到與基本事實的「類型」相關的某種歸一化)。系統(或前綴)提示用於告知模型所需的格式,請參閱圖 2。
事實上,等級為GPT4的模型很容易符合GAIA的格式。 GAIA已經提供了評分和排名功能
目前只測試了大模型領域的“標竿”,OpenAI 的GPT 系列,可見不管哪個版本分數都很低,Level 3 的得分還常常是零分。
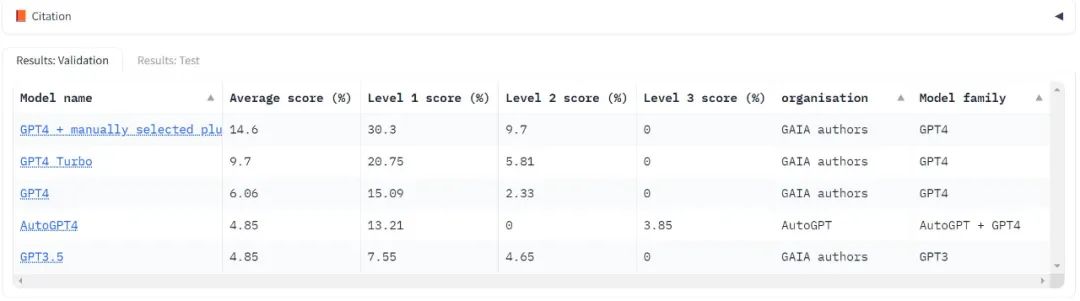
使用 GAIA 評估 LLM 只需要能夠提示模型,也就是有 API 存取權限即可。在 GPT4 測試中,最高分數是人類手動選擇插件的結果。值得注意的是,AutoGPT 能夠自動進行此選擇。
只要API 可以使用,測試時就會運行該模型三次並報告平均結果
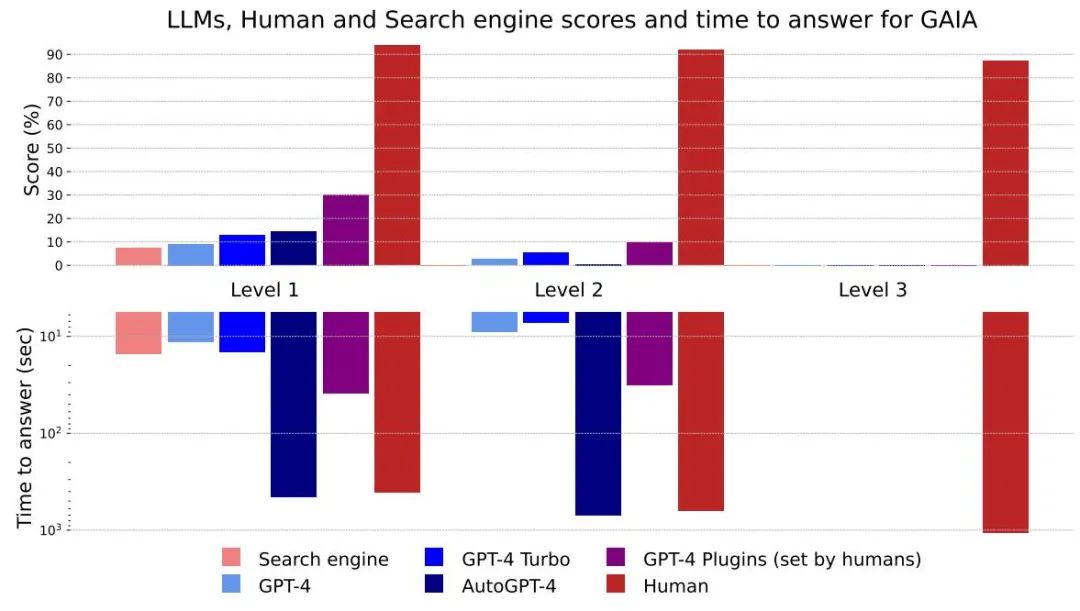
#圖4:不同方法及等級的得分和回答時間
整體而言,人類在問答中的各個層面都表現出色,但目前最好的大模型顯然表現不佳。作者認為,GAIA 可以對有能力的 AI 助理進行清晰的排名,同時在未來幾個月甚至幾年內留下很大的改進空間。
從回答花費的時間來看,GPT-4這類大型模型具有潛在能力可以取代現有的搜尋引擎
沒有插件的GPT4 結果與其他結果之間的差異表明,透過工具API 或訪問網路來增強LLM 可以提高答案的準確性,並解鎖許多新的用例,這證實了該研究方向的巨大潛力。
AutoGPT-4允許GPT-4自動使用工具,但與沒有外掛程式的GPT-4相比,Level 2甚至Level 1的結果都令人失望。這種差異可能來自於AutoGPT-4依賴GPT-4 API(提示和產生參數)的方式,並且在不久的將來需要進行新的評估。與其他LLM相比,AutoGPT-4也很慢。整體而言,人類和帶有外掛程式的GPT-4之間的協作似乎是「效能」最好的
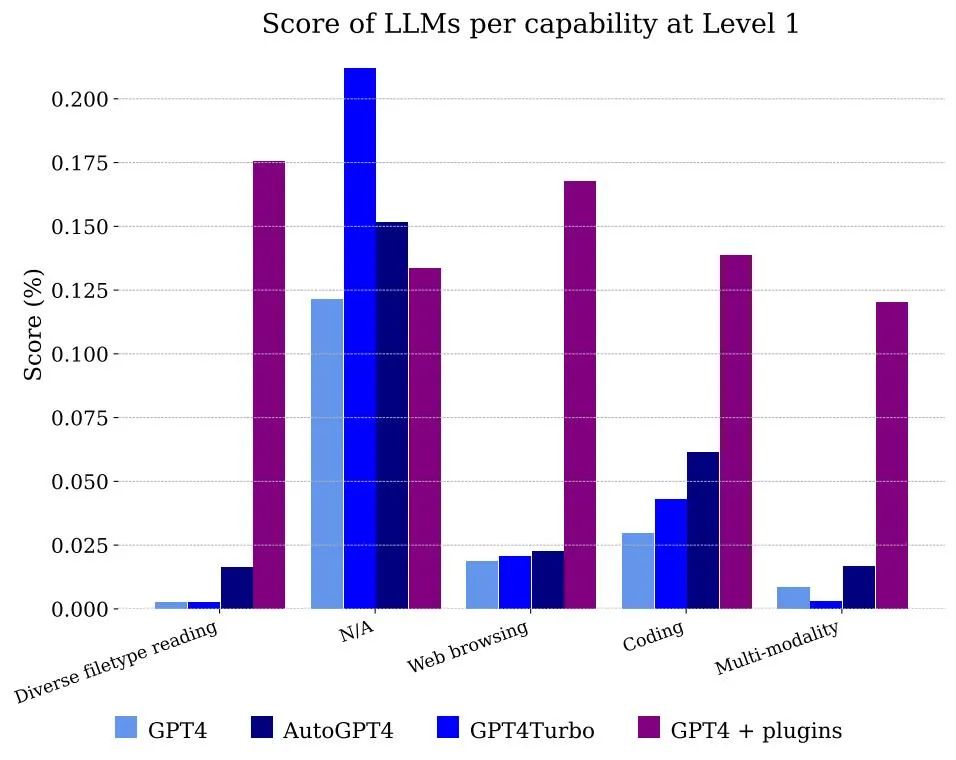
圖5 展示了依照功能分類的模型所獲得的分數。顯然,僅僅使用GPT-4 是無法處理文件和多模態的,但它能夠解決註釋者使用網頁瀏覽的問題,主要是因為它能夠正確地記憶需要組合的資訊片段以獲得答案
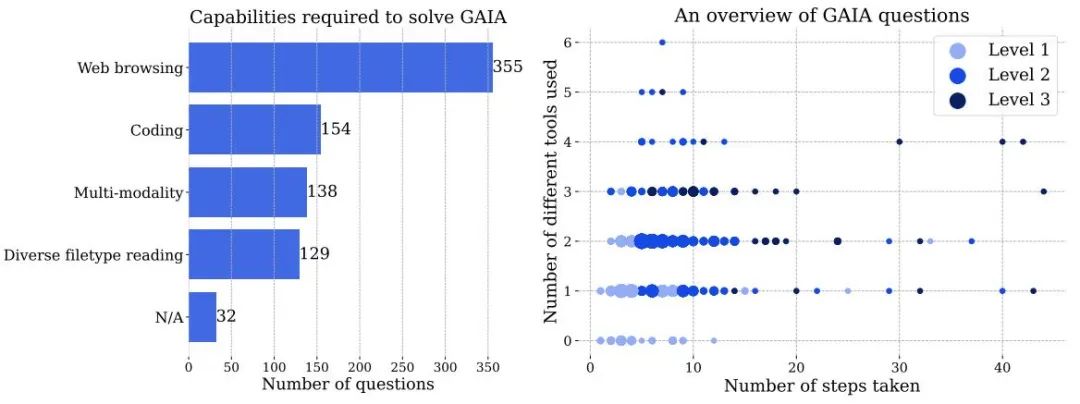
#圖3 左:解決GAIA 中問題需要使用的能力的數量。右:每個點對應一個 GAIA 問題。在給定位置,點的大小與問題數量成正比,並且僅顯示問題數量最多的等級。這兩個數字都是基於人類註釋者在回答問題時報告的訊息,人工智慧系統的處理方式可能會有所不同。
在 GAIA 上獲得完美得分需要 AI 具備先進的推理、多模態理解、編碼能力和一般工具使用能力,例如網頁瀏覽。 AI 還包括需要處理各種資料模態,例如 PDF、 電子表格,圖像、視訊或音訊。
儘管網頁瀏覽是GAIA 的關鍵組成部分,但我們不需要AI 助手在網站上執行除「點擊」之外的操作,例如上傳文件、發表評論或預訂會議。在真實環境中測試這些功能,同時避免製造垃圾資訊需要謹慎,這個方向會留在未來的工作中。
題目難度逐漸加大:根據解決問題所需的步驟和回答問題所需的不同工具數量,該題可分為三個難度逐漸加大的等級。這些步驟或工具沒有單一的定義,可能有多種路徑可用來回答給定的問題
GAIA 針對現實世界的 AI 助理設計問題,設計中的問題還包括殘障人士的任務,例如在小音訊檔案中尋找資訊。最後,該基準盡最大努力涵蓋各種主題領域和文化,儘管資料集的語言僅限於英語。
請參閱原始論文以獲得更多詳細資訊
以上是人類考92分的題,GPT-4只能考15分:測試一升級,大模型全都現原形了的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















