
2D擴散模型的引入大大簡化了圖像內容的創作流程,為2D設計產業帶來了革新。近年來,這個擴散模型已經擴展到了3D創作領域,降低了應用程式(如VR、AR、機器人技術和遊戲等)中的人力成本。許多研究已經開始探索使用預先訓練的2D擴散模型,以及採用評分蒸餾採樣(SDS)損失的NeRFs方法。然而,基於SDS的方法通常需要數小時的資源優化,並且經常引發圖形中的幾何問題,如多面Janus問題
另一方面,研究者對無需花費大量時間優化每個資源,也能夠實現多樣化產生的3D 擴散模型也進行了多種嘗試。這些方法通常需要取得包含真實資料的 3D 模型 / 點雲用於訓練。然而,對於真實影像來說,這種訓練資料難以取得。由於目前的 3D 擴散方法通常是基於兩階段訓練,這導致在不分類、高度多樣化的 3D 資料集上存在一個模糊且難以去噪的潛在空間,使得高品質渲染成為亟待解決的挑戰。
為了解決這個問題,已經有研究者提出了單階段模型,但是這些模型大多只針對特定的簡單類別,泛化性較差
#因此,本文研究者的目標是實現快速、逼真且通用的3D 生成。為此,他們提出了 DMV3D。 DMV3D 是一種全新的單階段的全類別擴散模型,能直接根據模型文字或單張圖片的輸入,產生 3D NeRF。在單一 A100 GPU 上,只需 30 秒,DMV3D 就能產生各種高傳真 3D 影像。

具體而言,DMV3D是一個2D多視圖影像擴散模型,它將3D NeRF的重建和渲染集成到其降噪器中,並以端到端的方式進行訓練,無需直接進行3D監督。這樣做避免了單獨訓練用於潛在空間擴散的3D NeRF編碼器(例如兩階段模型)和繁瑣的為每個物件進行最佳化的方法(例如SDS)中可能出現的問題
本文的方法本質上是在2D 多視圖擴散的框架基礎上進行3D 重建。這種方法是受到 RenderDiffusion 方法的啟發,後者是一種透過單視圖擴散實現 3D 生成的方法。然而,RenderDiffusion 方法的限制在於,訓練資料需要特定類別的先驗知識,而資料中的物件需要特定的角度或姿勢,因此其泛化性很差,無法對任意類型的物件進行3D 產生
據研究者認為,相較而言,只需要一組包含一個物體的四個多重視角的稀疏投影,即可描述一個未被遮蔽的3D物體。這種訓練資料源自於人類的空間想像能力,人們能夠透過幾個物體周圍的平面視圖建構出一個完整的3D物體。這種想像通常非常確切且具體化
不過,在應用這種輸入時,仍需要解決稀疏視圖下進行3D重建的任務。這是一個長期存在的問題,即使在輸入沒有雜訊的情況下,也是非常具有挑戰性的
本文的方法能夠基於單一圖像 / 文字實現 3D 生成。對於影像輸入,他們固定一個稀疏視圖作為無雜訊輸入,並對其他視圖進行類似於 2D 影像修復的降噪。為了實現基於文本的 3D 生成,研究者使用了在 2D 擴散模型中通常會用到的、基於注意力的文本條件和不受類型限制的分類器。
他們在訓練過程中只使用了影像空間監督,並使用了由Objaverse合成的影像和MVImgNet真實捕捉的影像組成的大型資料集。根據結果顯示,DMV3D在單影像3D重建方面達到了SOTA水平,超過了先前基於SDS的方法和3D擴散模型。此外,基於文本的3D模型生成方法也比之前的方法更優

我們來看看產生的3D 影像效果。


如何訓練並推理單階段3D 擴散模型?
研究者首先引入了一種新的擴散框架,該框架使用基於重建的降噪器來對有雜訊的多視圖影像去噪以進行3D 生成;其次他們提出了一種新的、以擴散時間步為條件的、基於LRM 的多視圖降噪器,從而通過3D NeRF 重建和渲染來漸進地對多視圖圖像進行去噪;最後進一步對模型進行擴散,支持文字和圖像調節,實現可控生成。
需要重寫的內容是:多重視圖擴散和去雜訊。 重寫後的內容:多角度視圖擴散與降噪
多視圖擴散。 2D擴散模型中處理的原始 x_0 分佈在資料集中是單一影像分佈。相反,研究者考慮的是多視圖圖像 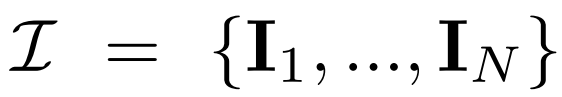 的聯合分佈,其中每組
的聯合分佈,其中每組 都是從視點C = {c_1, .. ., c_N}中相同3D 場景(資產)的圖像觀察結果。擴散過程相當於使用相同的雜訊調度獨立地對每個影像進行擴散操作,如下公式 (1) 所示。
都是從視點C = {c_1, .. ., c_N}中相同3D 場景(資產)的圖像觀察結果。擴散過程相當於使用相同的雜訊調度獨立地對每個影像進行擴散操作,如下公式 (1) 所示。
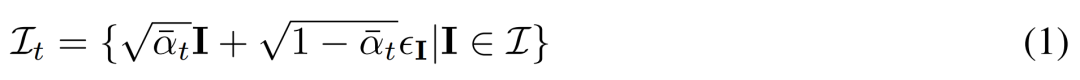
基於重建的去雜訊。 2D 擴散過程的逆過程本質上是去雜訊。本文中,研究者提出利用 3D 重建和渲染來實現 2D 多視圖影像去噪,同時輸出乾淨的、用於 3D 產生的 3D 模型。具體來講,他們使用3D 重建模組E (・) 來從有雜訊的多視圖影像 中重建3D 表示S,並使用可微渲染模組R (・) 對去雜訊影像進行渲染,如下公式(2) 所示。
中重建3D 表示S,並使用可微渲染模組R (・) 對去雜訊影像進行渲染,如下公式(2) 所示。
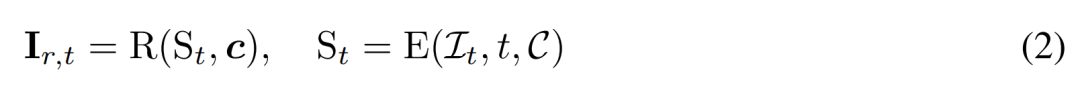
#基於重建的多重視圖降噪器
研究者基於LRM 建立了多視圖降噪器,並使用大型transformer 模型從有雜訊的稀疏視圖姿態影像中重建了一個乾淨的三平面NeRF,然後將重建後的三平面NeRF 的渲染用作去噪輸出。
重建與渲染。如下圖3 所示,研究者使用一個Vision Transformer(DINO)來將輸入影像 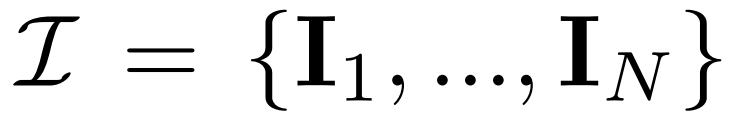 轉換為2D token,然後使用transformer 將學習到的三平面位置嵌入映射到最後的三平面,以表示資產的3D 形狀和外觀。接下來將預測到的三平面用來透過一個 MLP 來解碼體積密度和顏色,以進行可微體積渲染。
轉換為2D token,然後使用transformer 將學習到的三平面位置嵌入映射到最後的三平面,以表示資產的3D 形狀和外觀。接下來將預測到的三平面用來透過一個 MLP 來解碼體積密度和顏色,以進行可微體積渲染。
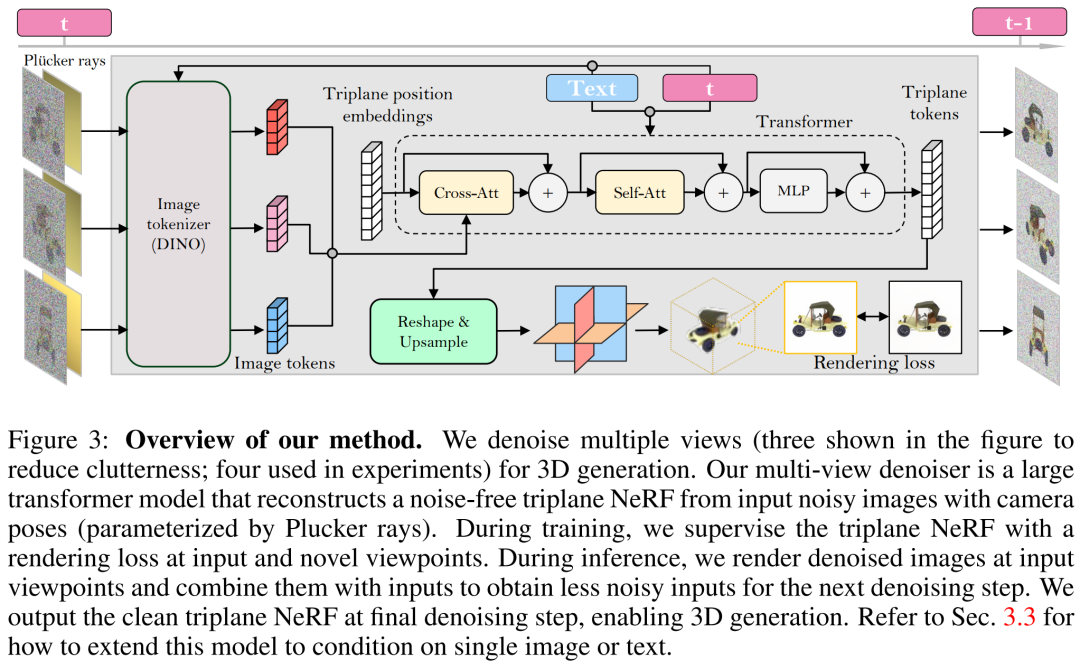
時間調節。與基於 CNN 的 DDPM(去噪擴散機率模型)相比,本文基於 transformer 的模型需要不同的時間調節設計。
在訓練本文模型時,研究者指出,在具有高度多樣化的相機內參和外參資料集(如MVImgNet)上,需要有效設計輸入相機調節,以幫助模型理解相機並進行3D推理
進行內容的重寫時,需要將原文的語言轉換成中文,但不改變原文的意思
以上方法使研究者提出的模型可以充當一個無條件生成模型。他們介紹如何利用條件降噪器 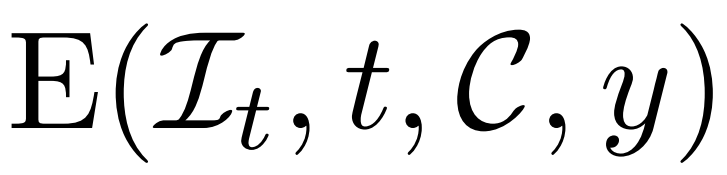 來對條件機率分佈進行建模,其中 y 表示文字或圖像,以實現可控 3D 生成。
來對條件機率分佈進行建模,其中 y 表示文字或圖像,以實現可控 3D 生成。
在圖像調節方面,研究人員提出了一種簡單而有效的策略,無需對模型的架構進行修改
文字調節。為了將文本調節加入自己的模型中,研究者採用了類似 Stable Diffusion 的策略。他們使用 CLIP 文字編碼器產生文字嵌入,並使用交叉注意力將它們注入到降噪器中。
需要進行改寫的內容是:訓練和推理
訓練。在訓練階段,研究者在範圍 [1, T] 內均勻地取樣時間步 t,並根據餘弦調度來添加雜訊。他們使用隨機相機姿態對輸入影像進行採樣,還隨機採樣額外的新視點來監督渲染以獲得更好的品質。
研究者使用條件訊號y來最小化訓練目標
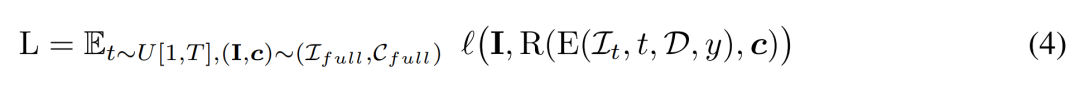
#推理。在推理階段,研究者選擇了以圓圈均勻圍繞物體的視點,以確保很好地覆蓋生成的 3D 資產。他們將四個視圖的相機市場角落固定為 50 度。
在實驗中,研究人員採用了AdamW優化器來訓練他們的模型,初始學習率為4e^- 4。他們為了這個學習率使用了3K步驟的預熱和餘弦衰減,使用256×256的輸入影像來訓練去噪模型,並使用128×128的裁切影像進行監督渲染
#關於資料集的內容需要重寫為:研究者的模型只需使用多視圖姿態影像進行訓練。因此,他們使用了來自Objaverse資料集的約730k個物件的渲染後多視圖影像。對於每個對象,他們按照LRM的設定,在固定50度FOV的隨機視點下進行了32次圖像渲染,並進行了均勻照明
首先是單圖像重建。研究者將自己的圖像 - 調節模型與 Point-E、Shap-E、Zero-1-to-3 和 Magic123 等以往方法在單一影像重建任務上進行了比較。他們使用到的指標有 PSNR、LPIPS、CLIP 相似性分數和 FID,以評估所有方法的新視圖渲染品質。
GSO和ABO測試集上的量化結果如下表1所示。研究者的模型優於所有基準方法,並且在這兩個資料集上實現了所有指標的新SOTA
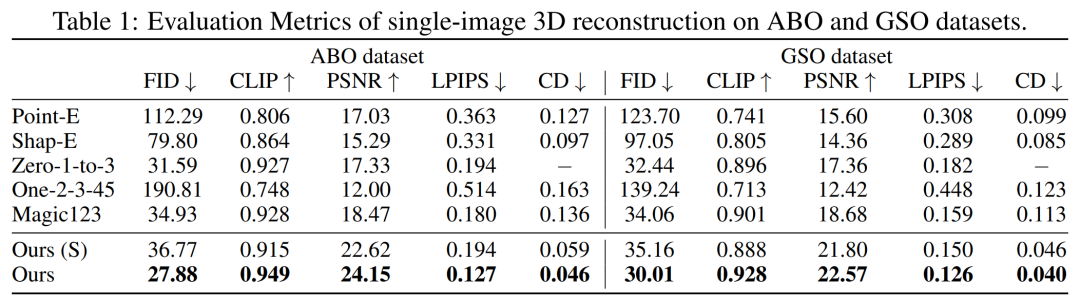
本文模型產生的結果在幾何和外觀細節方面相比基線具有更高質量,這一結果可以透過圖4進行定性展示
DMV3D 是一個以2D圖像為訓練目標的單階段模型,與之相比,它無需對每個資產單獨最佳化,同時可以消除多視圖擴散雜訊並直接產生3D NeRF模型。整體而言,DMV3D能夠快速產生3D影像,並獲得最佳的單一影像3D重建結果

#重新寫作如下:研究人員也對基於文本的3D生成結果進行了DMV3D的評估。研究人員比較了DMV3D與同樣支持全類別快速推理的Shap-E和Point-E。研究人員讓這三個模型根據Shap-E的50個文字提示進行生成,並使用兩個不同的ViT模型的CLIP準確度和平均準確度來評估生成結果,如表2所示
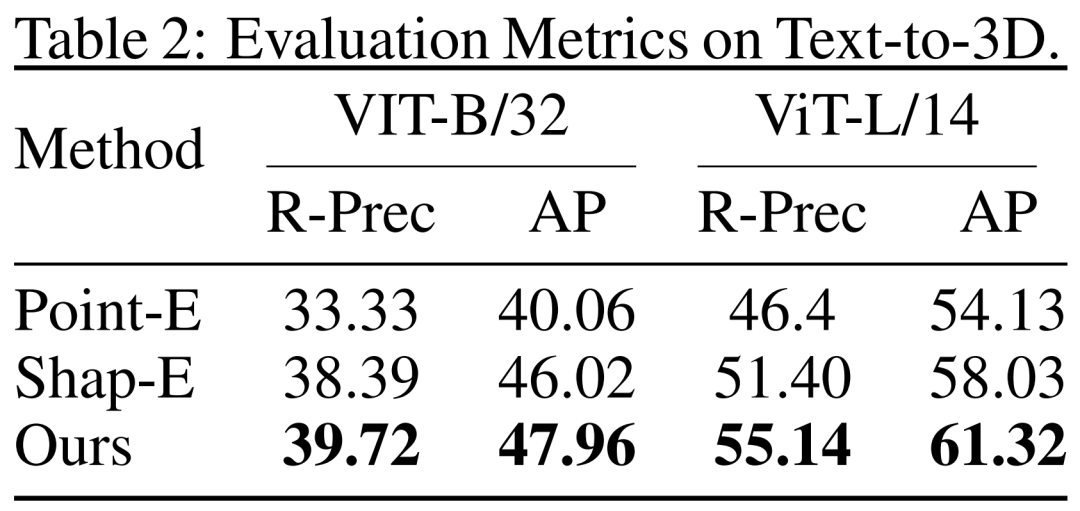
According to the data in the table, DMV3D shows the best accuracy. As can be seen from the qualitative results in Figure 5, compared to the results generated by other models, the graphics generated by DMV3D clearly contain richer geometric and appearance details, and the results are more realistic

What needs to be rewritten is: other results
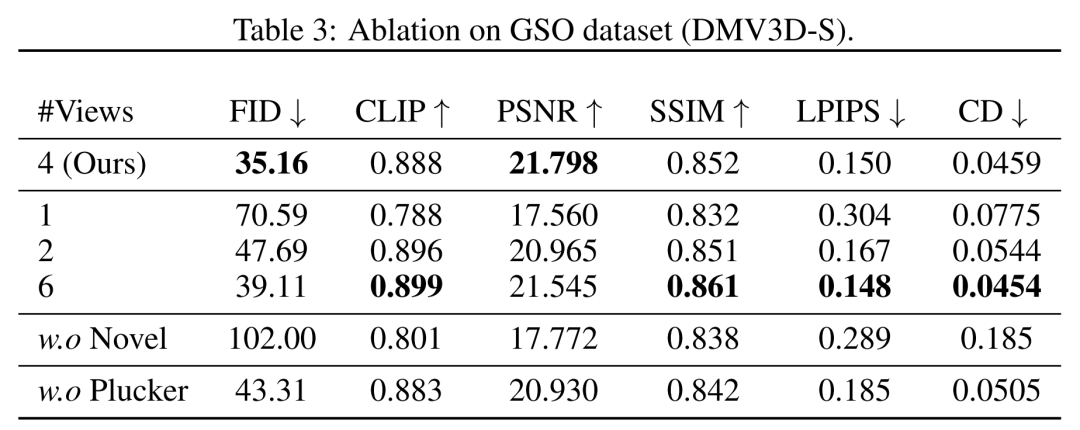
In terms of perspective, the researcher shows in Table 3 and Figure 8 Quantitative and qualitative comparison of models trained with different numbers of input views (1, 2, 4, 6).

#In terms of multi-instance generation, similar to other diffusion models, the model proposed in this article can generate a variety of examples based on random input, as shown in Figure 1, which demonstrates the generalization of the results generated by the model.

DMV3D has extensive flexibility and versatility in applications, and has strong development potential in the field of 3D generation applications. As shown in Figures 1 and 2, our method can lift any object in a 2D photo to a 3D dimension in image editing applications through methods such as segmentation (such as SAM)
Please read the original paper for more technical details and experimental results

以上是Adobe的新技術:用A100產生3D影像只需30秒,讓文字和影像動起來的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















