
译者 | 陈峻
审校 | 重楼
在本文中,我将向您介绍“少样本(Few-shot)学习”的相关概念,并重点讨论被广泛应用于文本分类的SetFit方法。

在监督(Supervised)机器学习中,大量数据集被用于模型训练,以便磨练模型能够做出精确预测的能力。在完成训练过程之后,我们便可以利用测试数据,来获得模型的预测结果。然而,这种传统的监督学习方法存在着一个显著缺点:它需要大量无差错的训练数据集。但是并非所有领域都能够提供此类无差错数据集。因此,“少样本学习”的概念应运而生。
在深入研究Sentence Transformer fine-tuning(SetFit)之前,我们有必要简要地回顾一下自然语言处理(Natural Language Processing,NLP)的一个重要方面,也就是:“少样本学习”。
少样本学习是指:使用有限的训练数据集,来训练模型。模型可以从这些被称为支持集的小集合中获取知识。此类学习旨在教会少样本模型,辨别出训练数据中的相同与相异之处。例如,我们并非要指示模型将所给图像分类为猫或狗,而是指示它掌握各种动物之间的共性和区别。可见,这种方法侧重于理解输入数据中的相似点和不同点。因此,它通常也被称为元学习(meta-learning)、或是从学习到学习(learning-to-learn)。
值得一提的是,少样本学习的支持集,也被称为k向(k-way)n样本(n-shot)学习。其中“k”代表支持集里的类别数。例如,在二分类(binary classification)中,k 等于 2。而“n”表示支持集中每个类别的可用样本数。例如,如果正分类有10个数据点,而负分类也有10个数据点,那么 n就等于10。总之,这个支持集可以被描述为双向10样本学习。
既然我们已经对少样本学习有了基本的了解,下面让我们通过使用SetFit进行快速学习,并在实际应用中对电商数据集进行文本分类。
由Hugging Face和英特尔实验室的团队联合开发的SetFit,是一款用于少样本照片分类的开源工具。你可以在项目库链接--https://github.com/huggingface/setfit?ref=hackernoon.com中,找到关于SetFit的全面信息。
就输出而言,SetFit仅用到了客户评论(Customer Reviews,CR)情感分析数据集里、每个类别的八个标注示例。其结果就能够与由三千个示例组成的完整训练集上,经调优的RoBERTa Large的结果相同。值得强调的是,就体积而言,经微优的RoBERTa模型比SetFit模型大三倍。下图展示的是SetFit架构:
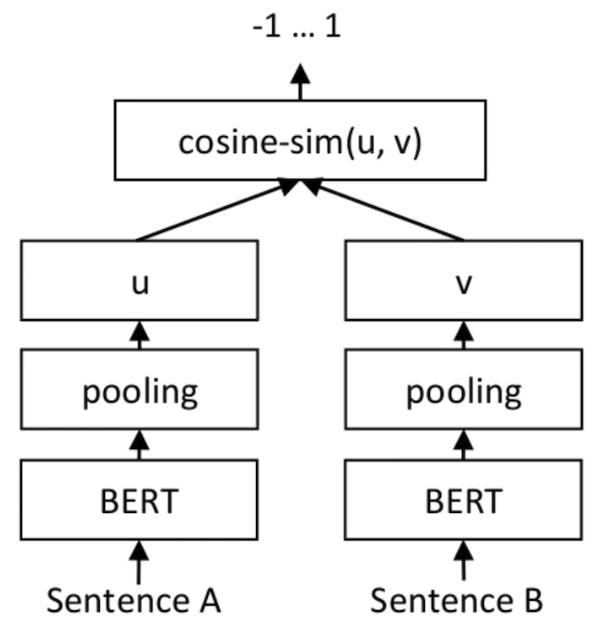
图片来源:https://www.php.cn/link/2456b9cd2668fa69e3c7ecd6f51866bf
SetFit的训练速度非常快,效率也极高。与GPT-3和T-FEW等大模型相比,其性能极具竞争力。请参见下图:
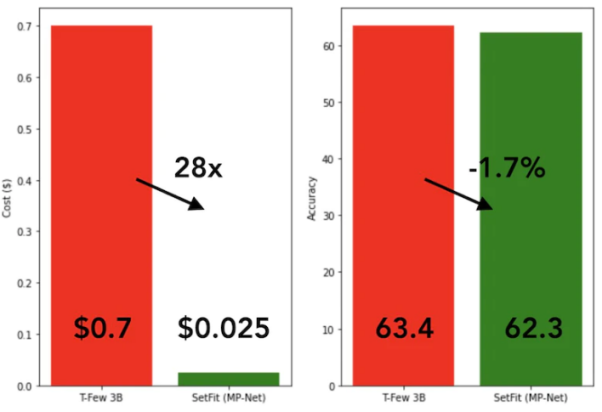 SetFit與T-Few 3B模型的比較
SetFit與T-Few 3B模型的比較
#如下圖所示,##SetFit在少樣本學習的表現優於RoBERTa。
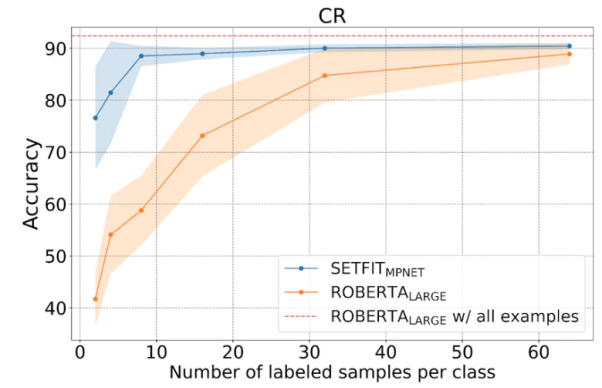
SetFit與RoBERT的比較,圖片來源:##https://www .php.cn/link/3ff4cea152080fd7d692a8286a587a67
##。 ,我們將用到由四個不同類別組成的獨特電商資料集,它們分別是:書籍、服裝與配件、電子產品、以及家居用品。此資料集的主要目的是將電商網站的產品描述歸類到指定的標籤下。
為了方便採用少樣本的訓練方法,我們將從四個類別中各選擇八個樣本,從而得到總共32 個訓練樣本。而其餘樣本則將留作測試之用。簡言之,我們在此使用的支持集是4向8
樣本學習。下圖展示的是自訂電商資料集的範例:
#自訂電商資料集樣本 #我們採用名為「all-mpnet-base-v2」的Sentence Transformers預訓練模型,將文字資料轉換為各種向量嵌入。此模型可以為輸入文本,產生維度為768
的向量嵌入。如下指令所示,我們將透過在conda環境(是一個開源的軟體包管理系統和環境管理系統)中安裝所需的軟體包,來開始SetFit
的實作。!pip3 install SetFit !pip3 install sklearn !pip3 install transformers !pip3 install sentence-transformers
from datasets import load_datasetdataset = load_dataset('csv', data_files={"train": 'E_Commerce_Dataset_Train.csv',"test": 'E_Commerce_Dataset_Test.csv'})
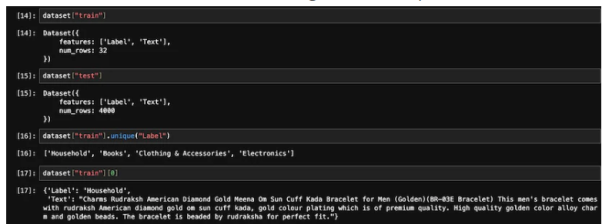
訓練與測試資料#我們使用##sklearn軟體包中的LabelEncoder,將文字標籤轉換為編碼標籤。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
Encoded_Product = le.fit_transform(dataset["train"]['Label']) dataset["train"] = dataset["train"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["train"].features)Encoded_Product = le.fit_transform(dataset["test"]['Label']) dataset["test"] = dataset["test"].remove_columns("Label").add_column("Label", Encoded_Product).cast(dataset["test"].features)from setfit import SetFitModel, SetFitTrainer from sentence_transformers.losses import CosineSimilarityLossmodel_id = "sentence-transformers/all-mpnet-base-v2" model = SetFitModel.from_pretrained(model_id)trainer = SetFitTrainer( model=model, train_dataset=dataset["train"], eval_dataset=dataset["test"], loss_class=CosineSimilarityLoss, metric="accuracy", batch_size=64, num_iteratinotallow=20, num_epochs=2, column_mapping={"Text": "text", "Label": "label"})
trainer.train()
trainer.evaluate()
此外,SetFit也能夠將訓練好的模型,儲存到本地記憶體中,以便後續從磁碟加載,用於將來的預測。
trainer.model._save_pretrained(save_directory="SetFit_ECommerce_Output/")model=SetFitModel.from_pretrained("SetFit_ECommerce_Output/", local_files_notallow=True)
input = ["Campus Sutra Men's Sports Jersey T-Shirt Cool-Gear: Our Proprietary Moisture Management technology. Helps to absorb and evaporate sweat quickly. Keeps you Cool & Dry. Ultra-Fresh: Fabrics treated with Ultra-Fresh Antimicrobial Technology. Ultra-Fresh is a trademark of (TRA) Inc, Ontario, Canada. Keeps you odour free."]output = model(input)
至此,相信您已經基本掌握了「少樣本學習」的概念,以及如何使用SetFit來進行文字分類等應用。當然,為了獲得更深刻的理解,我強烈建議您選擇一個實際場景,建立一個資料集,編寫對應的程式碼,並將該過程延展到零樣本學習、以及單樣本學習。
#陳峻(Julian Chen)是51CTO社群的編輯,他在IT專案實施方面有十多年的經驗,擅長管理內部和外部資源和風險,並專注於傳播網路和資訊安全的知識和經驗
原文標題:Mastering Few-Shot Learning with SetFit for Text Classification,作者:Shyam Ganesh S)
以上是在少樣本學習中,以SetFit進行文字分類的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















