

一言不合就跑分,國內AI大模型為何沉迷於'刷榜”

「不服跑個分」這句話,我相信關注手機圈的朋友一定不會感到陌生。例如,安兔兔、GeekBench等理論性能測試軟體因為能夠在一定程度上反映手機的性能,因此備受玩家的關注。同樣地,在PC處理器、顯示卡上也有對應的跑分軟體來衡量它們的效能
既然"萬物皆可跑分",目前最火爆的AI大模型也開始參與跑分比拼,尤其是在"百模大戰"開始後,幾乎每天都有突破,各家都自稱為"跑分第一"
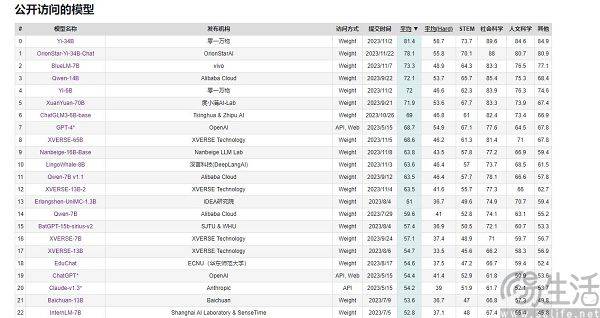
國產AI大模型在表現評分方面幾乎從未落後,但在使用者體驗方面卻始終無法超越GPT-4。這就引發了一個問題,即在大促銷售節點,各手機廠商總能夠宣稱自家產品“銷量第一”,透過不斷增加定語,將市場細分再細分,讓每個人都有機會成為第一,但在AI大模型領域,情況卻不同。畢竟,它們的評估標準基本上是統一的,其中包括MMLU(用於衡量多任務語言理解能力)、Big-Bench(用於量化和外推LLMs的能力),以及AGIEval(用於評估應對人類級任務的能力)
目前在國內常被引用的大型模式評測榜單有SuperCLUE、CMMLU和C-Eval。其中,CMMLU和C-Eval是由清華大學、上海交通大學和愛丁堡大學合作建構的綜合考試評測集。而CMMLU則是由MBZUAI、上海交通大學和微軟亞洲研究院共同推出。至於SuperCLUE,則是由各大專院校的人工智慧專業人士共同撰寫的
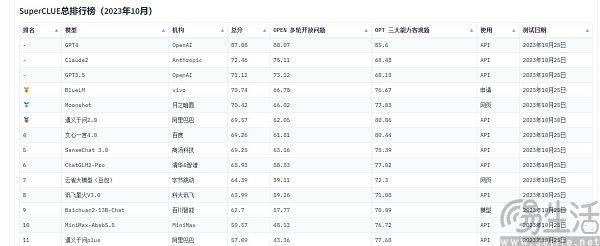
以C-Eval為例,在9月初的榜單上,雲天勵飛大模型 " 雲天書 " 排在第一、360排第八,GPT-4卻只能排在第十名。既然標準是可量化的,為什麼會出現反直覺的結果呢?大模型跑分榜單之所以會呈現出「群魔亂舞」的景象,其實是目前評價AI大模型表現的方法有局限性,它們是用「做題」的方式來衡量大模型的能力。
眾所周知,智慧型手機的SoC、電腦的CPU和顯示卡為了保護自身壽命,在高溫情況下會自動降頻,而低溫則能提升晶片效能。因此,有些人會將手機放入冰箱中,或為電腦配備更強大的散熱系統來進行效能測試,通常能得到比正常狀態下更高的成績。此外,各大手機廠商也會進行“專屬優化”,針對各類跑分軟體,這已經成為他們的標準操作了
同樣道理,人工智慧大模型的評分以做題為核心,自然會有一個題庫。沒錯,國內一些大模型不斷上榜的原因就在於這一點。由於各種原因,目前各大模型榜單的題庫對廠商幾乎是單向透明的,也就是出現了所謂的「基準洩漏」。例如,C-Eval榜單在剛上線時就有13948道題目,並且由於題庫有限,出現了讓某些不知名大模型通過刷題的方式“通關”的情況
大家可以想像一下,在考試之前,如果偶然看到了考捲和標準答案,然後突擊背題,考試成績將會大幅提高。因此,將大模型榜單預設的題庫加入訓練集,這樣一來大模型就成為了擬合基準資料的模型。而且,目前的LLM本身就以出色的記憶力而著稱,背誦標準答案簡直就是小菜一碟
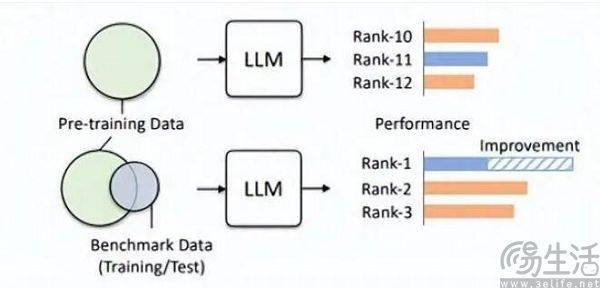
透過這個方式,小尺寸模型在跑分中也能擁有比大尺寸模型更好的結果,部分大模型所取得的高分就是在這樣的「微調」下實現。人大高瓴團隊在論文《Don't Make Your LLM an Evaluation Benchmark Cheater》中,就直白地指明了此類現象,而且這種投機取巧的做法對於大模型的性能反而是有害的。
高瓴團隊的研究人員發現,基準洩漏會導致大模型跑出誇張的成績,例如1.3B的模型可以在某些任務上超越10倍體量的模型,但副作用就是這些專門為「應試「設計的大模型,在其他正常測試任務上的表現會受到不利影響。畢竟想想也能知道,AI大模型本來應該是“做題家”、卻變成了“背題家”,為了獲得某榜單的高分,去使用該榜單特定的知識和輸出樣式,肯定就會誤導大模型。

訓練集、驗證集、測試集的不交叉顯然只是理想狀態,畢竟現實很骨感,資料外洩問題從根源幾乎不可避免。隨著相關技術的不斷進步,當下大模型的基石Transformer結構的記憶和接收能力不斷提升,今年夏季微軟研究院General AI的策略就已經實現了讓模型接收1億Tokens、而不會產生無法接受的遺忘。換而言之,未來AI大模型很有可能具有讀取整個互聯網的能力。
即使拋開技術進步,單純以當下的技術水平,數據污染其實也難以規避,因為優質數據總歸是稀缺、且產能有限的。 AI研究團隊Epoch在今年年初發表的論文就表明,AI不出5年就會把人類所有的高質量語料用光,而且這一結果是其將人類語言數據增長率,即全體人類未來5年內出版的書籍、撰稿的論文、寫的程式碼都考慮在內,預測的結果。
如果一個資料集適合用於評估的話,那麼它在預訓練方面肯定也能夠發揮更好的作用。例如,OpenAI的GPT-4就使用了權威的推理評估資料集GSM8K。因此,目前在大型模型評估領域存在一個尷尬的問題,大型模型對數據的需求似乎沒有止境,這導致評估機構必須比人工智慧大型模型製造商更快、更遠地前進。然而,現如今評估機構似乎根本沒有能力做到這一點
至於說為什麼某些廠商會在大模型跑分上格外上心,紛紛去操作刷榜呢?其實這行為背後的邏輯,就跟App開發者為自家App的用戶量注水一模一樣。畢竟App的用戶規模是衡量其價值的關鍵要素,而在當下這個AI大模型的起步階段,評測榜單的成績幾乎就是唯一一個相對客觀的評判標尺,畢竟在大眾的認知裡跑分高就等於性能強。
當刷榜可能帶來強烈的宣傳效應,甚至可能會為融資打下基礎的情況下,商業利益的加入就必然會驅使AI大模型廠商爭先恐後去刷榜了。
以上是一言不合就跑分,國內AI大模型為何沉迷於'刷榜”的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 2023年最新顯示卡效能排名列表
Jan 05, 2024 pm 11:12 PM
2023年最新顯示卡效能排名列表
Jan 05, 2024 pm 11:12 PM
2023最新顯示卡跑分排行榜已經發布,關注顯示卡天梯圖的用戶們都可以來看看,最近隨著顯卡廠商不斷的發布新顯卡,甚至還有老系列的推陳出新,新的榜單已經完全不一樣了~2023最新顯示卡跑分排行榜顯示卡天梯排行2023年電腦顯示卡選購建議:1、低階顯示卡:RTX3050、5600XT、2060S都是不錯的入門之選相當於買顯卡送CPU,可用於玩LOL、 Cf、鬥陣特攻等輕量級3D網遊,性價比突出,2、入門顯示卡:3060,適合多數一般的主流3D遊戲,中低畫質吃雞。 3.中階顯示卡:NVIDIA:RTX3060Ti、RTX2
 麒麟9000S解鎖跑分曝光:令人驚嘆的性能超越預期
Sep 05, 2023 pm 12:45 PM
麒麟9000S解鎖跑分曝光:令人驚嘆的性能超越預期
Sep 05, 2023 pm 12:45 PM
華為最新發布的Mate60Pro手機在國內市場開售後,引起了廣泛關注。然而,最近在跑分平台上出現了一些關於該機搭載的麒麟9000S處理器效能的爭議。根據平台的測試結果顯示,麒麟9000S的跑分並不完整,其中GPU跑分存在缺失,導致一些跑分軟體無法適配根據網上曝光的信息顯示,麒麟9000S在解鎖跑分測試中取得了驚人的950935分的總分。具體來看,CPU跑分高達279677分,而先前缺少的GPU跑分則為251152分。與先前安兔兔官方測試的總分699783分相比,這顯示出麒麟9000S在性能方面的
 AI大模型浪潮下算力需求爆增,商湯「大模型+大算力」賦能多元產業發展
Jun 09, 2023 pm 07:35 PM
AI大模型浪潮下算力需求爆增,商湯「大模型+大算力」賦能多元產業發展
Jun 09, 2023 pm 07:35 PM
近日,以「AI引領時代,算力驅動未來」為主題的「臨港新片區智算大會」舉行。會上,新片區智算產業聯盟正式成立,商湯科技作為算力提供企業成為聯盟一員,同時商湯科技被授予「新片區智算產業鏈鍊主」企業。作為臨港算力生態的積極參與者,商湯目前已建造了亞洲目前最大的智慧運算平台之一——商湯AIDC,可以輸出5000Petaflops的總算力,可支援20個千億參數量的超大模型同時訓練。以AIDC為底座、前瞻打造的商湯大裝置SenseCore,致力於打造高效率、低成本、規模化的下一代AI基礎設施與服務,賦能人工
 研究者:AI模型推理環節耗電較多,2027年產業用電將堪比荷蘭
Oct 14, 2023 am 08:25 AM
研究者:AI模型推理環節耗電較多,2027年產業用電將堪比荷蘭
Oct 14, 2023 am 08:25 AM
IT之家10月13日消息,《Cell》的姊妹期刊《Joule》本週出版了一篇名為《持續成長的人工智能能源足跡(Thegrowingenergyfootprintofartificialintelligence)》論文。透過查詢,我們了解到這篇論文是由科學研究機構Digiconomist的創辦人AlexDeVries發表的。他聲稱未來人工智慧的推理性能可能會消耗大量的電力,預計到2027年,人工智慧的用電量可能會相當於荷蘭一年的電力消耗量AlexDeVries表示,外界一向認為訓練一個AI模型「AI最
 OPPO Reno11 F現身Geekbench:搭載天璣7050
Feb 06, 2024 pm 11:10 PM
OPPO Reno11 F現身Geekbench:搭載天璣7050
Feb 06, 2024 pm 11:10 PM
2月6日消息,根據媒體報道,OPPO去年發布了OPPOReno11系列,提供標準版和Pro版兩種版本,如今OPPO還將帶來Reno11系列的新版本——Reno11F。目前,OPPOReno11F已經現身Geekbench6資料庫,新機單核跑分897分,多核心跑分2329分。根據基準測試,新機搭載的是聯發科天璣7050SoC,搭配Mali-G68MC4GPU和8GBRAM,出廠預裝基於Android14打造的ColorOS14系統。根據爆料,OPPOReno11F將採用一塊6.7吋的A
 中國聯通發布圖文AI大模型,可實現以文生圖、影片剪輯
Jun 29, 2023 am 09:26 AM
中國聯通發布圖文AI大模型,可實現以文生圖、影片剪輯
Jun 29, 2023 am 09:26 AM
驅動中國2023年6月28日消息,今日在上海世界行動通訊大會期間,中國聯通發布圖文大模型「鴻湖圖文大模型1.0」。中國聯通稱,鴻湖圖文大模型是首個針對營運商增值業務的大模型。第一財經記者了解到,鴻湖圖文大模型目前擁有8億訓練參數和20億訓練參數兩個版本,可以實現以文生圖、影片剪輯、以圖生圖等功能。此外,中國聯通董事長劉烈宏在今天的主題演講中也表示,生成式AI正在迎來發展的奇點,未來2年內50%的工作將受到人工智慧深刻影響。
 一加Ace 3V現身Geekbench平台:全球首發驍龍7+ Gen3
Mar 12, 2024 pm 10:34 PM
一加Ace 3V現身Geekbench平台:全球首發驍龍7+ Gen3
Mar 12, 2024 pm 10:34 PM
3月12日消息,一加Ace3V手機目前已經現身Geekbench跑分平台,型號為PJF110。在Geekbench6跑分中,一加Ace3V取得了最高單核1848、多核5007的分數,並於Geekbench5中取得了單核1416、多核4829的分數,接近天璣9200+。據悉,一加Ace3V將會全球首發驍龍7+Gen3行動平台,基於台積電4nm製程製程製造,採用「1+4+3」的核心配置,其中Cortex-X4超大核心頻率為2.9GHz,整合Adreno732GPU。續航力方面,該機配備55
 四倍提速,位元組跳動開源高性能訓練推理引擎LightSeq技術揭秘
May 02, 2023 pm 05:52 PM
四倍提速,位元組跳動開源高性能訓練推理引擎LightSeq技術揭秘
May 02, 2023 pm 05:52 PM
Transformer模型出自Google團隊2017年發表的論文《Attentionisallyouneed》,該論文中首次提出了使用Attention取代Seq2Seq模型循環結構的概念,為NLP領域帶來了極大衝擊。而隨著近年來研究的不斷推進,Transformer相關技術逐漸由自然語言處理流向其他領域。截止目前,Transformer系列模型已經成為了NLP、CV、ASR等領域的主流模型。因此,如何更快地訓練和推理Transformer模型已成為業界的重要研究方向。低精度量化技術能夠
