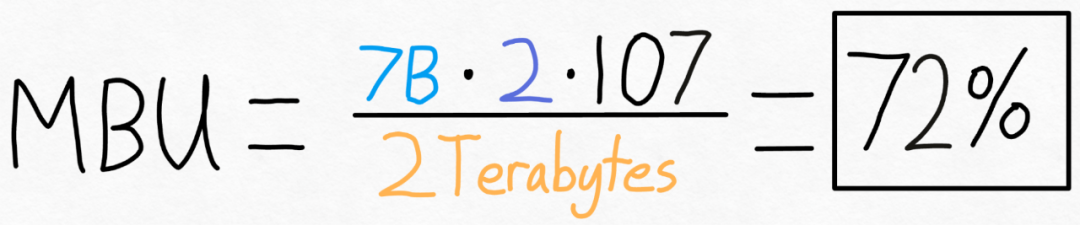在過去的一年裡,生成式AI 發展迅猛,在這當中,文本生成一直是一個特別受歡迎的領域,很多開源專案如llama.cpp、vLLM 、 MLC-LLM 等,為了取得更好的效果,都在進行不停的最佳化。 作為機器學習社群中最受歡迎框架之一的 PyTorch,自然也是抓住了這一新的機遇,不斷優化。為此讓大家更好的了解這些創新,PyTorch 團隊專門設置了系列博客,重點介紹如何使用純原生 PyTorch 加速生成式 AI 模型。 
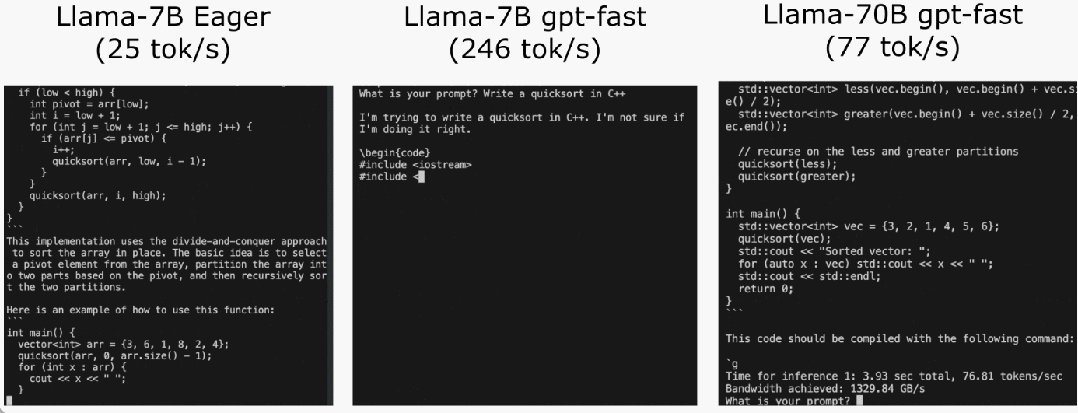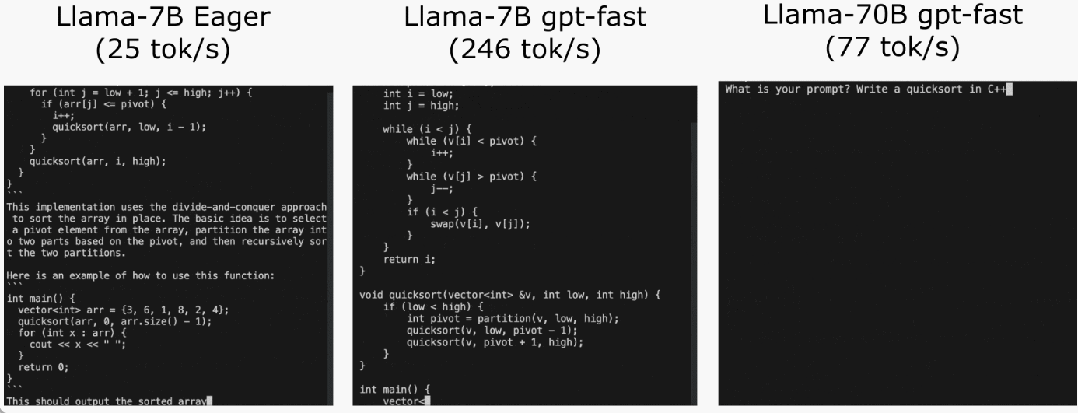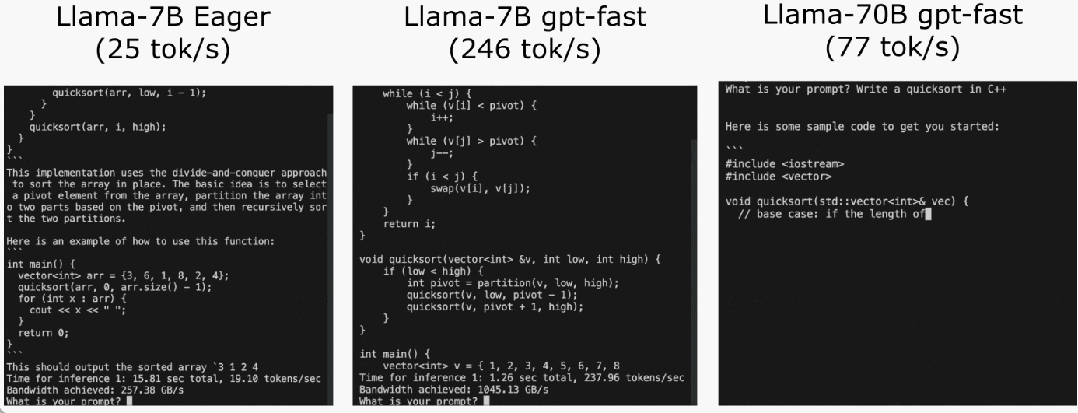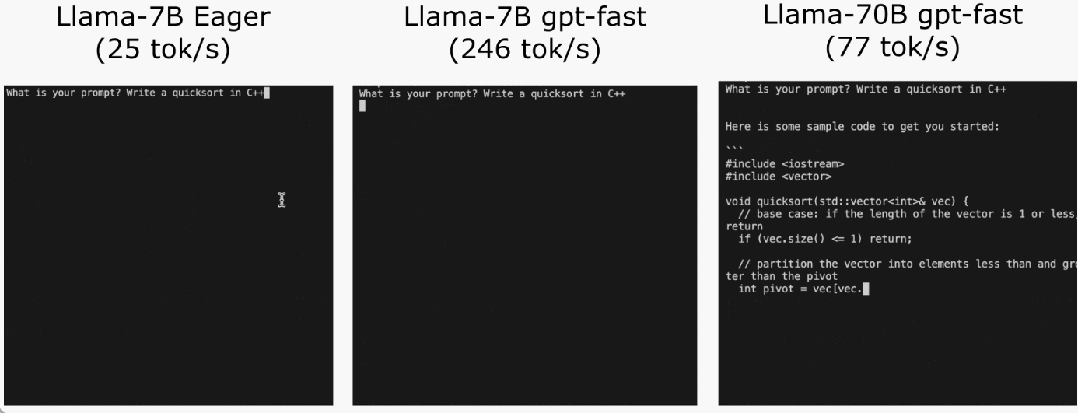
程式碼位址:https://github.com/pytorch-labs/gpt-fast我們先來看看結果,團隊重寫LLM,推理速度比基線足足快了10 倍,並且沒有損失準確率,只用了不到1000 行的純原生PyTorch 程式碼!
所有基準測試都在 A100-80GB 上運行的,功率限制在 330W。
- Torch.compile: PyTorch 模型編譯器, PyTorch 2.0 加入了一個新的函數,稱為torch.compile (),能夠透過一行程式碼對現有的模型進行加速;
- Speculative Decoding:一個大模型推理加速方法,使用一個小的「draft」模型來預測大的「目標」模型的輸出;
- 張量並行:透過在多個裝置上運行模型來加速模型推理。
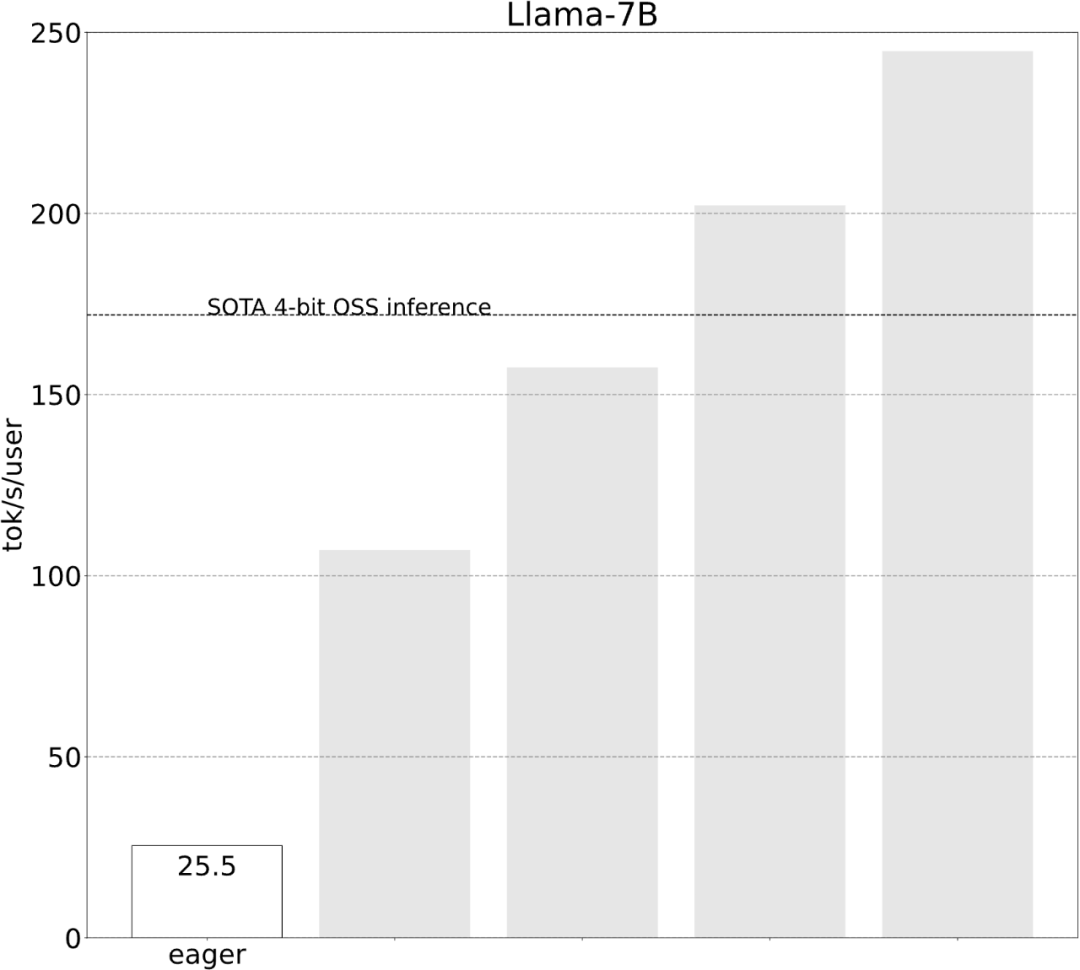
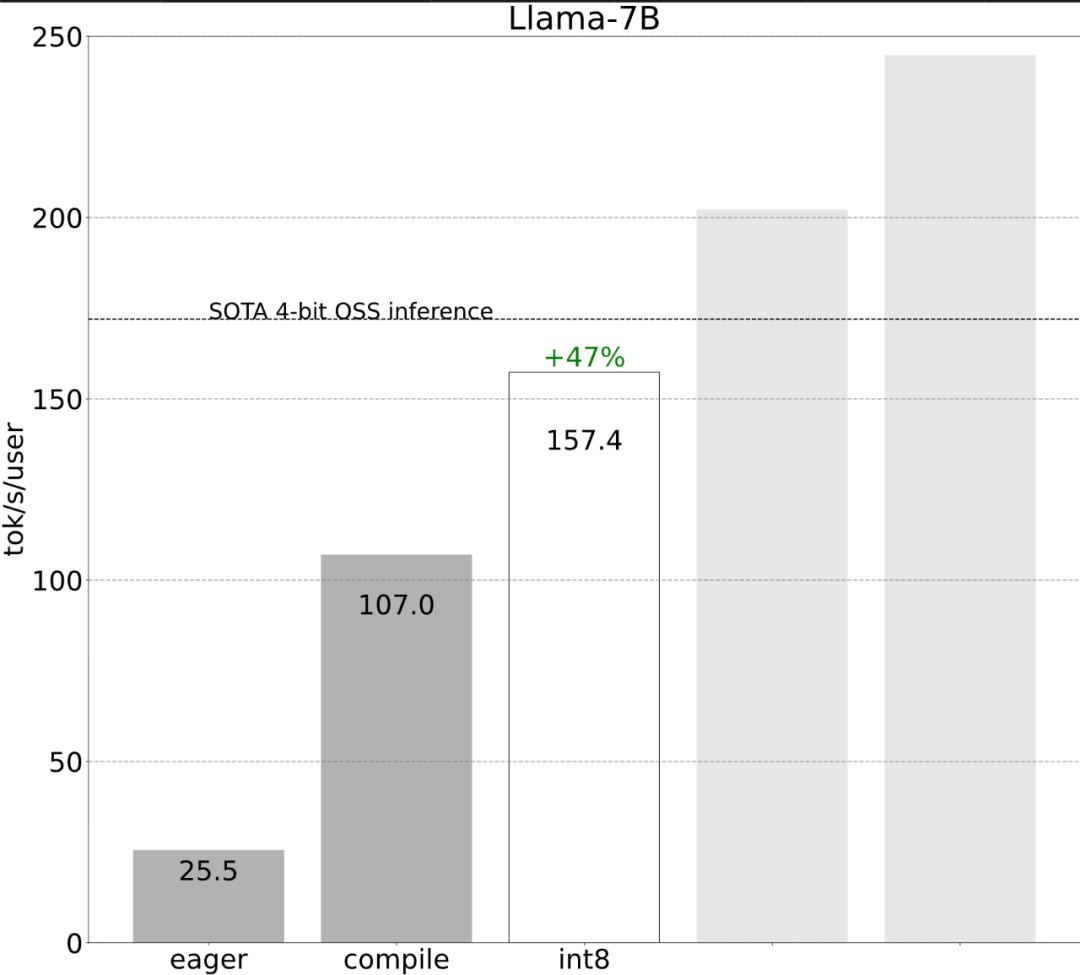
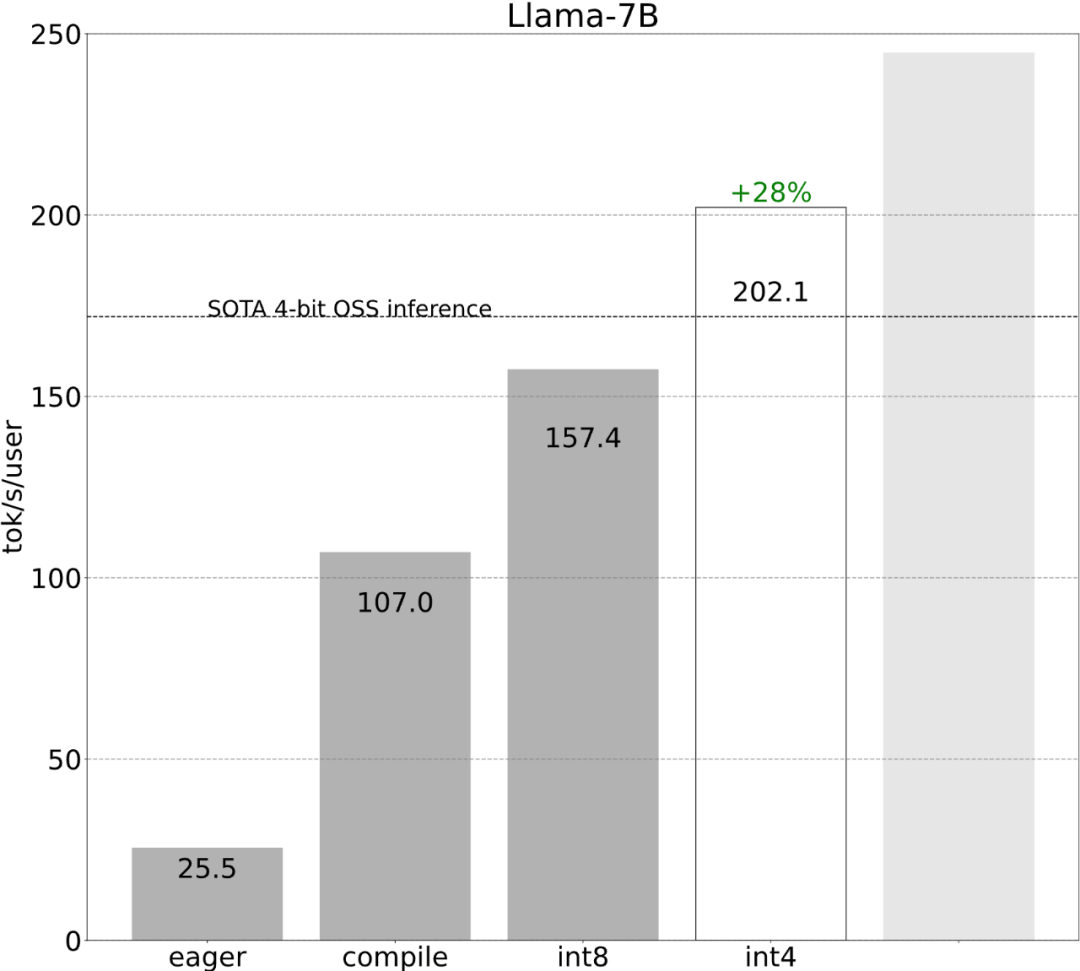
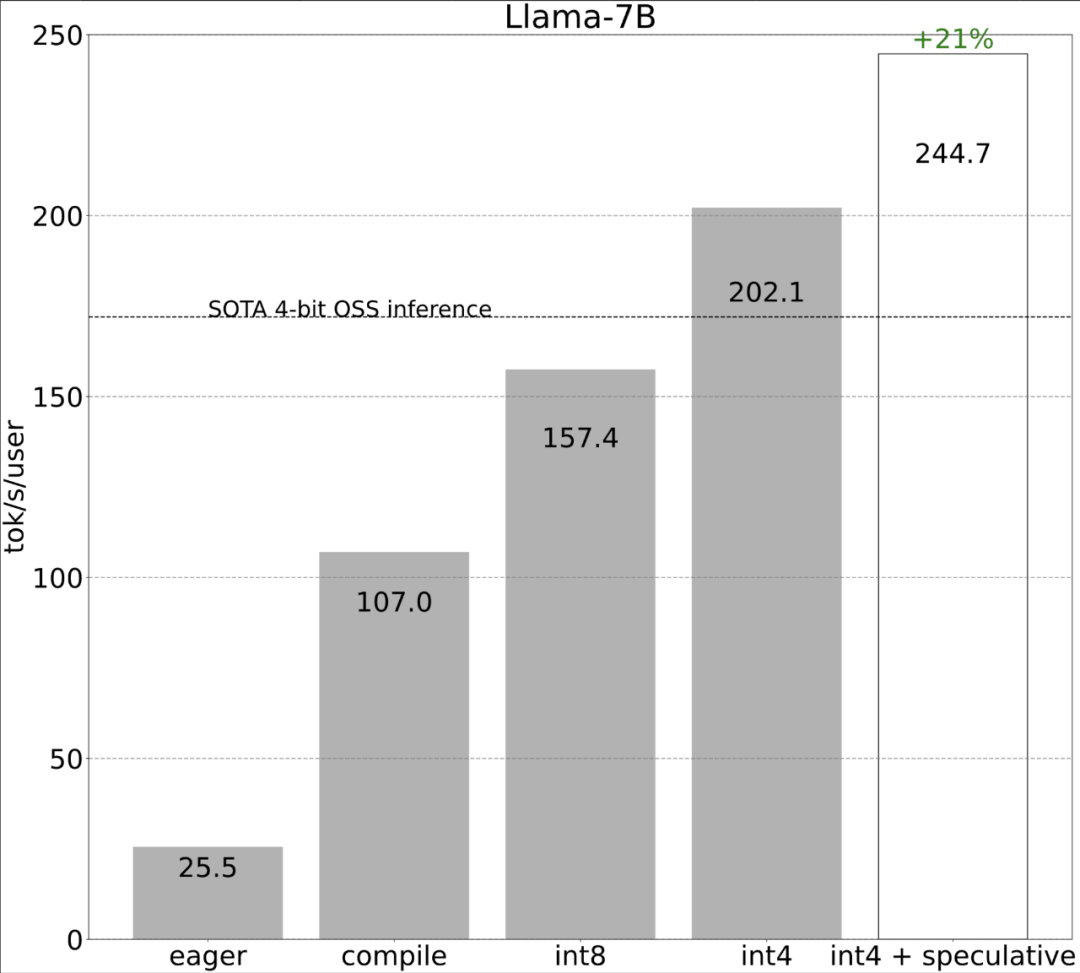
該研究表示,在沒有最佳化之前,大模型的推理表現為25.5 tok/s,效果不是很好:
經過一番探索後終於找到了原因:CPU 開銷過大。然後就有了下面的 6 步驟優化流程。
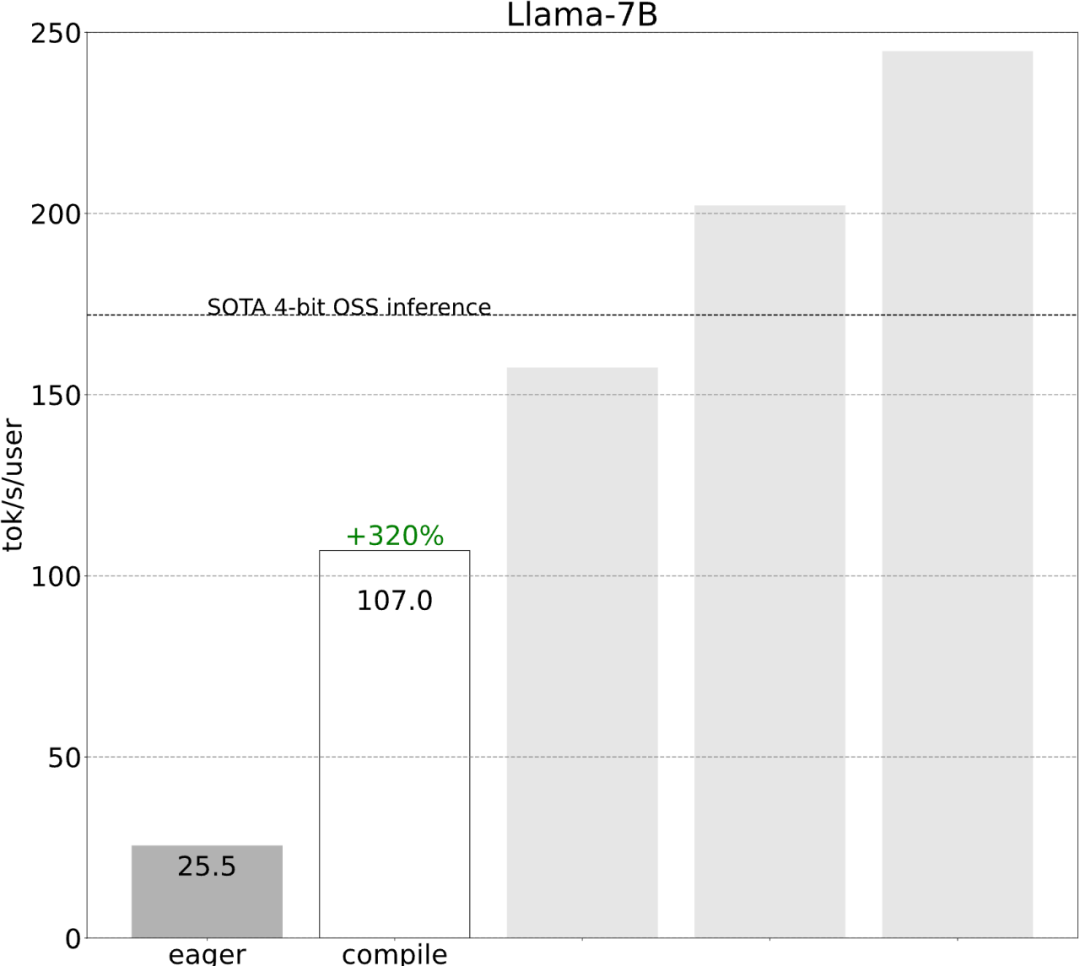
第一步:透過Torch.compile 和靜態KV 快取減少CPU 開銷,實現107.0 TOK/S#torch.compile 允許使用者將更大的區域捕獲到單一編譯區域中,特別是在mode=”reduce-overhead” 時(參考下面的程式碼),這一功能對於減少CPU 開銷非常有效,除此之外,本文還指定fullgraph=True,用來驗證模型中沒有「圖形中斷」(即torch.compile 無法編譯的部分)。
然而,即使有 torch.compile 的加持,還是會遇到一些障礙。 第一個障礙是 kv 快取。即當使用者產生更多的 token 時, kv 快取的「邏輯長度(logical length)」會成長。造成這種問題有兩個原因:一是每次快取成長時重新分配(和複製)kv 快取的成本非常高;其次,這種動態分配使得減少開銷變得更加困難。 為了解決這個問題,本文使用靜態 KV 緩存,靜態分配 KV 快取的大小,然後屏蔽掉注意力機制中未使用的值。
第二個障礙是 prefill 階段。用Transformer 進行文字產生可視為一個兩階段過程:1. 用來處理整個提示的prefill 階段2. 解碼token.儘管kv 快取被設定為靜態化,但由於提示長度可變,prefill 階段仍需要更多的動態性。因此,需要使用單獨的編譯策略來編譯這兩個階段。
雖然這些細節有點棘手,但實現起來並不困難,而且效能的提升是巨大的。這一通操作下來,效能提高了 4 倍多,從 25 tok/s 提高到 107 tok/s。
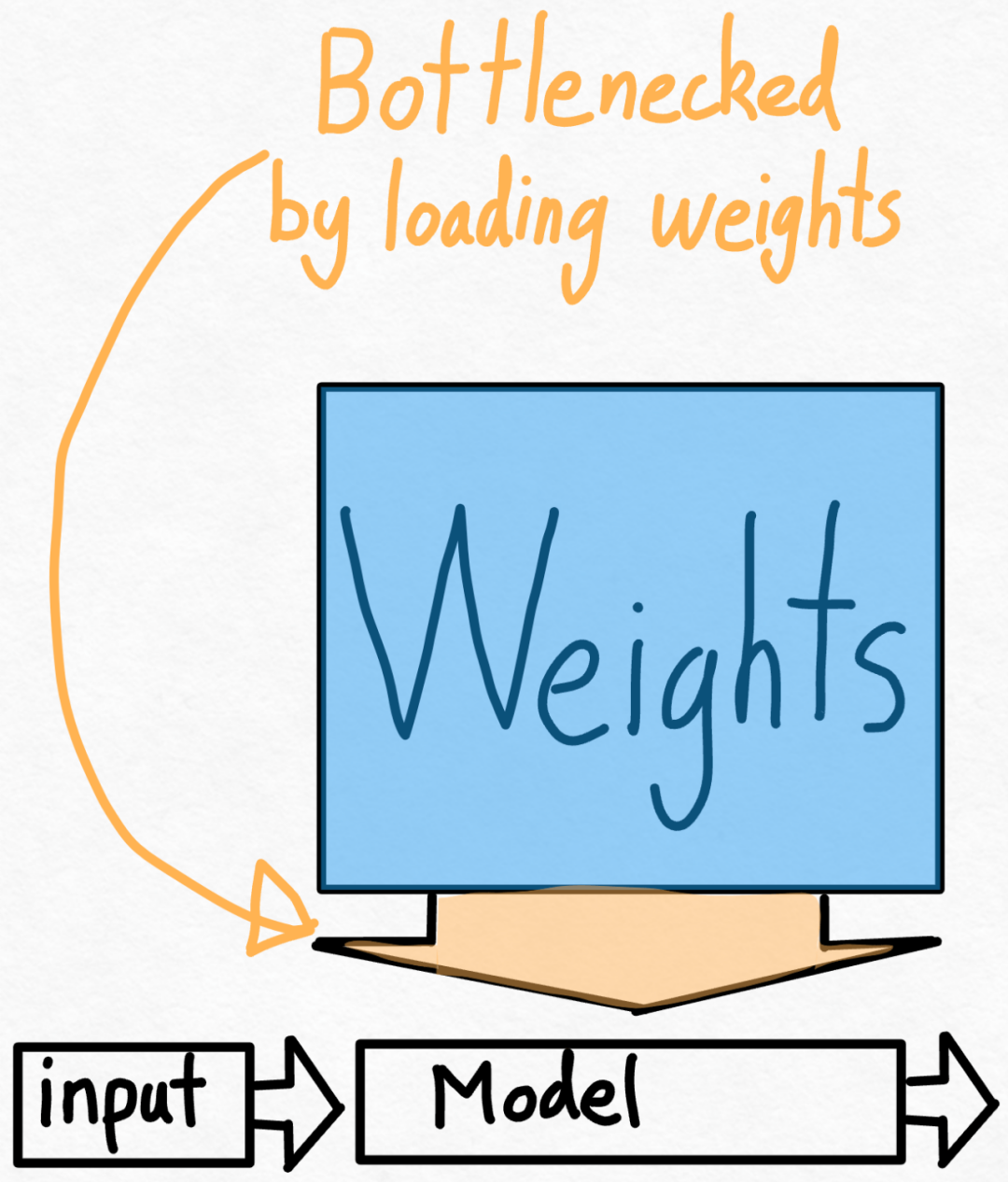
第二步:透過int8 權重化緩解記憶體頻寬瓶頸,實現157.4 tok /s透過上文,我們已經看到應用torch.compile 、靜態kv 快取等帶來的巨大加速,但PyTorch 團隊並不滿足於此,他們又找了其他角度進行最佳化。 他們認為加速生成式 AI 訓練的最大瓶頸是將權重從 GPU 全域記憶體載入到暫存器的代價。換句話說,每次前向傳播都需要「接觸(touch)」GPU 上的每個參數。那麼,理論上我們能夠以多快的速度「接觸」模型中的每個參數?
為了衡量這一點,本文使用模型頻寬利用率(MBU),計算它非常簡單,如下所示:
舉例來說,對於一個7B 參數模型,每個參數都儲存在fp16 中(每個參數2 位元組),可以實現107 tokens/s。 A100-80GB 理論上有 2 TB/s 的記憶體頻寬。 如下圖所示,將上述公式帶入具體的數值,可以得到 MBU 為 72%!這個結果是相當不錯的,因為很多研究很難突破 85%。
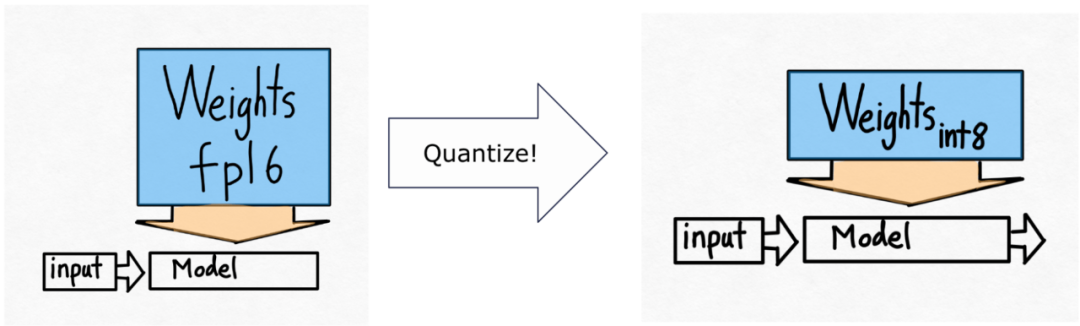
但 PyTorch 團隊也想將這個數值在提高一些。他們發現無法改變模型中參數的數量,也無法改變 GPU 的記憶體頻寬。但他們發現可以更改每個參數儲存的位元組數!
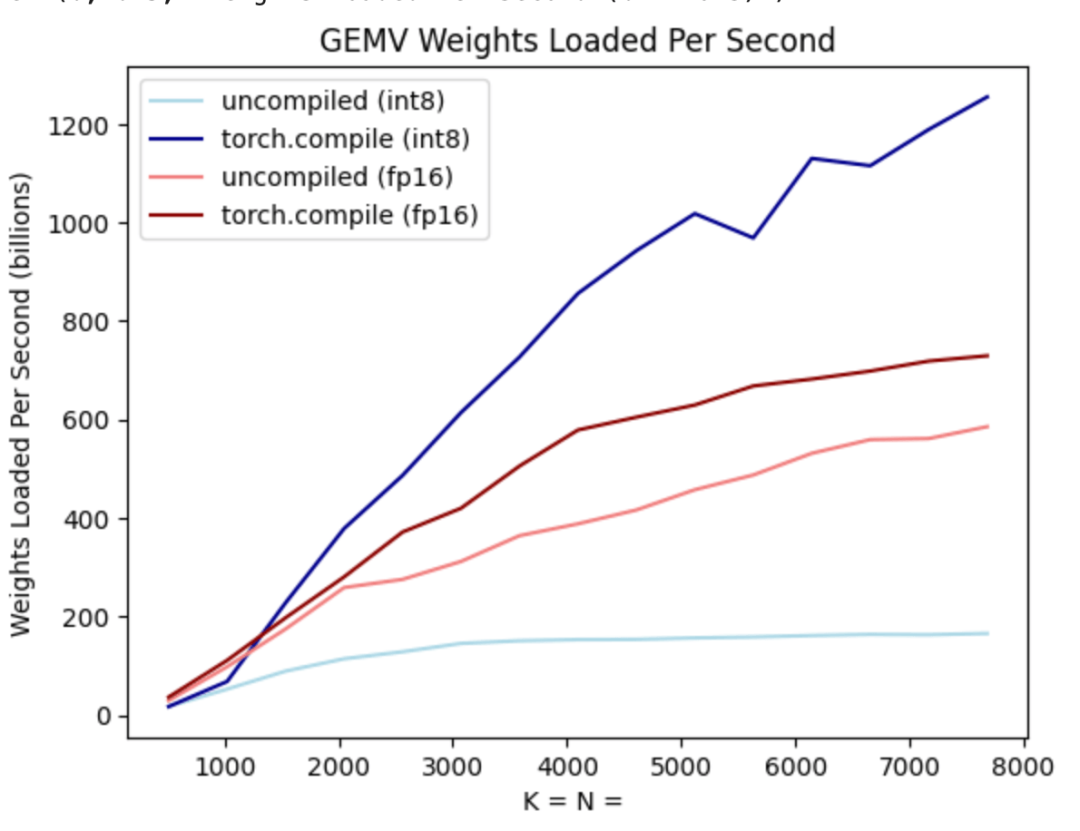
請注意,這只是量化權重,計算本身仍然在 bf16 中完成。此外,有了 torch.compile,可以輕鬆產生 int8 量化的高效率程式碼。
#就像上圖所展示的,從深藍色線(torch.compile int8)可以看出,使用torch.compile int8 僅權重量化時,效能有顯著提升。 將 int8 量化應用於 Llama-7B 模型,效能提高了約 50%,達到 157.4 tokens/s。
第三個步驟:使用Speculative Decoding
#即使在使用了int8 量化等技術之後,團隊仍面臨另一個問題,為了產生100 個token,必須載入權重100 次。
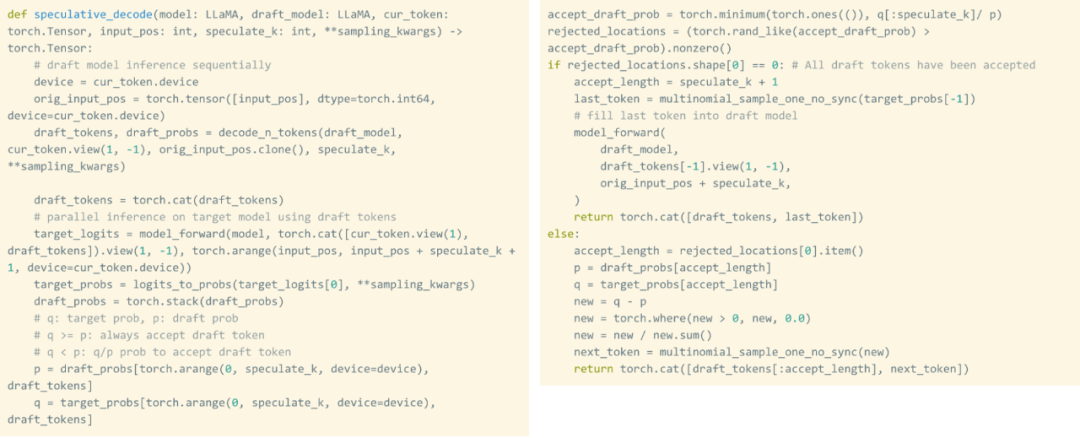
即使權重被量化,一遍又一遍地載入權重也避免不了,這種問題該如何解決?事實證明,利用 speculative decoding 能夠打破這種嚴格的串行依賴並獲得加速。
該研究使用草稿(draft)模型產生 8 個 token,然後使用驗證器模型並行處理,丟棄不匹配的 token。這一過程打破了串行依賴。整個實作過程大約 50 行原生 PyTorch 程式碼。
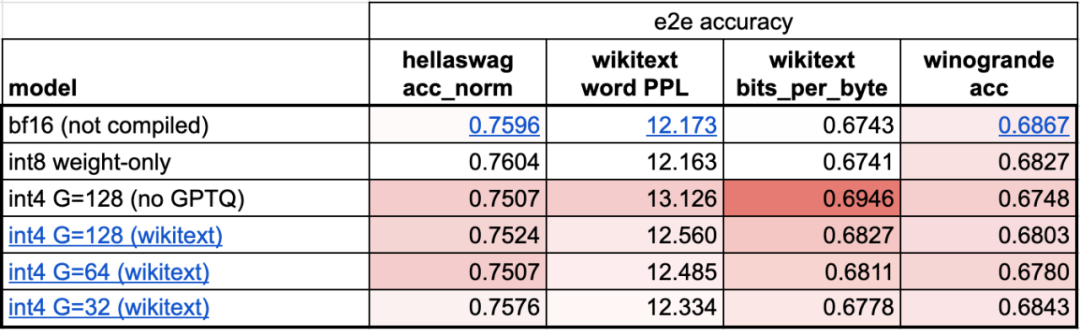
第四步:使用int4 量化和GPTQ 方法進一步減少權重,實作202.1 tok/s本文發現,當權重為4-bits 時,模型的準確率開始下降。
為了解決這個問題,本文使用兩個技巧來解決:第一個是擁有更細緻的縮放因子;另一種是使用更先進的量化策略。將這些操作組合在一起,得到如下:
第五步:將所有內容組合在一起,得到244.7 tok/s 最後,將所有技術組合在一起以獲得更好的性能,得到244.7 tok/s。
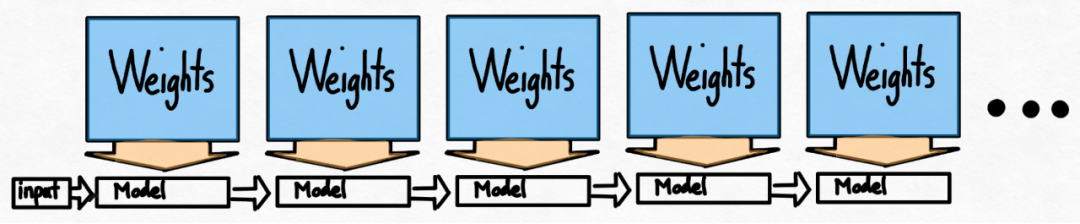
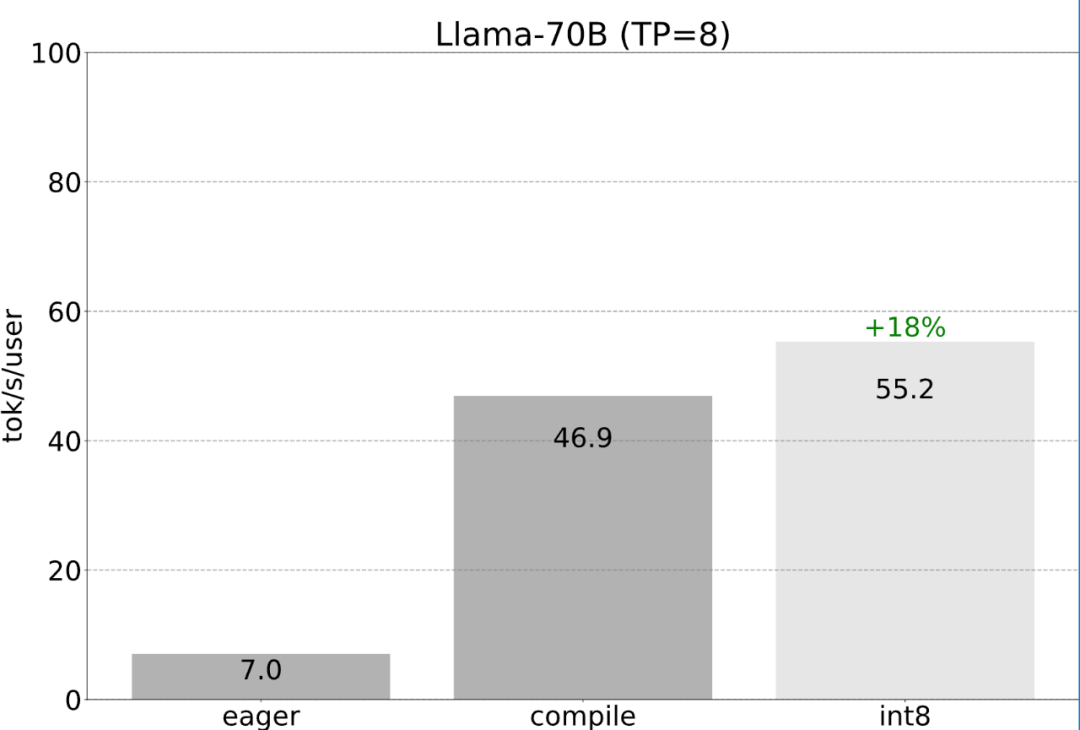
到目前為止,本文一直是在單一GPU 上最大限度地減少延遲。其實,使用多個 GPU 也是可以的,這樣一來,延遲現象會進一步改善。 非常慶幸的是,PyTorch 團隊提供了張量並行的低階工具,只需 150 行程式碼,並且不需要任何模型變更。
前面提到的所有最佳化都可以繼續與張量並行性組合,將這些組合在一起,能以55 tokens/s 的速度為Llama-70B 模型提供int8 量化。
最後,簡單總結文章主要內容。在 Llama-7B 上,本文使用「compile int4 quant speculative decoding」這套組合拳,實作 240 tok/s。在 Llama-70B,本文也透過引入張量並行性以達到約 80 tok/s,這些都接近或超過 SOTA 表現。 原文連結:https://pytorch.org/blog/accelerating-generative-ai-2/以上是不到1000行程式碼,PyTorch團隊讓Llama 7B提速10倍的詳細內容。更多資訊請關注PHP中文網其他相關文章!