

全方位、無死角的開源,邢波團隊LLM360讓大模型實現真正的透明

開源模型正展現著它們蓬勃的生命力,不僅數量激增,性能更是愈發優秀。圖靈獎得主Yann LeCun 也發出了這樣的感嘆:「開源人工智慧模型正走在超越專有模型的路上。」
專有模型在技術性能和創新能力方面表現出了巨大的潛力,但是由於其非開源的特性,阻礙了LLM的發展。一些開源模型雖然為從業者和研究者提供了多樣化的選擇,但大多數隻公開了最終的模型權重或推理程式碼,越來越多的技術報告將其範圍限制在頂層設計和表面統計之內。這種閉源的策略不僅限制了開源模型的發展,而且在很大程度上阻礙了整個LLM研究領域的進步
這意味著,這些模型需要更全面和深入地分享,包括訓練資料、演算法細節、實現挑戰以及效能評估的細節。
Cerebras、Petuum 和 MBZUAI 等的研究者們共同提出了 LLM360。這是一項全面開源 LLM 的倡議,主張向社區提供與 LLM 訓練相關的一切,包含訓練程式碼和資料、模型檢查點以及中間結果等。 LLM360 的目標是讓 LLM 訓練過程透明化,使每個人都能復現,從而推動開放和協作式的人工智慧研究的發展。

- #論文網址:https://arxiv.org/pdf/2312.06550 .pdf
- 專案網頁:https://www.llm360.ai/
- 部落格:https://www.llm360.ai/blog/introducing-llm360-fully-transparent-open-source-llms.html
#研究者們制定了LLM360 的架構,重點在於其設計原則和完全開源的理由。他們詳細規定了 LLM360 框架的組成部分,包含資料集、程式碼和配置、模型檢查點、指標等具體細節。 LLM360 為目前和未來的開源模型樹立了透明度的樣本。
研究者在 LLM360 的開源框架下發布了兩個從頭開始預先訓練的大型語言模型:AMBER 和 CRYSTALCODER。 AMBER 是基於 1.3T token 進行預訓練的 7B 英語語言模型。 CRYSTALCODER 是基於 1.4T token 預訓練的 7B 英語和代碼語言模型。在本文中,研究者們總結了這兩個模型的開發細節、初步評估結果、觀察結果以及從中汲取的經驗和教訓。值得注意的是,在發佈時,AMBER 和 CRYSTALCODER 在訓練過程中分別保存了 360 個和 143 個模型檢查點。

下面,我們一起來看看文章的詳細內容吧
LLM360 的框架
LLM360 將為LLM 預訓練過程中需要收集哪些資料和程式碼提供一個標準,以確保現有的工作能更好地在社區中流通、共享。它主要包含以下幾個部分:
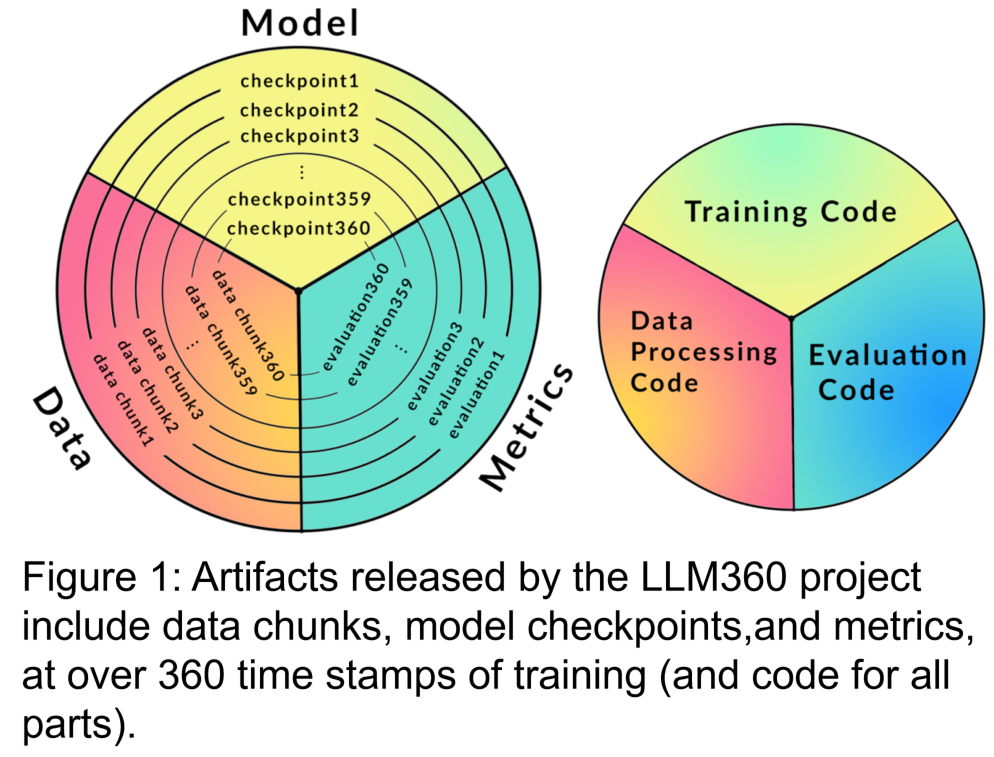
#1. 訓練資料集和資料處理程式碼
預訓練資料集對大型語言模型的效能至關重要。因此,了解預訓練資料集,用以評估潛在的行為問題和偏見非常重要。此外,公開的預訓練資料集有助於提高 LLM 在後續微調和適應各領域時的可擴展性。最近的研究表明,在重複資料上進行訓練會不成比例地降低模型最終的表現。因此,公開原始預訓練數據,有助於避免在下游微調或繼續在特定領域進行預訓練時使用到重複的數據。綜合以上原因,LLM360 倡導公開大型語言模型的原始資料集。在適當的情況中,也應公開關於資料過濾、處理和訓練順序的詳細資訊。
需要重新寫作的內容是:2. 訓練程式碼、超參數和設定
訓練程式碼、超參數和配置對 LLM 訓練的效能和品質有重大影響,但並非總是公開揭露。在 LLM360 中,研究者開源預訓練框架的所有訓練程式碼、訓練參數以及系統配置。
3. 模型檢查點重寫為:3.模型檢查點
定期儲存模型檢查點也相當有用。它們不僅對訓練過程中的故障恢復至關重要,而且對訓練後的研究也很有用,這些檢查點可以讓後來的研究者從多個起點繼續訓練模型,無需從頭開始訓練,有助於復現和深入研究。
4. 效能指標
#訓練一個LLM 往往需要花費數週至數月,訓練期間的演化趨勢可以提供有價值的資訊。然而,目前只有親歷者才能獲得訓練的詳細日誌和中間指標,這阻礙了對 LLM 的全面研究。這些統計數據往往包含了難以察覺的關鍵見解。即使是對這些衡量標準進行方差計算這樣的簡單分析,也能揭示重要的發現。例如,GLM 的研究團隊就是透過分析梯度規範行為,提出了一種有效處理損失尖峰和 NaN 損失的梯度收縮演算法。
Amber
AMBER 是LLM360 「大家庭」的第一位成員,同時發布的還有它的微調版本:AMBERCHAT 和AMBERSAFE 。

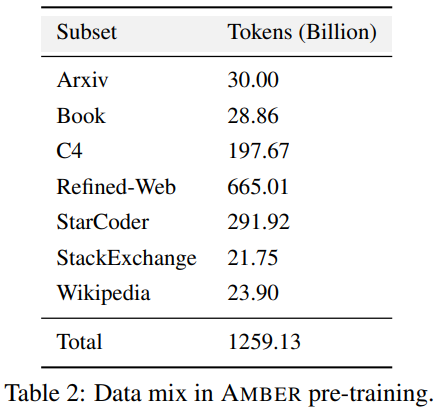
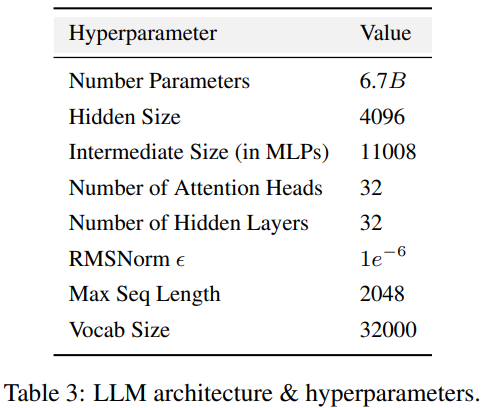
AMBER採用了與LLaMA 7B4相同的模型結構,表3總結了LLM的詳細結構配置
 #在預訓練和超參數方面,研究人員盡力遵循了LLaMA的預訓練超參數。 AMBER使用AdamW優化器進行訓練,超參數為:β₁=0.9,β₂=0.95。此外,研究人員還發布了幾個AMBER的微調版本:AMBERCHAT和AMBERSAFE。 AMBERCHAT是基於WizardLM的指令訓練資料集進行微調的。有關更多參數細節,請參閱原文
#在預訓練和超參數方面,研究人員盡力遵循了LLaMA的預訓練超參數。 AMBER使用AdamW優化器進行訓練,超參數為:β₁=0.9,β₂=0.95。此外,研究人員還發布了幾個AMBER的微調版本:AMBERCHAT和AMBERSAFE。 AMBERCHAT是基於WizardLM的指令訓練資料集進行微調的。有關更多參數細節,請參閱原文
為了達到不改變原始意義的目的,需要將內容重寫為中文。以下是對"實驗及結果"的重寫: 進行實驗和結果分析
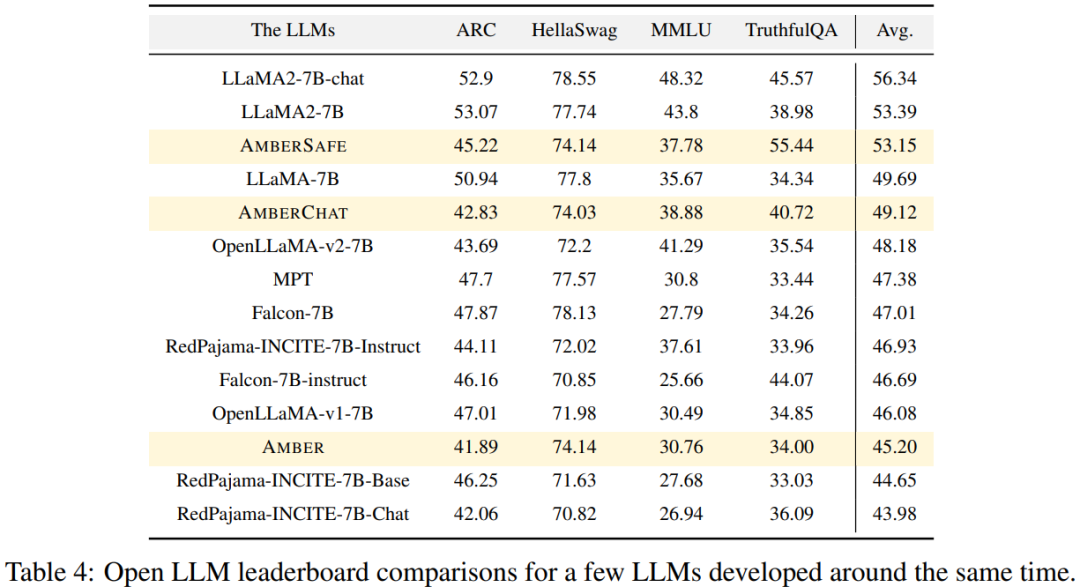
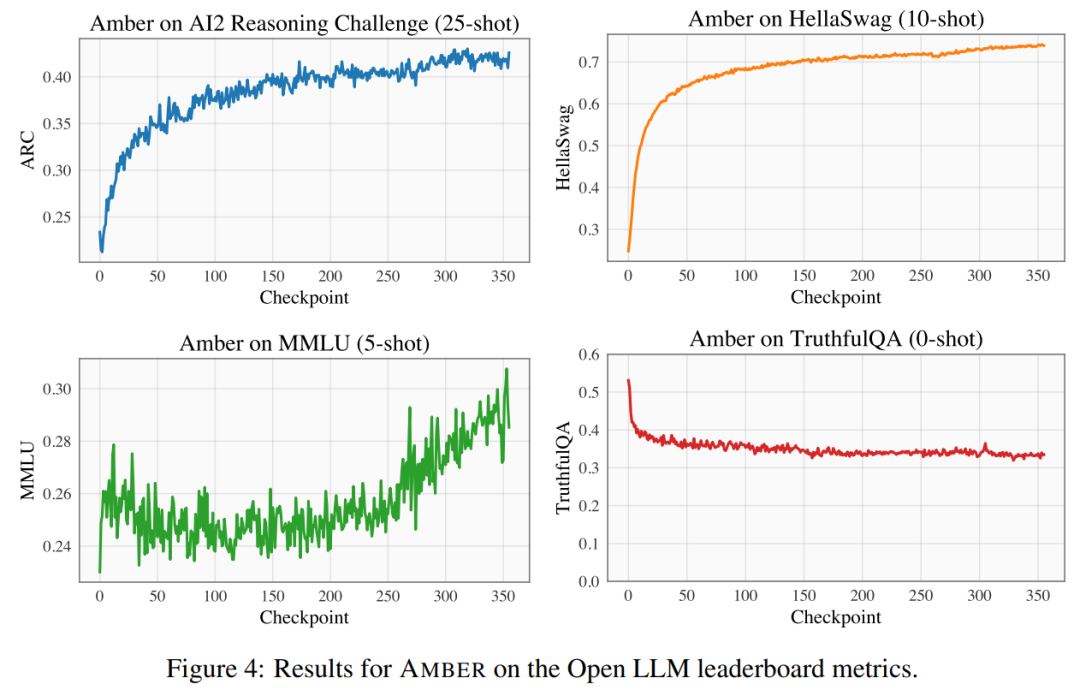
在表4 中,研究者將AMBER 的模型表現與OpenLLaMA、RedPajama-INCITE、Falcon、MPT 等類似時間段內訓練出的模型進行了比較。許多模型的設計靈感都來自 LLaMA 。可以發現,AMBER 在 MMLU 的得分較為出色,但在 ARC 的表現稍遜一籌。與其他類似模型相比,AMBER 的表現相對較強。 
CrystalCoder 是一個基於 1.4 T token 訓練的 7B 語言模型,實現了編碼和語言能力之間的平衡。與大多數先前的程式碼 LLM 不同,CrystalCoder 是透過精心混合文字和程式碼資料進行訓練的,以最大化在這兩個領域的實用性。與 Code Llama 2 相比,CrystalCoder 的程式碼資料在預訓練過程中較早引入。此外,研究者在 Python 和 Web 程式語言上訓練了 CrystalCoder,以提高其作為程式設計助理的實用性。
重新建構模型架構
CrystalCoder 採用了與LLaMA 7B 非常相似的架構,加入了最大更新參數化(muP)。除了這種特定的參數化,研究者也做了一些修改。另外,研究者也使用 LayerNorm 取代 RMSNorm,因為 CG-1 架構支援高效運算 LayerNorm。
為了達到不改變原始意義的目的,需要將內容重寫為中文。以下是對"實驗及結果"的重寫: 進行實驗和結果分析
在Open LLM Leaderboard上,研究者對此模型進行了基準測試,包括四個基準資料集和編碼基準資料集。如圖6所示
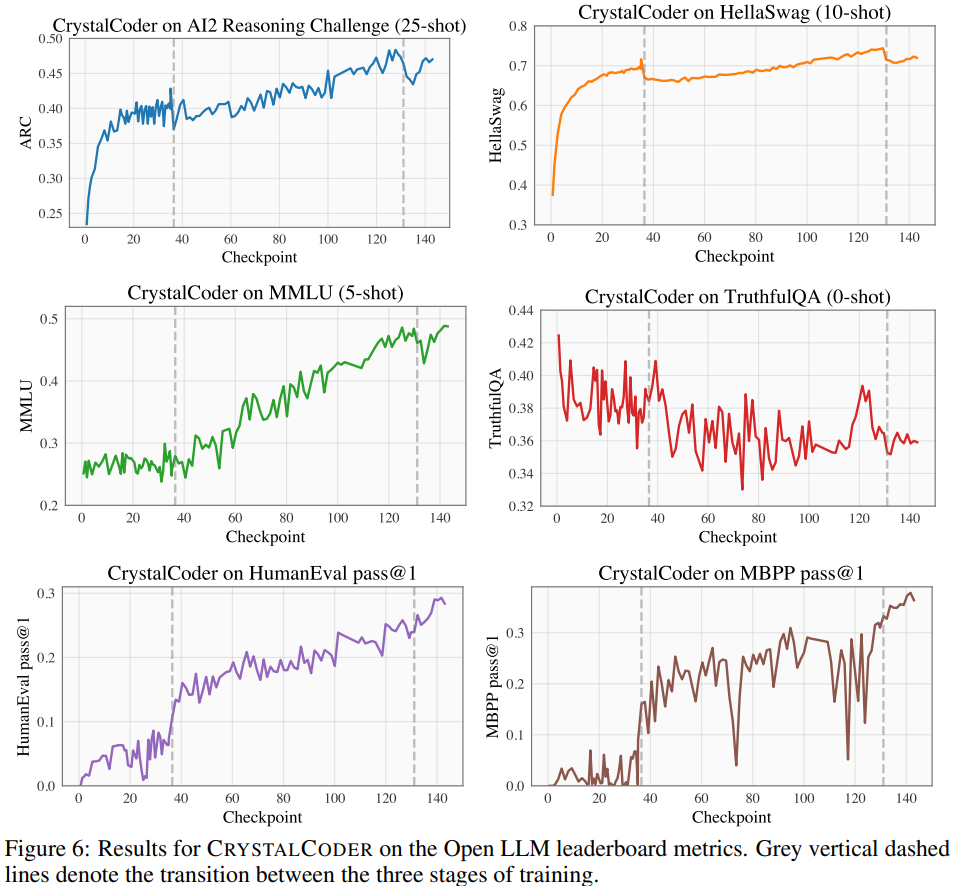
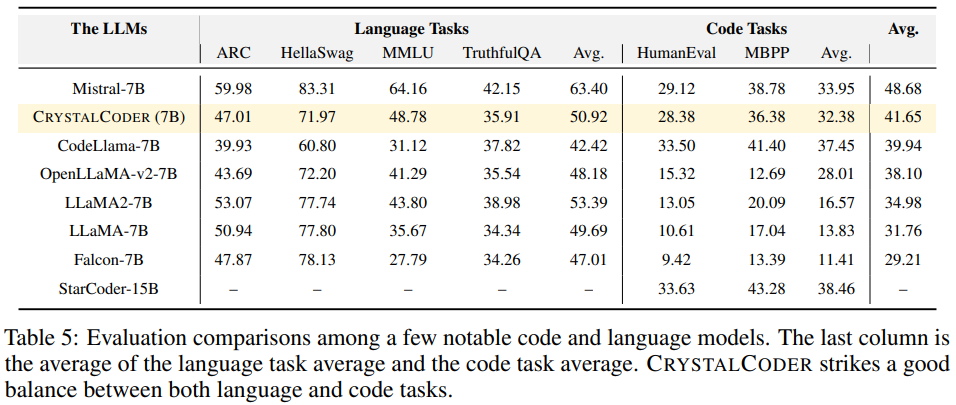
#參考表5,可以看到CrystalCoder在語言任務與程式碼任務之間取得了良好的平衡
#ANALYSIS360
#根據先前的研究,透過分析模型的中間檢查點,可以進行深入研究。研究人員希望LLM360能為社區提供有用的參考和研究資源。為此,他們發布了ANALYSIS360專案的初始版本,這是一個對模型行為進行多方面分析的有組織儲存庫,包括模型特徵和下游評估結果
作為對一系列模型檢查點進行分析的範例,研究者對LLM中的記憶化進行了初步研究。最近的研究顯示,LLM可能會記憶大部分訓練數據,並且透過適當的提示可以提取這些數據。這種記憶化不僅存在著洩漏私人訓練資料方面的問題,而且如果訓練資料包含重複或特殊性,還會降低LLM的效能。研究者公開了所有檢查點和數據,以便可以對整個訓練階段的記憶化進行全面分析
以下為本文所採用的記憶化得分方法,該得分錶示在長度為k 的提示後續長度為l 的token 的準確性。具體記憶化得分設置,請參閱原文。
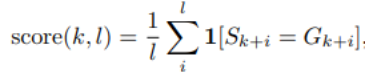
在圖7中呈現了10個選定檢查點的記憶化分數分佈情況
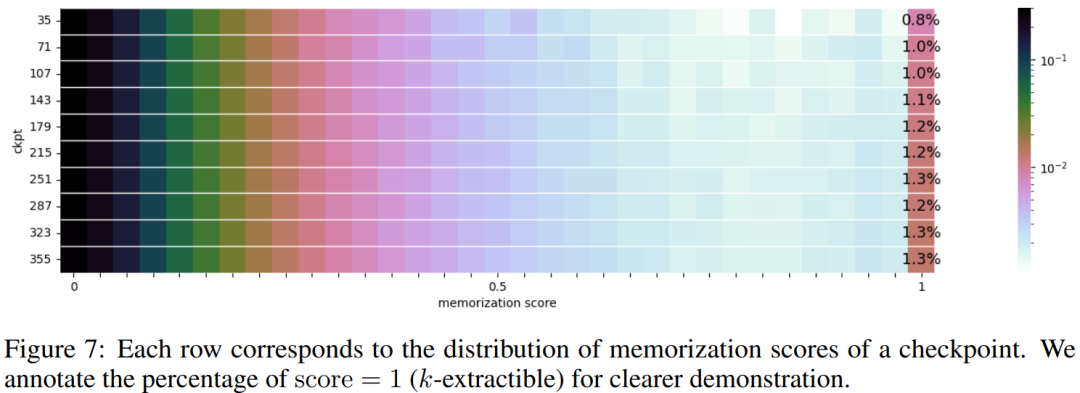
研究者根據所選檢查點將資料區塊分組,並在圖8 中繪製每個檢查點的每個資料區塊組的記憶化分數。他們發現 AMBER 檢查點對最新數據的記憶化程度超過先前的數據。此外對於每個資料區塊,記憶化分數在額外訓練後會略有下降,但之後會持續上升。
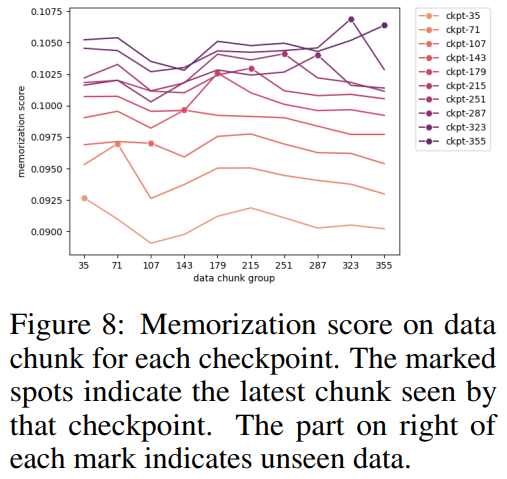
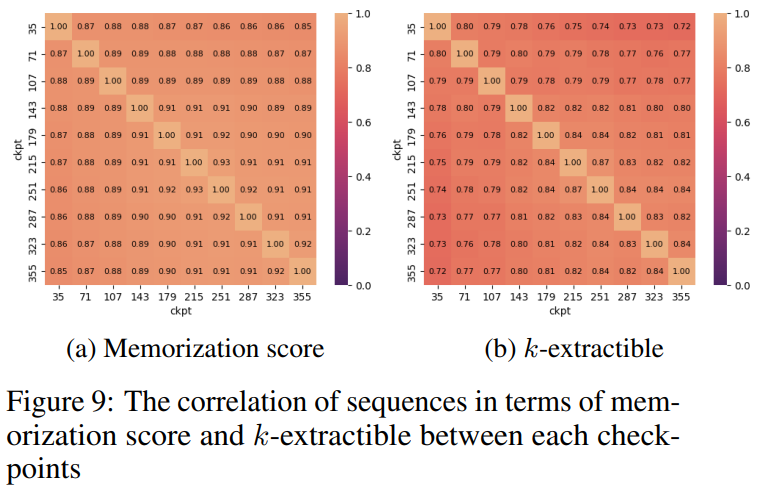
圖 9 展示了序列之間在記憶化分數和可擷取 k 值的相關性。可見,檢查點之間有強烈的相關性。
總結
#研究者總結了對AMBER和CRYSTALCODER的觀察結果和一些啟示。他們表示,預訓練是一項計算量龐大的任務,許多學術實驗室或小型機構都無法負擔。他們希望LLM360能提供全面的知識,讓使用者了解LLM預訓練過程中發生的情況,而無需親自動手
請查看原文以取得更多詳細資訊
以上是全方位、無死角的開源,邢波團隊LLM360讓大模型實現真正的透明的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
Debian郵件服務器防火牆配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian郵件服務器的防火牆是確保服務器安全性的重要步驟。以下是幾種常用的防火牆配置方法,包括iptables和firewalld的使用。使用iptables配置防火牆安裝iptables(如果尚未安裝):sudoapt-getupdatesudoapt-getinstalliptables查看當前iptables規則:sudoiptables-L配置
 debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何與其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系統中的readdir函數是用於讀取目錄內容的系統調用,常用於C語言編程。本文將介紹如何將readdir與其他工具集成,以增強其功能。方法一:C語言程序與管道結合首先,編寫一個C程序調用readdir函數並輸出結果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何實現文件排序
Apr 13, 2025 am 09:06 AM
在Debian系統中,readdir函數用於讀取目錄內容,但其返回的順序並非預先定義的。要對目錄中的文件進行排序,需要先讀取所有文件,再利用qsort函數進行排序。以下代碼演示瞭如何在Debian系統中使用readdir和qsort對目錄文件進行排序:#include#include#include#include//自定義比較函數,用於qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian OpenSSL如何進行數字簽名驗證
Apr 13, 2025 am 11:09 AM
Debian OpenSSL如何進行數字簽名驗證
Apr 13, 2025 am 11:09 AM
在Debian系統上使用OpenSSL進行數字簽名驗證,可以按照以下步驟操作:準備工作安裝OpenSSL:確保你的Debian系統已經安裝了OpenSSL。如果沒有安裝,可以使用以下命令進行安裝:sudoaptupdatesudoaptinstallopenssl獲取公鑰:數字簽名驗證需要使用簽名者的公鑰。通常,公鑰會以文件的形式提供,例如public_key.pe
 Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
Debian郵件服務器SSL證書安裝方法
Apr 13, 2025 am 11:39 AM
在Debian郵件服務器上安裝SSL證書的步驟如下:1.安裝OpenSSL工具包首先,確保你的系統上已經安裝了OpenSSL工具包。如果沒有安裝,可以使用以下命令進行安裝:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私鑰和證書請求接下來,使用OpenSSL生成一個2048位的RSA私鑰和一個證書請求(CSR):openss
 centos關機命令行
Apr 14, 2025 pm 09:12 PM
centos關機命令行
Apr 14, 2025 pm 09:12 PM
CentOS 關機命令為 shutdown,語法為 shutdown [選項] 時間 [信息]。選項包括:-h 立即停止系統;-P 關機後關電源;-r 重新啟動;-t 等待時間。時間可指定為立即 (now)、分鐘數 ( minutes) 或特定時間 (hh:mm)。可添加信息在系統消息中顯示。
 Debian OpenSSL如何防止中間人攻擊
Apr 13, 2025 am 10:30 AM
Debian OpenSSL如何防止中間人攻擊
Apr 13, 2025 am 10:30 AM
在Debian系統中,OpenSSL是一個重要的庫,用於加密、解密和證書管理。為了防止中間人攻擊(MITM),可以採取以下措施:使用HTTPS:確保所有網絡請求使用HTTPS協議,而不是HTTP。 HTTPS使用TLS(傳輸層安全協議)加密通信數據,確保數據在傳輸過程中不會被竊取或篡改。驗證服務器證書:在客戶端手動驗證服務器證書,確保其可信。可以通過URLSession的委託方法來手動驗證服務器
 Debian Hadoop日誌管理怎麼做
Apr 13, 2025 am 10:45 AM
Debian Hadoop日誌管理怎麼做
Apr 13, 2025 am 10:45 AM
在Debian上管理Hadoop日誌,可以遵循以下步驟和最佳實踐:日誌聚合啟用日誌聚合:在yarn-site.xml文件中設置yarn.log-aggregation-enable為true,以啟用日誌聚合功能。配置日誌保留策略:設置yarn.log-aggregation.retain-seconds來定義日誌的保留時間,例如保留172800秒(2天)。指定日誌存儲路徑:通過yarn.n
