

11個基本分佈,資料科學家95%的時間都在使用

繼上次盤點《資料科學家95%的時間都在使用的11個基本圖表》之後,今天將為大家帶來資料科學家95%的時間都在使用的11個基本分佈。掌握這些分佈,有助於我們更深入地理解數據的本質,並在數據分析和決策過程中做出更準確的推論和預測。

1. 常態分佈
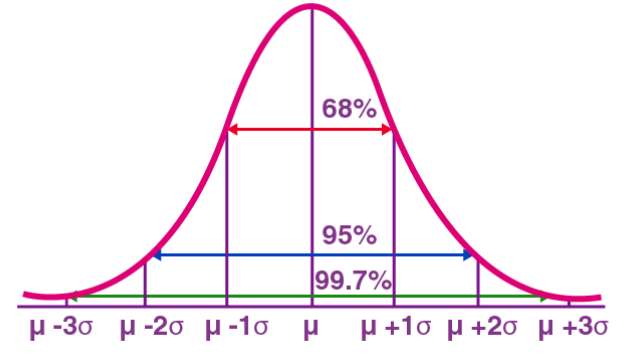
常態分佈(Normal Distribution),也稱為高斯分佈(Gaussian Distribution),是一種連續型機率分佈。它具有一個對稱的鐘形曲線,以平均值(μ)為中心,標準差(σ)為寬度。常態分佈在統計學、機率論、工程學等多個領域具有重要的應用價值。
常態分佈的機率密度函數可以表示為:
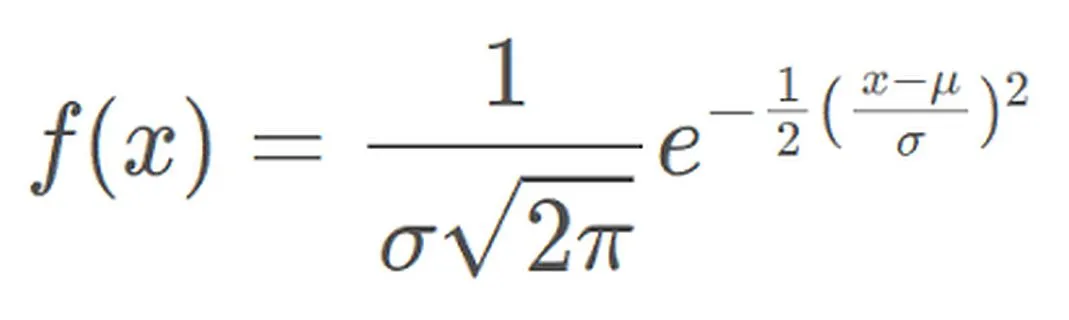
機率密度函數表示在給定值x附近的單位區間內常態分佈的隨機變數取值的機率密度。其中,μ表示平均值,σ表示標準差
常態分佈在實際中的應用是廣泛的。例如,人的身高和體重分佈近似於常態分佈。此外,考試成績通常呈常態分佈,高分和低分的人數較少,而中間分數的人數較多。這種分佈模式在許多領域都有重要的應用價值
2. 伯努利分佈
伯努利分佈(Bernoulli Distribution)是一種離散型機率分佈,用於描述只有兩種可能結果的單次隨機試驗。伯努利試驗可以是正面或反面,成功或失敗,是或否等。例如,拋硬幣、檢測產品是否合格、某人是否購買某種產品等。
伯努利分佈的機率品質函數為:
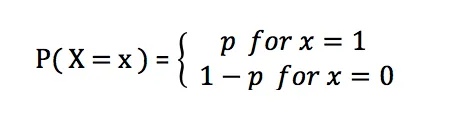
#在伯努利分佈中,p表示成功的機率,其取值範圍為0到1。當p等於0.5時,伯努利分佈就趨近於均勻分佈
伯努利分佈在實際中的應用:例如二項分佈就是伯努利分佈的n次獨立重複試驗。
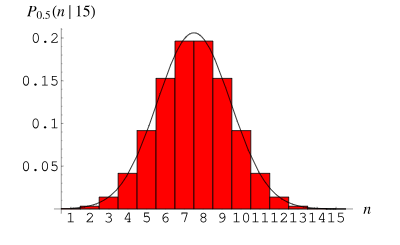
3. 二項分佈
二項分佈(Binomial Distribution)是一種離散型機率分佈,用於描述在n次獨立重複試驗中成功次數的機率分佈。每次試驗只有兩種可能的結果:成功(記為1)或失敗(記為0)。成功的機率為p,失敗的機率為1-p。
二項分佈的機率品質函數可以表示為:
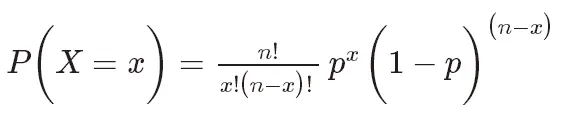
其中,P(X=k)表示成功次數為k的機率,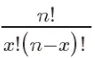 是組合數,表示從n次試驗中選擇k次成功的組合數。 p是成功的機率,取值範圍在0和1之間。 n是試驗次數。
是組合數,表示從n次試驗中選擇k次成功的組合數。 p是成功的機率,取值範圍在0和1之間。 n是試驗次數。
二項分佈在實際中的應用非常廣泛。舉例來說,在醫學研究中,我們可以利用二項分佈來計算患者接受某種治療的成功率。在工程領域中,我們可以使用二項分佈來評估產品在生產過程中的合格率。這些都是二項分佈在實際應用中的重要例子
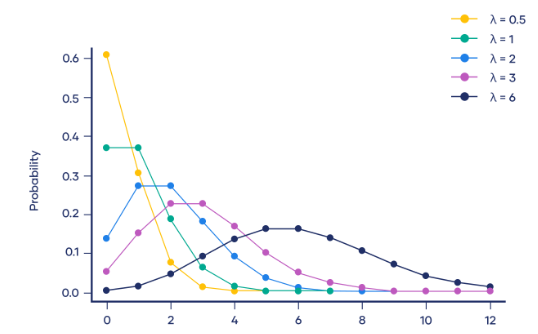
4. 泊松分佈
泊松分佈(Poisson Distribution)是一種離散型機率分佈,用於描述在固定時間內,事件發生的次數的機率分佈。泊松分佈適用於那些事件相互獨立,且平均發生速率恆定的情況。
泊松分佈的機率密度函數是:
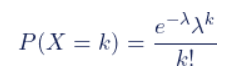
在這裡,P(X=k)代表在固定時間內事件發生k次的機率,λ表示事件的平均發生速率,也就是單位時間內事件發生的平均次數。 e是自然常數,約等於2.718。 k表示事件發生的次數
泊松分佈在實際中的應用十分廣泛,例如在電話呼叫中心,每分鐘打進的電話數量可以看作是泊松分佈,其中平均每分鐘打進的電話數為λ
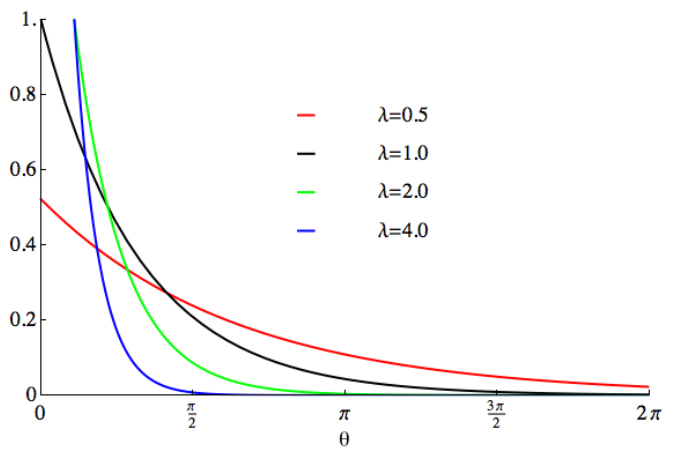
5. 指數分佈
指數分佈(Exponential Distribution)是一種連續型機率分佈,用來描述在固定時間內,事件發生的機率。指數分佈適用於那些事件相互獨立,且平均發生速率恆定的情況。
指數分佈的機率密度函數為:
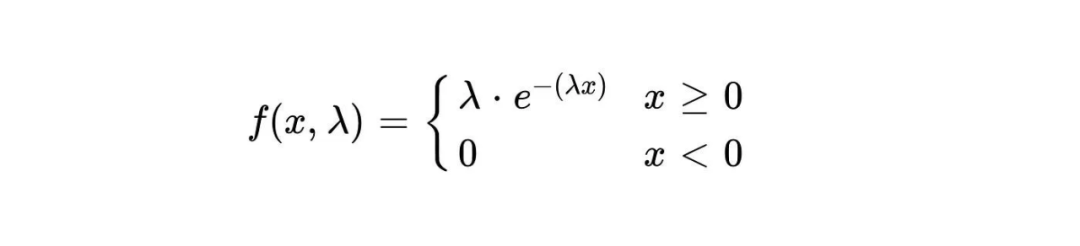
#在給定時間x內事件發生的機率密度用f(x,λ)表示。 λ表示事件的平均發生速率,即單位時間內事件發生的平均次數。 e是自然常數,約等於2.718
指數分佈在現實生活中有許多應用。例如,在放射性衰變中,放射性原子核的衰變時間可以被視為指數分佈。這意味著衰變時間的機率分佈符合指數函數。而平均衰變時間則對應著指數函數的參數λ
6. 伽瑪分佈
#Gamma分佈是一種連續機率分佈,用來描述事件在給定時間內發生的機率。它適用於事件之間互相獨立,且平均發生速率始終不變的情況
##在此其中,f(x)代表在特定時間x內事件發生的機率密度。 α和β是伽瑪分佈的形狀參數和速率參數。 α用來決定伽瑪分佈的形狀,取值範圍為0到正無窮。 β表示事件的平均發生速率,即在單位時間內事件發生的平均次數,取值範圍為0到正無窮。 e為自然常數,約等於2.718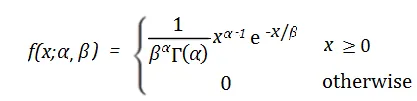
貝塔分佈的機率密度函數如下: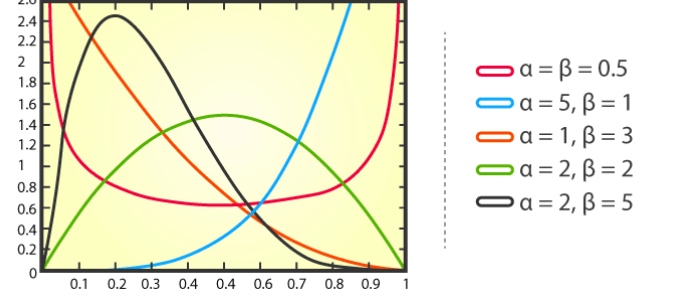
#在這其中,x代表成功的次數,α和β分別代表分佈的形狀參數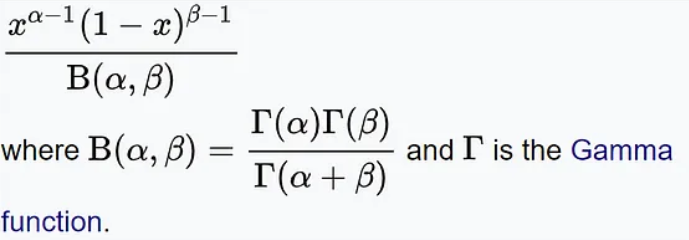
均勻分佈的特徵是,在給定的區間內,每個數值都有相同的機會出現。例如,拋一枚公正的硬幣,正面和反面出現的機率都是1/2,這就是一種均勻分佈。 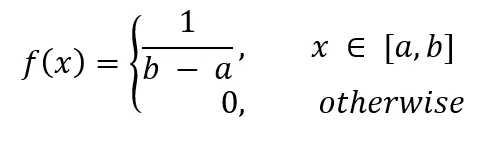
9. 對數常態分佈
對數常態分佈(Log-normal distribution)是一種連續型機率分佈,它的特徵是隨機變數的對數服從常態分佈。換句話說,如果一個隨機變數X的對數ln(X)服從常態分佈,那麼這個隨機變數X就服從對數常態分佈。
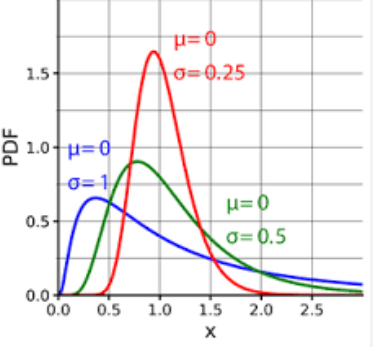
對數常態分佈的機率密度函數可以表示為:
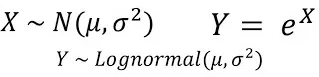
其中,μ是對數正態分佈的平均值,σ是對數常態分佈的標準差。
對數常態分佈在許多實際應用中都有重要意義,例如金融領域(股票價格、收益率等)、生物學(生長速率等)、經濟學(消費支出等)等。
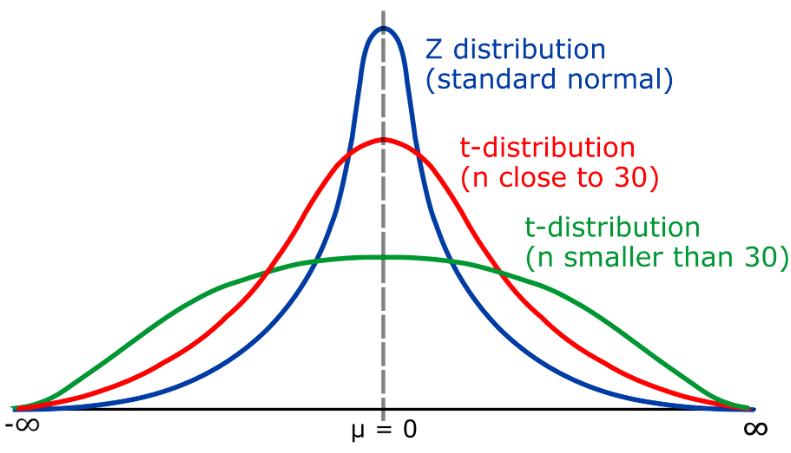
10. T分佈
T分佈,是一種連續型機率分佈,主要用於小樣本情況下描述平均值的分佈。 t分佈與常態分佈(Normal distribution)類似,但它的尾部可以向左右延伸,取決於自由度(k)的大小。 t分佈廣泛應用於統計推斷,例如在假設檢定中用於評估樣本平均值與總體平均值之間的顯著性差異。
t分佈的期望與變異數如下:
E(t)=0
#要重寫的內容是:Var( t)=k/(k-1)
t分佈的自由度(k)表示樣本大小(n)和總體標準差之間的關係。當k > 30時,t分佈接近常態分佈;當k接近1時,t分佈變為柯西分佈(Cauchy分佈)
在實際應用中,當樣本量較大(n>30 )時,可以使用常態分佈進行假設檢驗,這時可以利用z統計量建立信賴區間。然而,當樣本量較小(n
11. Weibull分佈
Weibull分佈(Weibull distribution)是一種連續型機率分佈。
Weibull分佈的機率密度函數為:
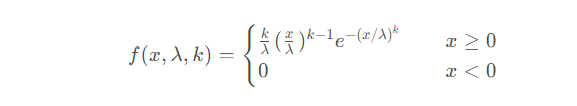
在韋伯分佈中,x視為隨機變量,λ則稱為比例參數(scale ),k則是形狀參數(shape)。就韋伯分佈而言,當k等於1時,它就是指數分佈。如果λ等於1的話,這就是最小化的韋伯分佈
以上是11個基本分佈,資料科學家95%的時間都在使用的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 使用pandas讀取CSV檔案並進行資料分析
Jan 09, 2024 am 09:26 AM
使用pandas讀取CSV檔案並進行資料分析
Jan 09, 2024 am 09:26 AM
Pandas是一個強大的資料分析工具,可以輕鬆讀取和處理各種類型的資料檔案。其中,CSV檔案是最常見且常用的資料檔案格式之一。本文將介紹如何使用Pandas讀取CSV檔案並進行資料分析,同時提供具體的程式碼範例。一、導入必要的函式庫首先,我們需要導入Pandas函式庫和其他可能需要的相關函式庫,如下所示:importpandasaspd二、讀取CSV檔使用Pan
 數據分析方法介紹
Jan 08, 2024 am 10:22 AM
數據分析方法介紹
Jan 08, 2024 am 10:22 AM
常見的資料分析方法:1、對照分析法;2、結構分析法;3、交叉分析法;4、趨勢分析法;5、因果分析法;6、關聯分析法;7、聚類分析法;8 、主成分分析法;9、散點分析法;10、矩陣分析法。詳細介紹:1、對照分析法:將兩個或兩個以上的資料進行比較分析,找出其中的差異與規律;2、結構分析法:對總體內各部分與總體進行比較分析的方法;3、交叉分析法等等。
 11個基本分佈,資料科學家95%的時間都在使用
Dec 15, 2023 am 08:21 AM
11個基本分佈,資料科學家95%的時間都在使用
Dec 15, 2023 am 08:21 AM
繼上次盤點《資料科學家95%的時間都在使用的11個基本圖表》之後,今天將為大家帶來資料科學家95%的時間都在使用的11個基本分佈。掌握這些分佈,有助於我們更深入地理解數據的本質,並在數據分析和決策過程中做出更準確的推論和預測。 1.常態分佈常態分佈(NormalDistribution),也被稱為高斯分佈(GaussianDistribution),是一種連續型機率分佈。它具有一個對稱的鐘形曲線,以平均值(μ)為中心,標準差(σ)為寬度。常態分佈在統計學、機率論、工程學等多個領域具有重要的應用價值。
 如何利用ECharts和php介面實現統計圖的資料分析與預測
Dec 17, 2023 am 10:26 AM
如何利用ECharts和php介面實現統計圖的資料分析與預測
Dec 17, 2023 am 10:26 AM
如何利用ECharts和php介面實現統計圖的資料分析和預測資料分析和預測在各個領域中扮演著重要角色,它們能夠幫助我們理解資料的趨勢和模式,為未來的決策提供參考。 ECharts是一款開源的資料視覺化函式庫,它提供了豐富且靈活的圖表元件,可以透過使用php介面來實現資料的動態載入和處理。本文將介紹基於ECharts和php介面的統計圖資料分析和預測的實作方法,並提供
 使用Go語言進行機器學習和數據分析
Nov 30, 2023 am 08:44 AM
使用Go語言進行機器學習和數據分析
Nov 30, 2023 am 08:44 AM
在當今智慧化的社會中,機器學習和數據分析是必不可少的工具,能夠幫助人們更好地理解和利用大量的數據。而在這些領域中,Go語言也成為了備受關注的程式語言,它的速度和效率使它成為了許多程式設計師的選擇。本文介紹如何使用Go語言進行機器學習和資料分析。一、機器學習Go語言的生態系統並不像Python和R那樣豐富,但是,隨著越來越多的人開始使用它,一些機器學習庫和框架
 Python 與機器學習的浪漫之旅,從新手到專家的一步之遙
Feb 23, 2024 pm 08:34 PM
Python 與機器學習的浪漫之旅,從新手到專家的一步之遙
Feb 23, 2024 pm 08:34 PM
1.Python與機器學習的邂逅python作為一種簡單易學、功能強大的程式語言,深受廣大開發者的喜愛。而機器學習作為人工智慧的一個分支,旨在讓電腦學會如何從數據中學習並做出預測或決策。 Python與機器學習的結合,可謂是珠聯璧合,為我們帶來了一系列強大的工具和函式庫,使得機器學習變得更加容易實現和應用。 2.Python機器學習庫探秘Python中提供了眾多功能豐富的機器學習庫,其中最受歡迎的包括:NumPy:提供了高效的數值計算功能,是機器學習的基礎庫。 SciPy:提供了更高階的科學計算工具,是
 資料分析與機器學習的11個進階視覺化圖表介紹
Oct 25, 2023 am 08:13 AM
資料分析與機器學習的11個進階視覺化圖表介紹
Oct 25, 2023 am 08:13 AM
視覺化是一種強大的工具,用於以直觀和可理解的方式傳達複雜的數據模式和關係。它們在數據分析中發揮著至關重要的作用,提供了通常難以從原始數據或傳統數位表示中辨別出來的見解。視覺化對於理解複雜的數據模式和關係至關重要,我們將介紹11個最重要且必須知道的圖表,這些圖表有助於揭示數據中的信息,使複雜數據更加可理解和有意義。 1.KSPlotKSPlot用來評估分佈差異。其核心思想是測量兩個分佈的累積分佈函數(CDF)之間的最大距離。最大距離越小,它們越有可能屬於同一分佈。所以它主要被解釋為確定分佈差異的「統
 哪些產業對Go語言需求較大?
Feb 21, 2024 pm 10:39 PM
哪些產業對Go語言需求較大?
Feb 21, 2024 pm 10:39 PM
在當今快速發展的科技時代,各種程式語言的應用範圍日益廣泛,其中Go語言作為一種高效、簡潔、易於學習和使用的程式語言,受到越來越多企業和開發者的青睞。 Go語言(也稱為Golang)是由Google開發的一種程式語言,它強調簡潔、高效和並發編程,適用於各種應用場景。那麼,哪些產業對Go語言的需求較大呢?接下來將分析一些主要產業,並探討它們對Go語言的需求。網際網路
