

英偉達打臉AMD:H100在軟體加持下,AI效能比MI300X快47%!


12月14日消息,AMD於本月初推出了其最強的AI晶片Instinct MI300X,其8-GPU伺服器的AI性能比英偉達H100 8-GPU高出了60%。對此,英偉達於近日發布了一組最新的H100與MI300X的性能對比數據,展示了H100如何使用正確的軟體提供比MI300X更快的AI性能。
根據AMD先前發表的數據顯示,MI300X的FP8/FP16性能都達到了英偉達(NVIDIA)H100的1.3倍,運行Llama 2 70B和FlashAttention 2 模型的速度比H100均快了20%。在8v8 伺服器中,運行Llama 2 70B模型,MI300X比H100快了40%;運行Bloom 176B模型,MI300X比H100快了60%。
但是,需要指出的是,AMD在將MI300X 與英偉達H100 進行比較時,AMD使用了最新的ROCm 6.0 套件中的優化庫(可支援最新的計算格式,例如FP16、Bf16 和FP8,包括Sparsity等),才得到了這些數字。相較之下,對於英偉達H100則並未沒有使用英偉達的 TensorRT-LLM 等優化軟體加持情況下進行測試。
AMD對英偉達H100測試的隱含聲明顯示,使用vLLM v.02.2.2推理軟體和英偉達DGX H100系統,Llama 2 70B查詢的輸入序列長度為2048,輸出序列長度為128
#英偉達最新發布的對於DGX H100(帶有8個NVIDIA H100 Tensor Core GPU,帶有80 GB HBM3)的測試結果顯示,使用了公開的NVIDIA TensorRT LLM軟體,其中v0.5.0用於Batch-1測試,v0.6.1用於延遲閾值測量。測試的工作量詳細資訊與先前進行的AMD測試相同
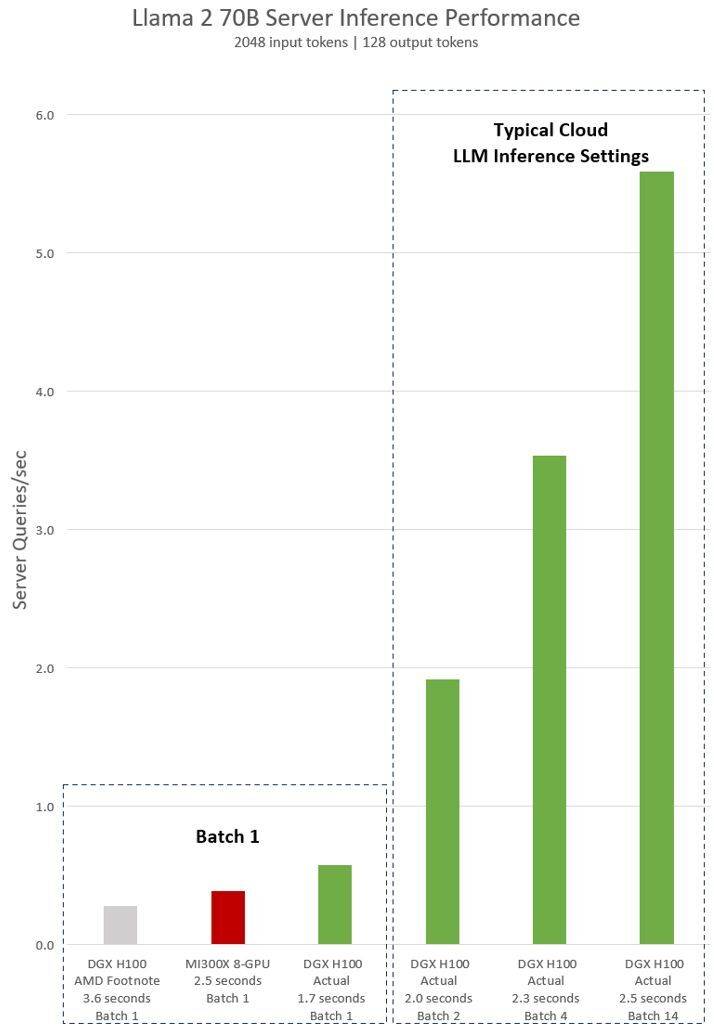
根據結果顯示,英偉達DGX H100伺服器在使用最佳化的軟體後,其效能提高了超過2倍,比AMD展示的MI300X 8-GPU伺服器快了47%
DGX H100 在1.7秒內可以處理單一推理任務。為了優化回應時間和資料中心的吞吐量,雲端服務為特定的服務設定了固定的回應時間。這樣他們可以將多個推理請求組合成更大的“Batch”,從而增加伺服器每秒的總體推理次數。 MLPerf 等業界標準基準測試也使用這個固定的反應時間指標來衡量效能
回應時間的微小權衡可能會導致伺服器可以即時處理的推理請求數量產生不確定因素。使用固定的 2.5 秒回應時間預算,英偉達DGX H100 伺服器每秒可以處理超過 5 個 Llama 2 70B 推理,而Batch-1每秒處理不到一個。
顯然,英偉達使用這些新的基準測試是相對公平的,畢竟AMD也使用其優化的軟體來評估其GPU的性能,所以為什麼不在測試英偉達H100時也這樣做呢?
要知道英偉達的軟體堆疊圍繞著CUDA生態系統,經過多年的努力和開發,在人工智慧市場擁有非常強大的地位,而AMD的ROCm 6.0是新的,尚未在現實場景中進行測試。
根據AMD先前透露的資訊顯示,已與微軟、Meta等大公司達成了很大一部分交易,這些公司將其MI300X GPU視為英偉達H100解決方案的替代品。
AMD最新的Instinct MI300X預計將在2024年上半年大量出貨,但是,屆時英偉達更強的H200 GPU也將出貨,2024下半年英偉達還將推出新一代的Blackwell B100。另外,英特爾也將會推出其新一代的AI晶片Gaudi 3。接下來,人工智慧領域的競爭似乎會變得更加激烈。
編輯:芯智訊-浪客劍
以上是英偉達打臉AMD:H100在軟體加持下,AI效能比MI300X快47%!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 華碩推出 Adol Book 14 Air,搭載 AMD Ryzen 9 8945H 和好奇的香爐
Aug 01, 2024 am 11:12 AM
華碩推出 Adol Book 14 Air,搭載 AMD Ryzen 9 8945H 和好奇的香爐
Aug 01, 2024 am 11:12 AM
華碩已經提供了多款 14 吋筆記型電腦,包括 Zenbook 14 OLED(亞馬遜售價 1,079.99 美元)。現在,它決定推出 Adol Book 14 Air,從表面上看它就像一台典型的 14 吋筆記型電腦。然而,一個不起眼的元
 OneXGPU 2 中的 AMD Radeon RX 7800M 效能優於 Nvidia RTX 4070 筆記型電腦 GPU
Sep 09, 2024 am 06:35 AM
OneXGPU 2 中的 AMD Radeon RX 7800M 效能優於 Nvidia RTX 4070 筆記型電腦 GPU
Sep 09, 2024 am 06:35 AM
OneXGPU 2 是首款搭載 Radeon RX 7800M 的 eGPU,而 AMD 尚未宣布推出這款 GPU。根據外置顯示卡方案製造商One-Netbook透露,AMD新GPU基於RDNA 3架構,擁有Navi
 Ryzen AI 軟體獲得新 Strix Halo 和 Kraken Point AMD Ryzen 處理器的支持
Aug 01, 2024 am 06:39 AM
Ryzen AI 軟體獲得新 Strix Halo 和 Kraken Point AMD Ryzen 處理器的支持
Aug 01, 2024 am 06:39 AM
AMD Strix Point 筆記型電腦剛剛上市,下一代 Strix Halo 處理器預計將於明年某個時候發布。不過,該公司已經在其 Ryzen AI 軟體中添加了對 Strix Halo 和 Krackan Point APU 的支援。
 適用於手持遊戲機的 AMD Z2 Extreme 晶片預計將於 2025 年初推出
Sep 07, 2024 am 06:38 AM
適用於手持遊戲機的 AMD Z2 Extreme 晶片預計將於 2025 年初推出
Sep 07, 2024 am 06:38 AM
儘管AMD 為手持遊戲機量身打造了Ryzen Z1 Extreme(及其非Extreme 變體),但該晶片只出現在兩款主流手持設備中:華碩ROG Ally(亞馬遜售價569 美元)和聯想Legion Go(三款)。
 AMD 公佈「Sinkclose」高風險漏洞,數百萬銳龍和 EPYC 處理器受影響
Aug 10, 2024 pm 10:31 PM
AMD 公佈「Sinkclose」高風險漏洞,數百萬銳龍和 EPYC 處理器受影響
Aug 10, 2024 pm 10:31 PM
本站8月10日訊息,AMD官方確認,部分EPYC和Ryzen處理器存在一個名為“Sinkclose”的新漏洞,代碼為“CVE-2023-31315”,可能涉及全球數百萬AMD用戶。那麼,什麼是Sinkclose呢?根據WIRED的一份報告,該漏洞允許入侵者在「系統管理模式(SMM)」中運行惡意程式碼。據稱,入侵者可以使用名為bootkit的惡意軟體來控制對方系統,而這種惡意軟體無法被防毒軟體偵測到。本站註:系統管理模式(SMM)是一種特殊的CPU工作模式,旨在實現高階電源管理和作業系統獨立功能,
 傳聞首款搭載 Ryzen AI 9 HX 370 的 Minisforum 迷你電腦將以高價推出
Sep 29, 2024 am 06:05 AM
傳聞首款搭載 Ryzen AI 9 HX 370 的 Minisforum 迷你電腦將以高價推出
Sep 29, 2024 am 06:05 AM
Aoostar 是最早推出 Strix Point 迷你電腦的公司之一,隨後 Beelink 推出了 SER9,起價高達 999 美元。 Minisforum 透過調侃 EliteMini AI370 加入了聚會,顧名思義,它將是該公司的
 交易 |配備 120Hz OLED、64GB RAM 和 AMD Ryzen 7 Pro 的 Lenovo ThinkPad P14s Gen 5 現在有 60% 折扣
Sep 07, 2024 am 06:31 AM
交易 |配備 120Hz OLED、64GB RAM 和 AMD Ryzen 7 Pro 的 Lenovo ThinkPad P14s Gen 5 現在有 60% 折扣
Sep 07, 2024 am 06:31 AM
這些天許多學生都回到了學校,有些人可能會注意到他們的舊筆記型電腦不再能勝任這項任務。一些大學生甚至可能正在市場上購買一款配備華麗 OLED 螢幕的高端商務筆記型電腦,在這種情況下
 Beelink SER9:小型 AMD Zen 5 迷你 PC 宣布配備 Radeon 890M iGPU,但 eGPU 選項有限
Sep 12, 2024 pm 12:16 PM
Beelink SER9:小型 AMD Zen 5 迷你 PC 宣布配備 Radeon 890M iGPU,但 eGPU 選項有限
Sep 12, 2024 pm 12:16 PM
Beelink 繼續以驚人的速度推出新的迷你電腦和隨附配件。回顧一下,自從發布 EQi12、EQR6 和 EX eGPU 擴充座以來,已經過了一個多月的時間。現在,該公司已將注意力轉向AMD的新Strix
