

[MySQL]Innodb参数优化_MySQL

innodb_buffer_pool_size
innodb_buffer_pool_size 参数用来设置Innodb 最主要的Buffer(Innodb_Buffer_Pool)的大小,也就是缓存用户表及索引数据的最主要缓存空间,对Innodb 整体性能影响也最大。
对于一台单独给MySQL 使用的主机,并假设只使用innodb引擎,一般建议该参数为物流内存的75%左右。
当系统上线之后,我们可以通过Innodb 存储引擎提供给我们的关于Buffer Pool 的实时状态信息作出进一步分析,来确定系统中Innodb 的Buffer Pool 使用情况是否正常高效:
mysql> show status like 'Innodb_buffer_pool_%'; +-----------------------------------------+---------------+ | Variable_name | Value | +-----------------------------------------+---------------+ | Innodb_buffer_pool_pages_data | 999020 | | Innodb_buffer_pool_pages_dirty | 47643 | | Innodb_buffer_pool_pages_flushed | 474668167 | | Innodb_buffer_pool_pages_LRU_flushed | 365125 | | Innodb_buffer_pool_pages_free | 0 | | Innodb_buffer_pool_pages_made_not_young | 0 | | Innodb_buffer_pool_pages_made_young | 203410903 | | Innodb_buffer_pool_pages_misc | 49552 | | Innodb_buffer_pool_pages_old | 368697 | | Innodb_buffer_pool_pages_total | 1048572 | | Innodb_buffer_pool_read_ahead_rnd | 0 | | Innodb_buffer_pool_read_ahead | 66348855 | | Innodb_buffer_pool_read_ahead_evicted | 3716819 | | Innodb_buffer_pool_read_requests | 3215992991498 | | Innodb_buffer_pool_reads | 65634998 | | Innodb_buffer_pool_wait_free | 651 | | Innodb_buffer_pool_write_requests | 21900970785 | +-----------------------------------------+---------------+
read 请求3215992991498次,其中有65634998次所请求的数据在buffer pool 中没有,也就是说有65634998 次是通过读取物理磁盘来读取数据的,所以很容易也就得出了Innodb Buffer Pool 的Read 命中率大概在为:(3215992991498- 65634998)/ 3215992991498* 100% = 99.998%。
innodb_buffer_pool_instances
该参数将innodb_buffer_pool划分为不同的instance,每个instance独立的LRU、FLUSH、FREE、独立的mutex控制。
对于比较大的innodb_buffer_pool_size,建议设置多个instances,避免内存锁的争用。
innodb_log_file_size
设置innodb redo log file的大小,从性能角度来看,日志文件越大越好,可以减少buffer pool checkpoint的频率,但是在MySQL的官方版本中,innodb_log_files_in_group*innodb_log_files_in_group不能超过4G。
日志文件越大,也意味着MySQL实例crash之后恢复的时间越长,不过一般生成系统都会配置主从库,因此这个因素可以忽略不考虑。
一般来说,在我个人维护的环境中,比较偏向于将事务日志设置为3 组,每个日志设置为256MB 大小,整体效果还算不错。
innodb_log_buffer_size
顾名思义,这个参数就是用来设置Innodb 的Log Buffer 大小的,系统默认值为1MB。Log Buffer的主要作用就是缓冲Log 数据,提高写Log 的IO 性能。一般来说,如果你的系统不是“写负载非常高且以大事务居多”的话,8MB 以内的大小就完全足够了。
我们也可以通过系统状态参数提供的性能统计数据来分析Log 的使用情况:
mysql> show status like 'innodb_log%'; +---------------------------+------------+ | Variable_name | Value | +---------------------------+------------+ | Innodb_log_waits | 0 | | Innodb_log_write_requests | 3486920147 | | Innodb_log_writes | 352577360 | +---------------------------+------------+
innodb_thread_concurrency
该参数表示innodb最大线程并发量,官方推荐设为0,表示由innodb自己控制,但实践证明,当并发过大时,innodb自己会控制不当,可能导致MySQL hang死,所以一般建议为CPU核心数(不含超线程)
innodb_io_capacity
表示每秒钟IO设备处理数据页的上限,如果硬盘性能比较好,可以设大一些(如1000)。
innodb_max_dirty_pages_pct
表示innodb从buffer中刷新脏页的比例不超过这个值,每次checkpoint的脏页刷新为:innodb_max_dirty_pages_pct*innodb_io_capacity
Innodb_flush_method
用来设置Innodb 打开和同步数据文件以及日志文件的方式,不过只有在Linux & Unix 系统上面有效。当我们设置为O_DSYNC,则系统以O_SYNC 方式打开和刷新日志文件, 通过fsync() 来打开和刷新数据文件。而设置为O_DIRECT 的时候, 则通过O_DIRECT(Solaris 上为directio())打开数据文件,同时以fsync()来刷新数据和日志文件。
总的来说,innodb_flush_method 的不同设置主要影响的是Innodb 在不同运行平台下进行IO 操作的时候所调用的操作系统IO 借口的区别。而不同的IO 操作接口对数据的处理方式会有一定的区别,所以处理性能也会有一定的差异。一般来说,如果我们的磁盘是通过RAID 卡做了硬件级别的RAID,建议可以使用O_DIRECT,可以一定程度上提高IO 性能,但如果RAID Cache 不够的话,还是需要谨慎对待。
innodb_file_per_table
一般建议开启,因为不同的表空间可以灵活设置数据目录的地址,避免共享表空间产生的IO竞争。
innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit = 0,Innodb 中的Log Thread 每隔1 秒钟会将log buffer中的数据写入到文件,同时还会通知文件系统进行文件同步的flush 操作,保证数据确实已经写入到磁盘上面的物理文件。但是,每次事务的结束(commit 或者是rollback)并不会触发Log Thread 将log buffer 中的数据写入文件。所以,当设置为0 的时候,当MySQL Crash 和OS Crash 或者主机断电之后,最极端的情况是丢失1 秒时间的数据变更。innodb_flush_log_at_trx_commit = 1,这也是Innodb 的默认设置。我们每次事务的结束都会触发Log Thread 将log buffer 中的数据写入文件并通知文件系统同步文件。这个设置是最安全的设置,能够保证不论是MySQL Crash 还是OS Crash 或者是主机断电都不会丢失任何已经提交的数据。
innodb_flush_log_at_trx_commit = 2,当我们设置为2 的时候,Log Thread 会在我们每次事务结束的时候将数据写入事务日志,但是这里的写入仅仅是调用了文件系统的文件写入操作。而我们的文件系统都是有缓存机制的,所以Log Thread 的这个写入并不能保证内容真的已经写入到物理磁盘上面完成持久化的动作。文件系统什么时候会将缓存中的这个数据同步到物理磁盘文件Log Thread 就完全不知道了。所以,当设置为2 的时候,MySQL Crash 并不会造成数据的丢失,但是OS Crash 或者是主机断电后可能丢失的数据量就完全控制在文件系统上了。
从上面的分析我们可以看出,当innodb_flush_log_at_trx_commit 设置为1 的时候是最安全的,但是由于所做的IO 同步操作也最多,所以性能也是三种设置中最差的一种。如果设置为0,则每秒有一次同步,性能相对高一些。如果设置为2,可能性能是三这种最好的。但是也可能是出现Crash后丢失数据最多的。到底该如何设置设置,就要根据具体的场景来分析了。一般来说,如果完全不能接受数据的丢失,那么我们肯定会通过牺牲一定的性能来换取数据的安全性,选择设置为1。而如果我们可以丢失很少量的数据(比如说1 秒之内),那么我们可以设置为0。当然,如果大家觉得我们的OS 足够稳定,主机硬件设备,而且主机的供电系统也足够安全,我们也可以将innodb_flush_log_at_trx_commit 设置为2 让系统的整体性能尽可能的高。
transaction-isolation
对于高并发应用来说,为了尽可能保证数据的一致性,避免并发可能带来的数据不一致问题,自然是事务隔离级别越高越好。但是,对于Innodb 来说,所使用的事务隔离级别越高,实现复杂度自然就会更高,所需要做的事情也会更多,整体性能也就会更差。
所以,我们需要分析自己应用系统的逻辑,选择可以接受的最低事务隔离级别。以在保证数据安全一致性的同时达到最高的性能。
虽然Innodb 存储引擎默认的事务隔离级别是REPEATABLE READ,但实际上在我们大部分的应用场景下,都只需要READ COMMITED 的事务隔离级别就可以满足需求了。
sync_binlog
表示每次刷新binlog到磁盘的数目。
对于核心系统,我们需要采用双1模式,即:innodb_flush_log_at_trx_commit=1, sync_binlog=1,这样可以保证主备库数据一致,不会有数据丢失。

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 PHP 5.4版本新功能:如何使用callable類型提示參數接受可呼叫的函數或方法
Jul 29, 2023 pm 09:19 PM
PHP 5.4版本新功能:如何使用callable類型提示參數接受可呼叫的函數或方法
Jul 29, 2023 pm 09:19 PM
PHP5.4版本新功能:如何使用callable類型提示參數接受可呼叫的函數或方法引言:PHP5.4版本引入了一個非常便利的新功能-可以使用callable類型提示參數來接受可呼叫的函數或方法。這個新功能使得函數和方法可以直接指定對應的可呼叫參數,而無需進行額外的檢查和轉換。在本文中,我們將介紹callable類型提示的使用方法,並提供一些程式碼範例,
 產品參數是什麼意思
Jul 05, 2023 am 11:13 AM
產品參數是什麼意思
Jul 05, 2023 am 11:13 AM
產品參數是指產品屬性的意思。例如服裝參數有品牌、材質、型號、大小、風格、布料、適應人群和顏色等;食品參數有品牌、重量、材質、衛生許可證號碼、適應人群和顏色等;家電參數有品牌、尺寸、顏色、產地、適應電壓、訊號、介面和功率等。
 C++ 函式參數型別安全檢查
Apr 19, 2024 pm 12:00 PM
C++ 函式參數型別安全檢查
Apr 19, 2024 pm 12:00 PM
C++參數類型安全檢查透過編譯時檢查、執行時間檢查和靜態斷言確保函數只接受預期類型的值,防止意外行為和程式崩潰:編譯時類型檢查:編譯器檢查類型相容性。運行時類型檢查:使用dynamic_cast檢查類型相容性,不符則拋出異常。靜態斷言:在編譯時對型別條件進行斷言。
 PHP Warning: in_array() expects parameter的解決方法
Jun 22, 2023 pm 11:52 PM
PHP Warning: in_array() expects parameter的解決方法
Jun 22, 2023 pm 11:52 PM
在開發過程中,我們可能會遇到這樣一個錯誤提示:PHPWarning:in_array()expectsparameter。這個錯誤提示會在使用in_array()函數時出現,有可能是因為函數的參數傳遞不正確所導致的。以下我們來看看這個錯誤提示的解決方法。首先,需要明確in_array()函數的作用:檢查一個值是否在陣列中存在。此函數的原型為:in_a
 C++程式以給定值為參數,找出雙曲正弦反函數的值
Sep 17, 2023 am 10:49 AM
C++程式以給定值為參數,找出雙曲正弦反函數的值
Sep 17, 2023 am 10:49 AM
雙曲函數是使用雙曲線而不是圓定義的,與普通三角函數相當。它從提供的弧度角傳回雙曲正弦函數中的比率參數。但要做相反的事,或者換句話說。如果我們想要根據雙曲正弦值計算角度,我們需要像雙曲反正弦運算一樣的反雙曲三角運算。本課程將示範如何使用C++中的雙曲反正弦(asinh)函數,並使用雙曲正弦值(以弧度為單位)計算角度。雙曲反正弦運算遵循下列公式-$$\mathrm{sinh^{-1}x\:=\:In(x\:+\:\sqrt{x^2\:+\:1})},其中\:In\:是\:自然對數\:(log_e\:k)
 i9-12900H參數評測大全
Feb 23, 2024 am 09:25 AM
i9-12900H參數評測大全
Feb 23, 2024 am 09:25 AM
i9-12900H是14核心的處理器,使用的架構和工藝都是全新的,線程也很高,整體的工作都是很優秀的,一些參數都有提升特別的全面,是可以給用戶們帶來極佳體驗的。 i9-12900H參數評測大全評測:1、i9-12900H是14核心的處理器,採用了q1架構以及24576kb的製程工藝,提升到了20個執行緒。 2.最大的CPU頻率是1.80!5.00ghz,整體主要取決於工作的負載。 3.相比較價位來說還是特別合適的,性價比很不錯,對於一些需要正常使用的伙伴來說非常的合適。 i9-12900H參數評測大全性能跑分
 100億參數的語言模型跑不動? MIT華人博士提出SmoothQuant量化,記憶體需求直降一半,速度提升1.56倍!
Apr 13, 2023 am 09:31 AM
100億參數的語言模型跑不動? MIT華人博士提出SmoothQuant量化,記憶體需求直降一半,速度提升1.56倍!
Apr 13, 2023 am 09:31 AM
大型語言模型(LLM)雖然性能強勁,但動輒幾百上千億的參數量,對計算設備還是內存的需求量之大,都不是一般公司能承受得住的。量化(Quantization)是常見的壓縮操作,透過降低模型權重的精度(如32bit降為8bit),犧牲一部分模型的效能來換取更快的推理速度,更少的記憶體需求。但對於超過1000億參數量的LLM來說,現有的壓縮方法都無法維持模型的準確率,也無法在硬體上有效率地運作。最近,麻省理工學院和英偉達的研究人員聯合提出了一個通用後訓練的量化(GPQ, general-purpose po
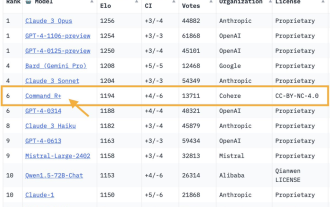 開源模型首勝GPT-4!競技場最新戰報引熱議,Karpathy:這是我唯二信任的榜單
Apr 10, 2024 pm 03:16 PM
開源模型首勝GPT-4!競技場最新戰報引熱議,Karpathy:這是我唯二信任的榜單
Apr 10, 2024 pm 03:16 PM
能打得過GPT-4的開源模型出現了!大模型競技場最新戰報:1040億參數開源模型CommandR+攀升至第6位,與GPT-4-0314打成平手,超過了GPT-4-0613。圖片這也是第一個在大模型競技場上擊敗GPT-4的開放權重模型。大模型競技場,可是大神Karpathy口中唯二信任的測試基準之一。圖片CommandR+來自AI獨角獸Cohere。這家大模型新創公司的共同創辦人兼CEO,正是Transformer最年輕作者AidanGomez(簡稱割麥子)。圖片這份戰報一出,又掀起了一波大模型社
