

使用SQL语句操作MYSQL字符编码_MySQL

-- 查看所有的字符编码
SHOW CHARACTER SET;
-- 查看创建数据库的指令并查看数据库使用的编码
show create database dbtest;
-- 查看数据库编码:
show variables like '%char%';
-- 设置character_set_server、set character_set_client和set character_set_results
set character_set_server = utf8; -- 服务器的默认字符集。使用这个语句可以修改成功,但重启服务后会失效。根本的办法是修改配置MYSQL文件MY.INI,character_set_server=utf8,配置到mysqld字段下。
set character_set_client = gbk; -- 来自客户端的语句的字符集。服务器使用character_set_client变量作为客户端发送的查询中使用的字符集。
set character_set_results = gbk; -- 用于向客户端返回查询结果的字符集。character_set_results变量指示服务器返回查询结果到客户端使用的字符集。包括结果数据,例如列值和结果元数据(如列名)。
-- 创建数据库时,设置数据库的编码方式
-- CHARACTER SET:指定数据库采用的字符集,utf8不能写成utf-8
-- COLLATE:指定数据库字符集的排序规则,utf8的默认排序规则为utf8_general_ci(通过show character set查看)
drop database if EXISTS dbtest;
create database dbtest CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 修改数据库编码
alter database dbtest CHARACTER SET GBK COLLATE gbk_chinese_ci;
alter database dbtest CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 创建表时,设置表、字段编码
use dbtest;
drop table if exists tbtest;
create table tbtest(
id int(10) auto_increment,
user_name varchar(60) CHARACTER SET GBK COLLATE gbk_chinese_ci,
email varchar(60),
PRIMARY key(id)
)CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 修改表编码
alter table tbtest character set utf8 COLLATE utf8_general_ci;
-- 修改字段编码
ALTER TABLE tbtest MODIFY email VARCHAR(60) CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 查看某字段使用的编码:
SELECT CHARSET(email) FROM tbtest;

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 11個常見的分類特徵的編碼技術
Apr 12, 2023 pm 12:16 PM
11個常見的分類特徵的編碼技術
Apr 12, 2023 pm 12:16 PM
機器學習演算法只接受數值輸入,所以如果我們遇到分類特徵的時候都會對分類特徵進行編碼,本文總結了常見的11個分類變數編碼方法。 1.ONE HOT ENCODING最受歡迎且常用的編碼方法是One Hot Enoding。一個具有n個觀測值和d個不同值的單一變量被轉換成具有n個觀測值的d個二元變量,每個二元變量使用一位(0,1)進行標識。例如:編碼後最簡單的實作是使用pandas的' get_dummiesnew_df=pd.get_dummies(columns=[‘Sex’], data=df)2、
 utf8編碼漢字佔多少位元組
Feb 21, 2023 am 11:40 AM
utf8編碼漢字佔多少位元組
Feb 21, 2023 am 11:40 AM
utf8編碼漢字佔3個位元組。在UTF-8編碼中,一個中文等於三個位元組,一個中文標點佔三個位元組;而在Unicode編碼中,一個中文(含繁體)等於兩個位元組。 UTF-8使用1~4位元組為每個字元編碼,一個US-ASCIl字元只需1位元組編碼,帶有變音符號的拉丁文、希臘文、西里爾字母、亞美尼亞語、希伯來文、阿拉伯文、敘利亞文等字母則需要2位元組編碼。
 如何在 Word 中鍵入箭頭
Apr 16, 2023 pm 11:37 PM
如何在 Word 中鍵入箭頭
Apr 16, 2023 pm 11:37 PM
如何使用自動更正在 Word 中鍵入箭頭在 Word 中鍵入箭頭的最快方法之一是使用預先定義的自動修正捷徑。如果您鍵入特定的字元序列,Word 會自動將這些字元轉換為箭頭符號。您可以使用此方法繪製多種不同的箭頭樣式。若要使用自動更正在 Word 中鍵入箭頭:將遊標移到文件中要顯示箭頭的位置。鍵入以下字元組合之一:如果您不希望將您鍵入的內容更正為箭頭符號,請按鍵盤上的退格鍵會將
 使用java的Character.isDigit()函數判斷字元是否為數字
Jul 27, 2023 am 09:32 AM
使用java的Character.isDigit()函數判斷字元是否為數字
Jul 27, 2023 am 09:32 AM
使用Java的Character.isDigit()函數判斷字元是否為數字字元在電腦內部以ASCII碼的形式表示,每個字元都有一個對應的ASCII碼。其中,數字字元0到9分別對應的ASCII碼值為48到57。要判斷一個字元是否為數字,可以使用Java中的Character類別提供的isDigit()方法來判斷。 isDigit()方法是Character類別的
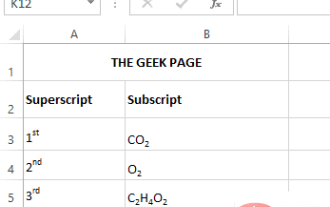 如何在 Microsoft Excel 中套用上標和下標格式選項
Apr 14, 2023 pm 12:07 PM
如何在 Microsoft Excel 中套用上標和下標格式選項
Apr 14, 2023 pm 12:07 PM
上標是一個字符或多個字符,可以是字母或數字,您需要將其設置為略高於正常文本行。例如,如果您需要寫1st,則字母st需要略高於字元1。同樣,下標是一組字符或單個字符,需要設置為略低於正常文本級別。例如,當你寫化學式時,你需要把數字放在正常字元行的下方。以下螢幕截圖顯示了上標和下標格式的一些範例。儘管這似乎是一項艱鉅的任務,但實際上將上標和下標格式應用於您的文字非常簡單。在本文中,我們將透過一些簡單的步驟說明如何輕鬆地使用上標或下標格式設定文字。希望你喜歡閱讀這篇文章。如何在 Excel 中套用上標
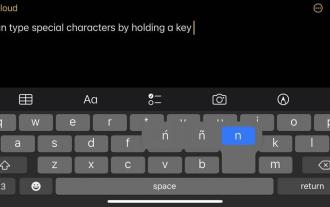 如何在 iPhone 和 Mac 上輸入擴充字符,例如度數符號?
Apr 22, 2023 pm 02:01 PM
如何在 iPhone 和 Mac 上輸入擴充字符,例如度數符號?
Apr 22, 2023 pm 02:01 PM
您的實體或數位鍵盤在表面上提供有限數量的字元選項。但是,有幾種方法可以在iPhone、iPad和Mac上存取重音字母、特殊字元等。標準iOS鍵盤可讓您快速存取大寫和小寫字母、標準數字、標點符號和字元。當然,還有很多其他角色。您可以從帶有變音符號的字母到倒置的問號中進行選擇。您可能無意中發現了隱藏的特殊字元。如果沒有,以下是在iPhone、iPad和Mac上存取它們的方法。如何在iPhone和iPad上存取擴充字元在iPhone或iPad上取得擴充字元非常簡單。在「訊息」、「
 知識圖譜:大模型的理想搭檔
Jan 29, 2024 am 09:21 AM
知識圖譜:大模型的理想搭檔
Jan 29, 2024 am 09:21 AM
大型語言模式(LLM)具有產生流暢和連貫文字的能力,為人工智慧的對話、創意寫作等領域帶來了新的前景。然而,LLM也存在一些關鍵限制。首先,它們的知識僅限於從訓練資料中辨識出的模式,缺乏對世界的真正理解。其次,推理能力有限,不能進行邏輯推理或從多個資料來源融合事實。面對更複雜、更開放的問題時,LLM的回答可能變得荒謬或矛盾,被稱為「幻覺」。因此,儘管LLM在某些方面非常有用,但在處理複雜問題和真實世界情境時,仍存在一定的限制。為了彌補這些差距,近年來出現了檢索增強生成(RAG)系統,其核心思想是
 正確在matplotlib中顯示中文字元的方法
Jan 13, 2024 am 11:03 AM
正確在matplotlib中顯示中文字元的方法
Jan 13, 2024 am 11:03 AM
在matplotlib中正確地顯示中文字符,是許多中文使用者常常遇到的問題。預設情況下,matplotlib使用的是英文字體,無法正確顯示中文字元。為了解決這個問題,我們需要設定正確的中文字體,並將其應用到matplotlib中。以下是一些具體的程式碼範例,幫助你正確地在matplotlib中顯示中文字元。首先,我們需要導入需要的函式庫:importmatplot
