

首選神經網路應用於時間序列數據

| 導讀 | 本文簡單介紹循環神經網路RNN的發展過程,分析了梯度下降演算法、反向傳播及LSTM過程。 |
隨著科學技術的發展以及硬體運算能力的大幅提升,人工智慧已經從幾十年的幕後工作一下子躍入人們眼簾。人工智慧的背後源自於大數據、高效能的硬體與優秀的演算法的支援。 2016年,深度學習已成為Google搜尋的熱詞,隨著最近一兩年的圍棋人機大戰中,阿法狗完胜世界冠軍後,人們感覺到再也無法抵擋住AI的車輪的快速駛來。在2017年這一年中,AI已經突破天際,相關產品也出現在人們的生活中,例如智慧機器人、無人駕駛以及語音搜尋等。最近,世界智能大會在天津舉辦成功,大會上許多業內行家及企業家發表自己對未來的看法,可以了解到,大多數的科技公司及研究機構都非常看好人工智能的前景,比如百度公司將自己的全部身家壓在人工智慧上,不管破釜沉舟後是一舉成名還是一敗塗地,只要不是一無所獲就行。為什麼突然深度學習會有這麼大的效應與熱潮呢?這是因為科技改變生活,很多的職業可能在未來的時間慢慢被人工智慧取代。全民都在熱議人工智慧與深度學習,就連Yann LeCun大牛都感受到了人工智慧在中國的火熱!
#言歸正傳,人工智慧的背後是大數據、優秀的演算法以及強大運算能力的硬體支援。例如,英偉達公司憑藉自己的強大的硬體研發能力以及對深度學習框架的支持奪得世全球最聰明的五十家公司榜首。另外優秀的深度學習演算法很多,時不時就會出現一個新的演算法,真是令人眼花撩亂。但大多都是基於經典的演算法改進而來,例如卷積神經網路(CNN)、深度信念網路(DBN)、循環神經網路(RNN)等等。
本文將介紹經典的網路之循環神經網路(RNN),而此網路也是時序資料的首選網路。當涉及某些順序機器學習任務時,RNN可以達到很高的精度,沒有其他演算法可以與之一較高下。這是由於傳統的神經網路只是具有一種短期記憶,而RNN具有有限的短期記憶的優勢。然而,第一代RNNs網路並沒有引起人們著重的注意,這是由於研究人員在利用反向傳播和梯度下降演算法過程中遭受了嚴重的梯度消失問題,阻礙了RNN幾十年的發展。最後,在90年代後期出現了重大突破,導致更準確的新一代RNN的問世。基於這項突破的近二十年,直到Google Voice Search和Apple Siri等應用程式開始搶奪其關鍵流程,開發人員完善並優化了新一代的RNN。現在,RNN網路遍布各個研究領域,並且正在幫助點燃人工智慧的復興之火。
與過去有關的神經網路(RNN)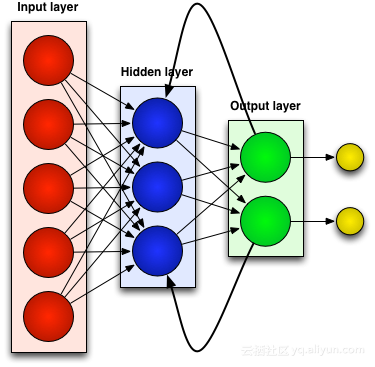
#大多數人造神經網絡,如前饋神經網絡,都沒有記憶它們剛剛收到的輸入。例如,如果提供前饋神經網路的字元“WISDOM”,當它到達字元“D”時,它已經忘記了它剛剛讀過字元“S”,這是一個大問題。無論訓練該網路是多麼的辛苦,總是很難猜出下一個最有可能的字元「O」。這使得它成為某些任務的一個相當無用的候選人,例如在語音識別中,識別的好壞在很大程度上受益於預測下一個字元的能力。另一方面,RNN網路確實記住了先前的輸入,但是處於一個非常複雜的水平。
我們再次輸入“WISDOM”,並將其應用到一個複發性網路中。 RNN網路中的單元或人造神經元在接收到「D」時也將其先前接收到的字元「S」作為其輸入。換句話說,就是把剛剛過去的事情聯合現在的事情作為輸入,來預測接下來會發生的事情,這給了它有限的短期記憶的優勢。當訓練時,提供足夠的背景下,可以猜測下一個字元最有可能是“O”。
調整與重新調整就像所有人工神經網路一樣,RNN的單元為其多個輸入分配一個權重矩陣,這些權重代表各個輸入在網路層中所佔的比重;然後對這些權重應用一個函數來確定單一輸出,這個函數一般稱為損失函數(代價函數),限定實際輸出與目標輸出之間的誤差。然而,循環神經網路不僅對當前輸入分配權重,而且還從對過去時刻輸入分配權重。然後,透過使得損失函數最下來動態的調整分配給當前輸入和過去輸入的權重,這個過程涉及到兩個關鍵概念:梯度下降和反向傳播(BPTT)。
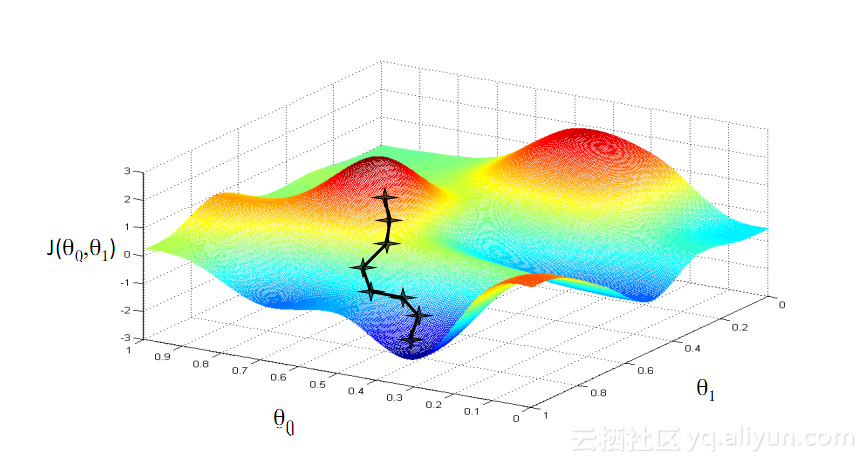
梯度下降機器學習中最著名的演算法之一就是梯度下降演算法。它的主要優點在於它顯著的迴避了「維數災難」。什麼是「維數災難」呢,是說在涉及向量的計算問題中,隨著維數的增加,計算量會呈指數倍增長。這個問題困擾著許多神經網路系統,因為太多的變數需要計算才能達到最小的損失函數。然而,梯度下降演算法透過放大多維誤差或代價函數的局部最小值來打破維數災難。這有助於系統調整分配給各個單元的權重值,以使網路變得更加精確。
透過時間的反向傳播#RNN透過反向推理微調其權重來訓練其單元。簡單的說,就是根據單元計算出的總輸出與目標輸出之間的誤差,從網路的最終輸出端反向逐層迴歸,利用損失函數的偏導調整每個單元的權重。這就是著名的BP演算法,關於BP演算法可以看本部落客之前的相關部落格。而RNN網路使用的是類似的一個版本,稱為通過時間的反向傳播(BPTT)。此版本擴展了調整過程,包括負責前一時刻(T-1)輸入值對應的每個單元的記憶的權重。
Yikes:梯度消失問題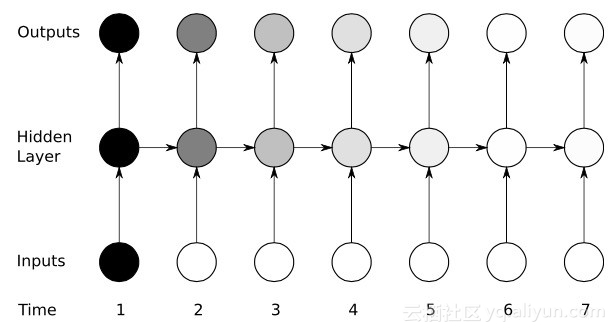
#儘管在梯度下降演算法和BPTT的幫助下享有一些初步的成功,但是許多人造神經網路(包括第一代RNNs網路),最終都遭受了嚴重的挫折——梯度消失問題。什麼是梯度消失問題呢,其基本想法其實很簡單。首先,來看一個梯度的概念,將梯度視為斜率。在訓練深層神經網路的背景中,梯度值越大代表坡度越陡峭,系統能夠越快下滑到終點線並完成訓練。但這也是研究者陷入困境的地方——當斜坡太平坦時,無法進行快速的訓練。這對於深層網路中的第一層而言特別關鍵,因為若第一層的梯度值為零,表示沒有了調整方向,無法調整相關的權重值來最下化損失函數,這一現象就是「消梯度失”。隨著梯度越來越小,訓練時間也會越來越長,類似物理學中的直線運動,光滑表面,小球會一直移動下去。
在九十年代後期,一個重大的突破解決了上述梯度消失問題,為RNN網路發展帶來了第二次研究熱潮。這種大突破的中心思想是引入了單元長短期記憶(LSTM)。
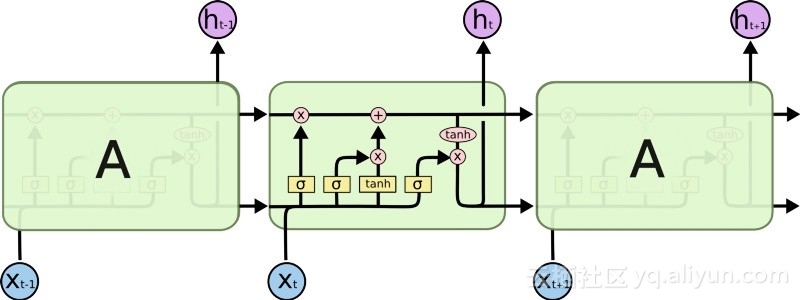
#LSTM的引進給AI領域創造了一個不同的世界。這是由於這些新單元或人造神經元(如RNN的標準短期記憶單元)從一開始就記住了它們的輸入。然而,與標準的RNN單元不同,LSTM可以掛載在它們的記憶體上,這些記憶體具有類似於常規電腦中的記憶體暫存器的讀取/寫入屬性。另外LSTM是類比的,而不是數字,使得它們的特徵可以區分。換句話說,它們的曲線是連續的,可以找到它們的斜坡的陡度。因此,LSTM特別適合反向傳播和梯度下降中所涉及的偏微積分。
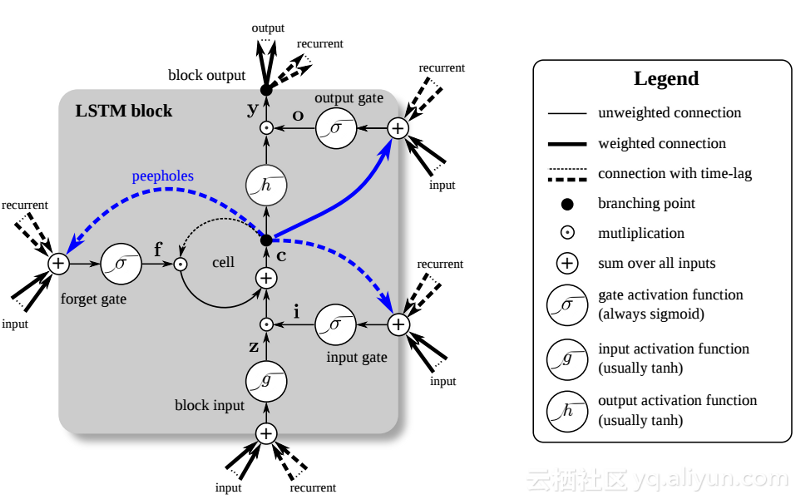
#總而言之,LSTM不僅可以調整其權重,還可以根據訓練的梯度來保留、刪除、轉換和控制其儲存資料的流入和流出。最重要的是,LSTM可以長時間保存重要的錯誤訊息,以使梯度相對陡峭,從而網路的訓練時間相對較短。這解決了梯度消失的問題,並大大提高了當今基於LSTM的RNN網路的準確性。由於RNN架構的顯著改進,Google、蘋果及許多其他先進的公司現在正在使用RNN為其業務中心的應用提供推動力。
總結循環神經網路(RNN)可以記住其先前的輸入,當涉及到連續的、與情境相關的任務(如語音辨識)時,它比其他人造神經網路具有更大的優勢。
關於RNN網路的發展歷程:第一代RNNs透過反向傳播和梯度下降演算法達到了修正錯誤的能力。但梯度消失問題阻止了RNN的發展;直到1997年,引入了一個基於LSTM的架構後,取得了巨大的突破。
新的方法有效地將RNN網路中的每個單元轉變成一個模擬計算機,大大提高了網路精度。
作者資訊
Jason Roell:軟體工程師,熱愛深度學習及其可改變技術的應用。
Linkedin:http://www.linkedin.com/in/jason-roell-47830817/
以上是首選神經網路應用於時間序列數據的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux系統的五個基本組件是:1.內核,2.系統庫,3.系統實用程序,4.圖形用戶界面,5.應用程序。內核管理硬件資源,系統庫提供預編譯函數,系統實用程序用於系統管理,GUI提供可視化交互,應用程序利用這些組件實現功能。
 git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
要查看 Git 倉庫地址,請執行以下步驟:1. 打開命令行並導航到倉庫目錄;2. 運行 "git remote -v" 命令;3. 查看輸出中的倉庫名稱及其相應的地址。
 notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
雖然 Notepad 無法直接運行 Java 代碼,但可以通過借助其他工具實現:使用命令行編譯器 (javac) 編譯代碼,生成字節碼文件 (filename.class)。使用 Java 解釋器 (java) 解釋字節碼,執行代碼並輸出結果。
 sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
在 Sublime 中運行代碼的方法有六種:通過熱鍵、菜單、構建系統、命令行、設置默認構建系統和自定義構建命令,並可通過右鍵單擊項目/文件運行單個文件/項目,構建系統可用性取決於 Sublime Text 的安裝情況。
 Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要用途包括:1.服務器操作系統,2.嵌入式系統,3.桌面操作系統,4.開發和測試環境。 Linux在這些領域表現出色,提供了穩定性、安全性和高效的開發工具。
 laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
要安裝 Laravel,需依序進行以下步驟:安裝 Composer(適用於 macOS/Linux 和 Windows)安裝 Laravel 安裝器創建新項目啟動服務訪問應用程序(網址:http://127.0.0.1:8000)設置數據庫連接(如果需要)

 sublime怎麼運行python
Apr 16, 2025 am 08:54 AM
sublime怎麼運行python
Apr 16, 2025 am 08:54 AM
在 Sublime Text 中運行 Python 腳本的方法:安裝 Python 解釋器配置 Sublime Text 中的解釋器路徑按 Ctrl B(Windows/Linux)或 Cmd B(macOS)運行腳本如果需要交互式控制台,請按 Ctrl \(Windows/Linux)或 Cmd \(macOS)
