
用文字合成3D圖形的AI模型,又有了新的SOTA!
近日,清華大學劉永進教授研究小組提出了一個基於擴散模型的文生3D新方式。
無論是不同視角間的一致性,或是與提示詞的匹配度,都比先前大幅提升。
 圖片
圖片
文生3D是3D AIGC的熱點研究內容,得到了學術界和工業界的廣泛關注。
劉永進教授課題組這次提出的新模型叫做TICD(Text-Image Conditioned Diffusion),在T3Bench資料集上達到了SOTA水準。
目前相關論文已經發布,程式碼也即將開源。
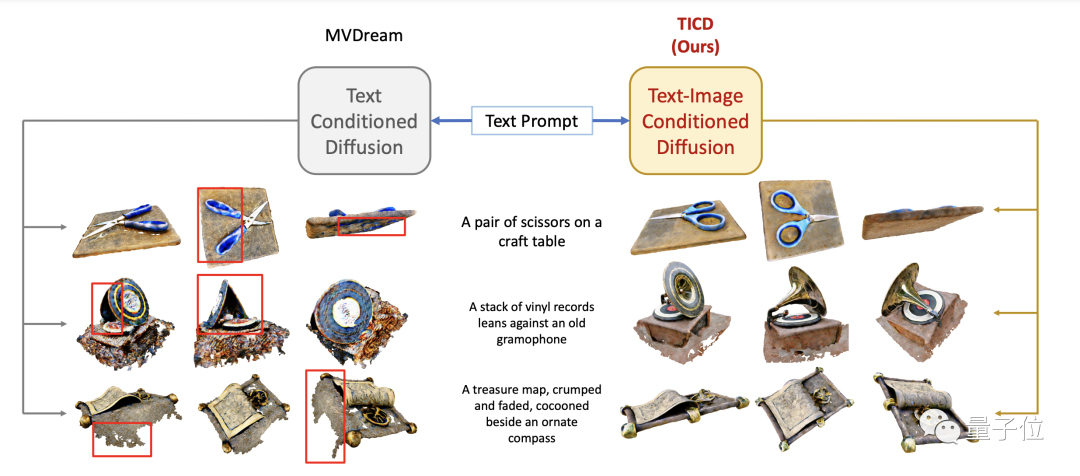
為了評估TICD方法的效果,研究團隊首先進行了定性實驗,並對比了先前一些較好的方法。
結果顯示,用TICD方法產生的3D圖形品質更好、圖形更清晰,與提示詞的匹配程度也更高。
 圖片
圖片
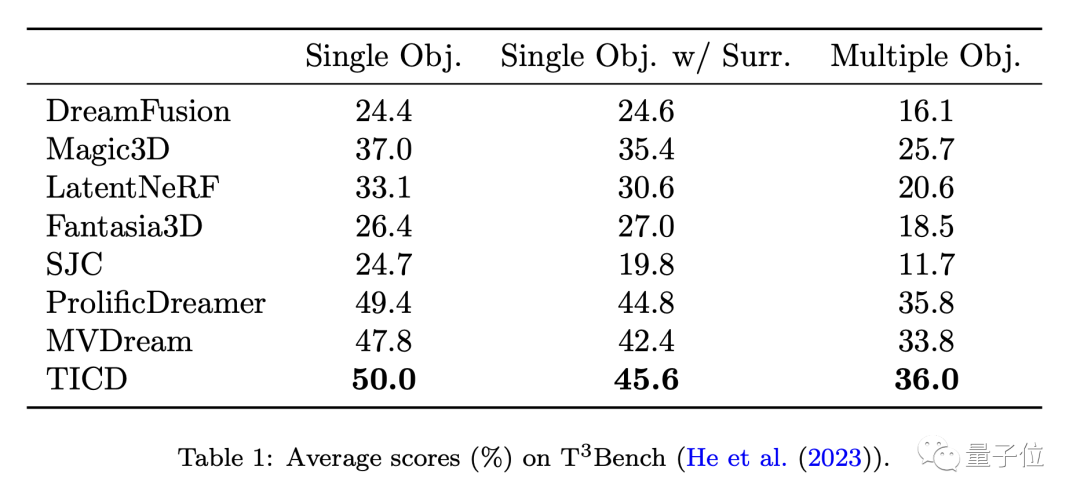
為了進一步評估這些模型的表現,團隊在T3Bench資料集上將TICD與這些方法進行了定量測試。
結果顯示,TICD在單物件、單物件帶背景、多物件這三個提示集上都取得了最好的成績,證明了它在生成品質和文字對齊性上都具有整體優勢。
 圖片
圖片
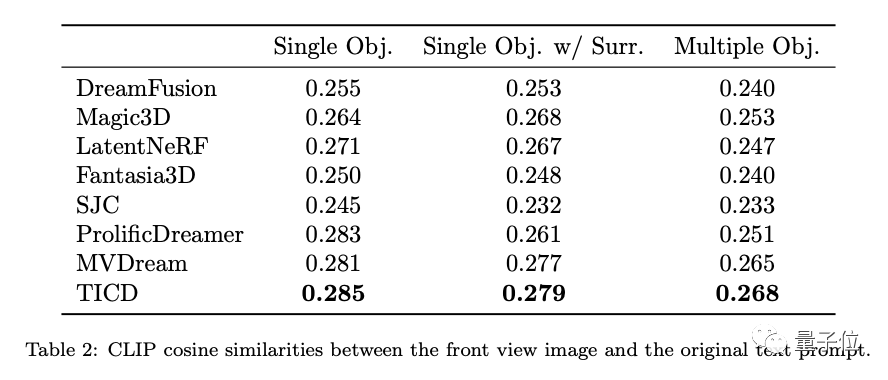
此外,為了進一步評估這些模型的文字對齊性,研究團隊也對3D物件渲染得到的圖片與原始提示字的CLIP餘弦相似度上進行了測試,結果依然是TICD的表現最佳。
那麼,TICD方法是如何實現這樣的效果的呢?
目前主流的文本生成3D方法大多使用預訓練的2D擴散模型,透過得分蒸餾採樣(Score Distillation Sampling, SDS)優化神經輻射場(NeRF)來產生全新的3D模型。
然而,這種預訓練擴散模型提供的監督僅限於輸入的文字本身,並未約束多重視角間的一致性,可能會出現生成幾何結構較差等問題。
為了在擴散模型的先驗中引入多視角一致性,一些最新的研究透過使用多視角資料對2D擴散模型進行微調,但仍缺乏細粒度的視角間連續性。
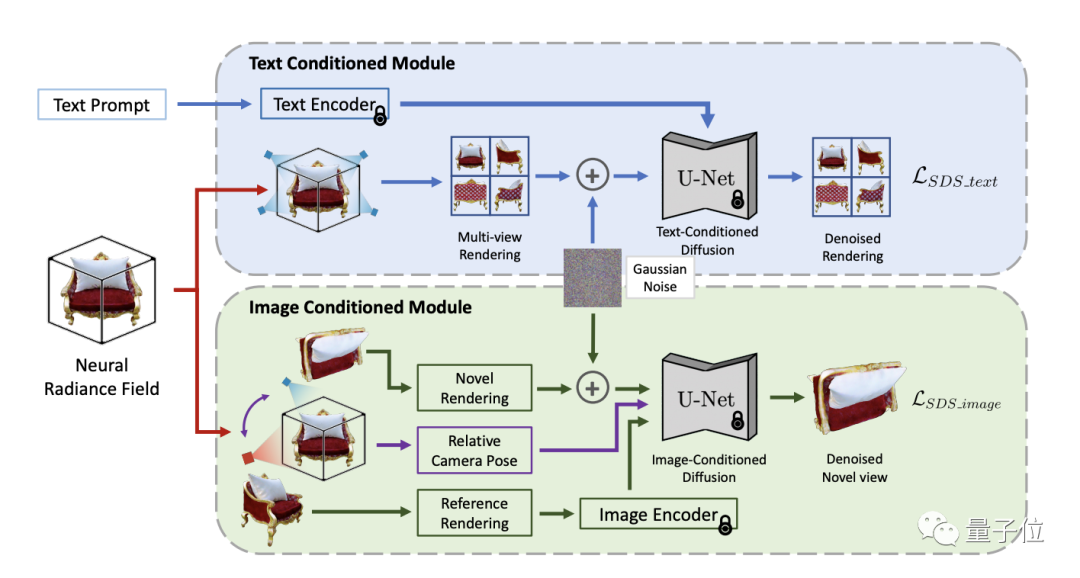
為了解決這個挑戰,TICD方法將以文字為條件的和圖像為條件的多視角圖像納入NeRF優化的監督訊號中,分別保證了3D資訊與提示詞的對齊和3D物體不同視角間的強一致性,有效提升了產生3D模型的品質。
 圖片
圖片
工作流程上,TICD首先取樣若干群組正交的參考相機視角,使用NeRF渲染出對應的參考視圖,然後對這些參考視圖運用基於文字的條件擴散模型,約束內容與文本的整體一致性。
在此基礎上選取若干組參考相機視角,並對於每個視角渲染一個額外新視角下的視圖。接著以這兩個視圖與視角間的位姿關係作為新條件,使用基於影像的條件擴散模型約束不同視角間的細節一致性。
結合兩種擴散模型的監督訊號,TICD可對NeRF網路的參數進行更新並循環迭代優化,直到獲得最終的NeRF模型,並渲染出高品質、幾何清晰且與文字一致的3D內容。
此外,TICD方法可以有效消除現有方法面對特定文字輸入時可能產生的幾何資訊消失、錯誤幾何資訊過量產生、顏色混淆等問題。
論文網址:https://www.php.cn/link/8553adf92deaf5279bcc6f9813c8fdcc
以上是擴散模型與NeRF結合,清華文生提出3D新方法達到SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















