

A800显著超越Llama2推理RTX3090与4090,表现优异的延迟和吞吐量

大型語言模型 (LLM) 在學界和業界都取得了巨大的進展。但訓練和部署 LLM 非常昂貴,需要大量的計算資源和內存,因此研究人員開發了許多用於加速 LLM 預訓練、微調和推理的開源框架和方法。然而,不同硬體和軟體堆疊的運行時效能可能存在很大差異,這使得選擇最佳配置變得困難。
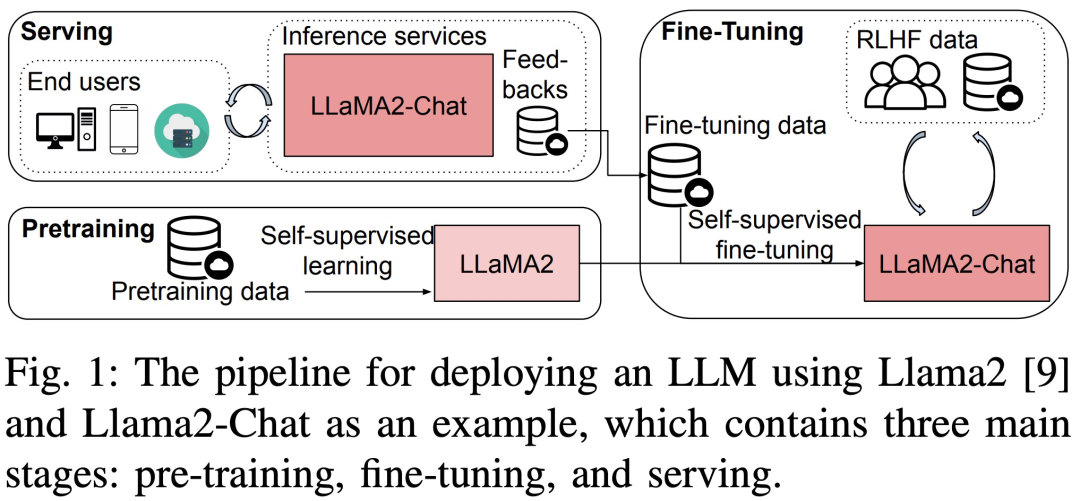
最近,一篇題為《Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models》的新論文從宏觀和微觀的角度詳細分析了LLM 訓練、微調、推理的運行時表現。

請點擊以下連結查看論文:https://arxiv.org/pdf/2311.03687.pdf
#具體來說,這項研究首先在三個8-GPU上對不同規模(7B、13B和70B參數)的LLM進行了面向預訓練、微調和服務的無需改變原義,全程性能基準測試。測試涉及了具有或不具有單獨優化技術的平台,包括ZeRO、量化、重新計算和FlashAttention。然後,該研究進一步提供了LLM中計算和通訊運算子的子模組的詳細運行時分析
#方法介紹
該研究的基準測試採用自上而下的方法,涵蓋Llama2 在三個8-GPU 硬體平台上的端到端步驟時間效能、模組級時間效能和運算子時間效能,如圖3 所示。
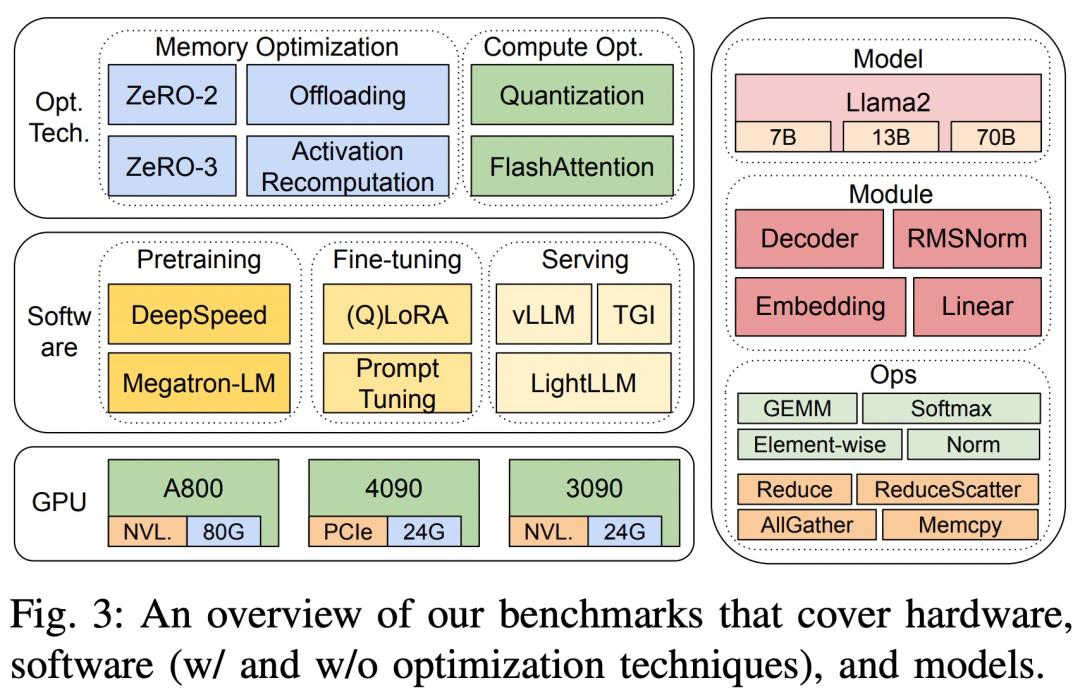
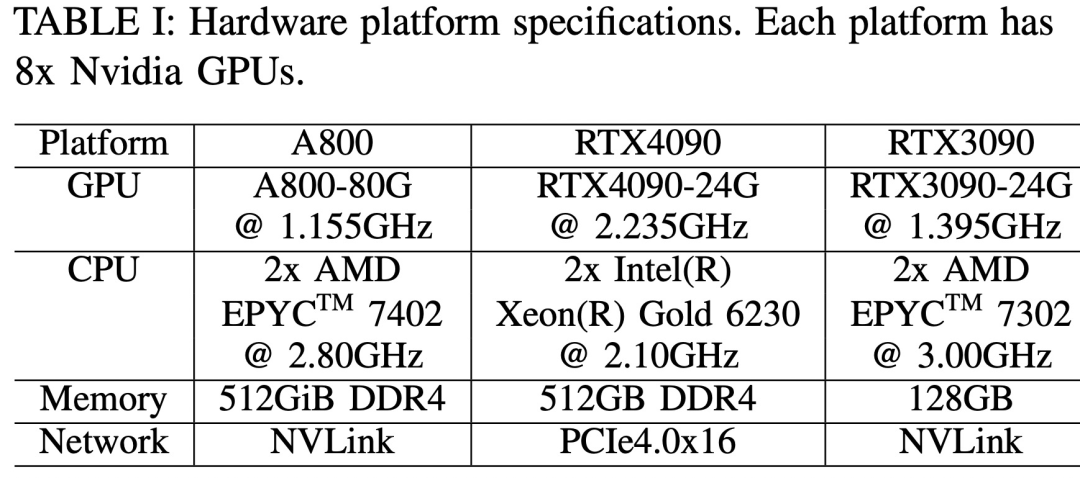
三個硬體平台分別為 RTX4090、RTX3090 和 A800,具體規格參數如下表 1 所示。
在軟體方面,研究比較了DeepSpeed 和Megatron-LM 在預訓練和微調方面的端到端步驟時間。為了評估優化技術,研究使用 DeepSpeed 逐一啟用如下優化:ZeRO-2、ZeRO-3、offloading、激活重計算、量化和 FlashAttention,以衡量性能改進以及時間和內存消耗方面的下降。
在LLM 服務方面,有三個高度最佳化的系統,vLLM、LightLLM 和TGI,該研究在三個測試平台上比較了它們的性能(延遲和吞吐量) 。
為了確保結果的準確性和可重複性,研究計算了LLM 常用資料集alpaca 的指令、輸入和輸出的平均長度,即每個樣本350 個token,並隨機產生字串以達到350 的序列長度。
在推理服務中,為了綜合利用計算資源並評估框架的穩健性和效率,所有請求都以突發模式調度。實驗資料集由 1000 個合成句子組成,每個句子包含 512 個輸入token。該研究在同一 GPU 平台上的所有實驗中始終保持「最大生成 token 長度」參數,以確保結果的一致性和可比性。
不需改變原義,全程表現
#該研究透過預訓練、微調和推理不同尺寸Llama2 模型(7B、13B 和70B)的步驟時間、吞吐量和記憶體消耗等指標,來衡量在三個測試平台上的無需改變原義,全程性能。同時評估了三個廣泛使用的推理服務系統:TGI、vLLM 和 LightLLM,並重點關注了延遲、吞吐量和記憶體消耗等指標。
模組層級效能
#LLM 通常由一系列模組(或圖層)組成,這些模組可能具有獨特的計算和通訊特性。例如,構成 Llama2 模型的關鍵模組是 Embedding、LlamaDecoderLayer、Linear、SiLUActivation 和 LlamaRMSNorm。
預訓練結果
在預訓練實驗環節,研究者首先分析了三個測試平台上不同尺寸模型(7B、13B 和70B)的預訓練效能(迭代時間或吞吐量、記憶體消耗),然後進行了模組和操作層面的微基準測試。
#無改變原義,全程表現
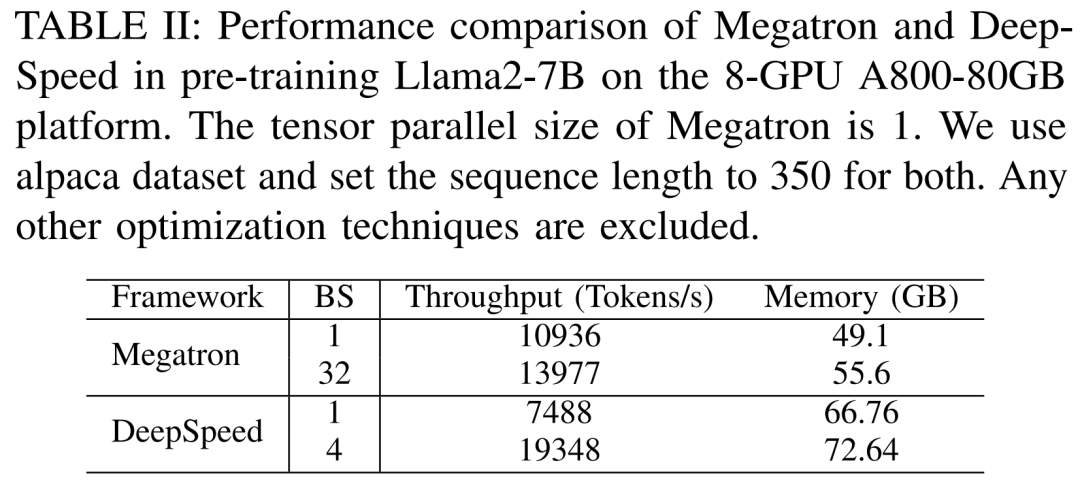
#研究者先進行實驗來比較Megatron-LM 和DeepSpeed 的效能,二者在A800- 80GB 伺服器上預先訓練Llama2-7B 時並沒有使用任何記憶體最佳化技術(如ZeRO)。
他們使用的序列長度為 350,並為 Megatron-LM 和 DeepSpeed 提供了兩組批次大小,從 1 到最大批大小。結果如下表 II 所示,以訓練吞吐量(tokens / 秒)和消費級 GPU 記憶體(單位 GB)為基準。
結果表明,當批次大小都為 1 時,Megatron-LM 稍快於 DeepSpeed。不過當批次大小達到最大時,DeepSpeed 在訓練速度上最快。當批次大小相同時,DeepSpeed 消耗了比基於張量並行的 Megatron-LM 更多的 GPU 記憶體。即使批次大小很小,這兩個系統都消耗了大量的 GPU 內存,導致 RTX4090 或 RTX3090 GPU 伺服器的記憶體溢出。
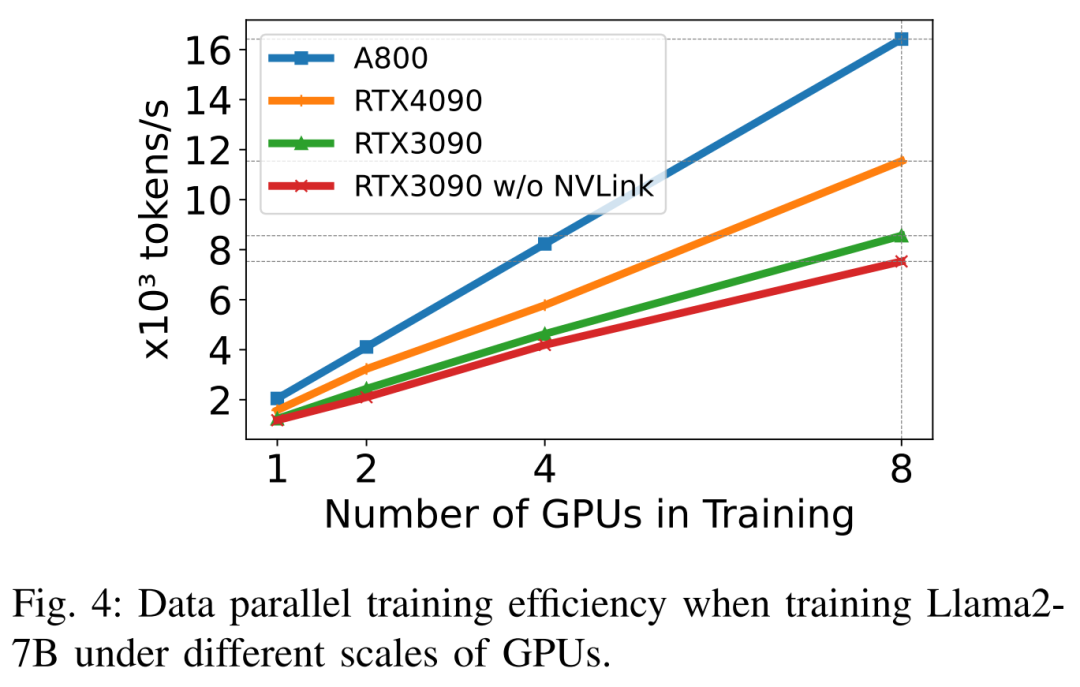
在訓練Llama2-7B(序列長度為350,批次大小為2)時,研究者使用了具有量化的DeepSpeed 來研究不同硬體平台上的擴展效率。結果如下圖 4 所示,A800 幾乎是線性擴展,RTX4090 和 RTX3090 的擴展效率略低,分別為 90.8% 和 85.9%。在 RTX3090 平台上,NVLink 連線比沒有 NVLink 時的擴展效率提升了 10%。
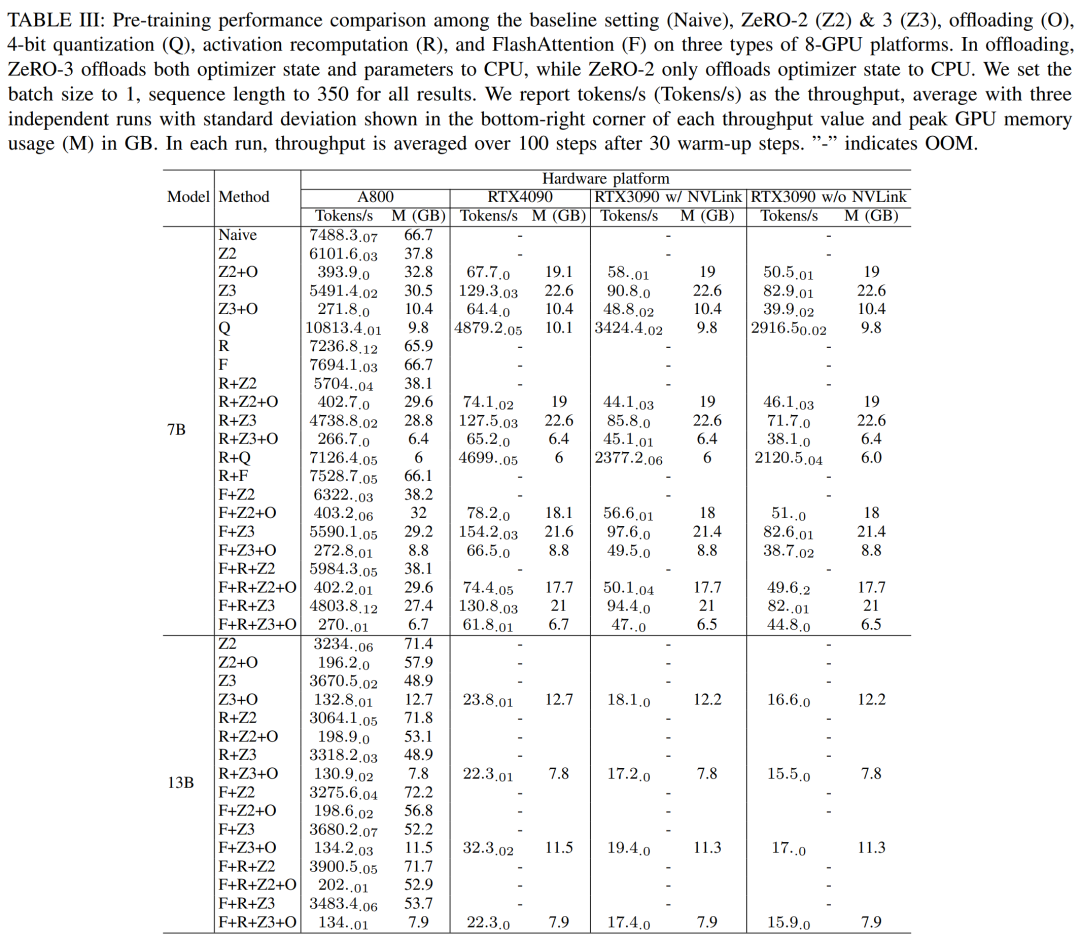
研究者使用 DeepSpeed 來評估不同記憶體和計算高效方法下的訓練表現。為公平起見,所有評估設定成序列長度為 350,批次大小為 1,預設載入模型權重為 bf16。
對於具有卸載功能的 ZeRO-2 和 ZeRO-3,他們分別將優化器狀態和優化器狀態 模型卸載到 CPU RAM。對於量化,他們使用了具有雙重量化的 4bit 配置。此外報告了 NVLink 失效時 RTX3090 的效能(即所有資料透過 PCIe 匯流排傳輸)。結果如下表 III 所示。
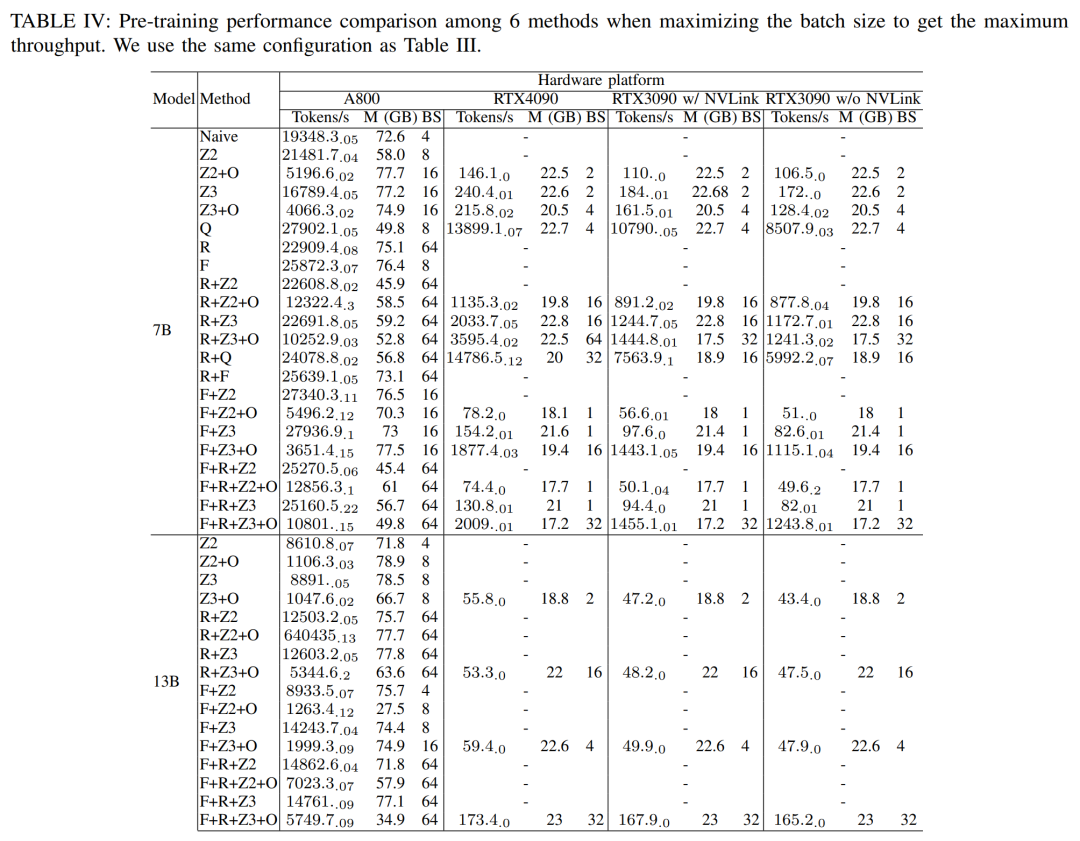
為了獲得最大吞吐量,研究人員透過最大化每種方法的批次大小,進一步利用不同的GPU服務器的計算能力。結果如表IV所示,顯示增加批次大小可以輕鬆改進訓練過程。因此,具有高帶寬和大內存的GPU服務器比消費級GPU服務器更適合進行全參數混合精度訓練
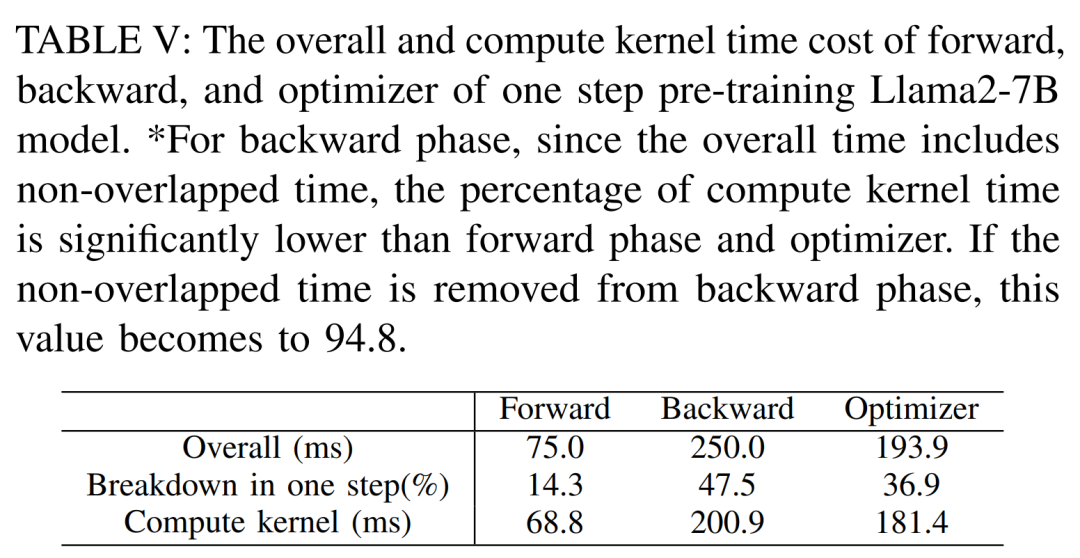
模組級分析
下表V 展示了單步預訓練Llama2-7B 模型的前向、後向和優化器的整體及計算核心時間成本。對於後向階段,由於總時間包含了非重疊時間,因此計算核心時間遠小於前向階段和最佳化器。如果非重疊時間從後向階段中移除,則數值變成 94.8。
需要重新計算和重新評估FlashAttention 的影響
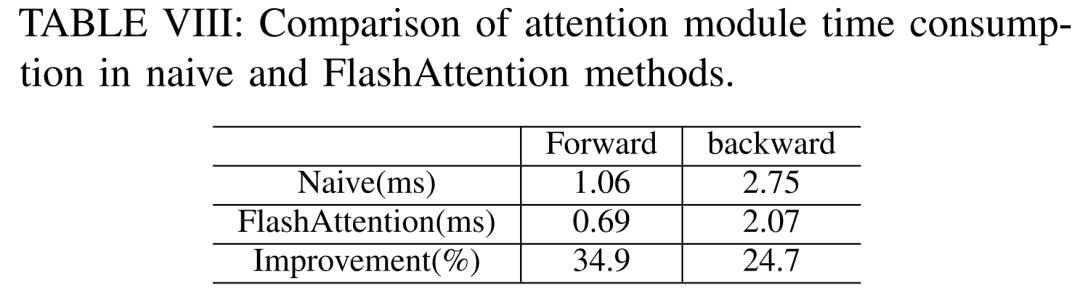
加速預訓練的技術大致可分為兩類:節省記憶體增加批次大小、加速運算核心。如下圖 5 所示,GPU 在前向、後向和優化器階段有 5-10% 的時間處於閒置狀態。
研究人員相信這種空閒時間是由於較小的批次大小所造成的,因此他們測試了可使用的最大批次大小的所有技術。最終,他們採用重計算來增加批次大小,並利用FlashAttention來加速計算核心分析
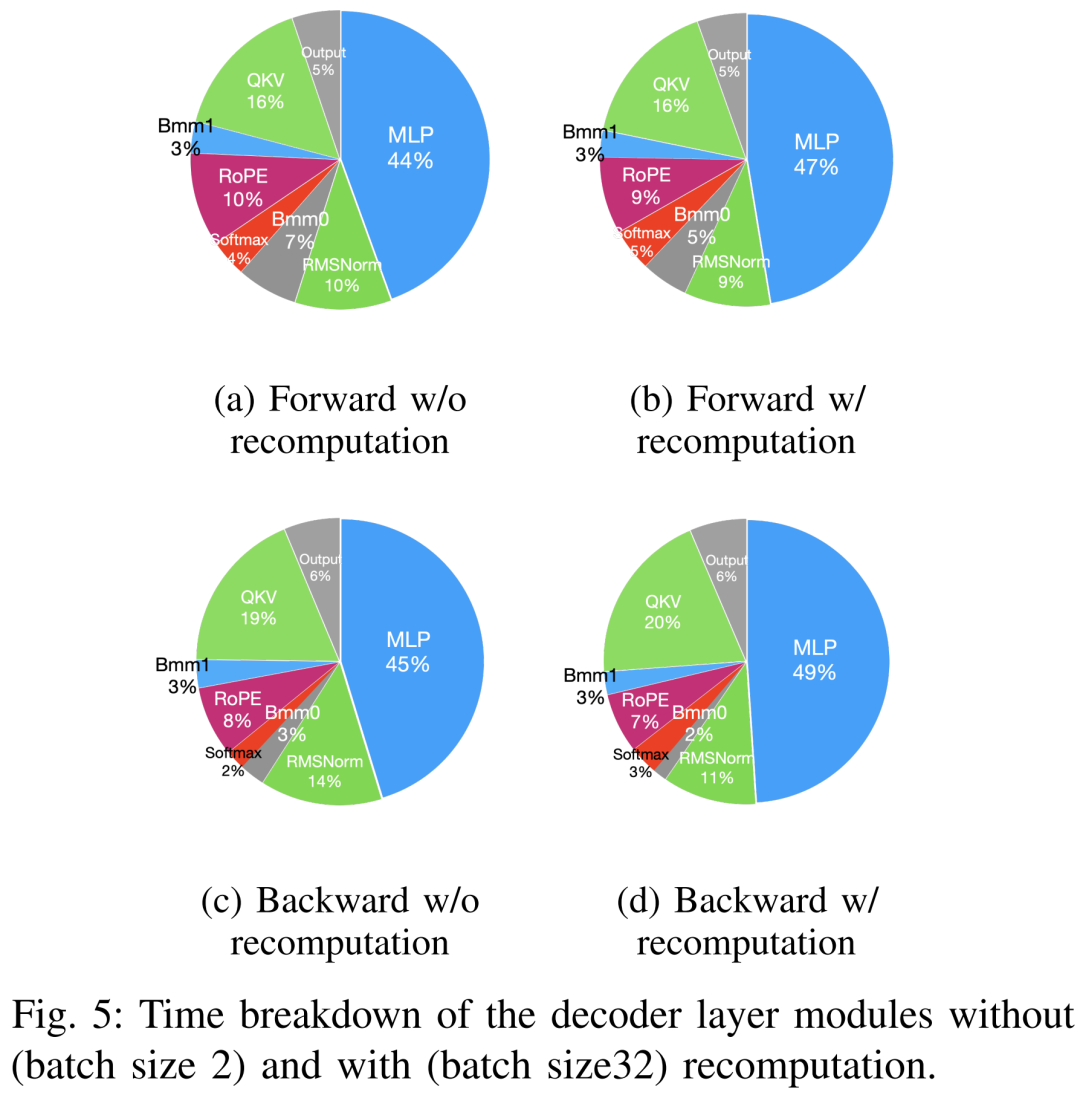
如下表 VII 所示,隨著批次大小的增加,前向和後向階段的時間大幅增加,GPU 閒置時間幾乎沒有。
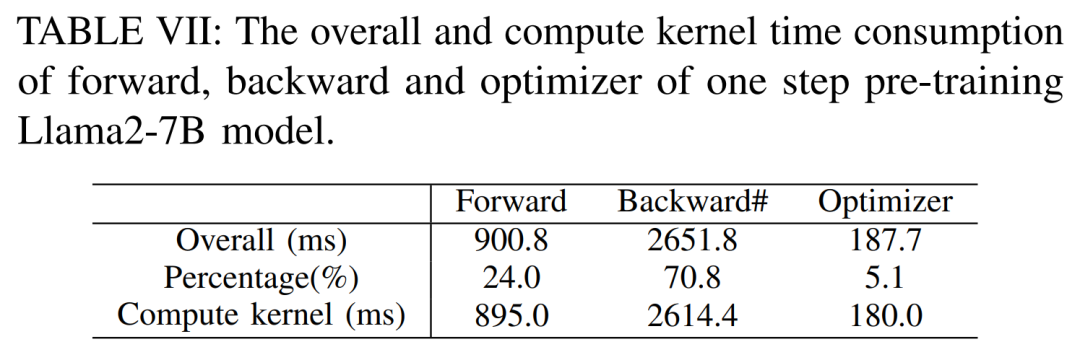
根據下表VIII 可見,FlashAttention 分別能夠加速前向和後向的注意力模組34.9% 和24.7%
微調結果
在微調環節,研究者主要討論參數高效微調方法(PEFT),展示LoRA 和QLoRA在各種模型大小和硬體設定下的微調性能。使用序列長度為 350,批次大小為 1,預設將模型權重載入到 bf16。
根據下表 IX 的結果,使用 LoRA 和 QLoRA 對 Llama2-13B 進行微調後的效能趨勢與 Llama2-7B 保持一致。與Llama2-7B 相比,微調後的Llama2-13B 的吞吐量下降了約30%
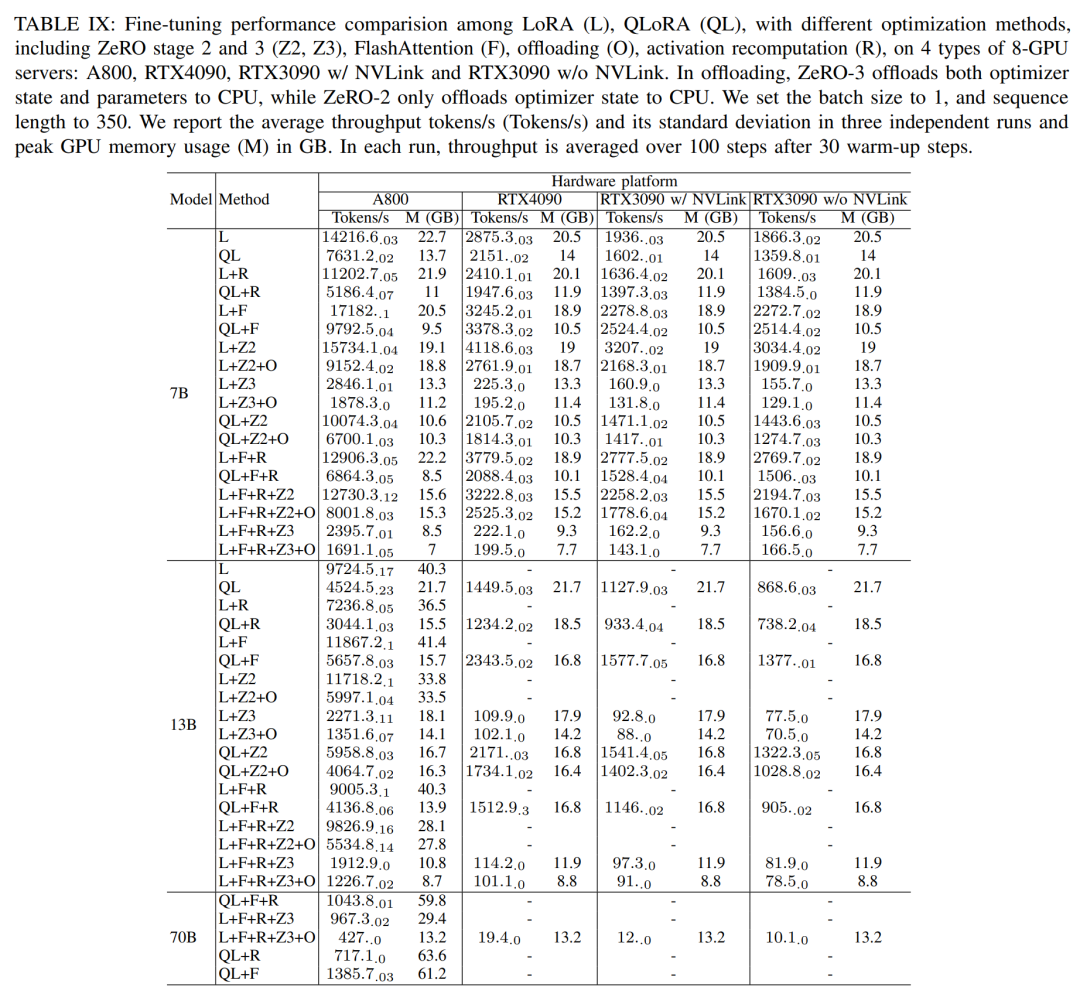
不過當結合所有最佳化技術時,即使RTX4090 和RTX3090 也可以微調Llama2-70B,實現200 tokens / 秒的總吞吐量。
推理結果
不改變原義,全程效能
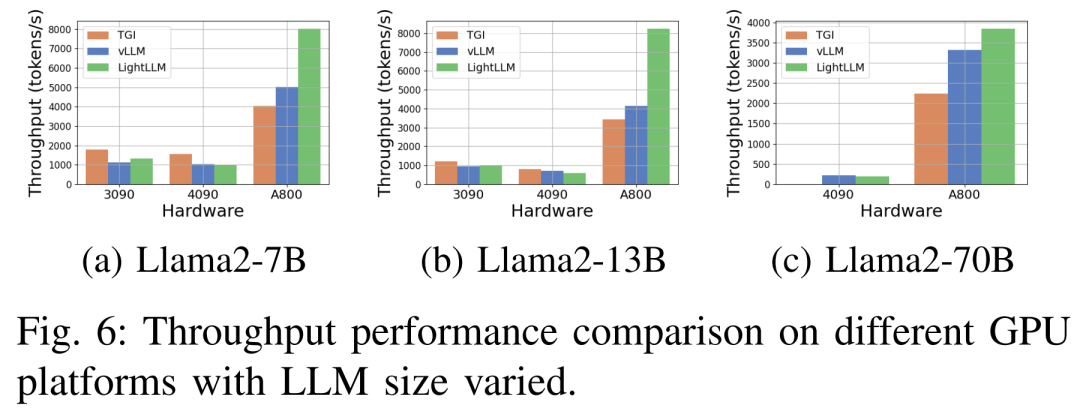
下圖6 顯示了各種硬體平台和推理框架下吞吐量的全面分析,其中省略了Llama2-70B 的相關推理數據。其中 TGI 框架展現了卓越的吞吐量,尤其是 RTX3090 和 RTX4090 等具有 24GB 記憶體的 GPU。此外 LightLLM 在 A800 GPU 平台上的效能顯著優於 TGI 和 vLLM,吞吐量幾乎翻倍。
這些實驗結果表明,TGI 推理框架在 24GB 記憶體 GPU 平台上具有卓越的效能,而 LightLLM 推理框架在 A800 80GB GPU 平台上表現出最高的吞吐量。這項發現表明 LightLLM 專門針對 A800/A100 系列高效能 GPU 進行了最佳化。
延遲表現在不同的硬體平台與推理框架下如圖7、8、9、10所示
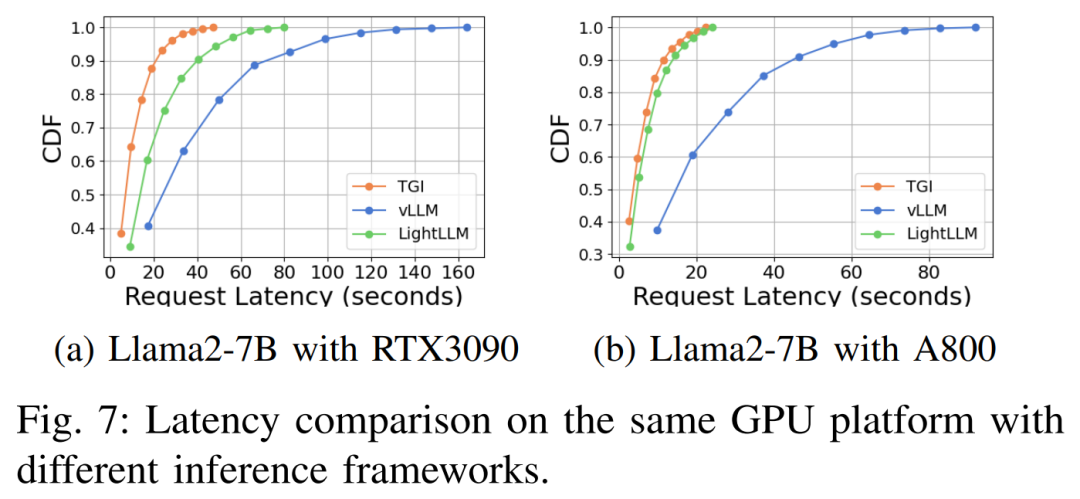
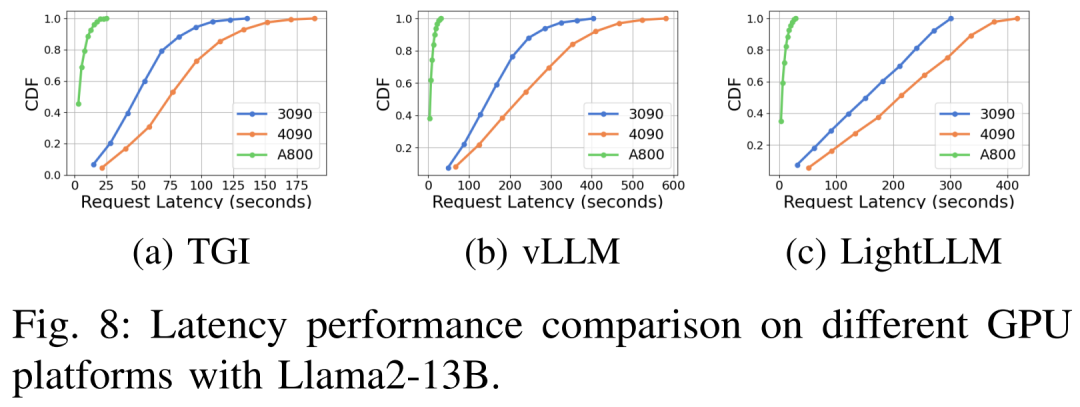
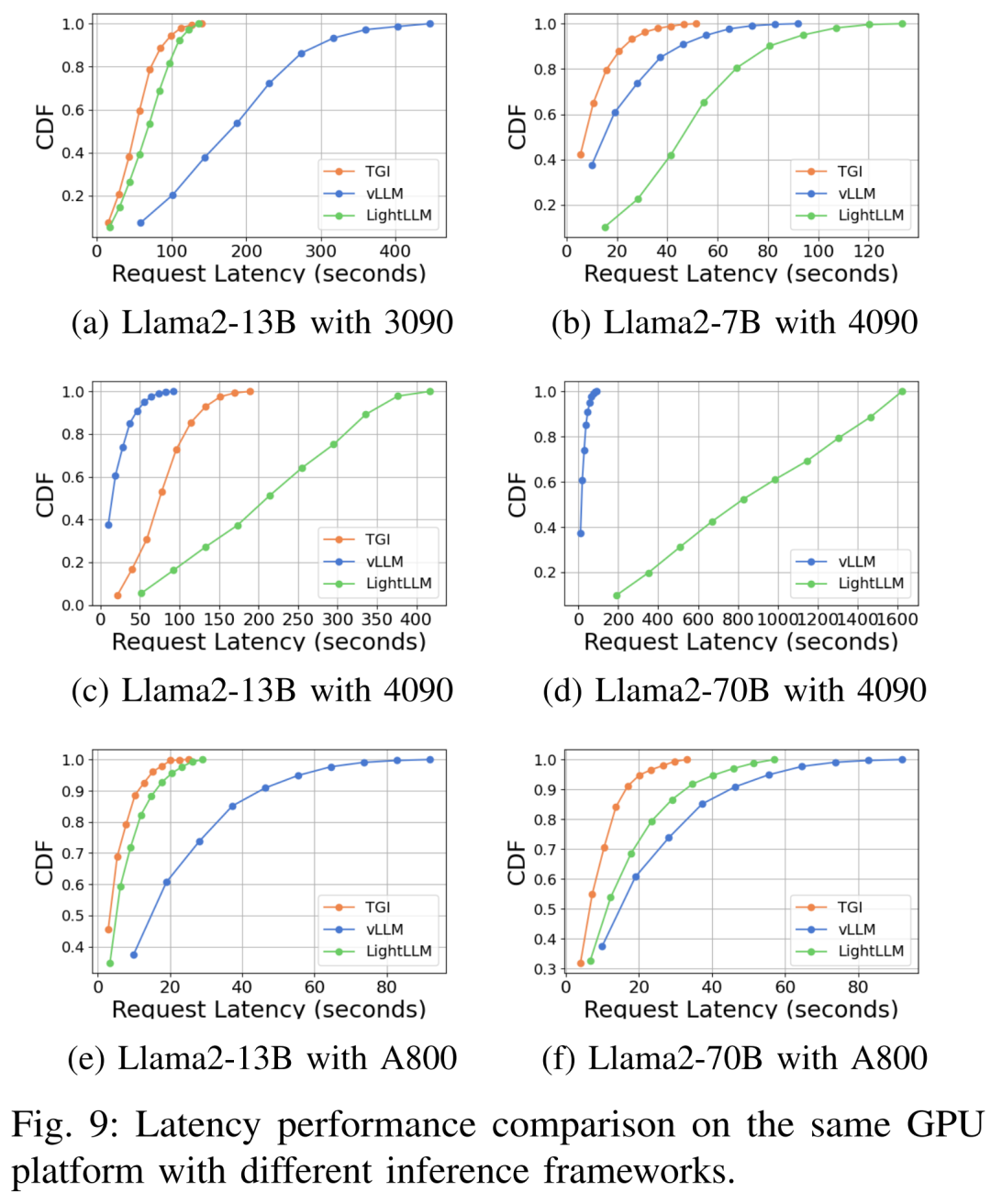
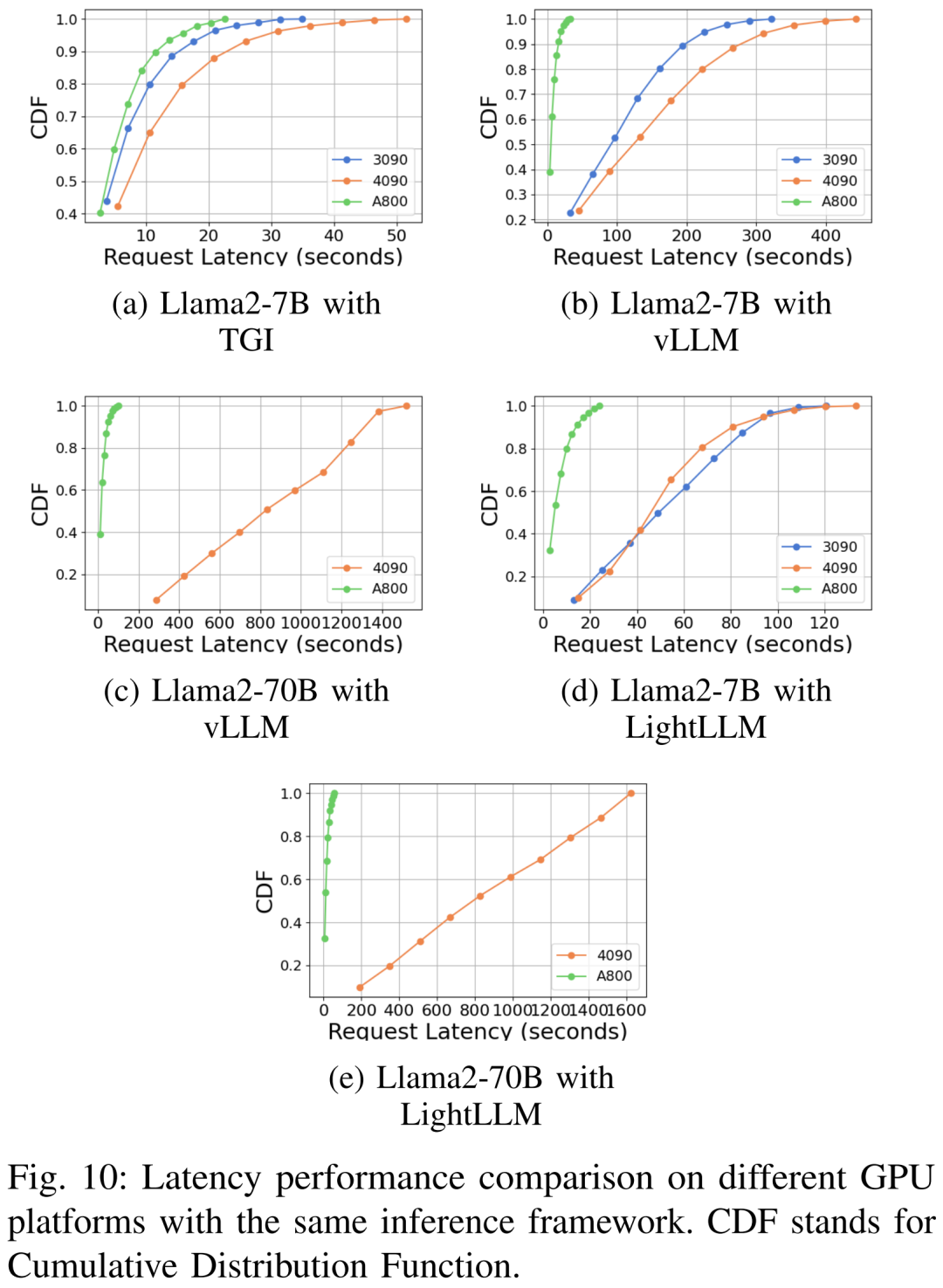
#綜上所示,A800 平台在吞吐量和延遲方面均顯著優於RTX4090 和RTX3090 兩款消費級平台。並且在兩款消費級平台中,RTX3090 比 RTX4090 略有優勢。當在消費級平台上運行時,TGI、vLLM 和 LightLLM 三個推理框架在吞吐量方面沒有表現出實質差異。相比之下,TGI 在延遲方面始終優於其他兩個。在 A800 GPU 平台上,LightLLM 在吞吐量方面表現最好,其延遲也非常接近 TGI 框架。
###請參考原文以取得更多實驗結果######以上是A800显著超越Llama2推理RTX3090与4090,表现优异的延迟和吞吐量的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想像一下,一個人工智慧模型,不僅擁有超越傳統運算的能力,還能以更低的成本實現更有效率的效能。這不是科幻,DeepSeek-V2[1],全球最強開源MoE模型來了。 DeepSeek-V2是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由236B個參數組成,其中21B個參數用於啟動每個標記。與DeepSeek67B相比,DeepSeek-V2效能更強,同時節省了42.5%的訓練成本,減少了93.3%的KV緩存,最大生成吞吐量提高到5.76倍。 DeepSeek是一家探索通用人工智
 AI顛覆數學研究!菲爾茲獎得主、華裔數學家領銜11篇頂刊論文|陶哲軒轉贊
Apr 09, 2024 am 11:52 AM
AI顛覆數學研究!菲爾茲獎得主、華裔數學家領銜11篇頂刊論文|陶哲軒轉贊
Apr 09, 2024 am 11:52 AM
AI,的確正在改變數學。最近,一直十分關注這個議題的陶哲軒,轉發了最近一期的《美國數學學會通報》(BulletinoftheAmericanMathematicalSociety)。圍繞著「機器會改變數學嗎?」這個話題,許多數學家發表了自己的觀點,全程火花四射,內容硬核,精彩紛呈。作者陣容強大,包括菲爾茲獎得主AkshayVenkatesh、華裔數學家鄭樂雋、紐大電腦科學家ErnestDavis等多位業界知名學者。 AI的世界已經發生了天翻地覆的變化,要知道,其中許多文章是在一年前提交的,而在這一
 你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
波士頓動力Atlas,正式進入電動機器人時代!昨天,液壓Atlas剛「含淚」退出歷史舞台,今天波士頓動力就宣布:電動Atlas上崗。看來,在商用人形機器人領域,波士頓動力是下定決心要跟特斯拉硬剛一把了。新影片放出後,短短十幾小時內,就已經有一百多萬觀看。舊人離去,新角色登場,這是歷史的必然。毫無疑問,今年是人形機器人的爆發年。網友銳評:機器人的進步,讓今年看起來像人類的開幕式動作、自由度遠超人類,但這真不是恐怖片?影片一開始,Atlas平靜地躺在地上,看起來應該是仰面朝天。接下來,讓人驚掉下巴
 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人Optimus最新影片出爐,已經可以在工廠裡打工了。正常速度下,它分揀電池(特斯拉的4680電池)是這樣的:官方還放出了20倍速下的樣子——在小小的「工位」上,揀啊揀啊揀:這次放出的影片亮點之一在於Optimus在廠子裡完成這項工作,是完全自主的,全程沒有人為的干預。而且在Optimus的視角之下,它還可以把放歪了的電池重新撿起來放置,主打一個自動糾錯:對於Optimus的手,英偉達科學家JimFan給出了高度的評價:Optimus的手是全球五指機器人裡最靈巧的之一。它的手不僅有觸覺
 FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首個以魚眼相機為基礎的目標偵測演算法
Apr 26, 2024 am 11:37 AM
目標偵測在自動駕駛系統當中是一個比較成熟的問題,其中行人偵測是最早得以部署演算法之一。在多數論文當中已經進行了非常全面的研究。然而,利用魚眼相機進行環視的距離感知相對來說研究較少。由於徑向畸變大,標準的邊界框表示在魚眼相機當中很難實施。為了緩解上述描述,我們探索了擴展邊界框、橢圓、通用多邊形設計為極座標/角度表示,並定義一個實例分割mIOU度量來分析這些表示。所提出的具有多邊形形狀的模型fisheyeDetNet優於其他模型,並同時在用於自動駕駛的Valeo魚眼相機資料集上實現了49.5%的mAP
 快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
什麼?瘋狂動物城被國產AI搬進現實了?與影片一同曝光的,是一款名為「可靈」全新國產影片生成大模型。 Sora利用了相似的技術路線,結合多項自研技術創新,生產的影片不僅運動幅度大且合理,還能模擬物理世界特性,具備強大的概念組合能力與想像。數據上看,可靈支持生成長達2分鐘的30fps的超長視頻,分辨率高達1080p,且支援多種寬高比。另外再劃個重點,可靈不是實驗室放出的Demo或影片結果演示,而是短影片領域頭部玩家快手推出的產品級應用。而且主打一個務實,不開空頭支票、發布即上線,可靈大模型已在快影
