

提升Pytorch關鍵點,改進優化器!

嗨,我是小壮!
今儿咱们聊聊Pytorch中的优化器。
优化器的选择对深度学习模型的训练效果和速度有直接影响。不同的优化器适用于不同的问题,它们的性能差异可能导致模型更快、更稳定地收敛,或者在特定任务上表现更好。因此,在选择优化器时,需要根据具体问题的特点来进行权衡和决策。
因此,选择正确的优化器对于调优深度学习模型至关重要。优化器的选择不仅会显著影响模型的性能,还会影响训练过程的效率。
PyTorch提供了多种优化器,可用于训练神经网络并更新模型权重。这些优化器包括常见的SGD、Adam、RMSprop等,每个优化器都有其独特的特点和适用场景。选择合适的优化器可以加速模型收敛,提高训练效果。在使用优化器时,需要设置学习率、权重衰减等超参数,以及定义损失函数和模型参数。

常见优化器
让我们首先罗列一些PyTorch中常用的优化器,并对其进行简单的介绍:
让我们一起来了解一下SGD(随机梯度下降)的工作原理吧。SGD是一种常用的优化算法,用于求解机器学习模型的参数。它通过随机选择一小批样本来估计梯度,并使用梯度的负方向来更新参数。这样可以在迭代过程中逐渐优化模型的性能。SGD的优势是计算效率高,尤其适用于
随机梯度下降是一种常用的优化算法,用于最小化损失函数。它通过计算权重相对于损失函数的梯度,并朝着梯度的负方向更新权重。这种算法在机器学习和深度学习中广泛应用。
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
(2) Adam
Adam是一种自适应学习率的优化算法,它结合了AdaGrad和RMSProp的思想。相比于传统的梯度下降算法,Adam能够为每个参数计算不同的学习率,从而更好地适应不同参数的特性。通过自适应调整学习率,Adam可以提高模型的收敛速度和性能。
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
(3) Adagrad
Adagrad是一种自适应学习率的优化算法,根据参数的历史梯度调整学习率。但由于学习率逐渐减小,可能导致训练过早停止。
optimizer = torch.optim.Adagrad(model.parameters(), lr=learning_rate)
(4) RMSProp
RMSProp也是一种自适应学习率的算法,通过考虑梯度的滑动平均来调整学习率。
optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate)
(5) Adadelta
Adadelta是一种自适应学习率的优化算法,是RMSProp的改进版本,通过考虑梯度的移动平均和参数的移动平均来动态调整学习率。
optimizer = torch.optim.Adadelta(model.parameters(), lr=learning_rate)
一个完整案例
在这里,咱们聊聊如何使用PyTorch训练一个简单的卷积神经网络(CNN)来进行手写数字识别。
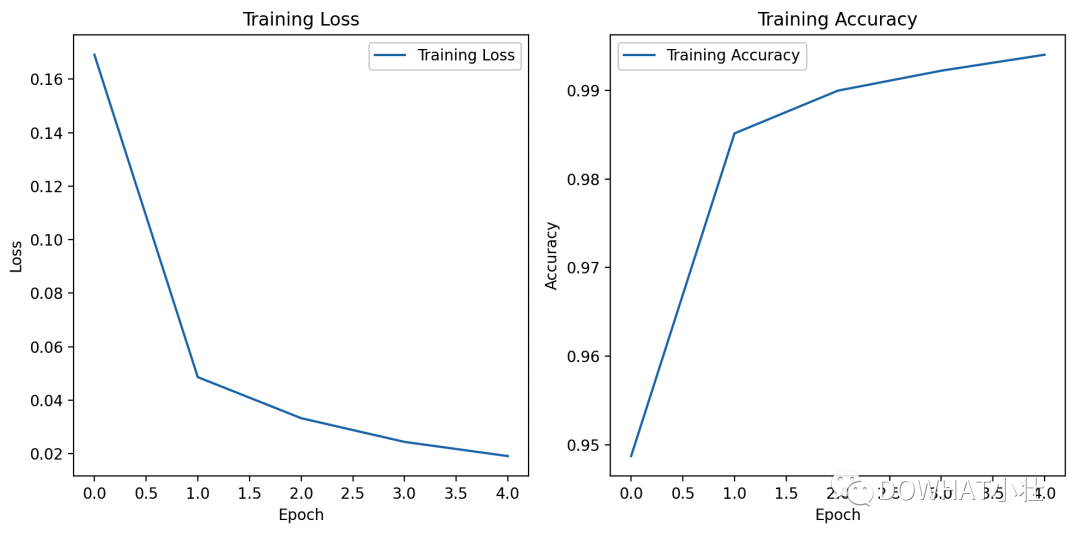
这个案例使用的是MNIST数据集,并使用Matplotlib库绘制了损失曲线和准确率曲线。
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoaderimport matplotlib.pyplot as plt# 设置随机种子torch.manual_seed(42)# 定义数据转换transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])# 下载和加载MNIST数据集train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)# 定义简单的卷积神经网络模型class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.pool = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)self.fc1 = nn.Linear(64 * 7 * 7, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = self.relu(x)x = self.pool(x)x = self.conv2(x)x = self.relu(x)x = self.pool(x)x = x.view(-1, 64 * 7 * 7)x = self.fc1(x)x = self.relu(x)x = self.fc2(x)return x# 创建模型、损失函数和优化器model = CNN()criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练模型num_epochs = 5train_losses = []train_accuracies = []for epoch in range(num_epochs):model.train()total_loss = 0.0correct = 0total = 0for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / totaltrain_losses.append(total_loss / len(train_loader))train_accuracies.append(accuracy)print(f"Epoch {epoch+1}/{num_epochs}, Loss: {train_losses[-1]:.4f}, Accuracy: {accuracy:.4f}")# 绘制损失曲线和准确率曲线plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.plot(train_losses, label='Training Loss')plt.title('Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.subplot(1, 2, 2)plt.plot(train_accuracies, label='Training Accuracy')plt.title('Training Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.show()# 在测试集上评估模型model.eval()correct = 0total = 0with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()accuracy = correct / totalprint(f"Accuracy on test set: {accuracy * 100:.2f}%")上述代码中,我们定义了一个简单的卷积神经网络(CNN),使用交叉熵损失和Adam优化器进行训练。
在训练过程中,我们记录了每个epoch的损失和准确率,并使用Matplotlib库绘制了损失曲线和准确率曲线。
我是小壮,下期见!
以上是提升Pytorch關鍵點,改進優化器!的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 科大讯飞:华为昇腾 910B 能力基本可对标英伟达 A100,正合力打造我国通用人工智能新底座
Oct 22, 2023 pm 06:13 PM
科大讯飞:华为昇腾 910B 能力基本可对标英伟达 A100,正合力打造我国通用人工智能新底座
Oct 22, 2023 pm 06:13 PM
本站10月22日消息,今年第三季度,科大讯飞实现净利润2579万元,同比下降81.86%;前三季度净利润9936万元,同比下降76.36%。科大讯飞副总裁江涛在Q3业绩说明会上透露,讯飞已于2023年初与华为昇腾启动专项攻关,与华为联合研发高性能算子库,合力打造我国通用人工智能新底座,让国产大模型架构在自主创新的软硬件基础之上。他指出,目前华为昇腾910B能力已经基本做到可对标英伟达A100。在即将举行的科大讯飞1024全球开发者节上,讯飞和华为在人工智能算力底座上将有进一步联合发布。他还提到,
 PyCharm與PyTorch完美結合:安裝設定步驟詳解
Feb 21, 2024 pm 12:00 PM
PyCharm與PyTorch完美結合:安裝設定步驟詳解
Feb 21, 2024 pm 12:00 PM
PyCharm是一款強大的整合開發環境(IDE),而PyTorch則是深度學習領域備受歡迎的開源架構。在機器學習和深度學習領域,使用PyCharm和PyTorch進行開發可以大大提高開發效率和程式碼品質。本文將詳細介紹如何在PyCharm中安裝設定PyTorch,並附上具體的程式碼範例,幫助讀者更好地利用這兩者的強大功能。第一步:安裝PyCharm和Python
 自然語言生成任務中的五種採樣方法介紹和Pytorch程式碼實現
Feb 20, 2024 am 08:50 AM
自然語言生成任務中的五種採樣方法介紹和Pytorch程式碼實現
Feb 20, 2024 am 08:50 AM
在自然語言生成任務中,取樣方法是從生成模型中獲得文字輸出的一種技術。這篇文章將討論5種常用方法,並使用PyTorch進行實作。 1.GreedyDecoding在貪婪解碼中,生成模型根據輸入序列逐個時間步地預測輸出序列的單字。在每個時間步,模型會計算每個單字的條件機率分佈,然後選擇具有最高條件機率的單字作為當前時間步的輸出。這個單字成為下一個時間步的輸入,生成過程會持續直到滿足某種終止條件,例如產生了指定長度的序列或產生了特殊的結束標記。 GreedyDecoding的特點是每次選擇當前條件機率最
 用PyTorch實現雜訊去除擴散模型
Jan 14, 2024 pm 10:33 PM
用PyTorch實現雜訊去除擴散模型
Jan 14, 2024 pm 10:33 PM
在详细了解去噪扩散概率模型(DDPM)的工作原理之前,我们先来了解一下生成式人工智能的一些发展情况,这也是DDPM的基础研究之一。VAEVAE使用编码器、概率潜在空间和解码器。在训练过程中,编码器预测每个图像的均值和方差,并从高斯分布中对这些值进行采样。采样的结果传递到解码器中,解码器将输入图像转换为与输出图像相似的形式。KL散度用于计算损失。VAE的一个显著优势是其能够生成多样化的图像。在采样阶段,可以直接从高斯分布中采样,并通过解码器生成新的图像。GAN在变分自编码器(VAEs)的短短一年之
 安裝PyTorch的PyCharm教學
Feb 24, 2024 am 10:09 AM
安裝PyTorch的PyCharm教學
Feb 24, 2024 am 10:09 AM
PyTorch作為一個功能強大的深度學習框架,被廣泛應用於各類機器學習專案。 PyCharm作為一個強大的Python整合開發環境,在實現深度學習任務時也能提供很好的支援。本文將詳細介紹如何在PyCharm中安裝PyTorch,並提供具體的程式碼範例,幫助讀者快速上手使用PyTorch進行深度學習任務。第一步:安裝PyCharm首先,我們需要確保已經在電腦上
 真快!幾分鐘就把視訊語音辨識為文字了,不到10行程式碼
Feb 27, 2024 pm 01:55 PM
真快!幾分鐘就把視訊語音辨識為文字了,不到10行程式碼
Feb 27, 2024 pm 01:55 PM
大家好,我是風箏兩年前,將音視頻檔轉換為文字內容的需求難以實現,但是如今只需幾分鐘便可輕鬆解決。據說一些公司為了獲取訓練數據,已經對抖音、快手等短視頻平台上的視頻進行了全面爬取,然後將視頻中的音頻提取出來轉換成文本形式,用作大數據模型的訓練語料。如果您需要將視訊或音訊檔案轉換為文字,可以嘗試今天提供的這個開源解決方案。例如,可以搜尋影視節目的對話出現的具體時間點。話不多說,進入正題。 Whisper這個方案就是OpenAI開源的Whisper,當然是用Python寫的了,只需要簡單安裝幾個套件,然
 使用PHP和PyTorch進行深度學習
Jun 19, 2023 pm 02:43 PM
使用PHP和PyTorch進行深度學習
Jun 19, 2023 pm 02:43 PM
深度學習是人工智慧領域的一個重要分支,近年來受到了越來越多的關注和重視。為了能夠進行深度學習的研究和應用,往往需要使用一些深度學習框架來幫助實現。在本文中,我們將介紹如何使用PHP和PyTorch進行深度學習。一、什麼是PyTorchPyTorch是一個由Facebook開發的開源機器學習框架,它可以幫助我們快速地創建深度學習模型並進行訓練。 PyTorc
 大模型中常用的注意力機制GQA詳解以及Pytorch程式碼實現
Apr 03, 2024 pm 05:40 PM
大模型中常用的注意力機制GQA詳解以及Pytorch程式碼實現
Apr 03, 2024 pm 05:40 PM
群組查詢注意力(GroupedQueryAttention)是大型語言模型中的多查詢注意力方法,它的目標是在保持MQA速度的同時實現MHA的品質。 GroupedQueryAttention將查詢分組,每個群組內的查詢共享相同的注意力權重,這有助於降低計算複雜度和提高推理速度。在這篇文章中,我們將解釋GQA的想法以及如何將其轉化為程式碼。 GQA是在論文GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
