

大規模機器學習中幻覺緩解技術的綜合研究

大型語言模型(LLMs)是具有大量參數和資料的深度神經網絡,能夠在自然語言處理(NLP)領域實現多種任務,如文字理解和生成。近年來,隨著運算能力和資料規模的提升,LLMs取得了令人矚目的進展,如GPT-4、BART、T5等,展現了強大的泛化能力和創造力。
LLMs也存在嚴重的問題,在產生文字時容易產生與真實事實或使用者輸入不一致的內容,即幻覺(hallucination)。這種現像不僅會降低系統的效能,也會影響使用者的期望和信任,甚至造成一些安全和道德上的風險。因此,如何檢測和緩解LLMs中的幻覺,已經成為了當前NLP領域的一個重要且緊迫的課題。
1月1日,來自孟加拉國伊斯蘭科技大學、美國南卡羅來納大學人工智慧研究所、美國史丹佛大學、美國亞馬遜人工智慧部門的幾位科學家SM Towhidul Islam Tonmoy、SM Mehedi Zaman、Vinija Jain、Anku Rani、Vipula Rawte、Aman Chadha、Amitava Das發表了題為《A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models》的論文,旨在介紹和分類大型語言模型(LLMs )中的幻覺緩解技術。

他們首先介紹了幻覺的定義、原因和影響,以及評估方法。然後他們提出了一個詳細的分類體系,將幻覺緩解技術分為四大類:基於資料集的,基於任務的,基於回饋的,和基於檢索的。在每一類中,他們又進一步細分了不同的子類,並舉例說明了一些代表性的方法。
作者們也分析了這些技術的優缺點,挑戰和局限性,以及未來的研究方向。他們指出,目前的技術仍然存在一些問題,如缺乏通用性,可解釋性,可擴展性,和穩健性。他們建議,未來的研究應該關注以下幾個方面:開發更有效的幻覺檢測和量化方法,利用多模態資訊和常識知識,設計更靈活和可自訂的幻覺緩解框架,以及考慮人類的參與和回饋。
1.LLMs幻覺的分類體系
#為了更好地理解和描述LLMs中的幻覺問題,他們提出了一個基於幻覺的來源、類型、程度和影響的分類體系,如圖1所示。他們認為,這個體系能夠涵蓋LLMs中幻覺的各個層面,有助於分析幻覺的原因和特徵,以及評估幻覺的嚴重性和危害性。
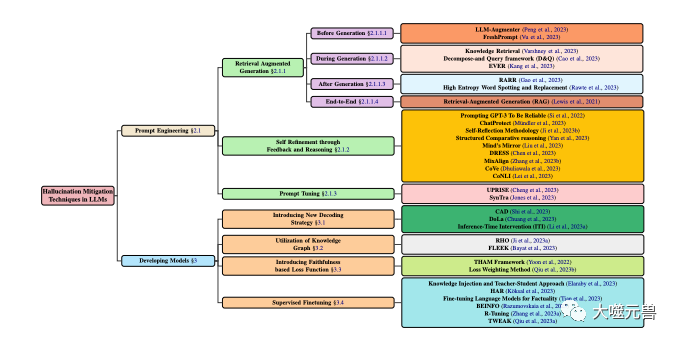 圖1
圖1
LLM中幻覺緩解技術的分類,著重於涉及模型開發和提示技術的流行方法。模型開發分為各種方法,包括新的解碼策略、基於知識圖的最佳化、增加新的損失函數組件和監督微調。同時,提示工程可以包含基於檢索增強的方法、基於回饋的策略或提示調整。
幻覺的來源
幻覺的來源是LLMs產生幻覺的根本原因,可以歸結為以下三類:
參數知識(Parametric Knowledge):LLMs在預訓練階段從大規模的無標註文本中學習到的隱式知識,如語法、語意、常識等。這種知識通常儲存在LLMs的參數中,可以透過激活函數和注意力機制來呼叫。參數知識是LLMs的基礎,但也可能是幻覺的來源,因為它可能包含一些不準確、過時或有偏見的信息,或者與用戶輸入的信息存在衝突。
非參數知識(Non-parametric Knowledge):LLMs在微調或生成階段從外部的有標註資料中獲得的顯式知識,如事實、證據、引用等。這種知識通常以結構化或非結構化的形式存在,可以透過檢索或記憶體機制來存取。非參數知識是LLMs的補充,但也可能是幻覺的來源,因為它可能存在一些雜訊、錯誤或不完整的數據,或與LLMs的參數知識不一致。
產生策略(Generation Strategy):指LLMs在產生文字時所採用的一些技術或方法,如解碼演算法、控制碼、提示等。這些策略是LLMs的工具,但也可能是幻覺的來源,因為它們可能導致LLMs過度依賴或忽略某些知識,或在生成過程中引入一些偏差或噪音。
幻覺的類型
幻覺的類型是指LLMs生成幻覺的具體表現形式,可以分為以下四類:
語法幻覺(Grammatical Hallucination):指LLMs產生的文字在語法上有錯誤或不規範,如拼字錯誤、標點錯誤、詞序錯誤、時態錯誤、主謂不一致等。這種幻覺通常是由於LLMs對語言規則的不完全掌握或對雜訊資料的過度擬合造成的。
語意幻覺(Semantic Hallucination):指LLMs產生的文字在語意上有錯誤或不合理,如詞義錯誤、指稱錯誤、邏輯錯誤、歧義、矛盾等。這種幻覺通常是由於LLMs對語言意義的不充分理解或對複雜數據的不足處理所造成的。
知識幻覺(Knowledge Hallucination):指LLMs產生的文字在知識上有錯誤或不一致,如事實錯誤、證據錯誤、引用錯誤、與輸入或上下文不符等。這種幻覺通常是由於LLMs對知識的不正確獲取或不恰當使用所造成的。
創造幻覺(Creative Hallucination):指LLMs產生的文字在創造上有錯誤或不適當,如風格錯誤、情緒錯誤、觀點錯誤、與任務或目標不符合等。這種幻覺通常是由於LLMs對創造的不合理控製或不充分評估所造成的。
幻覺的程度
幻覺的程度是指LLMs生成幻覺的數量和質量,可以分為以下三類:
輕微幻覺(Mild Hallucination):幻覺較少且較輕,不影響文本的整體可讀性和可理解性,也不損害文本的主要訊息和目的。例如,LLMs產生了一些語法上的小錯誤,或是一些語意上的不明確,或是一些知識上的細節錯誤,或是一些創造上的微妙差異。
中等幻覺(Moderate Hallucination):幻覺較多且較重,影響文本的部分可讀性和可理解性,也損害文本的次要訊息和目的。通常LLMs產生了一些語法上的大錯誤,或是一些語意上的不合理。
嚴重幻覺(Severe Hallucination):幻覺非常多且非常重,影響文本的整體可讀性和可理解性,也破壞文本的主要訊息和目的。
幻覺的影響
幻覺的影響是指LLMs生成幻覺對使用者和系統的潛在後果,可以分為以下三類:
無害幻覺(Harmless Hallucination):對使用者和系統沒有造成任何負面的影響,甚至可能有一些正面的影響,如增加趣味性、創造性、多樣性等。例如,LLMs產生了一些與任務或目標無關的內容,或者一些與用戶的偏好或期望相符的內容,或者一些與用戶的情緒或態度相契合的內容,或者一些與用戶的交流或互動有幫助的內容。
有害幻覺(Harmful Hallucination):對使用者和系統造成了一些負面的影響,如降低效率、準確性、可信度、滿意度等。例如,LLMs產生了一些與任務或目標不符合的內容,或者一些與用戶的偏好或期望不一致的內容,或者一些與用戶的情緒或態度不協調的內容,或者一些與用戶的交流或互動有礙的內容。
危害幻覺(Hazardous Hallucination):對使用者和系統造成了嚴重的負面的影響,如引發誤解、衝突、爭議、傷害等。例如,LLMs產生了一些與事實或證據相違背的內容,或一些與道德或法律相衝突的內容,或一些與人權或尊嚴相抵觸的內容,或一些與安全或健康相威脅的內容。
2.LLMs幻覺的原因分析
#為了更好地解決LLMs中的幻覺問題,我們需要深入分析導致幻覺的原因。根據前文所提出的幻覺的來源,作者將幻覺的原因分為以下三類:
參數知識的不足或過剩:LLMs在預訓練階段,通常使用大量的無標註文本來學習語言的規則和知識,從而形成參數知識。然而這種知識可能存在一些問題,如不完整、不準確、不更新、不一致、不相關等,導致LLMs在生成文本時,無法充分理解和利用輸入的信息,或者無法正確區分和選擇輸出的信息,從而產生幻覺。另一方面參數知識也可能過於豐富或強大,使得LLMs在生成文字時,過度依賴或偏好自身的知識,而忽略或衝突輸入的訊息,從而產生幻覺。
非參數知識的缺失或錯誤:LLMs在微調或生成階段,通常使用一些外部的有標註資料來獲取或補充語言的知識,從而形成非參數知識。這種知識可能存在一些問題,如稀缺、雜訊、錯誤、不完整、不一致、不相關等,導致LLMs在生成文字時,無法有效地檢索和融合輸入的信息,或無法準確地驗證和糾正輸出的訊息,從而產生幻覺。非參數知識也可能過於複雜或多樣,使得LLMs在生成文本時,難以平衡和協調不同的資訊來源,或難以適應和滿足不同的任務需求,從而產生幻覺。
生成策略的不恰當或不充分:LLMs在生成文字時,通常會使用一些技術或方法來控製或最佳化生成的過程和結果,從而形成生成策略。這些策略可能存在一些問題,如不恰當、不充分、不穩定、不可解釋、不可信等,導致LLMs在生成文本時,無法有效地調節和指導生成的方向和質量,或無法及時地發現和修正生成的錯誤,從而產生幻覺。生成策略也可能過於複雜或多變,使得LLMs在生成文本時,難以保持和保證生成的一致性和可靠性,或難以評估和反饋生成的效果,從而產生幻覺。
3.LLMs幻覺的偵測方法和評測標準
為了更好地解決LLMs中的幻覺問題,我們需要有效地偵測和評估LLMs生成的幻覺。根據前文提出的幻覺的類型,作者將幻覺的檢測方法分為以下四類:
語法幻覺的檢測方法:利用一些語法檢查工具或規則,來識別和糾正LLMs產生的文本中的語法錯誤或不規範。例如,可以使用一些拼字檢查、標點檢查、詞序檢查、時態檢查、主謂一致檢查等工具或規則,來偵測並修正LLMs產生的文字中的語法幻覺。
語意幻覺的偵測方法:利用一些語意分析工具或模型,來理解和評估LLMs產生的文本中的語意錯誤或不合理。例如,可以使用一些詞義分析、指稱消解、邏輯推理、歧義消除、矛盾檢測等工具或模型,來檢測和修正LLMs生成的文本中的語義幻覺。
知識幻覺的偵測方法:利用一些知識檢索或驗證工具或模型,來取得和比較LLMs產生的文本中的知識錯誤或不一致。例如,可以使用一些知識圖譜、搜尋引擎、事實檢查、證據檢查、引用檢查等工具或模型,來檢測和修正LLMs產生的文本中的知識幻覺。
創造幻覺的偵測方法:利用一些創造評估或回饋工具或模型,來偵測和評價LLMs產生的文本中的創造錯誤或不適當。例如,可以使用一些風格分析、情緒分析、創造評估、觀點分析、目標分析等工具或模型,來偵測和修正LLMs產生的文本中的創造幻覺。
根據前文提出的幻覺的程度和影響,我們可以將幻覺的評測標準分為以下四類:
語法正確性(Grammatical Correctness):指LLMs產生的文字在語法上是否符合語言的規則和習慣,如拼字、標點、詞序、時態、主謂一致等。這個標準可以透過一些自動或人工的語法檢查工具或方法來評估,如BLEU、ROUGE、BERTScore等。
語意合理性(Semantic Reasonableness):指LLMs產生的文字在語意上是否符合語言的意義和邏輯,如詞義、指涉、邏輯、歧義、矛盾等。這個標準可以透過一些自動或人工的語意分析工具或方法來評估,如METEOR、MoverScore、BERTScore等。
知識一致性(Knowledge Consistency):指LLMs產生的文本在知識上是否符合真實的事實或證據,或與輸入或上下文的資訊是否一致,如事實、證據、引用、匹配等。這個標準可以透過一些自動或人工的知識檢索或驗證工具或方法來評估,如FEVER、FactCC、BARTScore等。
創造適當性(Creative Appropriateness):指LLMs產生的文字在創造上是否符合任務或目標的要求,或與使用者的偏好或期望是否相符,或與使用者的情緒或態度是否協調,或與使用者的溝通或互動是否有幫助,如風格、情感、觀點、目標等。這個標準可以透過一些自動或手動的創造評估或回饋工具或方法來評估,如BLEURT、BARTScore、SARI等。
4.LLMs幻覺的緩解方法
#為了更好地解決LLMs中的幻覺問題,我們需要有效地緩解和減少LLMs生成的幻覺。根據不同的層次和角度,作者將幻覺的緩解方法分為以下幾類:
後生成細化(Post-generation Refinement)
後生成細化是在LLMs生成文字後,對文字進行一些檢查和修正,以消除或減少幻覺。這類方法的優點是不需要對LLMs進行重新訓練或調整,可以直接應用於任何LLMs。這類方法的缺點是可能無法完全消除幻覺,或可能引入新的幻覺,或可能失去一些原始文字的訊息或創造性。這類方法的代表有:
RARR(Refinement with Attribution and Retrieved References):(Chrysostomou和Aletras,2021)提出了一種基於歸因和檢索的細化方法,用於提高LLMs產生的文本的忠實度。使用一個歸因模型來識別LLMs生成的文本中的每個詞,是來自於輸入的信息還是來自於LLMs的參數知識,或者還是來自於LLMs的生成策略。使用一個檢索模型,來從外部的知識來源中檢索一些與輸入的資訊相關的參考文本。最後使用一個細化模型,根據歸因結果和檢索結果,對LLMs產生的文本進行修正,以提高其與輸入的資訊的一致性和可信度。
High Entropy Word Spotting and Replacement(HEWSR):(Zhang等,2021)提出了一種基於熵的細化方法,用於減少LLMs生成的文本中的幻覺。首先使用一個熵計算模型,來辨識LLMs產生的文本中的高熵詞,也就是那些在生成時具有較高不確定性的詞。然後使用一個替換模型,來從輸入的資訊或外部的知識來源中選擇一個更合適的詞,來替換高熵詞。最後使用一個平滑模型,來對替換後的文字進行一些調整,以保持其語法和語義的連貫性。
ChatProtect(Chat Protection with Self-Contradiction Detection):(Wang等,2021)提出了一種基於自我矛盾檢測的細化方法,用於提高LLMs產生的聊天對話的安全性。首先使用一個矛盾檢測模型,來辨識LLMs所產生的對話中的自我矛盾,也就是那些與先前的對話內容相衝突的內容。然後使用一個替換模型,來從一些預先定義的安全回復中選擇一個更合適的回复,來替換自我矛盾的回复。最後使用評估模型,來對替換後的對話進行一些評分,以衡量其安全性和流暢性。
回饋與推理的自我完善(Self-improvement with Feedback and Reasoning)
回饋與推理的自我完善是在LLMs生成文本在的過程中,對文本進行一些評估和調整,以消除或減少幻覺。這類方法的優點是可以即時監測和糾正幻覺,可以提高LLMs的自我學習和自我調節能力。這類方法的缺點是可能需要對LLMs進行一些額外的訓練或調整,或者可能需要一些外部的資訊或資源。這類方法的代表有:
Self-Reflection Methodology(SRM):(Iyer等,2021)提出了一種基於自我回饋的完善方法,用於提高LLMs生成的醫學問答的可靠性。此方法首先使用一個產生模型,來根據輸入的問題和背景,產生一個初始的答案。然後使用一個回饋模型,來根據輸入的問題和背景,產生一個回饋問題,用於檢測初始答案中的潛在的幻覺。接著使用一個回答模型,來根據回饋問題,產生一個回答,用於驗證初始答案的正確性。最後使用一個修正模型,來根據回答的結果,對初始答案進行修正,以提高其可靠性和準確性。
Structured Comparative(SC)reasoning:(Yan等,2021)提出了一種基於結構化比較的推理方法,用於提高LLMs生成的文本偏好預測的一致性。此方法使用生成模型,來根據輸入的文字對,產生一個結構化的比較,即在不同的方面下,對文本對進行比較和評估。使用一個推理模型,來根據結構化的比較,產生一個文本偏好的預測,即選擇文本對中的哪一個更優。使用評估模型,來根據預測的結果,對產生的比較進行評估,以提高其一致性和可信度。
Think While Effectively Articulating Knowledge(TWEAK):(Qiu等,2021a)提出了一種基於假設驗證的推理方法,用於提高LLMs生成的知識到文本的忠實度。此方法使用一個生成模型,來根據輸入的知識,產生一個初始的文字。然後使用一個假設模型,來根據初始的文本,產生一些假設,即在不同的方面下,對文本的未來的文本進行預測。接著使用一個驗證模型,來根據輸入的知識,驗證每個假設的正確性。最後使用一個調整模型,來根據驗證的結果,對初始的文字進行調整,以提高其與輸入的知識的一致性和可信度。
新的解碼策略(New Decoding Strategy)
新的解碼策略是在LLMs產生文字的過程中,對文字的機率分佈進行一些改變或優化,以消除或減少幻覺。這類方法的優點是可以直接影響產生的結果,可以提高LLMs的彈性和效率。這類方法的缺點是可能需要對LLMs進行一些額外的訓練或調整,或者可能需要一些外部的資訊或資源。這類方法的代表有:
Context-Aware Decoding(CAD):(Shi等,2021)提出了一種基於對比的解碼策略,用於減少LLMs生成的文本中的知識衝突。此策略使用對比模型,來計算LLMs在使用和不使用輸入的資訊時,輸出的機率分佈的差異。然後使用一個放大模型,來放大這個差異,使得與輸入的資訊一致的輸出的機率更高,而與輸入的資訊衝突的輸出的機率更低。最後使用一個生成模型,來根據放大後的機率分佈,產生文本,以提高其與輸入的資訊的一致性和可信度。
Decoding by Contrasting Layers(DoLa):(Chuang等,2021)提出了一種基於層對比的解碼策略,用於減少LLMs生成的文本中的知識幻覺。首先使用一個層選擇模型,來選擇LLMs中的某些層,作為知識層,也就是那些包含較多事實知識的層。然後使用一個層對比模型,來計算知識層和其他層在詞彙空間中的對數差異。最後使用一個生成模型,來根據層對比後的機率分佈,產生文本,以提高其與事實知識的一致性和可信度。
知識圖譜的利用(Knowledge Graph Utilization)
知識圖譜的利用是在LLMs生成文本的過程中,利用一些結構化的知識圖譜,來提供或補充一些與輸入的資訊相關的知識,以消除或減少幻覺。這類方法的優點是可以有效地獲取和整合外部的知識,可以提高LLMs的知識覆蓋和知識一致性。這類方法的缺點是可能需要對LLMs進行一些額外的訓練或調整,或者可能需要一些高品質的知識圖譜。這類方法的代表有:
RHO(Representation of linked entities and relation predicates from a Knowledge Graph):(Ji等,2021a)提出了一個基於知識圖譜的表示方法,用於提高LLMs產生的對話回應的忠實度。首先使用知識檢索模型,從知識圖譜中檢索一些與輸入的對話相關的子圖,也就是包含一些實體和關係的圖。然後使用一個知識編碼模型,來對子圖中的實體和關係進行編碼,得到它們的向量表示。接著使用一個知識融合模型,將知識的向量表示整合到對話的向量表示中,得到一個增強的對話表示。最後使用知識生成模型,來根據增強的對話表示,產生一個忠實的對話回應。
FLEEK(FactuaL Error detection and correction with Evidence Retrieved from external Knowledge):(Bayat等,2021)提出了一種基於知識圖譜的驗證和修正方法,用於提高LLMs生成的文本的事實性。該方法首先使用一個事實識別模型,來識別LLMs生成的文本中的潛在的可驗證的事實,即那些可以在知識圖譜中找到證據的事實。然後使用一個問題產生模型,來為每個事實產生一個問題,用於查詢知識圖譜。接著使用知識檢索模型,來從知識圖譜中檢索一些與問題相關的證據。最後使用一個事實驗證和修正模型,來根據證據,驗證和修正LLMs產生的文本中的事實,以提高其事實性和準確性。
基於忠實度的損失函數(Faithfulness-based Loss Function)
基於忠實度的損失函數是在LLMs訓練或微調的在過程中,使用一些衡量生成文字與輸入資訊或真實標籤之間一致性的指標,作為損失函數的一部分,以消除或減少幻覺。這類方法的優點是可以直接影響LLMs的參數最佳化,可以提高LLMs的忠實度和準確度。這類方法的缺點是可能需要對LLMs進行一些額外的訓練或調整,或者可能需要一些高品質的標註資料。這類方法的代表有:
Text Hallucination Mitigating(THAM)Framework:(Yoon等,2022)提出了一個基於資訊理論的損失函數,用於減少LLMs生成的視頻對話中的幻覺。首先使用對話語言模型,來計算對話的機率分佈。然後使用一個幻覺語言模型,來計算幻覺的機率分佈,即從輸入的影片中無法獲得的資訊的機率分佈。接著使用互資訊模型,計算對話和幻覺的互訊息,即對話中包含幻覺的程度互資訊。最後使用一個交叉熵模型,來計算對話和真實標籤的交叉熵,也就是對話的準確性。此損失函數的目標是最小化互資訊和交叉熵的和,從而減少對話中的幻覺和錯誤。
Factual Error Correction with Evidence Retrieved from external Knowledge(FECK):(Ji等,2021b)提出了一種基於知識證據的損失函數,用於提高LLMs生成的文本的事實性。首先使用知識檢索模型,從知識圖譜中檢索一些與輸入的文字相關的子圖,也就是包含一些實體和關係的圖。然後使用一個知識編碼模型,來對子圖中的實體和關係進行編碼,得到它們的向量表示。接著使用一個知識對齊模型,來對齊LLMs產生的文本中的實體和關係,與知識圖譜中的實體和關係,得到它們的匹配程度。最後,此損失函數使用一個知識損失模型,來計算LLMs產生的文本中的實體和關係,與知識圖譜中的實體和關係,之間的距離,即事實的偏差。此損失函數的目標是最小化知識損失,從而提高LLMs產生的文本的事實性和準確性。
提示微調(Prompt Tuning)
#提示微調是在LLMs產生文字的過程中,使用一些特定的文字或符號,作為輸入的一部分,來控製或引導LLMs的生成行為,以消除或減少幻覺。這類方法的優點是可以有效地調節和指導LLMs的參數知識,可以提高LLMs的適應性和靈活性。這類方法的缺點是可能需要對LLMs進行一些額外的訓練或調整,或者可能需要一些高品質的提示。這類方法的代表有:
UPRISE(Universal Prompt-based Refinement for Improving Semantic Equivalence):(Chen等,2021)提出了一種基於通用提示的微調方法,以於提高LLMs生成的文本的語意等價性。首先使用一個提示產生模型,來根據輸入的文本,產生一個通用的提示,即一些用於引導LLMs生成語義等價的文本的文本或符號。然後使用一個提示微調模型,來根據輸入的文字和提示,微調LLMs的參數,使其更傾向於產生與輸入的文字語義等價的文字。最後,該方法使用一個提示產生模型,來根據微調後的LLMs的參數,產生一個語義等價的文字。
SynTra(Synthetic Task for Hallucination Mitigation in Abstractive Summarization):(Wang等,2021)提出了一種基於合成任務的微調方法,用於減少LLMs生成的摘要中的幻覺。首先使用一個合成任務產生模型,來根據輸入的文本,產生一個合成的任務,即一個用於檢測摘要中的幻覺的問題。然後使用合成任務微調模型,來根據輸入的文字和任務,微調LLMs的參數,使其更傾向於產生與輸入的文字一致的摘要。最後使用一個合成任務產生模型,來根據微調後的LLMs的參數,產生一個一致的摘要。
5.LLMs幻覺的挑戰和局限性
#儘管LLMs中的幻覺緩解技術已經取得了一些進展,但仍然存在一些挑戰和局限性,需要進一步的研究和探索。以下是一些主要的挑戰和限制:
幻覺的定義和測量:沒有一個統一和明確的定義和度量,不同的研究可能使用不同的標準和指標,來判斷和評估LLMs生成的文本中的幻覺。這導致了一些不一致和不可比較的結果,也影響了LLMs中幻覺問題的理解和解決。因此,需要建立一個通用且可靠的幻覺的定義和度量,以便於對LLMs中的幻覺進行有效的檢測和評估。
幻覺的數據和資源:缺乏一些高品質和大規模的數據和資源,來支持LLMs中幻覺的研究和開發。例如,缺乏一些包含幻覺標註的資料集,來訓練和測試LLMs中幻覺的檢測和緩解方法;缺乏一些包含真實事實和證據的知識來源,來提供和驗證LLMs生成的文本中的知識;缺乏一些包含使用者回饋和評價的平台,來收集和分析LLMs產生的文本中的幻覺的影響。因此,需要建立一些高品質和大規模的數據和資源,以便於對LLMs中的幻覺進行有效的研究和開發。
幻覺的原因和機制:沒有一個深入且全面的原因和機制的分析,來揭示和解釋LLMs為什麼會產生幻覺,以及幻覺如何在LLMs中形成和傳播的。例如,不清楚LLMs中的參數知識、非參數知識和生成策略是如何相互影響和作用的,以及它們是如何導致不同類型、程度和影響的幻覺的。因此,需要進行一些深入和全面的原因和機制的分析,以便於對LLMs中的幻覺進行有效的預防和控制。
幻覺的解決和優化:沒有一個完善和通用的解決和優化的方案,來消除或減少LLMs生成的文本中的幻覺,以及提高LLMs生成的文本的質量和效果。例如,不清楚如何在不失去LLMs的泛化能力和創造力的前提下,提高LLMs的忠實度和準確度。因此,需要設計一些完善和通用的解決和最佳化的方案,以便於提高LLMs產生的文本的品質和效果。
以上是大規模機器學習中幻覺緩解技術的綜合研究的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 為什麼大型語言模型都在使用 SwiGLU 作為激活函數?
Apr 08, 2024 pm 09:31 PM
為什麼大型語言模型都在使用 SwiGLU 作為激活函數?
Apr 08, 2024 pm 09:31 PM
如果你一直在關注大型語言模型的架構,你可能會在最新的模型和研究論文中看到「SwiGLU」這個詞。 SwiGLU可以說是在大語言模型中最常使用的激活函數,我們這篇文章就來對它進行詳細的介紹。 SwiGLU其實是2020年Google提出的激活函數,它結合了SWISH和GLU兩者的特徵。 SwiGLU的中文全名為“雙向門控線性單元”,它將SWISH和GLU兩種激活函數進行了優化和結合,以提高模型的非線性表達能力。 SWISH是一種非常普遍的激活函數,它在大語言模型中得到廣泛應用,而GLU則在自然語言處理任務中表現出
 微調真的能讓LLM學到新東西嗎:引入新知識可能讓模型產生更多的幻覺
Jun 11, 2024 pm 03:57 PM
微調真的能讓LLM學到新東西嗎:引入新知識可能讓模型產生更多的幻覺
Jun 11, 2024 pm 03:57 PM
大型語言模型(LLM)是在龐大的文字資料庫上訓練的,在那裡它們獲得了大量的實際知識。這些知識嵌入到它們的參數中,然後可以在需要時使用。這些模型的知識在訓練結束時被「具體化」。在預訓練結束時,模型實際上停止學習。對模型進行對齊或進行指令調優,讓模型學習如何充分利用這些知識,以及如何更自然地回應使用者的問題。但是有時模型知識是不夠的,儘管模型可以透過RAG存取外部內容,但透過微調使用模型適應新的領域被認為是有益的。這種微調是使用人工標註者或其他llm創建的輸入進行的,模型會遇到額外的實際知識並將其整合
 PHP中的自然語言處理入門指南
Jun 11, 2023 pm 06:30 PM
PHP中的自然語言處理入門指南
Jun 11, 2023 pm 06:30 PM
隨著人工智慧技術的發展,自然語言處理(NaturalLanguageProcessing,NLP)已經成為了非常重要的技術。 NLP可以幫助我們更好地理解和分析人類語言,從而實現一些自動化的任務,例如智慧客服、情緒分析、機器翻譯等。在本文中,我們將介紹使用PHP進行自然語言處理的基本知識和工具。什麼是自然語言處理自然語言處理是一種利用人工智慧技術來處
 可視化FAISS向量空間並調整RAG參數提高結果精度
Mar 01, 2024 pm 09:16 PM
可視化FAISS向量空間並調整RAG參數提高結果精度
Mar 01, 2024 pm 09:16 PM
隨著開源大型語言模型的效能不斷提高,編寫和分析程式碼、推薦、文字摘要和問答(QA)對的效能都有了很大的提高。但當涉及QA時,LLM通常會在未訓練資料的相關的問題上有所欠缺,許多內部文件都保存在公司內部,以確保合規性、商業機密或隱私。當查詢這些文件時,會使得LLM產生幻覺,產生不相關、捏造或不一致的內容。一種處理這項挑戰的可行技術是檢索增強生成(RAG)。它涉及透過引用訓練資料來源以外的權威知識庫來增強回應的過程,以提升生成的品質和準確性。 RAG系統包括一個檢索系統,用於從語料庫中檢索相關文檔片段
 使用SPIN技術進行自我博弈微調訓練的LLM的最佳化
Jan 25, 2024 pm 12:21 PM
使用SPIN技術進行自我博弈微調訓練的LLM的最佳化
Jan 25, 2024 pm 12:21 PM
2024年是大型語言模型(LLM)快速發展的一年。在LLM的訓練中,對齊方法是一個重要的技術手段,其中包括監督微調(SFT)和依賴人類偏好的人類回饋強化學習(RLHF)。這些方法在LLM的發展中起到了至關重要的作用,但是對齊方法需要大量的人工註釋資料。面對這項挑戰,微調成為一個充滿活力的研究領域,研究人員積極致力於開發能夠有效利用人類資料的方法。因此,對齊方法的發展將推動LLM技術的進一步突破。加州大學最近進行了一項研究,介紹了一種名為SPIN(SelfPlayfInetuNing)的新技術。 S
 大模型中常用的注意力機制GQA詳解以及Pytorch程式碼實現
Apr 03, 2024 pm 05:40 PM
大模型中常用的注意力機制GQA詳解以及Pytorch程式碼實現
Apr 03, 2024 pm 05:40 PM
群組查詢注意力(GroupedQueryAttention)是大型語言模型中的多查詢注意力方法,它的目標是在保持MQA速度的同時實現MHA的品質。 GroupedQueryAttention將查詢分組,每個群組內的查詢共享相同的注意力權重,這有助於降低計算複雜度和提高推理速度。在這篇文章中,我們將解釋GQA的想法以及如何將其轉化為程式碼。 GQA是在論文GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
 利用知識圖譜增強RAG模型的能力和減輕大模型虛假印象
Jan 14, 2024 pm 06:30 PM
利用知識圖譜增強RAG模型的能力和減輕大模型虛假印象
Jan 14, 2024 pm 06:30 PM
在使用大型語言模型(LLM)時,幻覺是一個常見問題。儘管LLM可以產生流暢連貫的文本,但其產生的資訊往往不準確或不一致。為了防止LLM產生幻覺,可以利用外部的知識來源,例如資料庫或知識圖譜,來提供事實資訊。這樣一來,LLM可以依賴這些可靠的資料來源,從而產生更準確和可靠的文字內容。向量資料庫和知識圖譜向量資料庫向量資料庫是一組表示實體或概念的高維度向量。它們可以用於度量不同實體或概念之間的相似性或相關性,透過它們的向量表示進行計算。一個向量資料庫可以根據向量距離告訴你,「巴黎」和「法國」比「巴黎」和
 RoSA: 一種高效能微調大模型參數的新方法
Jan 18, 2024 pm 05:27 PM
RoSA: 一種高效能微調大模型參數的新方法
Jan 18, 2024 pm 05:27 PM
隨著語言模型擴展到前所未有的規模,對下游任務進行全面微調變得十分昂貴。為了解決這個問題,研究人員開始注意並採用PEFT方法。 PEFT方法的主要想法是將微調的範圍限制在一小部分參數上,以降低計算成本,同時仍能實現自然語言理解任務的最先進性能。透過這種方式,研究人員能夠在保持高效能的同時,節省運算資源,為自然語言處理領域帶來新的研究熱點。 RoSA是一種新的PEFT技術,透過在一組基準測試的實驗中,發現在使用相同參數預算的情況下,RoSA表現出優於先前的低秩自適應(LoRA)和純稀疏微調方法。本文將深
