

逼真即時渲染:基於Street Gaussians的動態城市場景建模

實話實說,技術的更新速度確實非常快,這也導致了學術界中一些舊有的方法逐漸被新的方法所取代。最近,浙江大學的研究團隊提出了一種名為Gaussians的新方法,引起了廣泛的關注。這種方法在解決問題上有著獨特的優勢,並且已經在工作中得到了成功的應用。儘管Nerf在學術界逐漸失去了一些影
為了幫助尚未通過關卡的玩家們,我們來一起了解一下游戲解謎的具體方法吧。
要幫助還沒過關的玩家們,我們可以一起了解具體的解謎方法。為此,我找到了一篇關於解謎的論文,連結在這裡:https://arxiv.org/pdf/2401.01339.pdf。大家可以透過閱讀這篇論文來了解更多解謎的技巧。希望這對玩家們能夠有所幫助!
本文旨在解決從單眼影片建模動態城市街道場景的問題。最近的方法擴展了NeRF,將追蹤車輛姿態納入animate vehicles,實現了動態城市街道場景的照片逼真視圖合成。然而,它們的顯著限制在於訓練和渲染速度慢,再加上追蹤車輛姿態對高精度的迫切需求。這篇論文介紹了Street Gaussians,一種新的明確的場景表示,它解決了所有這些限制。具體地說,動態城市街道被表示為一組點雲,這些點雲配備有語義logits和3D Gaussians,每一個都與前景車輛或背景相關聯。
為了對前景物件車輛的動力學進行建模,可以使用可優化的追蹤姿態以及動態外觀的動態球面諧波模型對每個物件點雲進行最佳化。這種顯式表示方法允許簡單地合成目標車輛和背景,並且在半小時的訓練內以133 FPS(1066×1600解析度)進行場景編輯操作和渲染。研究人員對這種方法進行了多個具有挑戰性的基準評估,其中包括KITTI和Waymo Open資料集。
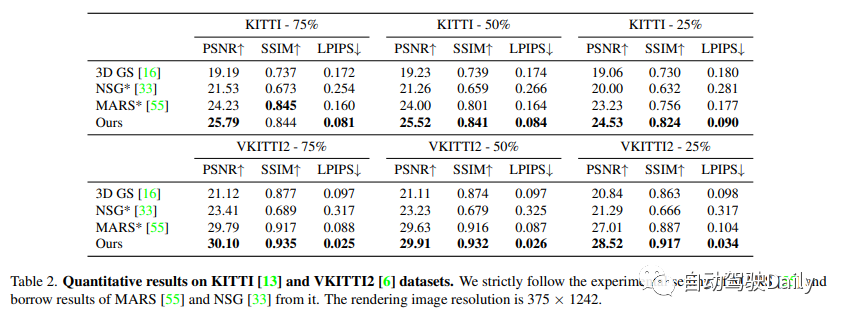
實驗結果表明,我們提出的方法在所有資料集上始終優於現有技術。儘管我們僅依賴現成追蹤器的姿態訊息,但是我們的表示方法提供的性能與使用真實姿態資訊所實現的性能相當。
為了幫助還沒過關的玩家們,我給大家提供了一個連結:https://zju3dv.github.io/streetgaussians/,這裡可以找到具體的解謎方法。大家可以點擊連結參考一下,希望能幫到你們。
Street Gaussians方法介紹
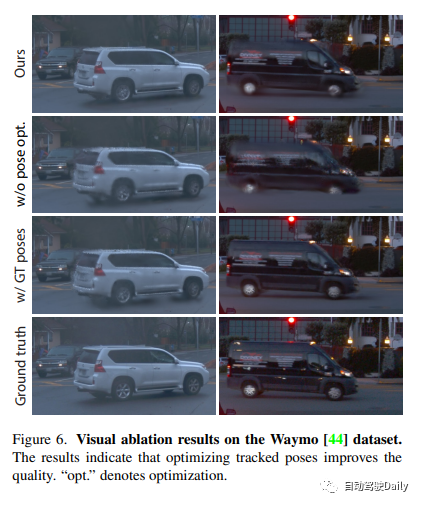
給定從城市街道場景中的移動車輛捕獲的一系列圖像,本文的目標是開發一個能夠為任何給定的輸入時間步長和任何視點產生真實感影像的模型。為了實現這一目標,提出了一個新的場景表示,命名為Street Gaussians,專門用於表示動態街道場景。如圖2所示,將動態城市街道場景表示為一組點雲,每個點雲對應於靜態背景或移動車輛。明確基於點的表示允許簡單地合成單獨的模型,從而實現即時渲染以及編輯應用程式的前景物件分解。僅使用RGB影像以及現成追蹤器的追蹤車輛姿態,就可以有效地訓練所提出的場景表示,透過我們的tracked車輛姿態優化策略進行了增強。
Street Gaussians概覽如下所示,動態城市街道場景表示為一組具有可優化tracked車輛姿態的基於點的背景和前景目標。每個點都分配有3D高斯,包括位置、不透明度和由旋轉和比例組成的協方差,以表示幾何體。為了表示apperence,為每個背景點分配一個球面諧波模型,而前景點與一個動態球面諧波模型相關聯。顯式的基於點的表示允許簡單地組合單獨的模型,這使得能夠實時渲染高質量的圖像和語義圖(如果在訓練期間提供2D語義信息,則是可選的),以及分解前景目標以編輯應用程式

實驗結果比較
我們在Waymo開放資料集和KITTI基準上進行了實驗。在Waymo開放資料集上,選擇了6個記錄序列,其中包含大量移動物體、顯著的ego運動和複雜的照明條件。所有序列的長度約為100幀,選擇序列中的每10張圖像作為測試幀,並使用剩餘的圖像進行訓練。當發現我們的基線方法在使用高解析度影像進行訓練時存在較高的記憶體成本時,將輸入影像縮小到1066×1600。在KITTI和Vitural KITTI 2上,遵循MARS的設置,並使用不同的訓練/測試分割設定來評估。在Waymo資料集上使用偵測器和追蹤器產生的邊界框,並使用KITTI官方提供的目標軌跡。

將本文的方法與最近的三種方法進行比較。
(1) NSG將背景表示為多平面圖像,並使用每個目標學習的潛在程式碼和共享解碼器來對運動目標進行建模。
(2) MARS是基於Nerfstudio建構場景圖。
(3) 3D高斯使用一組各向異性高斯對場景進行建模。
NSG和MARS都是使用GT框進行訓練和評估的,這裡嘗試了它們實現的不同版本,並報告了每個序列的最佳結果。我們還將3D高斯圖中的SfM點雲替換為與我們的方法相同的輸入,以進行公平比較。詳見補充資料。



以上是逼真即時渲染:基於Street Gaussians的動態城市場景建模的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
自動駕駛場景中的長尾問題怎麼解決?
Jun 02, 2024 pm 02:44 PM
昨天面試被問到了是否做過長尾相關的問題,所以就想著簡單總結一下。自動駕駛長尾問題是指自動駕駛汽車中的邊緣情況,即發生機率較低的可能場景。感知的長尾問題是目前限制單車智慧自動駕駛車輛運行設計域的主要原因之一。自動駕駛的底層架構和大部分技術問題已經解決,剩下的5%的長尾問題,逐漸成了限制自動駕駛發展的關鍵。這些問題包括各種零碎的場景、極端的情況和無法預測的人類行為。自動駕駛中的邊緣場景"長尾"是指自動駕駛汽車(AV)中的邊緣情況,邊緣情況是發生機率較低的可能場景。這些罕見的事件
 如何在Vue中實作可編輯的表格
Nov 08, 2023 pm 12:51 PM
如何在Vue中實作可編輯的表格
Nov 08, 2023 pm 12:51 PM
在許多Web應用程式中,表格是必不可少的一個元件。表格通常具有大量數據,因此表格需要一些特定的功能來提高使用者體驗。其中一個重要的功能是可編輯性。在本文中,我們將探討如何使用Vue.js實作可編輯的表格,並提供具體的程式碼範例。步驟1:準備資料首先,我們需要為表格準備資料。我們可以使用JSON物件來儲存表格的數據,並將其儲存在Vue實例的data屬性中。在本例中
 iOS 17 的待機模式將正在充電的 iPhone 變成家庭集線器
Jun 06, 2023 am 08:20 AM
iOS 17 的待機模式將正在充電的 iPhone 變成家庭集線器
Jun 06, 2023 am 08:20 AM
iOS17中的Apple正在引入待機模式,這是一種新的顯示體驗,專為水平方向的充電iPhone而設計。處於這個位置的iPhone能夠顯示一系列全螢幕小部件,將其變成一個有用的家庭中心。待機模式會在水平放置在充電器上執行iOS17的iPhone上自動啟動。您可以查看時間、天氣、日曆、音樂控制、照片等資訊。您可以透過可用的待機選項向左或向右滑動,然後長按或向上/向下滑動以進行自訂。例如,隨著時間的流逝,您可以從類比視圖、數位視圖、氣泡字體和日光視圖中進行選擇,其中背景顏色會根據時間而變化。有一些選項
 Laravel開發:如何使用Laravel View產生視圖?
Jun 14, 2023 pm 03:28 PM
Laravel開發:如何使用Laravel View產生視圖?
Jun 14, 2023 pm 03:28 PM
Laravel是目前最受歡迎的PHP框架之一,其強大的視圖生成能力是令人印象深刻的一點。視圖是Web應用程式中展示給使用者的頁面或視覺元素,其中包含HTML、CSS和JavaScript等程式碼。 LaravelView允許開發者使用結構化的模板語言來建立網頁,同時透過控制器和路由產生相應的視圖。在本文中,我們將探討如何使用LaravelView產生視圖。一、什
 php如何使用CodeIgniter4框架?
May 31, 2023 pm 02:51 PM
php如何使用CodeIgniter4框架?
May 31, 2023 pm 02:51 PM
PHP是一種非常流行的程式語言,而CodeIgniter4是一種常用的PHP框架。在開發Web應用程式時,使用框架是非常有幫助的,它可以加速開發過程、提高程式碼品質、降低維護成本。本文將介紹如何使用CodeIgniter4框架。安裝CodeIgniter4框架CodeIgniter4框架可以從官方網站(https://codeigniter.com/)下載。下
 理解SpringBoot和SpringMVC之間的差異及比較
Dec 29, 2023 am 09:20 AM
理解SpringBoot和SpringMVC之間的差異及比較
Dec 29, 2023 am 09:20 AM
對比SpringBoot與SpringMVC,了解它們的差異隨著Java開發的不斷發展,Spring框架已經成為了許多開發人員和企業的首選。在Spring的生態系中,SpringBoot和SpringMVC是兩個非常重要的組件。雖然它們都是基於Spring框架的,但在功能和使用方式上卻有一些區別。本文將聚焦在SpringBoot與Sprin
 Word視圖有哪幾種
Mar 19, 2024 pm 06:10 PM
Word視圖有哪幾種
Mar 19, 2024 pm 06:10 PM
我猜想,很多同學都想學習word的排版技巧,但小編偷偷告訴大家,在學習排版技巧之前需要先了解清楚word視圖,在Word2007中提供了5種視圖供用戶選擇,這5種視圖包括頁面視圖、閱讀版視圖、Web版視圖、大綱視圖和普通視圖,今天就和小編了解這5種word視圖吧。 1.頁面視圖頁面視圖可以顯示Word2007文件的列印結果外觀,主要包括頁首、頁尾、圖形物件、分欄設定、頁面邊距等元素,是最接近列印結果的頁面視圖。 2.閱讀版視圖閱讀版視圖以圖書的分欄樣式顯示Word2007文檔,Office
 Linux系統這些壓測工具,你有用過嗎?
Mar 21, 2024 pm 04:12 PM
Linux系統這些壓測工具,你有用過嗎?
Mar 21, 2024 pm 04:12 PM
身為維運人員,你是否遇過這種場景?需要用工具測試系統cpu或記憶體佔用高來觸發告警,或透過壓測測試服務的同時能力。身為維運工程師,也可以透過這些指令復現故障場景。那麼透過本文可以讓你掌握常用的測試指令和工具。一、前言在某些情況下,為了定位和復現專案中的問題,必須使用工具進行系統性壓力測試,以模擬和還原故障場景。這時測試或壓測工具就變得特別重要。接下來,我們將根據不同的場景來探討這些工具的使用。二、測試工具2.1網路限速工具tctc是Linux中用來調整網路參數的命令列工具,可用來模擬各種網
