

LLM學會左右互搏,基礎模型或將迎來群體革新

金庸武俠小說中有一門武術絕技:左右互搏;乃是周伯通在桃花島的地洞裡苦練十餘年所創武功,初期想法在於左手與右手打架,以自娛自樂。而這種想法不僅能用來練武功,也能用來訓練機器學習模型,例如前幾年風靡一時的生成對抗網路(GAN)。
進入現今的大模型(LLM)時代,研究者發現了左右互搏的精妙用法。最近,加州大學洛杉磯分校的顧全團隊提出了一種名為SPIN(Self-Play Fine-Tuning)的新方法。這種方法能夠在不使用額外的微調資料的情況下,僅透過自我博弈來大幅提升LLM的能力。顧全全教授表示:「授之以魚不如授之以漁:透過自我博弈微調(SPIN)可以讓所有大模型從弱到強得到提升!」
這項研究也在社交網路引起了不少討論,例如賓州大學華頓商學院的Ethan Mollick 教授就表示:「更多證據表明,AI 不會受限於可供其訓練的人類創造內容的數量。這篇論文再次表明使用AI 創造的資料訓練AI 可以比僅使用人類創造的資料獲得更高品質的結果。」
此外,還有許多研究人員對此方法感到興奮,並對2024 年在相關方向的進展表現出極大期待。顧全全教授向機器之心表示:「如果你希望訓練一個超越GPT-4 的大模型,這是絕對值得嘗試的技術。」

##論文網址為https://arxiv.org/pdf/2401.01335.pdf。
大型語言模型(LLM)開啟了通用人工智慧(AGI)的大突破時代,它能以非凡的能力解決需要複雜推理和專業知識的廣泛任務。 LLM 擅長的領域包括數學推理 / 問題求解、程式碼生成 / 程式設計、文字生成、摘要和創意寫作等等。
LLM 的一大關鍵進步是訓練後的對齊過程,這能讓模型的行為更符合需求,但這個過程卻往往依賴於成本高昂的人類標註資料。經典的對齊方法包括基於人類演示的監督式微調(SFT)和基於人類偏好回饋的強化學習(RLHF)。
而這些對齊方法全都需要大量人類標註資料。因此,為了精簡對齊過程,研究人員希望開發出能有效利用人類數據的微調方法。
這也是這項研究的目標:發展出新的微調方法,使得微調後的模型可以繼續變強,而且這個微調過程無需使用微調資料集以外的人類標註數據。
實際上,機器學習社群一直都很關注如何在不使用額外訓練資料的情況下將弱模型提升成強模型,這方面的研究甚至可以追溯至boosting 演算法。也有研究表明,自訓練演算法可以在混合模型中將弱學習器轉換成強學習器,而無需額外的標註資料。但是,要在沒有外部引導的前提下自動提升 LLM 的能力既複雜又少有研究。這就引出了以下問題:
我們能讓 LLM 在沒有額外人類標註資料的前提下實現自我提升嗎?
方法
#從技術細節上講,我們可以將來自先前迭代的LLM 記為pθt,其對於人類標註的SFT 資料集中的prompt x,可以產生響應y'。接下來的目標是找到一個新的 LLM pθ{t 1},使其有能力區分 pθt 產生的響應 y' 和人類給出的響應 y。
這個過程可被視為一個兩個玩家的遊戲過程:主玩家就是新LLM pθ{t 1},其目標是區分對手玩家pθt 的反應以及人類生成的反應;對手玩家就是舊LLM pθt,其任務是產生與人類標註的SFT 資料集盡可能相近的反應。
新 LLM pθ{t 1} 是通过微调旧 LLM pθt 得到的,训练过程是让新的 LLM pθ{t 1} 有很好的能力区分 pθt 生成的响应 y' 和人类给出的响应 y。而这个训练不仅让新的 LLM pθ{t 1} 作为一个主玩家达到很好的区分能力,而且让新的 LLM pθ{t 1} 作为一个对手玩家在下一轮迭代中,给出更对齐 SFT 数据集的响应。在下一轮迭代中,新获得的 LLM pθ{t 1} 会变成响应生成的对手玩家。
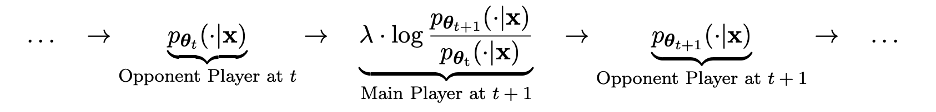

这个自我博弈的过程的目标是让 LLM 最终收敛到 pθ∗=p_data,使得可能存在的最强大的 LLM 生成的响应不再与其之前版本和人类生成的响应不同。
有趣的是,这个新方法与 Rafailov et al. 近期提出的直接偏好优化(DPO)方法表现出了相似性,但新方法的明显区别是采用了自我博弈机制。也因此,这个新方法就有了一大显著优势:无需额外的人类偏好数据。
此外,我们也能明显看出这种新方法与生成对抗网络(GAN)的相似性,只不过新方法中的判别器(主玩家)和生成器(对手)是同一个 LLM 在相邻两次迭代后的实例。
该团队还对这个新方法进行了理论证明,结果表明:当且仅当 LLM 的分布等于目标数据分布时,即 p_θ_t=p_data 时,该方法可以收敛。
实验
在实验中,该团队使用了一个基于 Mistral-7B 微调后的 LLM 实例 zephyr-7b-sft-full。
结果表明,新方法能在连续迭代中持续提升 zephyr-7b-sft-full,而作为对比,当在 SFT 数据集 Ultrachat200k 上使用 SFT 方法持续训练时,评估分数则会达到性能瓶颈,甚至出现下降情况。
更有趣的是,新方法使用的数据集只是 Ultrachat200k 数据集的一个 50k 大小的子集!
新方法 SPIN 还有另一项成就:可有效地将 HuggingFace Open LLM 排行榜中基础模型 zephyr-7b-sft-full 的平均分数从 58.14 提升至 63.16,其中在 GSM8k 和 TruthfulQA 上能有超过 10% 的惊人提升,在 MT-Bench 上也可从 5.94 提升至 6.78。
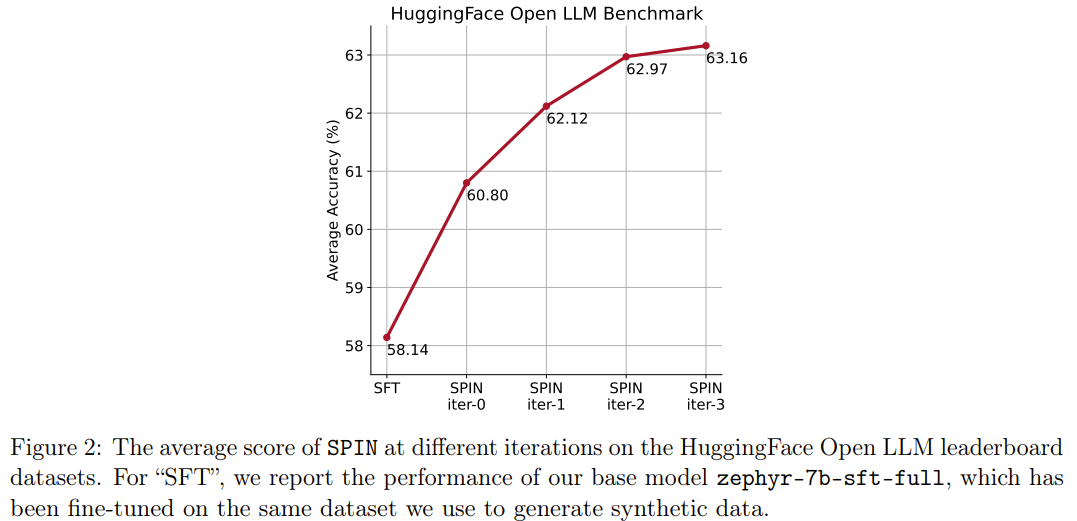
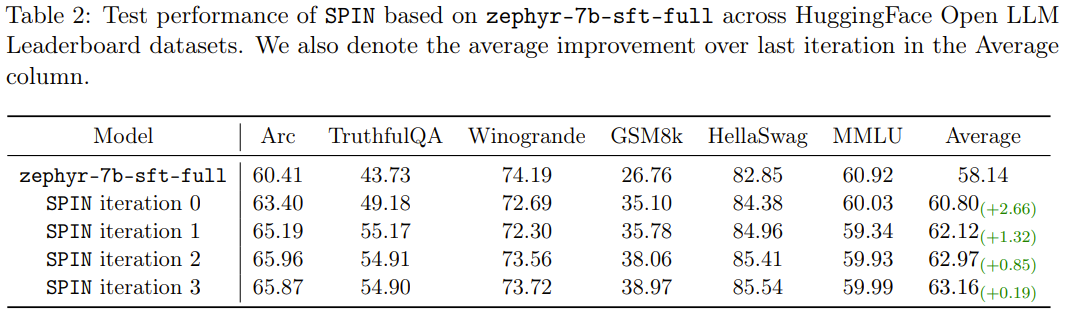
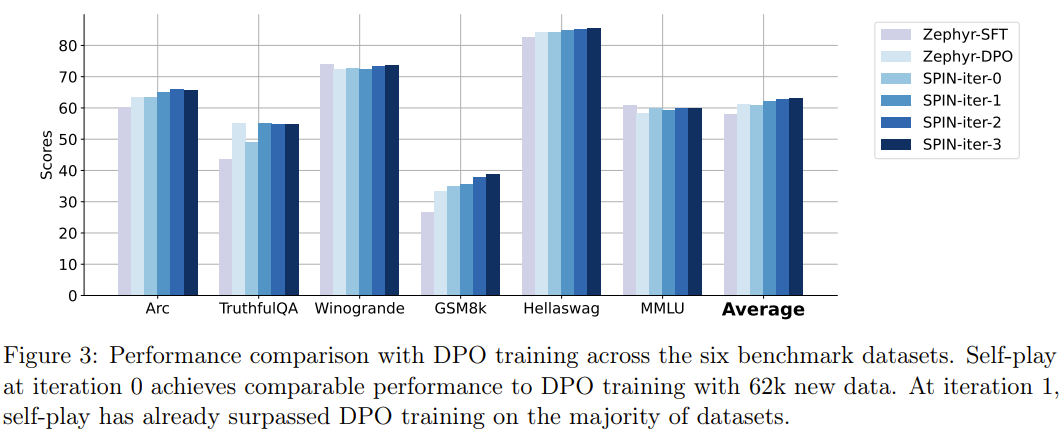
值得注意的是,在 Open LLM 排行榜上,使用 SPIN 微调的模型甚至能与再使用额外 62k 偏好数据集训练的模型媲美。
结论
通过充分利用人类标注数据,SPIN 让大模型靠自我博弈从弱变强。与基于人类偏好反馈的强化学习(RLHF)相比,SPIN 使 LLM 能够在没有额外人类反馈或者更强的 LLM 反馈的情况下自我改进。在包含 HuggingFace Open LLM 排行榜的多个基准数据集实验上,SPIN 显著且稳定地提高了 LLM 的性能,甚至超过了使用额外 AI 反馈训练的模型。
我们期待 SPIN 可以助力大模型的进化和提升,并最终实现超越人类水平的人工智能。
以上是LLM學會左右互搏,基礎模型或將迎來群體革新的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
幣圈行情實時數據免費平台推薦前十名發布
Apr 22, 2025 am 08:12 AM
適合新手的加密貨幣數據平台有CoinMarketCap和非小號。 1. CoinMarketCap提供全球加密貨幣實時價格、市值、交易量排名,適合新手與基礎分析需求。 2. 非小號提供中文友好界面,適合中文用戶快速篩選低風險潛力項目。
 okx在線 okx交易所官網在線
Apr 22, 2025 am 06:45 AM
okx在線 okx交易所官網在線
Apr 22, 2025 am 06:45 AM
OKX 交易所的詳細介紹如下:1) 發展歷程:2017 年創辦,2022 年更名為 OKX;2) 總部位於塞舌爾;3) 業務範圍涵蓋多種交易產品,支持 350 多種加密貨幣;4) 用戶遍布 200 餘個國家,千萬級用戶量;5) 採用多重安全措施保障用戶資產;6) 交易費用基於做市商模式,費率隨交易量增加而降低;7) 曾獲多項榮譽,如“年度加密貨幣交易所”等。
 各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
各大虛擬貨幣交易平台的特色服務一覽
Apr 22, 2025 am 08:09 AM
機構投資者應選擇Coinbase Pro和Genesis Trading等合規平台,關注冷存儲比例與審計透明度;散戶投資者應選擇幣安和火幣等大平台,注重用戶體驗與安全;合規敏感地區的用戶可通過Circle Trade和Huobi Global進行法幣交易,中國大陸用戶需通過合規場外渠道。
 大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
大宗交易的虛擬貨幣交易平台排行榜top10最新發布
Apr 22, 2025 am 08:18 AM
選擇大宗交易平台時應考慮以下因素:1. 流動性:優先選擇日均交易量超50億美元的平台。 2. 合規性:查看平台是否持有美國FinCEN、歐盟MiCA等牌照。 3. 安全性:冷錢包存儲比例和保險機制是關鍵指標。 4. 服務能力:是否提供專屬客戶經理和定制化交易工具。
 支持多種幣種的虛擬貨幣交易平台推薦前十名一覽
Apr 22, 2025 am 08:15 AM
支持多種幣種的虛擬貨幣交易平台推薦前十名一覽
Apr 22, 2025 am 08:15 AM
優先選擇合規平台如OKX和Coinbase,啟用多重驗證,資產自託管可減少依賴:1. 選擇有監管牌照的交易所;2. 開啟2FA和提幣白名單;3. 使用硬件錢包或支持自託管的平台。
 數字貨幣交易app容易上手的推薦top10(025年最新排名)
Apr 22, 2025 am 07:45 AM
數字貨幣交易app容易上手的推薦top10(025年最新排名)
Apr 22, 2025 am 07:45 AM
gate.io(全球版)核心優勢是界面極簡,支持中文,法幣交易流程直觀;幣安(簡版)核心優勢是全球交易量第一,簡版模式僅保留現貨交易;OKX(香港版)核心優勢是界面簡潔,支持粵語/普通話,衍生品交易門檻低;火幣全球站(香港版)核心優勢是老牌交易所,推出元宇宙交易終端;KuCoin(中文社區版)核心優勢是支持800 幣種,界面採用微信式交互;Kraken(香港版)核心優勢是美國老牌交易所,持有香港SVF牌照,界面簡潔;HashKey Exchange(香港持牌)核心優勢是香港知名持牌交易所,支持法
 幣圈十大行情網站的使用技巧與推薦2025
Apr 22, 2025 am 08:03 AM
幣圈十大行情網站的使用技巧與推薦2025
Apr 22, 2025 am 08:03 AM
國內用戶適配方案包括合規渠道和本地化工具。 1. 合規渠道:通過OTC平台如Circle Trade進行法幣兌換,境內需通過香港或海外平台。 2. 本地化工具:使用幣圈網獲取中文資訊,火幣全球站提供元宇宙交易終端。
 數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
數字貨幣交易所App前十名蘋果版下載入口匯總
Apr 22, 2025 am 09:27 AM
提供各種複雜的交易工具和市場分析。覆蓋 100 多個國家,日均衍生品交易量超 300 億美元,支持 300 多個交易對與 200 倍槓桿,技術實力強大,擁有龐大的全球用戶基礎,提供專業的交易平台、安全存儲解決方案以及豐富的交易對。
