

AI驅動的事件智慧分析系統的實際建置應用

一、背景
隨著虛擬化、雲端運算等新技術廣泛應用,企業資料中心內部的IT基礎架構規模急遽成長。這導致電腦硬體和軟體規模擴大,同時也頻繁發生電腦故障。因此,第一線維運人員迫切需要更專業、更強大的維運工具來應對挑戰。
在資料中心的日常運維工作中,通常會使用基礎監控系統和應用監控系統來建構故障發現的機制。透過設定預設的閾值,當各種軟硬體發生異常時,指標項目會超過這些閾值,從而觸發警告。維運專家會立即收到通知並進行故障排障工作,以確保資料中心的穩定運作。這樣的監控機制可以及時發現並解決潛在的問題,提高資料中心的可靠性和可用性。
事件智慧分析系統即是為解決警示轉故障並分析處置而生的系統。
二、總體架構
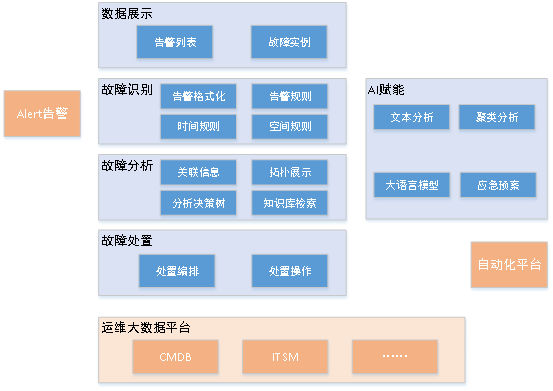
#1、事件智慧分析系統架構
#事件智慧分析系統打造「故障辨識-故障分析-故障處置」全流程的故障處理體系,將維運專家的經驗沉澱為數位化模型,當故障發生時,可以自動的對故障進行「辨識-分析-處置”,進而縮短MTTR(平均故障修復時間,Mean Time To Repair)。
事件智慧分析系統引入AI技術為系統各模組賦能,當維運專家沒有手動建立故障模型時,AI會自動的為警告建立故障,並自動進行分析,進而給予分析方案,輔助運維專家對故障進行分析。 AI賦能減輕了維運專家建模的工作量壓力,同時也彌補了維運專家的經驗盲點。
以下是事件智慧分析系統的整體架構圖:
 圖片
圖片
#其中藍色部分是事件智慧分析系統的功能模組,橘色部分是周邊系統,提供對應的資料或介面。
2、和周邊系統的關係
統一事件平台:Alert系統收集各監控系統(基礎監控、應用監控、日誌監控的)的告警,統一匯聚後,轉換為統一的格式,傳送到kafka;事件智慧分析系統會從kafka系統讀取所有警告資料。
自動化平台:維運專家事前在自動化平台新建一些編排和腳本,作為處理故障的方法,當故障分析找到根因後,可以透過呼叫自動化平台介面來實現處置任務編排和下發執行,最終實現自動處置的目的。
CMDB:在故障分析時,可使用CMDB中儲存的物件實例屬性和關係,將警告實例和處置實例進行邏輯關聯;同時在展示警告物件週邊物件的某些資訊時,也需要關聯對應的CMDB物件實例資料。
ITSM:提供變更單和事件單等工單數據,當發生故障時,需要使用這些工單資料進行分析。
維運大數據平台:大數據平台提供資料清洗工具,幫助事件智慧分析平台對所需的資料進行清洗,同時提供大量資料儲存的技術支援;大數據平台是事件智慧分析所需數據的堅實基礎,同時也為後續的AI分析提供了分析數據,包含了CMDB的物件數據、ITSM的工單數據、監控系統的指標數據和警告數據等。
三、功能詳解
#1、故障辨識
故障識別的主要功能就是建立故障模型,其能夠定義警告轉化為故障的規則,同時對故障模型的定義,也是對故障的一次簡單分類,例如會有CPU使用率高故障、記憶體使用率高故障、磁碟使用率高故障、網路延遲故障等,簡單的說就是哪幾個告警可以變成一個故障,告警和故障的數量關係既可以是1:1的,也可以是n:1的關係;只有形成了具體故障,才能方便後續的分析與處置。
警告格式化:
將從統一事件平台收到的告警,進行標準化處理,處理稱為事件智慧處置系統所需要的格式,部分欄位需要尋找配置管理的物件實例資料進行補充。
故障模型定義:
故障場景模型的定義主要包括基本資訊、故障規則和分析決策等功能,具體描述如下:
1)基本資訊包含故障名稱、所屬物件、故障類型和故障描述等資訊;
2)故障規則可分為以下幾類:
- 對警告配對的關鍵字規則設定:警告的json欄位中的摘要summary、等級level等欄位都可以作為條件設定,而且可以將多個規則進行邏輯設定運算(規則的與或非計算);
- 時間規則:包含立刻執行(收到警告立刻產生故障實例)、等待固定時間視窗(初始警告開始後一段時間內的警告強制聚合故障實例)、等待滑動時間視窗(最後警告開始後一段時間內的警告強制聚合故障實例);
- 位置規則:包括同機器、同部署單元、同物理子系統,在指定範圍內的滿足條件的告警都聚合成一個故障實例。
3)關聯指定的分析決策樹,決定分析方案。
2、故障分析
#故障分析是從關聯資料展示、拓樸資料展示、分析決策樹和知識庫檢索等多個面向對故障進行分析展示,為維運專家提供資料支撐,協助其快速尋找故障根因並處置故障。其中分析決策樹可以關聯處置。
關聯資訊展示:
1)警告分析:警告對象所對應物理子系統和部署單元所關聯的其他軟硬體對象在最近48小時內的警告資料;
2)指標分析:警告物件對應物理子系統和部署單元所關聯的其他軟硬體物件在故障前2小時內的指標資料;
3)變更分析:警告物件所對應系統在最近48小時內的變更工單記錄,進行變更分析;
4)日誌分析:對警告物件及週邊物件的指定路徑的應用日誌和系統日誌進行分析,並進行展示;
5)連結分析:以交易碼為核心,將警告物件所涉及的交易碼上下游連結資料進行分析,並進行展示;
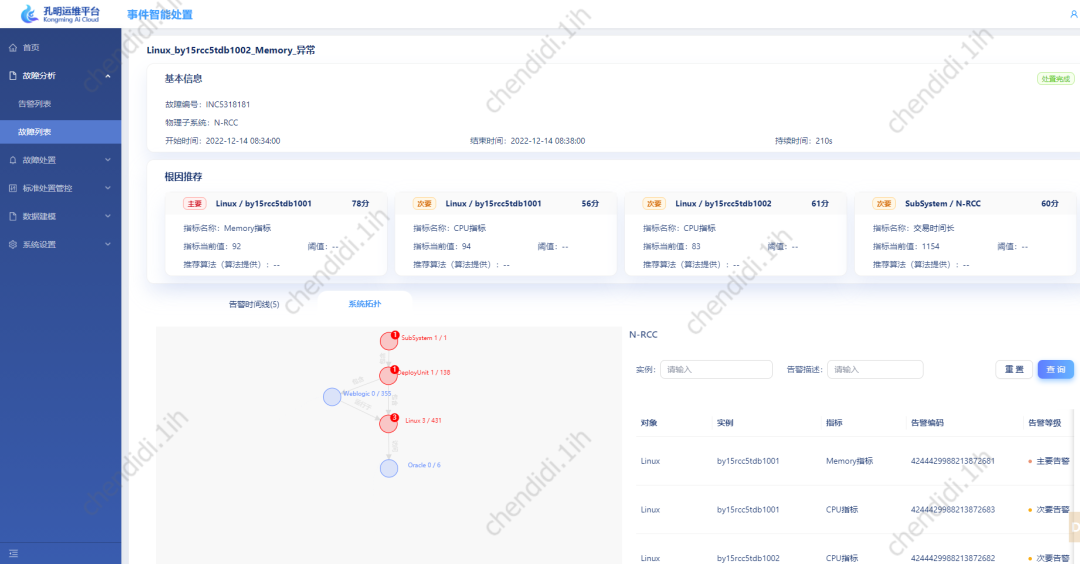
拓樸結構展示:
以物理子系統為維度,將全系統所涉及的運維物件以樹狀的拓樸結構進行展示,同時對其中有警告的節點進行標紅處理,以提示運維專家。
具體的範例如下:
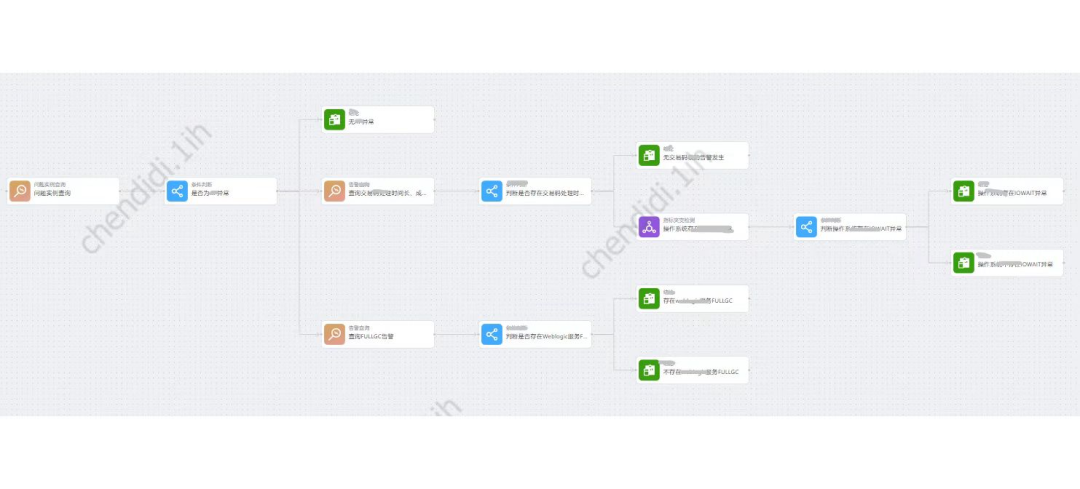
#分析決策樹:
以CMDB物件及關聯、警告、指標、變更、日誌和連結等資料為基礎,整合到可自訂編輯的分析決策樹中。
維運專家可以預設分析資料的順序和判斷標準,將維運經驗以數位化模型的方式,沉澱到分析決策樹中,當發生故障時,平台會根據預先設定的分析決策樹對相關數據進行分析和判斷,最終給出結果。
分析決策樹最終的葉子節點可以關聯處置,確保故障的「識別-分析-處置」全生命週期的自動化運作。
具體的樣例如下:
 圖片
圖片
##資料中心以維運大資料平台上的資料為基礎,建構知識庫系統,主要收集緊急應變計畫、事件單處理全流程記錄、維運專家經驗總結等文字資料。
當發生故障時,會用故障的關鍵字去知識庫進行檢索(字串比對),回傳對應的文字知識,作為專家經驗回傳。在AI賦能的章節會講述使用文本分析的方式進行關聯搜索,而不僅僅只是簡單的字串匹配。
3、故障處置
#故障處置主要按事前定義好的處置模型進行處置,主要包括處置決策編排處置操作,需依託於自動化平台實現處置任務的編排與執行。
1)處置編排:處置編排是一些列處置操作的有機結合,因為有些處置需要對運維對象進行先隔離再重啟;將處置操作的腳本進行流程編輯,使得若干個操作腳本按照既定的順序下發到具體實例機器並執行;
#2)處置操作:對腳本(shell、python)進行封裝,使其可以在實例機器上執行,也可以被處置編排呼叫;處置操作是處置的最小動作,例如tomcat的重啟、隔離、熔斷等腳本;
##故障處置大都依據運維專家經驗或緊急計畫文檔,將其進行數位沉澱為模型。 故障處置結束後,會根據流程記錄處置相關記錄,以供後續回顧分析使用。 ######四、AI賦能##########AI賦能是為了在故障的「識別-分析-處置」全流程中,盡量減少人工配置工作量,減輕運維專家工作壓力,同時也可以彌補運維專家經驗無法覆蓋的部分,且可以在初始化階段就涵蓋歷史上出現過的100%告警類型;總體原則是透過AI計算,在故障識別和分析的領域,透過自動建模、自動聚合、自動分析等方式,建構出故障模型和分析方案,給維運專家提供參考,但是確保最後的處置由維運專家做最後的判斷和控制,保證演算法做99%的工作,人工審核確保最後1%的工作。
1、自動建模
#回顧三-1章節關於故障模型的定義,我們發現只要確定警告規則、時間規則和空間規則,同時確定分析決策樹就可以建立一個故障模型,而時間規則和空間規則可以預設為最常見的立刻執行和同機器,分析決策樹可以使用最常規健康檢查。
因此建立故障模型,為同一類的故障建立模型,最核心的問題就是透過警告內容對故障進行分類,而我們使用警告內容的關鍵字來進行確定分類,進而建立某類型的故障模型。那麼自動建模的問題,就退化為尋找警告的關鍵字並以此建立故障模型。
整體邏輯圖如下:
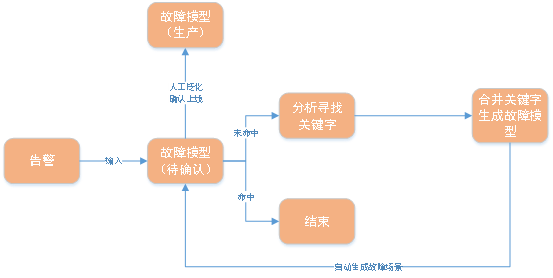
圖片
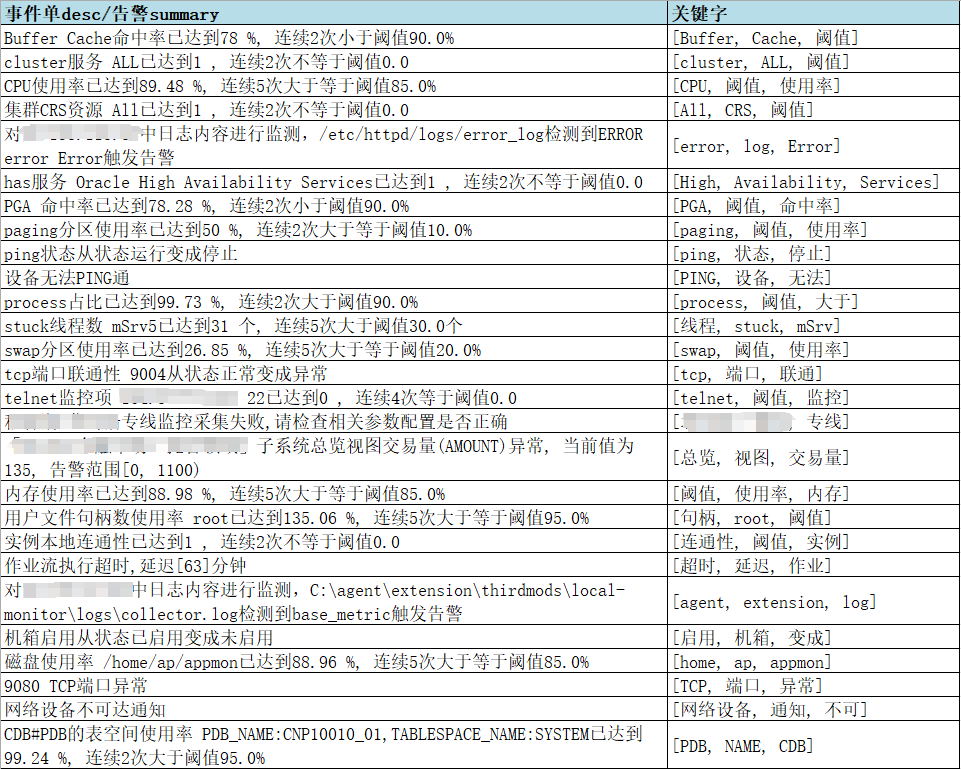
#使用以上演算法,使用部分警告內容計算後,得到的資料效果如下: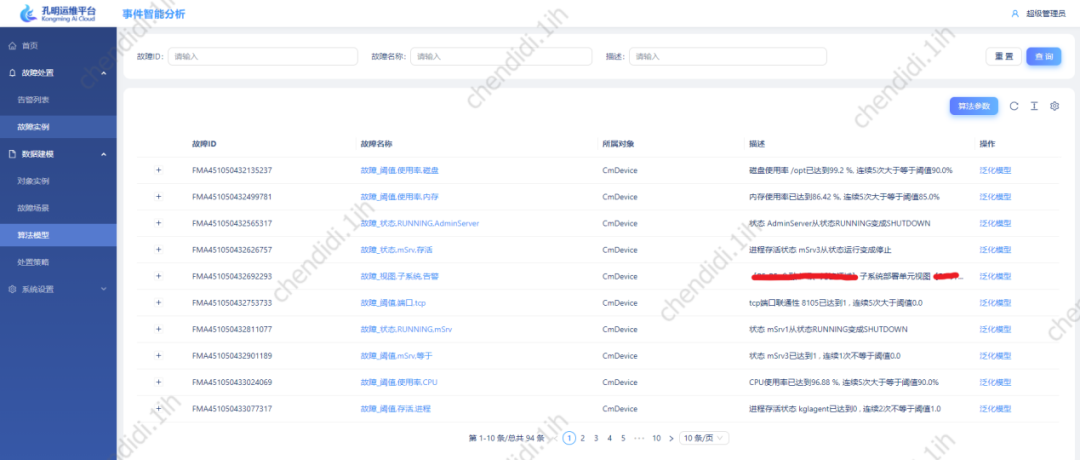
圖片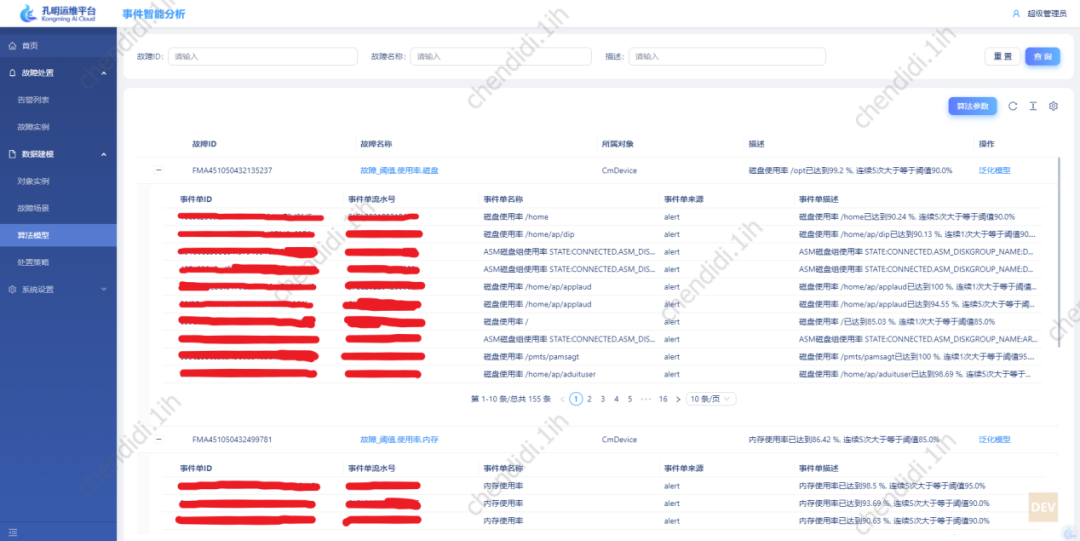
圖片
2、自動聚類故障 自Google發布BERT(Bidirectional Encoder Representations from Transformers)之後,在各文字任務中刷榜,取得了非常好的效果,因此使用其來計算文字相似性,主要是計算警告內容和故障描述之間的相似性。 現在建立我們的聚類演算法,具體流程示意圖如下: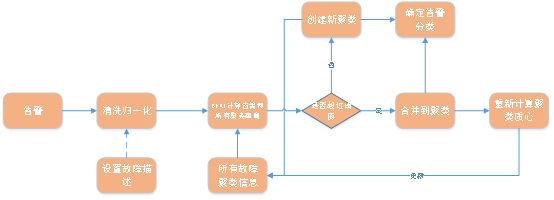
圖片
#具體步驟如下: 1)如果有需要可以人工設定故障描述,作為故障聚類的錨定方向;本步驟並非必須的,如果沒有,則直接跳過;2)將警告訊息進行清洗,去除一些無用的字元;3)使用BERT模型,對警告摘要的文字內容和所有故障聚類的資訊進行文本相似性計算,得到是否相似的結果(透過判斷是否超過閾值來判斷是否相似);4)如果是相似的,則將此告警歸屬於此故障聚類;5)如果距離值未超過閾值,則將此警告設為一個新的故障聚類;6)第4,5步的結果更新到故障聚類訊息清單中;7)從第2步再處理下一個警告資料。 ######本演算法可以將警告歸屬到不同類型的故障中,如果沒有現成類型的故障,則自建一個類型,針對此不同故障類型的分類,可以有不同的分析方法。 ##########本演算法的優點如下:
1)透過歷史和即時警告數據,無監督的自動做了故障分類,也無需建立故障模型,節省了人力;
2)針對即時告警,故障聚類的過程保證了可以做到即時線上更新,無需定期計算和更新模型;
3)警告自動產生或關聯故障,可以進一步關聯對應的緊急應變計畫,得到故障的分析方案和處置方法。
3、自動產生分析方案
#回顧三-2章節故障分析,對故障的分析,主要集中在故障節點及週邊節點的資訊進行展示,在分析決策樹的設定上也需要較多的人工設定。
在AI賦能後,考慮以緊急計畫、警告細節和故障分析中的展示訊息為提示詞(prompt),利用現有效果極佳的大語言模型,自動的給出故障分析方案。
考慮到私有化部署問題,大語言模型可以考慮ChatGLM2、llama2等,具體實施階段可以根據需要和硬體層級選擇不同的大語言模型,在本文的方案描述中,統一使用LLM表示大語言模型,請讀者註意區分。
主要流程示意圖如下:
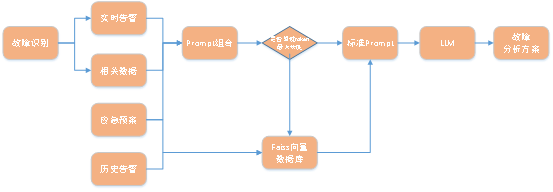
#故障識別後,獲得了對應的即時警告和展示的相關數據,結合應急預案數據,組成prompt組合,prompt提示詞是為了在LLM大語言模型提問時,獲得更好的輸出效果。
同時將緊急計畫和歷史警告數據,分批存入到faiss向量資料庫,每批的文字量不超過LLM的token限制數量;當prompt組合提示詞超過了LLM大語言模型時,會將prompt組合提示詞向faiss向量資料庫進行查詢,獲得向量最相似的文本;以這些不超過token長度限制的文本,向LLM查詢,獲得的返回即為故障分析方案(文本形式)。
具體效果參考下圖:
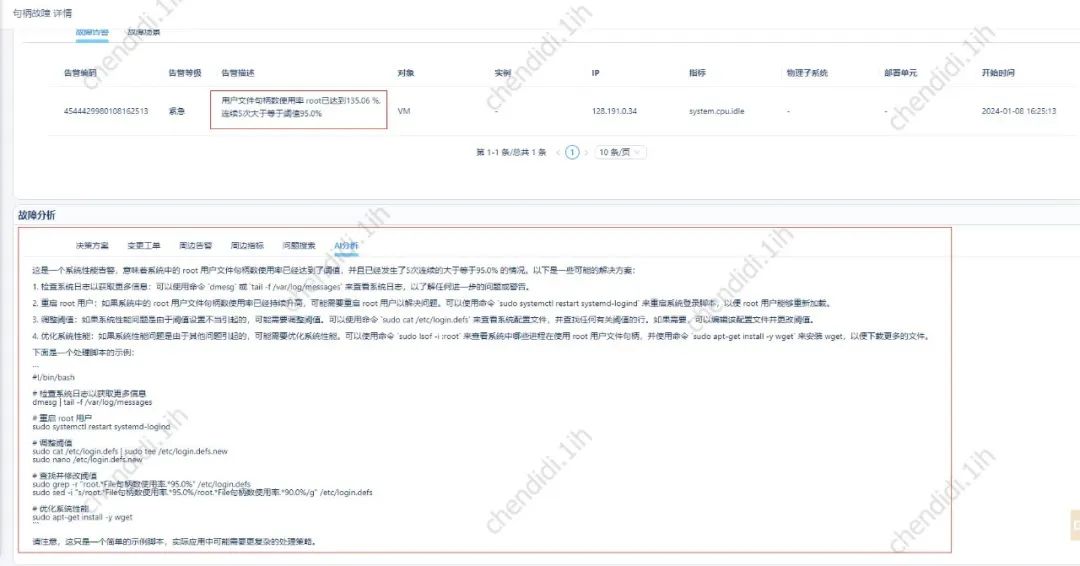
#4、緊急應變計畫檢索
緊急計畫作為業界的必備手冊,完善的記錄了所有系統和所有維運物件對應故障的分析和處置步驟,是非常好的文字資料依靠,在這個系統中會有很多地方都會使用到應急計畫的內容。因此提供緊急應變計畫的檢索能力十分必要,可以利用知識庫系統作為緊急應變計畫的檢索基數基礎。
可以提供字串匹配的文字檢索,也可以提供文字分析後的關鍵字檢索,同時也可以語意層級的向量相似性檢索,無論哪種方式都是為了取得系統所需要對應的緊急應變計畫文字。
以上若干種檢索方式都可以利用前文中提到的技術手段進行處理,在此不再贅述。
五、結語
事件智慧分析系統是為了幫助維運專家對各系統進行維運,因此提供了一系列可以建模的方法,讓維運專家可以將運維經驗沉澱為數位化的模型;當資料量(故障樣本資料和運維相關資料)越來越大時,使用一些AI演算法,可以減輕維運專家的工作量,輔助維運專家做分析決策;最終希望達到無需維運專家介入,也能夠自動運維的境界,即對故障的「自發現,免維護」。
以上是AI驅動的事件智慧分析系統的實際建置應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Laravel的地理空間:互動圖和大量數據的優化
Apr 08, 2025 pm 12:24 PM
Laravel的地理空間:互動圖和大量數據的優化
Apr 08, 2025 pm 12:24 PM
利用地理空間技術高效處理700萬條記錄並創建交互式地圖本文探討如何使用Laravel和MySQL高效處理超過700萬條記錄,並將其轉換為可交互的地圖可視化。初始挑戰項目需求:利用MySQL數據庫中700萬條記錄,提取有價值的見解。許多人首先考慮編程語言,卻忽略了數據庫本身:它能否滿足需求?是否需要數據遷移或結構調整? MySQL能否承受如此大的數據負載?初步分析:需要確定關鍵過濾器和屬性。經過分析,發現僅少數屬性與解決方案相關。我們驗證了過濾器的可行性,並設置了一些限制來優化搜索。地圖搜索基於城
 mysql 無法啟動怎麼解決
Apr 08, 2025 pm 02:21 PM
mysql 無法啟動怎麼解決
Apr 08, 2025 pm 02:21 PM
MySQL啟動失敗的原因有多種,可以通過檢查錯誤日誌進行診斷。常見原因包括端口衝突(檢查端口占用情況並修改配置)、權限問題(檢查服務運行用戶權限)、配置文件錯誤(檢查參數設置)、數據目錄損壞(恢復數據或重建表空間)、InnoDB表空間問題(檢查ibdata1文件)、插件加載失敗(檢查錯誤日誌)。解決問題時應根據錯誤日誌進行分析,找到問題的根源,並養成定期備份數據的習慣,以預防和解決問題。
 mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
mysql安裝後怎麼使用
Apr 08, 2025 am 11:48 AM
文章介紹了MySQL數據庫的上手操作。首先,需安裝MySQL客戶端,如MySQLWorkbench或命令行客戶端。 1.使用mysql-uroot-p命令連接服務器,並使用root賬戶密碼登錄;2.使用CREATEDATABASE創建數據庫,USE選擇數據庫;3.使用CREATETABLE創建表,定義字段及數據類型;4.使用INSERTINTO插入數據,SELECT查詢數據,UPDATE更新數據,DELETE刪除數據。熟練掌握這些步驟,並學習處理常見問題和優化數據庫性能,才能高效使用MySQL。
 偏遠的高級後端工程師(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
偏遠的高級後端工程師(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
遠程高級後端工程師職位空缺公司:Circle地點:遠程辦公職位類型:全職薪資:$130,000-$140,000美元職位描述參與Circle移動應用和公共API相關功能的研究和開發,涵蓋整個軟件開發生命週期。主要職責獨立完成基於RubyonRails的開發工作,並與React/Redux/Relay前端團隊協作。為Web應用構建核心功能和改進,並在整個功能設計過程中與設計師和領導層緊密合作。推動積極的開發流程,並確定迭代速度的優先級。要求6年以上複雜Web應用後端
 mysql 能返回 json 嗎
Apr 08, 2025 pm 03:09 PM
mysql 能返回 json 嗎
Apr 08, 2025 pm 03:09 PM
MySQL 可返回 JSON 數據。 JSON_EXTRACT 函數可提取字段值。對於復雜查詢,可考慮使用 WHERE 子句過濾 JSON 數據,但需注意其性能影響。 MySQL 對 JSON 的支持在不斷增強,建議關注最新版本及功能。
 了解 ACID 屬性:可靠數據庫的支柱
Apr 08, 2025 pm 06:33 PM
了解 ACID 屬性:可靠數據庫的支柱
Apr 08, 2025 pm 06:33 PM
數據庫ACID屬性詳解ACID屬性是確保數據庫事務可靠性和一致性的一組規則。它們規定了數據庫系統處理事務的方式,即使在系統崩潰、電源中斷或多用戶並發訪問的情況下,也能保證數據的完整性和準確性。 ACID屬性概述原子性(Atomicity):事務被視為一個不可分割的單元。任何部分失敗,整個事務回滾,數據庫不保留任何更改。例如,銀行轉賬,如果從一個賬戶扣款但未向另一個賬戶加款,則整個操作撤銷。 begintransaction;updateaccountssetbalance=balance-100wh
 mysql 主鍵可以為 null
Apr 08, 2025 pm 03:03 PM
mysql 主鍵可以為 null
Apr 08, 2025 pm 03:03 PM
MySQL 主鍵不可以為空,因為主鍵是唯一標識數據庫中每一行的關鍵屬性,如果主鍵可以為空,則無法唯一標識記錄,將會導致數據混亂。使用自增整型列或 UUID 作為主鍵時,應考慮效率和空間佔用等因素,選擇合適的方案。
 掌握SQL LIMIT子句:控制查詢中的行數
Apr 08, 2025 pm 07:00 PM
掌握SQL LIMIT子句:控制查詢中的行數
Apr 08, 2025 pm 07:00 PM
SQLLIMIT子句:控制查詢結果行數SQL中的LIMIT子句用於限制查詢返回的行數,這在處理大型數據集、分頁顯示和測試數據時非常有用,能有效提升查詢效率。語法基本語法:SELECTcolumn1,column2,...FROMtable_nameLIMITnumber_of_rows;number_of_rows:指定返回的行數。帶偏移量的語法:SELECTcolumn1,column2,...FROMtable_nameLIMIToffset,number_of_rows;offset:跳過
