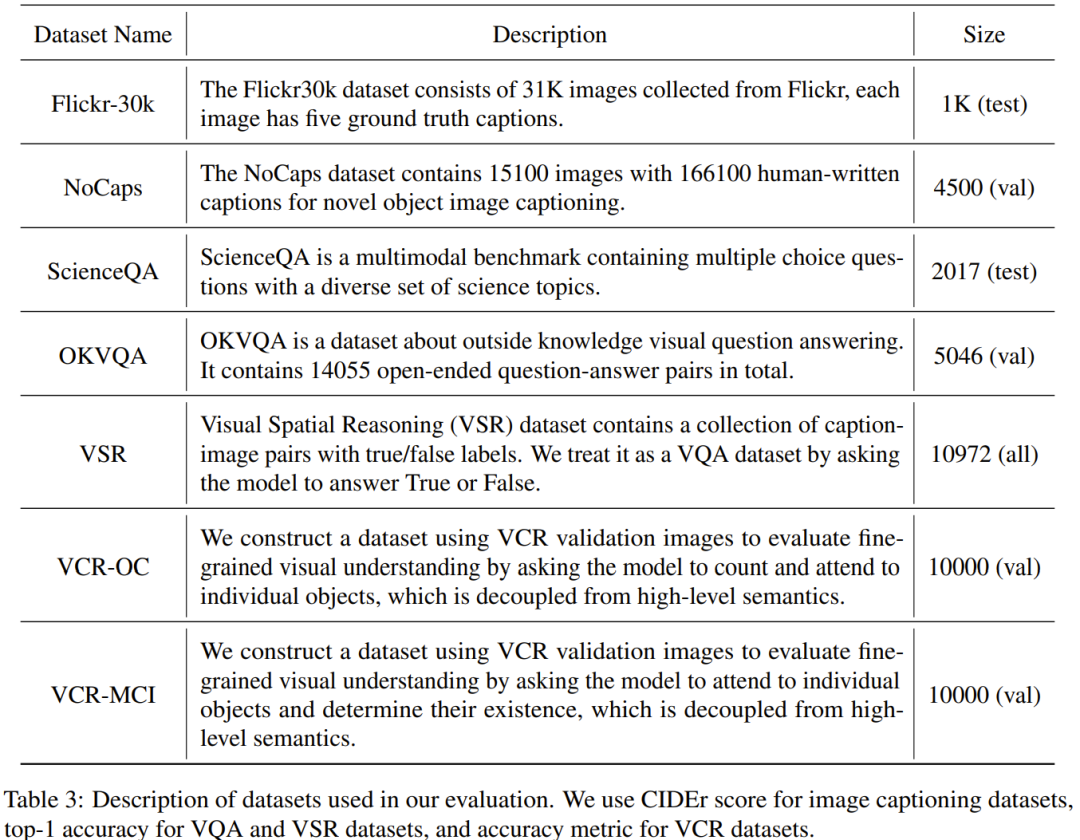
在產生細節豐富和精確的圖像描述方面,GPT-4 已經展現出了強大超凡的能力,其標誌著一個語言和視覺處理新時代的到來。 因此,類似於GPT-4 的多模態大型語言模型(MLLM)近來異軍突起,成為了一個炙手可熱的新興研究領域,其研究核心是將強大的LLM 用作執行多模態任務的認知框架。 MLLM 出乎意料的卓越表現不僅超越了傳統方法,更使其成為了實現通用人工智慧的潛在途徑之一。 為了創造好用的MLLM,需要使用大規模的配對的圖像- 文字資料以及視覺- 語言微調資料來訓練凍結的LLM(如LLaMA 和Vicuna )與視覺表徵(如CLIP 和BLIP-2)之間的連接器(如MiniGPT-4、LLaVA 和LLaMA-Adapter)。 MLLM 的訓練通常分為兩個階段:預訓練階段和微調階段。預訓練的目的是讓 MLLM 獲得大量知識,而微調則是為了教會模型更好地理解人類意圖並產生準確的回應。 為了增強 MLLM 理解視覺 - 語言和遵循指令的能力,近期出現了一種名為指令微調(instruction tuning)的強大微調技術。該技術有助於將模型與人類偏好對齊,讓模型在各種不同的指令下都能產生人類期望的結果。在發展指令微調技術方面,一個相當有建設性的方向是在微調階段引入影像標註、視覺問答(VQA)和視覺推理資料集。 InstructBLIP 和 Otter 等先前的技術的做法是使用一系列視覺 - 語言資料集來進行視覺指令微調,也得到了頗具潛力的結果。 但是,人們已經觀察到:常用的多模態指令微調資料集包含大量低品質實例,即其中的回應是不正確或不相關的。這樣的數據具有誤導性,並會對模型的表現表現造成負面影響。 這個問題促使研究者開始探究這個可能性:能否使用少量高品質的遵循指示資料來獲得穩健的表現表現? 近期的一些研究得到了鼓舞人心的成果,顯示這個方向是有潛力的。例如 Zhou et al. 提出了 LIMA ,這是一個使用人類專家精挑細選出的高品質資料微調得到的語言模型。該研究表明,即使使用數量有限的高品質遵循指令數據,大型語言模型也可以獲得令人滿意的結果。所以,研究人員得出結論:在對齊方面,少即是多(Less is More)。然而,對於如何為微調多模態語言模型選擇合適的高品質資料集,之前還沒有一個清晰的指導方針。 上海交通大學清源研究院和里海大學的研究團隊填補了這一空白,提出了一個穩健有效的數據選擇器。這個數據選擇器能夠自動識別並過濾低品質視覺 - 語言數據,從而確保模型訓練所使用的都是最相關和資訊最豐富的樣本。 #論文網址:https://arxiv.org/abs/2308.12067 研究者表示,這項研究關注的重點是探索少量但優質的指令微調資料對微調多模態大型語言模型的功效。除此之外,這篇論文還引入了幾個專為評估多模態指令資料的品質而設計的新指標。在影像上執行譜聚類之後,資料選擇器會計算一個加權分數,其組合了 CLIP 分數、GPT 分數、獎勵分數和每個視覺 - 語言資料的答案長度。 透過在微調 MiniGPT-4 所使用的 3400 個原始資料上使用該選擇器,研究者發現這些資料大部分都有低品質的問題。使用這個數據選擇器,研究者得到了一個小得多的精選數據子集 —— 僅有 200 個數據,只有原始數據集的 6%。然後他們使用像 MiniGPT-4 一樣的訓練配置,微調得到了一個新模型:InstructionGPT-4。 研究者表示這是一個令人興奮的發現,因為其顯示:在視覺 - 語言指令微調中,資料的品質比數量更重要。此外,這種更強調資料品質的變革提供了一個能提升 MLLM 微調的更有效的新範式。研究者進行了嚴格的實驗,對已微調MLLM 的實驗評估集中於七個多樣化且複雜的開放域多模態資料集,包括Flick- 30k、ScienceQA、 VSR 等。他們在不同的多模態任務上比較了使用不同資料集選取方法(使用資料選擇器、對資料集隨機取樣、使用完整資料集)而微調得到的模型的推理性能,結果展現了InstructionGPT-4 的優越性。 此外還需說明:研究者用於評估的評估者是 GPT-4。具體而言,研究者使用了 prompt 將 GPT-4 變成了評價者,可以使用 LLaVA-Bench 中的測試集來比較 InstructionGPT-4 和原始 MiniGPT-4 的反應結果。 結果發現,儘管與MiniGPT-4 所使用的原始指令遵循資料相比,InstructionGPT-4 使用的微調資料僅有6% 那麼一點點,但後者在73% 的情況下給出的反應都相同或更好。
- #透過選擇200 個(約6%)高品質的指令遵循資料來訓練InstructionGPT-4,研究者表明可以為多模態大型語言模型使用更少的指令資料來實現更好的對齊。
- 文中提出了一種資料選擇器,其使用了一種可解釋的簡單原則來選取用於微調的高品質多模態指令遵循資料。這種方法力求在資料子集的評估和調整中實現有效性和可攜性。
- 研究者透過實驗顯示這種簡單技巧能夠很好地應對不同任務。相較於原始的 MiniGPT-4,僅使用 6% 已過濾資料微調得到的 InstructionGPT-4 在多種任務上都取得了更優表現。
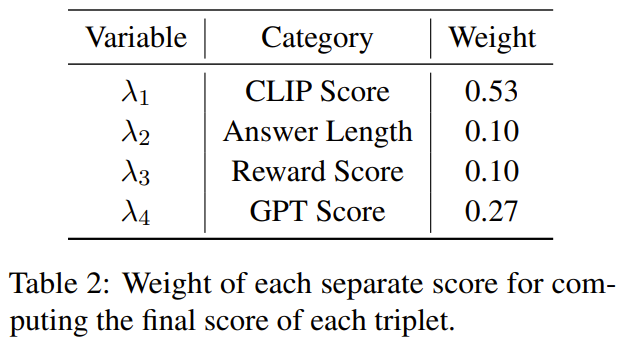
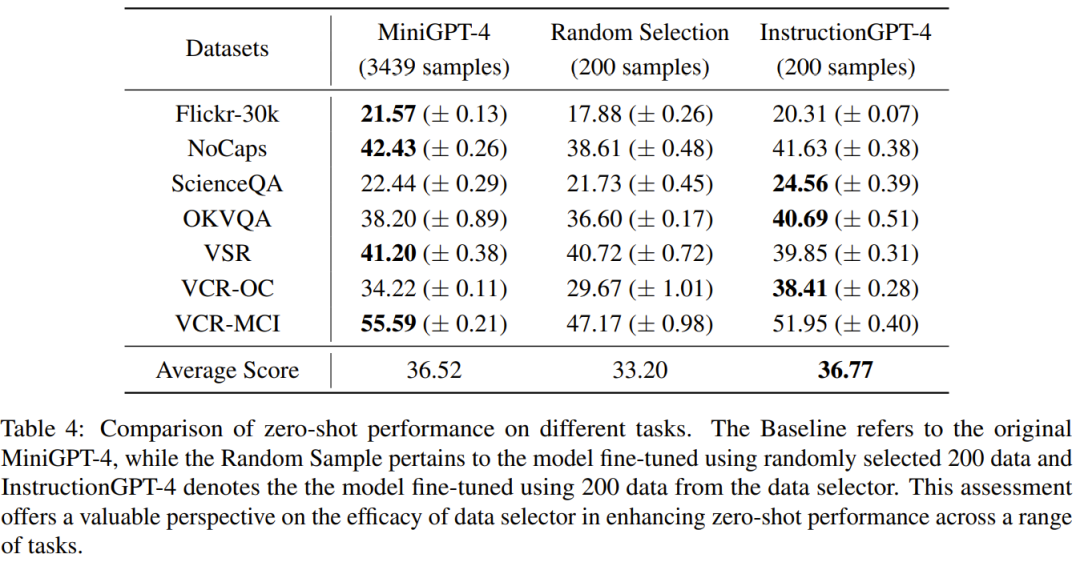
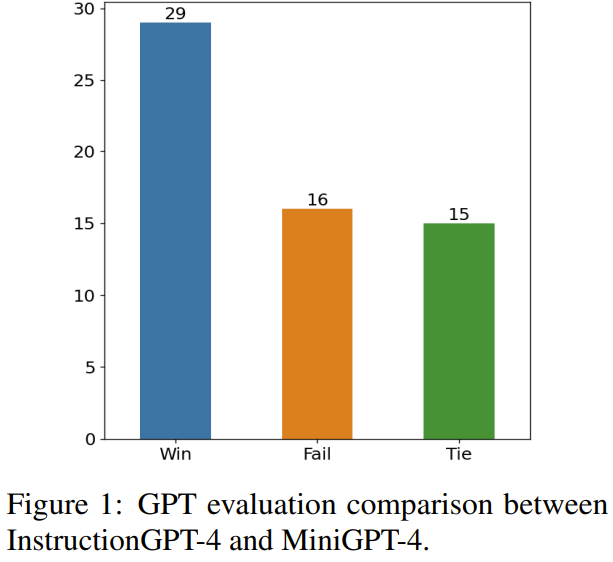
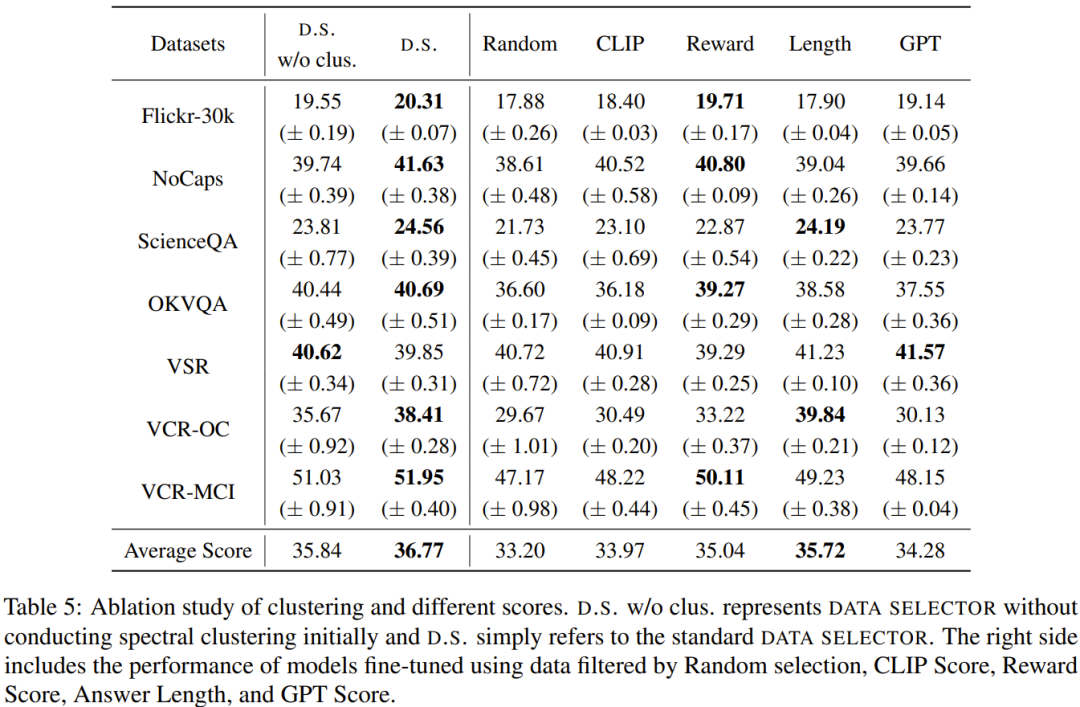
這項研究的目標是提出一個簡單且可移植的資料選擇器,使其能自動從原始微調資料集中精選出子集。為此,研究者定義了一個選取原則,該原則的重點是多模態資料集的多樣化和品質。下面將簡單介紹一下。 #為了有效地訓練MLLM,選取有用的多模態指令資料是至關重要的。而為了選出最優的指令數據,研究者提出了兩大關鍵原則:多樣性與品質。對於多樣性,研究者採用的方法是對影像嵌入進行聚類,以將資料分成不同的組別。為了評估質量,研究者採用了一些用於高效評估多模態資料的關鍵指標。 給定一個視覺-語言指令資料集和一個預訓練MLLM(如MiniGPT-4 和LLaVA),資料選擇器的最終目標是識別出一個用於微調的子集並且使得該子集能為預訓練MLLM 帶來提升。 為了選出這個子集並確保其多樣性,研究者首先是使用聚類演算法將原始資料集分成多個類別。 為了確保所選的多模態指令資料的質量,研究者制定了一套用於評估的指標,如下表 1 所示。 表 2 則給出了在計算最終分數時,每個不同分數的權重。 #表4 比較了MiniGPT- 4 基準模型、使用隨機取樣的資料微調得到的MiniGPT-4 以及使用資料選擇器微調得到的InstructionGPT-4 的表現。可以觀察到,InstructionGPT-4 的平均表現是最好的。具體來說,InstructionGPT-4 在 ScienceQA 的表現超過基準模型 2.12%,在 OKVQA 和 VCR-OC 上則分別超過基準模型 2.49% 和 4.19%。 此外,InstructionGPT-4 在除 VSR 之外的所有其它任務上都優於隨機樣本訓練的模型。透過在一系列任務上評估和對比這些模型,可以辨別出它們各自的能力,並確定新提出的數據選擇器的效能 —— 數據選擇器能有效識別高品質數據。 這樣的全面分析顯示:明智的資料選擇可以提升模型在各種不同任務上的零樣本表現。 LLM 本身存在固有的位置偏見,對此可參考本站文章《語言模型悄悄偷懶?新研究:上下文太長,模型會略過中間不看》。因此研究者採取了措施來解決這個問題,具體來說就是同時使用兩種排布回應的順序來執行評估,即將 InstructionGPT-4 產生的回應放在 MiniGPT-4 產生的回應之前或之後。為了製定明確的評判標準,他們採用了「贏-平-輸」(Win-Tie-Lose)框架:1) 贏:InstructionGPT-4 在兩種情況下都贏或贏一次平一次;2) 平:InstructionGPT-4 與MiniGPT-4 平手兩次或贏一次輸一次;3) 輸:InstructionGPT-4輸兩次或輸一次平一次。 在 60 個問題上,InstructionGPT-4 贏 29 局,輸 16 局,其餘 15 局平手。這足以證明在響應質量上,InstructionGPT-4 明顯優於 MiniGPT-4。 表5 給了消融實驗的分析結果,從中可以看出聚類演算法和各種評估分數的重要性。
##為了深入了解InstructionGPT-4 在理解視覺輸入和產生合理回應方面的能力,研究者也對InstructionGPT-4 和MiniGPT-4 的圖像理解和對話能力進行了對比評估。此分析基於一個顯眼的實例,涉及到對圖像的描述以及進一步的理解,結果見表 6。 ###############InstructionGPT-4 更擅長提供全面的圖像描述和識別圖像中有趣的方面。與 MiniGPT-4 相比,InstructionGPT-4 更有能力辨識影像中存在的文字。在這裡,InstructionGPT-4 能夠正確指出圖像中有一個短語:Monday, just Monday.###############更多細節請參見原始論文。 ###
以上是精選200筆資料後,MiniGPT-4被配對相同模型的效果超越的詳細內容。更多資訊請關注PHP中文網其他相關文章!






![PHP實戰開發極速入門: PHP快速創建[小型商業論壇]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)




















