

使用SAM實現可靠的多模態3D檢測的RoboFusion

論文連結:https://arxiv.org/pdf/2401.03907.pdf
多模態3D偵測器設計用於研究安全可靠的自動駕駛感知系統。儘管它們在乾淨的基準資料集上取得了最先進的效能,但往往忽略了現實世界環境的複雜性和惡劣條件。同時,隨著視覺基礎模型(VFM)的出現,提高多模態三維偵測的穩健性和泛化能力在自動駕駛中面臨機會和挑戰。因此,作者提出了RoboFusion框架,它利用像SAM這樣的VFM來解決分佈外(OOD)噪音場景。
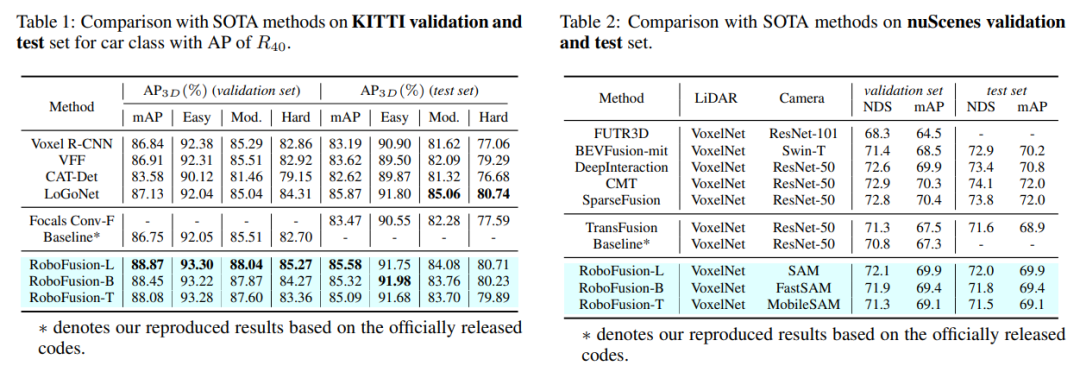
首先,我們將最初的SAM套用於名為SAM-AD的自動駕駛場景。為了將SAM或SAMAD與多模態方法對齊,我們引入了AD-FPN來對SAM擷取的影像特徵進行上取樣。為了進一步降低雜訊和天氣幹擾,我們採用小波分解對深度導引影像進行去雜訊。最後,我們使用自註意機制來自適應地重新加權融合的特徵,以增強資訊特徵的同時抑制過量雜訊。 RoboFusion透過利用VFM的泛化和穩健性逐漸降低噪聲,從而增強了多模式3D目標檢測的彈性。因此,根據KITTIC和nuScenes-C基準測試的結果,RoboFusion在噪音場景中實現了最先進的效能。
論文提出了一個穩健的框架,名為RoboFusion,它利用像SAM這樣的VFM來將3D多模態目標偵測器從乾淨場景調整為OOD噪音場景。其中,SAM的適應策略是關鍵。
1) 使用從SAM中提取的特徵,而不是推理分割結果。
2) 提出了SAM-AD,這是針對AD場景的預訓練SAM。
3) 介紹了一種新的AD-FPN來解決用於將VFM與多模式3D偵測器對準的特徵上取樣問題。
為了降低雜訊幹擾並保留訊號特徵,引入了深度引導小波注意(DGWA)模組,有效衰減高低頻雜訊。
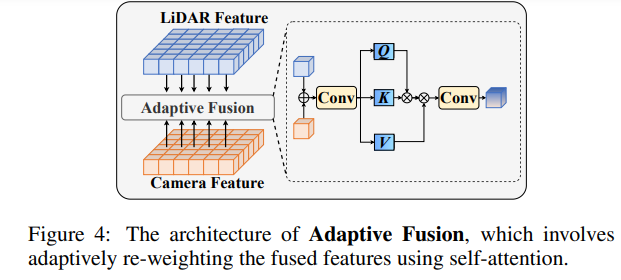
在融合點雲特徵和影像特徵後,透過自適應融合重新加權特徵,增強特徵的穩健性和抗噪性。
RoboFusion網路結構
RoboFusion框架如下所示,其雷射雷達分支遵循基線[Chen et al.,2022;Bai et al.,2022]產生激光雷達特徵。在相機分支中,首先採用高度最佳化的SAM-AD演算法擷取穩健的影像特徵,並結合AD-FPN以取得多尺度特徵。接下來,利用原始點產生稀疏深度圖S,並將其輸入深度編碼器以獲得深度特徵,同時與多尺度影像特徵進行融合,得到深度引導影像特徵。然後,透過波動注意力機制去除突變雜訊。最後,透過自註意機制實現自適應融合,將點雲特徵與具有深度資訊的穩健影像特徵結合。
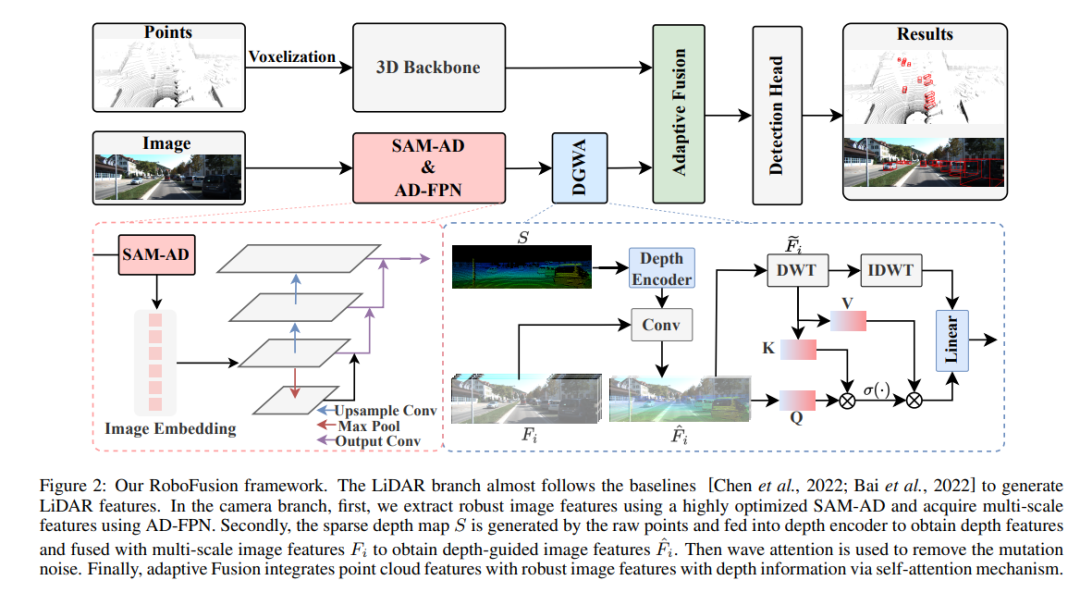
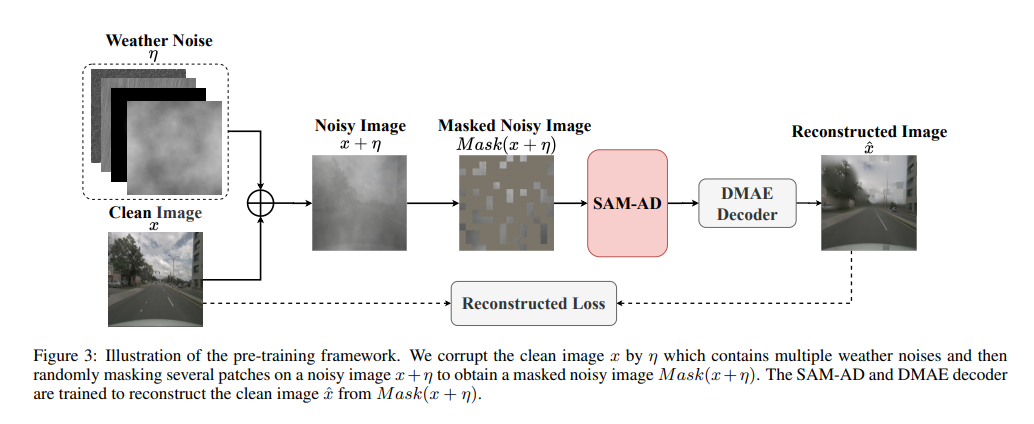
SAM-AD:為了進一步讓SAM適應AD(自動駕駛)場景,對SAM進行預先訓練以獲得SAM-AD。具體而言,我們從成熟的資料集(即KITTI和nuScenes)中收集了大量影像樣本,形成了基礎的AD資料集。在DMAE之後,對SAM進行預訓練,以獲得AD場景中的SAM-AD,如圖3所示。將x表示為來自AD資料集的乾淨影像(即KITTI和nuScenes),將η表示為基於x產生的雜訊影像。噪音類型和嚴重程度分別從四種天氣(即雨、雪、霧和陽光)和1-5的五種嚴重程度中隨機選擇。使用SAM、MobileSAM的影像編碼器作為我們的編碼器,而解碼器和重建損失與DMAE相同。
AD-FPN。作為一種可提示的分割模型,SAM由三個部分組成:影像編碼器、提示編碼器和遮罩解碼器。一般來說,有必要將影像編碼器推廣到訓練VFM,然後再訓練解碼器。換言之,影像編碼器可以為下游模型提供高品質和高度穩健的影像嵌入,而遮罩解碼器僅被設計為提供用於語義分割的解碼服務。此外,我們需要的是魯棒的圖像特徵,而不是提示編碼器對提示訊息的處理。因此,我們使用SAM的影像編碼器來提取穩健的影像特徵。然而,SAM利用ViT系列作為其影像編碼器,其排除了多尺度特徵,僅提供高維度低解析度特徵。為了產生目標偵測所需的多尺度特徵,受[Li et al.,2022a]的啟發,設計了一種AD-FPN,它提供基於ViT的多尺度特性!
儘管SAM-AD或SAM具有提取穩健影像特徵的能力,但2D域和3D域之間的差距仍然存在,並且在損壞的環境中缺乏幾何資訊的相機經常放大雜訊並引起負遷移問題。為了緩解這個問題,我們提出了深度引導小波注意(DGWA)模組,該模組可以分為以下兩個步驟。 1) 設計了一個深度引導網絡,透過結合點雲的影像特徵和深度特徵,在影像特徵之前添加幾何體。 2) 使用Haar小波轉換將影像的特徵分解為四個子帶,然後注意力機制允許對子帶中的信息特徵進行去噪!
實驗比較
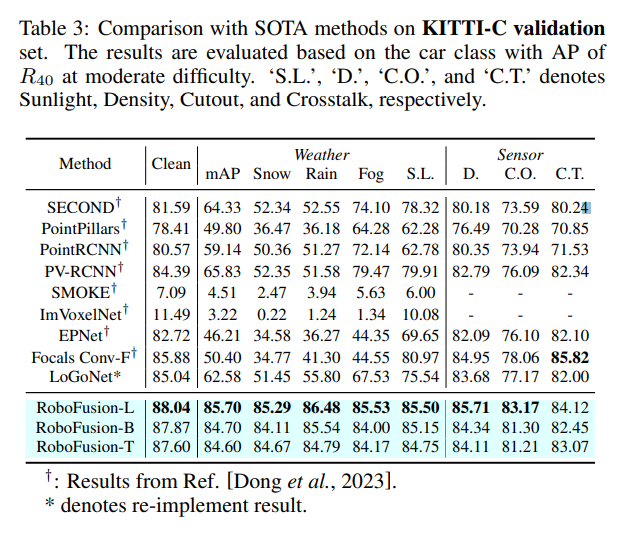
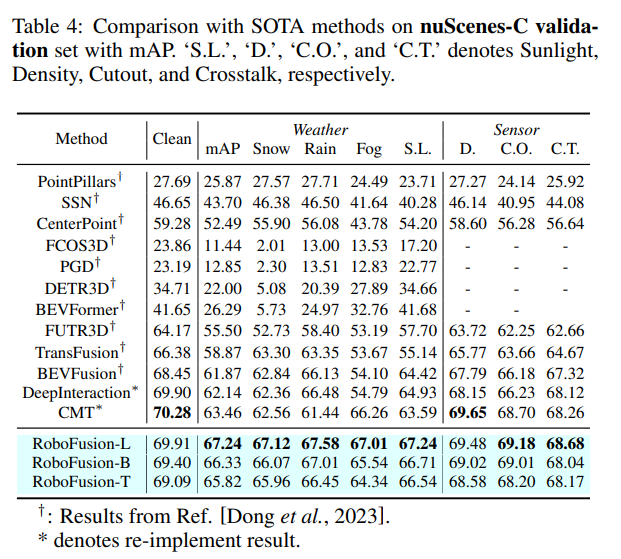
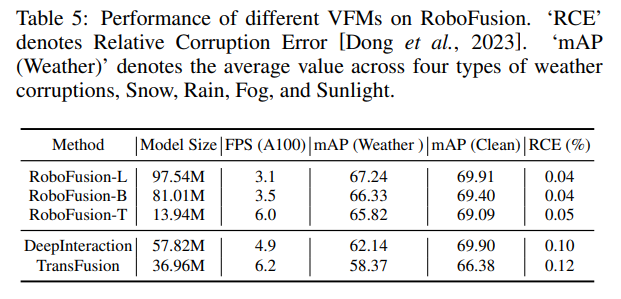


以上是使用SAM實現可靠的多模態3D檢測的RoboFusion的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 如何評估Java框架商業支援的性價比
Jun 05, 2024 pm 05:25 PM
如何評估Java框架商業支援的性價比
Jun 05, 2024 pm 05:25 PM
評估Java框架商業支援的性價比涉及以下步驟:確定所需的保障等級和服務等級協定(SLA)保證。研究支持團隊的經驗和專業知識。考慮附加服務,如昇級、故障排除和效能最佳化。權衡商業支援成本與風險緩解和提高效率。
 PHP 框架的學習曲線與其他語言框架相比如何?
Jun 06, 2024 pm 12:41 PM
PHP 框架的學習曲線與其他語言框架相比如何?
Jun 06, 2024 pm 12:41 PM
PHP框架的學習曲線取決於語言熟練度、框架複雜性、文件品質和社群支援。與Python框架相比,PHP框架的學習曲線較高,而與Ruby框架相比,則較低。與Java框架相比,PHP框架的學習曲線中等,但入門時間較短。
 PHP 框架的輕量級選項如何影響應用程式效能?
Jun 06, 2024 am 10:53 AM
PHP 框架的輕量級選項如何影響應用程式效能?
Jun 06, 2024 am 10:53 AM
輕量級PHP框架透過小體積和低資源消耗提升應用程式效能。其特點包括:體積小,啟動快,記憶體佔用低提升響應速度和吞吐量,降低資源消耗實戰案例:SlimFramework創建RESTAPI,僅500KB,高響應性、高吞吐量
 RedMagic Tablet 3D Explorer Edition 配備裸眼 3D 顯示器
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition 配備裸眼 3D 顯示器
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition 與 Gaming Tablet Pro 一起推出。然而,後者更適合遊戲玩家,而前者則更適合娛樂。新款 Android 平板電腦具有該公司所謂的「裸眼 3D」功能
 golang框架文件最佳實踐
Jun 04, 2024 pm 05:00 PM
golang框架文件最佳實踐
Jun 04, 2024 pm 05:00 PM
編寫清晰全面的文件對於Golang框架至關重要。最佳實踐包括:遵循既定文件風格,例如Google的Go程式設計風格指南。使用清晰的組織結構,包括標題、子標題和列表,並提供導覽。提供全面且準確的信息,包括入門指南、API參考和概念。使用程式碼範例說明概念和使用方法。保持文件更新,追蹤變更並記錄新功能。提供支援和社群資源,例如GitHub問題和論壇。建立實際案例,如API文件。
 如何為不同的應用場景選擇最佳的golang框架
Jun 05, 2024 pm 04:05 PM
如何為不同的應用場景選擇最佳的golang框架
Jun 05, 2024 pm 04:05 PM
根據應用場景選擇最佳Go框架:考慮應用類型、語言特性、效能需求、生態系統。常見Go框架:Gin(Web應用)、Echo(Web服務)、Fiber(高吞吐量)、gorm(ORM)、fasthttp(速度)。實戰案例:建構RESTAPI(Fiber),與資料庫互動(gorm)。選擇框架:效能關鍵選fasthttp,靈活Web應用選Gin/Echo,資料庫互動選gorm。
 Java框架學習路線圖:不同領域中的最佳實踐
Jun 05, 2024 pm 08:53 PM
Java框架學習路線圖:不同領域中的最佳實踐
Jun 05, 2024 pm 08:53 PM
針對不同領域的Java框架學習路線圖:Web開發:SpringBoot和PlayFramework。持久層:Hibernate和JPA。服務端響應式程式設計:ReactorCore和SpringWebFlux。即時計算:ApacheStorm和ApacheSpark。雲端運算:AWSSDKforJava和GoogleCloudJava。
 Golang框架學習過程中常見的迷思有哪些?
Jun 05, 2024 pm 09:59 PM
Golang框架學習過程中常見的迷思有哪些?
Jun 05, 2024 pm 09:59 PM
Go框架學習的迷思有以下5種:過度依賴框架,限制彈性。不遵循框架約定,程式碼難以維護。使用過時庫,帶來安全和相容性問題。過度使用包,混淆程式碼結構。忽視錯誤處理,導致意外行為和崩潰。
