

小紅書搜尋團隊揭示:驗證負樣本在大規模模型蒸餾中的重要性


大語言模型(LLMs)在推理任務上表現出色,但其黑盒屬性和龐大參數量限制了其在實踐中的應用。特別是在處理複雜的數學問題時,LLMs有時會出現錯誤的推理鏈。傳統的研究方法僅從正樣本中遷移知識,忽略了合成資料中帶有錯誤答案的重要資訊。因此,為了提高LLMs的性能和可靠性,我們需要更全面地考慮和利用合成數據,不僅限於正樣本,以幫助LLMs更好地理解和推理複雜問題。這將有助於解決LLMs在實踐中的挑戰,推動其廣泛應用。
在AAAI 2024 上,小紅書搜尋演算法團隊##提出了一個創新框架,在蒸餾大模型推理能力的過程中充分利用負樣本知識。負樣本,即那些在推理過程中未能得出正確答案的數據,雖常被視為無用,實則蘊含著寶貴的資訊。
論文提出並驗證了負樣本在大模型蒸餾過程中的價值,建構一個模型專業化框架:除了使用正樣本外,還充分利用負樣本來提煉LLM 的知識。該框架包括三個序列化步驟,包括負向協助訓練(NAT)、負向校準增強(NCE)和動態自洽性(ASC),涵蓋從訓練到推理的全階段過程。透過一系列廣泛的實驗,我們展示了負向數據在 LLM 知識蒸餾中的關鍵作用。
一、背景在當前情況下,思維鏈(CoT)的引導下,大型語言模型(LLMs)展現了強大的推理能力。然而,我們已經證明,這種湧現能力只有具備千億級參數的模型才能夠實現。由於這些模型需要龐大的計算資源和高昂的推理成本,它們在資源受限的情況下很難應用。因此,我們的研究目標是開發出能夠進行複雜算術推理的小型模型,以便在實際應用中進行大規模部署。
知識蒸餾提供了一種有效的方法,可以將 LLMs 的特定能力遷移到更小的模型中。這個過程也被稱為模型專業化(model specialization),它強制小模型專注於某些能力。先前的研究利用 LLMs 的上下文學習(ICL)來產生數學問題的推理路徑,並將其作為訓練數據,有助於小模型獲得複雜推理能力。然而,這些研究只使用了產生的具有正確答案的推理路徑(即正樣本)作為訓練樣本,忽略了在錯誤答案(即負樣本)的推理步驟中有價值的知識。因此,研究者開始探索如何利用負樣本中的推理步驟,以提高小模型的表現。 一種方法是使用對抗訓練,即引入一個生成器模型來產生錯誤答案的推理路徑,然後將這些路徑與正樣本一起用於訓練小模型。這樣,小模型可以學習到在錯誤推理步驟中的有價值的知識,並提高其推理能力。另一種方法是利用自監督學習,透過將正確答案與錯誤答案進行對比,讓小模型學習區分它們,並從中提取有用的信息。這些方法都可以為小模型提供更全面的訓練,使其具備更強大的推理能力。 總之,利用負樣本中的推理步驟可以幫助小模型獲得更全面的訓練,提升其推理能力。這種
 圖片
圖片
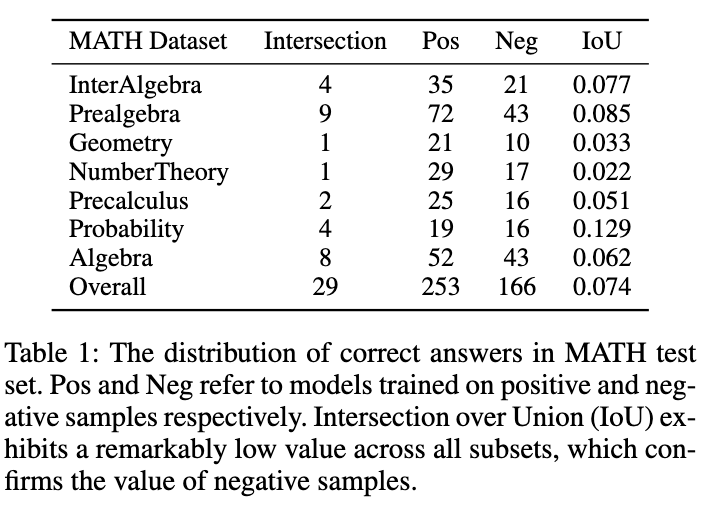
如圖所示,表1 展示了一個有趣的現象:分別在正、負樣本在資料上訓練的模型,在MATH 測試集上的準確答案重疊非常小。儘管負樣本訓練的模型準確性較低,但它能夠解決一些正樣本模型無法正確回答的問題,這證實了負樣本中包含著寶貴的知識。此外,負樣本中的錯誤連結能夠幫助模型避免犯下類似錯誤。另一個我們應該利用負樣本的原因是 OpenAI 基於 token 的定價策略。即使是 GPT-4,在 MATH 資料集上的準確性也低於 50%,這意味著如果只利用正樣本知識,大量的 token 會被浪費。因此,我們提出:相較於直接丟棄負樣本,更好的方式是從中提取並利用有價值的知識,以增強小模型的專業化。
模型專業化過程一般可以概括為三個步驟:
1)思維鏈蒸餾(Chain-of-Thought Distillation),使用LLMs 產生的推理鏈訓練小模型。
2)自我增強(Self-Enhancement),進行自蒸餾或資料自擴充,以進一步優化模型。
3)自洽性(Self-Consistency)被廣泛用作一種有效的解碼策略,以提高推理任務中的模型效能。
在這項工作中,我們提出了一種新的模型專業化框架,可以全方位利用負樣本,促進從 LLMs 提取複雜推理能力。
- 我們首先設計了負向協助訓練(NAT)方法,其中dual-LoRA 結構被設計用於從正向、負向兩方面獲取知識。作為一個輔助模組,負向 LoRA 的知識可以透過校正注意力機制,動態地整合到正向 LoRA 的訓練過程中。
- 對於自我增強,我們設計了負向校準增強(NCE),它將負向輸出作為基線,以加強關鍵正向推理鏈路的蒸餾。
- 除了訓練階段,我們在推理過程中也利用負向資訊。傳統的自洽性方法將相等或基於機率的權重分配給所有候選輸出,導致投票出一些不可靠的答案。為了緩解該問題,提出了動態自洽性(ASC)方法,在投票前進行排序,其中排序模型在正負樣本上進行訓練的。
二、方法
我們提出的框架以LLaMA 為基礎模型,主要包含三個部分,如圖所示:
-
步驟1 :對負向LoRA 進行訓練,透過合併單元幫助學習正樣本的推理知識;
-
##步驟2 :利用負向LoRA 作為基準來校準自我增強的過程;
- ##步驟3 :在正樣本和負樣本上訓練排名模型,在推理過程中根據其得分,自適應地對候選推理鏈路進行加權。
圖片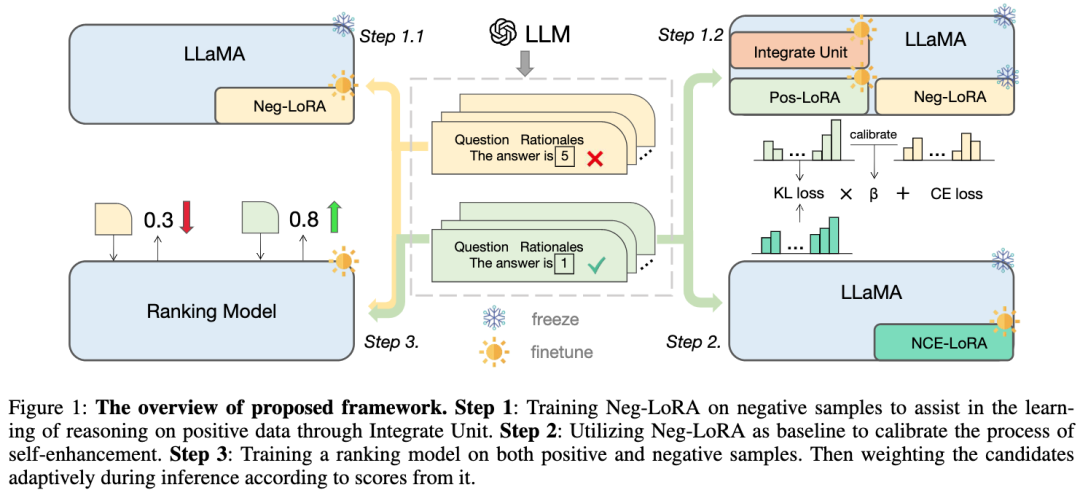
2.1 負向協助訓練(NAT)我們提出了一個兩階段的負向協助訓練(NAT)範式,分為
負向知識吸收與動態整合單元兩部分:
2.1.1 負向知識吸收
#透過在負向資料
上最大化以下期望,負樣本的知識被LoRA θ
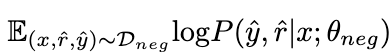 吸收。在這個過程中,LLaMA 的參數保持凍結。
吸收。在這個過程中,LLaMA 的參數保持凍結。
圖片
2.1.2 動態整合單元
由於無法預先確定 θ
擅長哪些數學問題,我們設計瞭如下圖所示的動態整合單元,以便在 學習正樣本知識的過程中,動態整合來自 θ
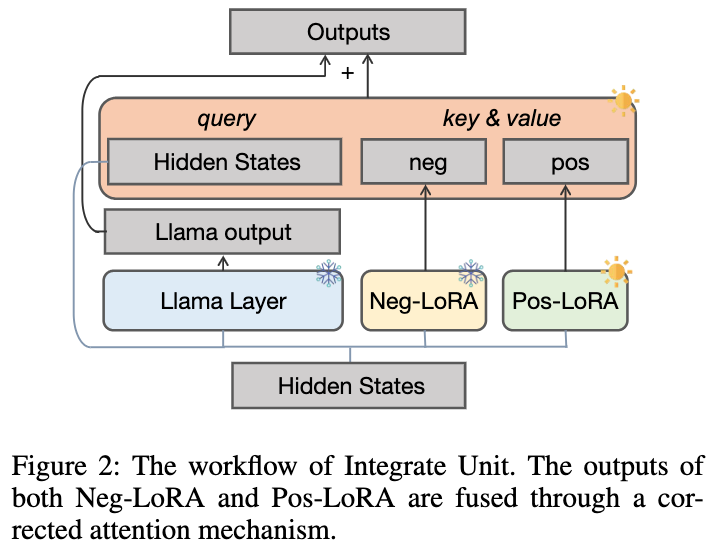 的知識:
的知識:
#圖片
我們凍結 θ
以防止內部知識被遺忘,並額外引入正LoRA 模組 θ 。理想情況下,我們應該正向整合正負 LoRA 模組(在每個 LLaMA 層中輸出表示為 與 ),以補充正樣本中所缺乏但對應 所具有的有益知識。當 θ
包含有害知識時,我們應該對正負 LoRA 模組進行負向集成,以幫助減少正樣本中可能的不良行為。
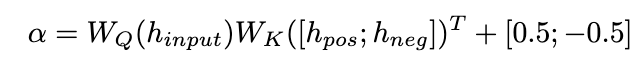 我們提出了一種修正注意力機制來實現這一目標,如下所示:
我們提出了一種修正注意力機制來實現這一目標,如下所示:
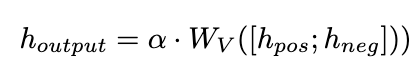 圖片
圖片
我們使用
作為詢問來計算 和 的注意力權重。透過在增加校正項 [0.5;-0.5], 的注意力權重被限制在 [-0.5,0.5] 的範圍內,從而實現了在正、負兩個方向上自適應地整合來自 的知識的效果。最終,
和 LLaMA 層輸出的總和形成了動態整合單元的輸出。
2.2 負向校準增強(NCE)
為了進一步增強模型的推理能力,我們提出了負校準增強(NCE),它使用負面知識來幫助自我增強過程。我們首先使用 NAT 為中的每個問題產生對作為擴充樣本,並將它們補充到訓練資料集中。對於自蒸餾部分,我們注意到一些樣本可能包含更關鍵的推理步驟,對提升模型的推理能力至關重要。我們的主要目標是確定這些關鍵的推理步驟,並在自蒸餾過程中加強對它們的學習。
考慮NAT 已經包含了 θ
的有用知識,使得NAT 比 θ
推理能力較強的因素,隱含在兩者之間不一致的推理連結中。因此,我們使用KL 散度來測量這種不一致性,並最大化該公式的期望:
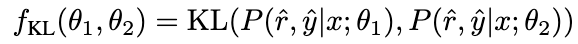
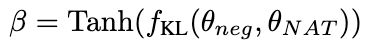
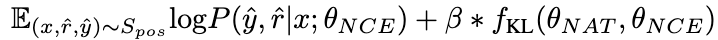
##圖片
圖片#β 值越大,表示兩者之間的差異越大,表示該樣本包含更多關鍵知識。透過引入 β 來調整不同樣本的損失權重,NCE 將能夠選擇性地學習並增強 NAT 中嵌入的知識。
 2.3 動態自洽性(ASC)
2.3 動態自洽性(ASC)
#自洽性(SC)對於進一步提升模型在複雜推理中的表現有效的。然而,目前的方法要么為每個候選者分配相等的權重,要么簡單地基於生成機率分配權重。這些策略無法在投票階段根據 (rˆ, yˆ) 的品質調整候選權重,這可能會使正確候選項不易被選出。為此,我們提出了動態自洽性方法(ASC),它利用正負資料來訓練排序模型,可以自適應地重新配權候選推理鏈路。
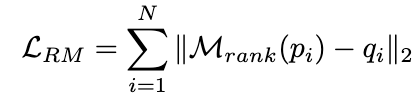 2.3.1 排序模型訓練
2.3.1 排序模型訓練
#理想情況下,我們希望排序模型為得出正確答案的推理鏈路分配更高的權重,反之亦然。因此,我們用以下方式建構訓練樣本:
圖片
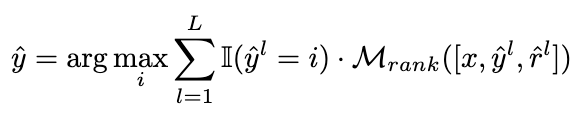 並使用MSE loss 去訓練排序模型:
並使用MSE loss 去訓練排序模型:
圖片
 2.3.2 加權策略
2.3.2 加權策略
##我們將投票策略修改為以下公式,以實現自適應地重新加權候選推理鏈路的目標:
圖片
######下圖中展示了ASC 策略的流程:###############圖片############從知識遷移的角度來看,ASC 實作了對來自LLMs的知識(正向和負向)的進一步利用,以幫助小模型獲得更好的性能。 #########三、實驗#########本研究專注於具有挑戰性的數學推理資料集 MATH,該資料集共有 12500 個問題,涉及七個不同的科目。此外,我們也引入了以下四個資料集來評估所提出的框架對分佈外(OOD)資料的泛化能力:GSM8K、ASDiv、MultiArith和SVAMP。 ######對於教師模型,我們使用 Open AI 的 gpt-3.5-turbo 和 gpt-4 API來產生推理鏈。對於學生模型,我們選擇 LLaMA-7b。
在我們的研究中有兩種主要類型的基準:一種為大語言模型(LLMs),另一種則是基於 LLaMA-7b。對於 LLMs,我們將其與兩種流行的模型進行比較:GPT3 和 PaLM。對於 LLaMA-7b,我們首先提供我們的方法與三種設定進行比較:Few-shot、Fine-tune(在原始訓練樣本上)、CoT KD(思維鏈蒸餾)。在從負向角度學習方面,還將包括四種基線方法:MIX(直接以正向和負向資料的混合物訓練LLaMA)、CL(對比學習)、NT(負訓練)和UL(非似然損失)。
3.1 NAT 實驗結果
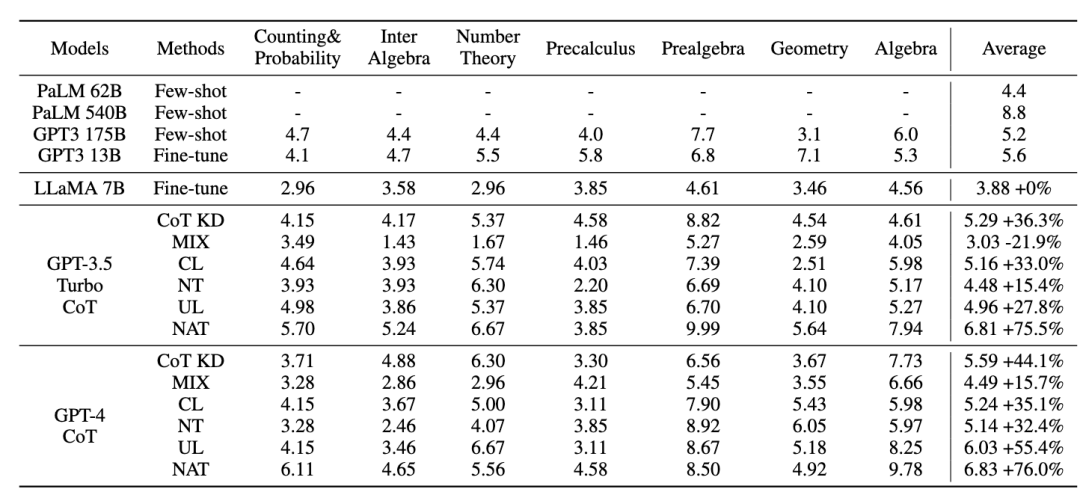
#所有的方法都使用了貪婪搜尋(即溫度= 0),NAT 的實驗結果如圖所示,顯示所提出的NAT 方法在所有基線上都提高了任務準確性。
從 GPT3 和 PaLM 的低值可以看出,MATH 是一個非常困難的數學資料集,但 NAT 仍然能夠在參數極少的情況下表現突出。與在原始資料上進行微調相比,NAT 在兩種不同的 CoT 來源下實現了約 75.75% 的提升。與 CoT KD 在正樣本上的比較,NAT 也顯著提高了準確性,顯示了負樣本的價值。
對於利用負向資訊基線,MIX 的低效能表示直接訓練負樣本會使模型效果很差。其他方法也大多不如 NAT,這表明在複雜推理任務中僅在負方向上使用負樣本是不夠的。
 圖片
圖片
3.2 NCE 實驗結果
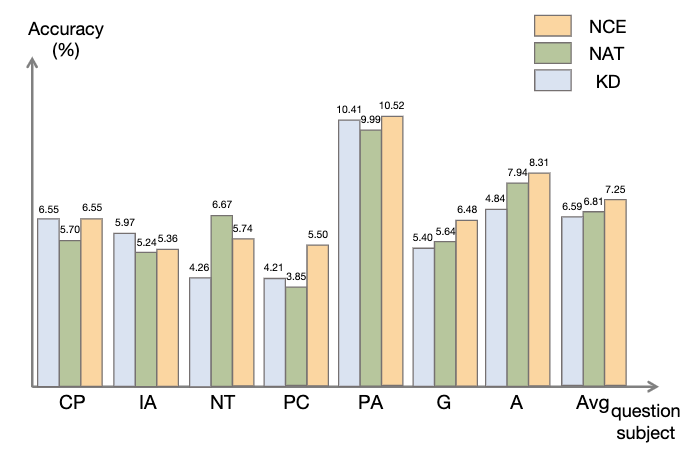
如圖所示,與知識蒸餾(KD)相比,NCE 實現了平均10%(0.66) 的進步,證明了利用負樣本提供的校準資訊進行蒸餾的有效性。與 NAT 相比,儘管 NCE 減少了一些參數,但它仍然有 6.5% 的進步,實現壓縮模型並提高性能的目的。
 圖片
圖片
3.3 ASC 實驗結果
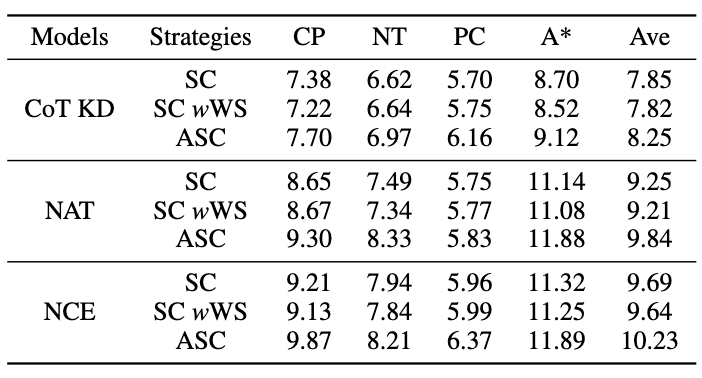
為了評估ASC,我們將其與基礎SC 和加權(WS)SC 進行比較,使用採樣溫度T = 1 產生了16 個樣本。如圖所示,結果表明,ASC 從不同樣本聚合答案,是一種更有前景的策略。
 圖片
圖片
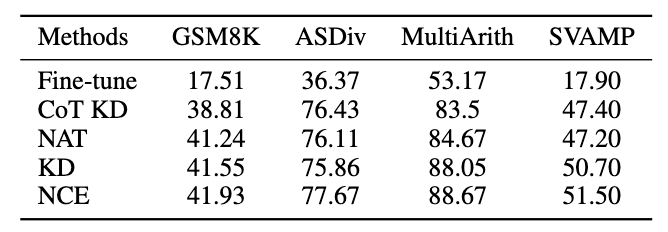
3.4 泛化性實驗結果
除了MATH 資料集,我們評估了框架在其他數學推理任務上的泛化能力,實驗結果如下。
 圖片
圖片
四、結語
本篇工作探討了利用負樣本從大語言模型中提煉複雜推理能力,遷移到專業化小模型的有效性。 小紅書搜尋演算法團隊提出了一個全新的框架,由三個序列化步驟組成,並在模型專業化的整個過程中充分利用負向資訊。 負向協助訓練(NAT)可以從兩個角度提供更全面地利用負向資訊的方法。 負向校準增強(NCE)能夠校準自蒸餾過程,使其更有針對性地掌握關鍵知識。基於兩種觀點訓練的排序模型可以為答案聚合分配更適當的權重,以實現動態自洽性(ASC)。大量實驗表明,我們的框架可以透過產生的負樣本來提高提煉推理能力的有效性。
論文網址:https://www.php.cn/link/8fa2a95ee83cd1633cfd64f78e856bd3
#五、作者簡介
-
李易為:
##現博士就讀於北京理工大學,小紅書社群搜尋實習生,在AAAI、ACL、EMNLP、NAACL、NeurIPS、KBS 等機器學習、自然語言處理領域頂尖會議/期刊上發表數篇論文,主要研究方向為大語言模式蒸餾與推理、開放域對話生成等。
-
袁沛文:
-
##。現博士就讀於北京理工大學,小紅書社群搜尋實習生,在NeurIPS、AAAI 等發表多篇一作論文,曾獲DSTC11 Track 4 第二名。主要研究方向為大語言模式推理與評測。
馮少雄:
#負責小紅書社群搜尋向量回想。在 AAAI、EMNLP、ACL、NAACL、KBS 等機器學習、自然語言處理領域頂尖會議/期刊發表數篇論文。
以上是小紅書搜尋團隊揭示:驗證負樣本在大規模模型蒸餾中的重要性的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 10個生成AI編碼擴展,在VS代碼中,您必須探索
Apr 13, 2025 am 01:14 AM
10個生成AI編碼擴展,在VS代碼中,您必須探索
Apr 13, 2025 am 01:14 AM
嘿,編碼忍者!您當天計劃哪些與編碼有關的任務?在您進一步研究此博客之前,我希望您考慮所有與編碼相關的困境,這是將其列出的。 完畢? - 讓&#8217
 GPT-4O vs OpenAI O1:新的Openai模型值得炒作嗎?
Apr 13, 2025 am 10:18 AM
GPT-4O vs OpenAI O1:新的Openai模型值得炒作嗎?
Apr 13, 2025 am 10:18 AM
介紹 Openai已根據備受期待的“草莓”建築發布了其新模型。這種稱為O1的創新模型增強了推理能力,使其可以通過問題進行思考
 視覺語言模型(VLMS)的綜合指南
Apr 12, 2025 am 11:58 AM
視覺語言模型(VLMS)的綜合指南
Apr 12, 2025 am 11:58 AM
介紹 想像一下,穿過美術館,周圍是生動的繪畫和雕塑。現在,如果您可以向每一部分提出一個問題並獲得有意義的答案,該怎麼辦?您可能會問:“您在講什麼故事?
 pixtral -12b:Mistral AI'第一個多模型模型 - 分析Vidhya
Apr 13, 2025 am 11:20 AM
pixtral -12b:Mistral AI'第一個多模型模型 - 分析Vidhya
Apr 13, 2025 am 11:20 AM
介紹 Mistral發布了其第一個多模式模型,即Pixtral-12b-2409。該模型建立在Mistral的120億參數Nemo 12B之上。是什麼設置了該模型?現在可以拍攝圖像和Tex
 如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
如何在SQL中添加列? - 分析Vidhya
Apr 17, 2025 am 11:43 AM
SQL的Alter表語句:動態地將列添加到數據庫 在數據管理中,SQL的適應性至關重要。 需要即時調整數據庫結構嗎? Alter表語句是您的解決方案。本指南的詳細信息添加了Colu
 超越駱駝戲:大型語言模型的4個新基準
Apr 14, 2025 am 11:09 AM
超越駱駝戲:大型語言模型的4個新基準
Apr 14, 2025 am 11:09 AM
陷入困境的基準:駱駝案例研究 2025年4月上旬,梅塔(Meta)揭開了其Llama 4套件的模特,擁有令人印象深刻的性能指標,使他們對GPT-4O和Claude 3.5 Sonnet等競爭對手的良好定位。倫斯的中心
 如何使用AGNO框架構建多模式AI代理?
Apr 23, 2025 am 11:30 AM
如何使用AGNO框架構建多模式AI代理?
Apr 23, 2025 am 11:30 AM
在從事代理AI時,開發人員經常發現自己在速度,靈活性和資源效率之間進行權衡。我一直在探索代理AI框架,並遇到了Agno(以前是Phi-
 多動症遊戲,健康工具和AI聊天機器人如何改變全球健康
Apr 14, 2025 am 11:27 AM
多動症遊戲,健康工具和AI聊天機器人如何改變全球健康
Apr 14, 2025 am 11:27 AM
視頻遊戲可以緩解焦慮,建立焦點或支持多動症的孩子嗎? 隨著醫療保健在全球範圍內挑戰,尤其是在青年中的挑戰,創新者正在轉向一種不太可能的工具:視頻遊戲。現在是世界上最大的娛樂印度河之一
