

詳解B+樹的原理及實作Python程式碼

B 樹是自平衡樹的高級形式,其中所有值都存在於葉級中。 B 樹所有葉子都處於同一水平,每個節點的子節點數量≥2。 B 樹與B樹的差異在於各節點在B樹上不是相互連接,而在B 樹上是相互連接的。
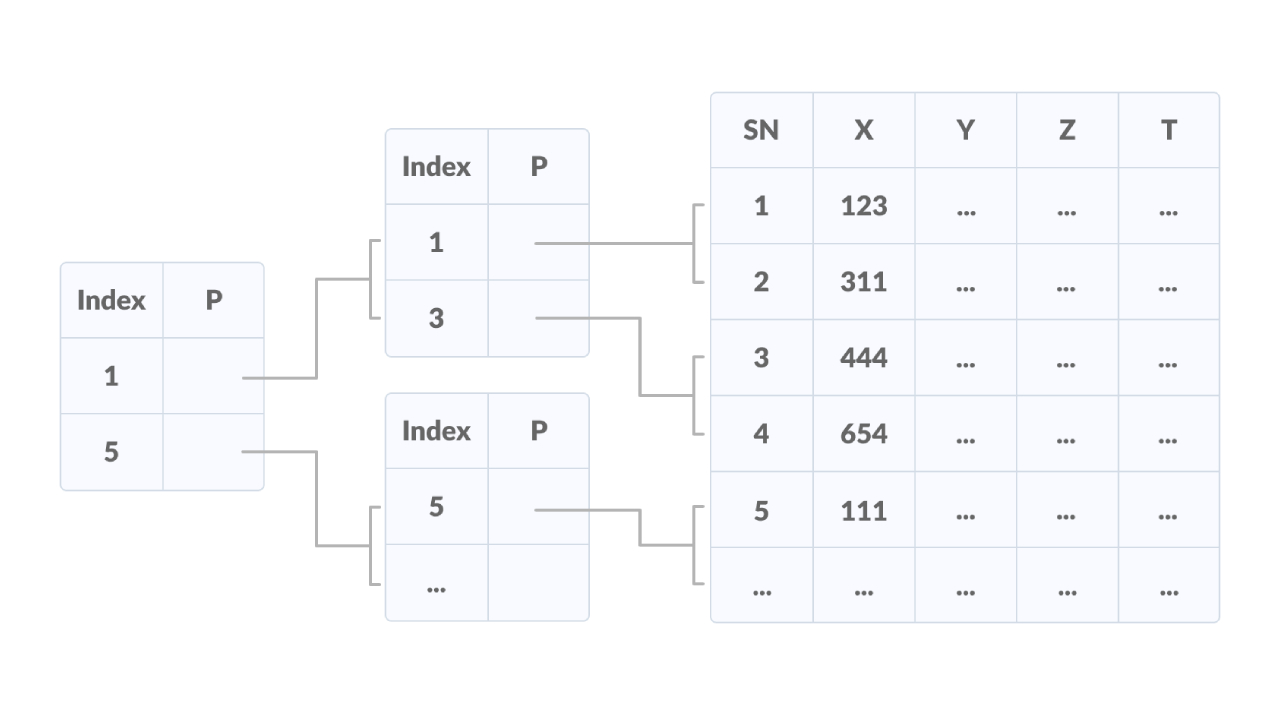
B 樹多層索引結構圖
B 樹搜尋規則
1、從根節點開始。將k與根節點的鍵進行比較[k1,k2,k3,......k(m-1)]
2、如果k 3、如果k==k1,再和ķ2比較.,如果k 4、如果k>k2,繼續和k3,k4,...k(m-1)比較,重複如第2步和第3步 5、直到節點中存在k,則傳回true,否則回傳false。 以上是詳解B+樹的原理及實作Python程式碼的詳細內容。更多資訊請關注PHP中文網其他相關文章!Python實作B 樹
import math
class Node:
def __init__(self, order):
self.order = order
self.values = []
self.keys = []
self.nextKey = None
self.parent = None
self.check_leaf = False
def insert_at_leaf(self, leaf, value, key):
if (self.values):
temp1 = self.values
for i in range(len(temp1)):
if (value == temp1[i]):
self.keys[i].append(key)
break
elif (value < temp1[i]):
self.values = self.values[:i] + [value] + self.values[i:]
self.keys = self.keys[:i] + [[key]] + self.keys[i:]
break
elif (i + 1 == len(temp1)):
self.values.append(value)
self.keys.append([key])
break
else:
self.values = [value]
self.keys = [[key]]
class BplusTree:
def __init__(self, order):
self.root = Node(order)
self.root.check_leaf = True
def insert(self, value, key):
value = str(value)
old_node = self.search(value)
old_node.insert_at_leaf(old_node, value, key)
if (len(old_node.values) == old_node.order):
node1 = Node(old_node.order)
node1.check_leaf = True
node1.parent = old_node.parent
mid = int(math.ceil(old_node.order / 2)) - 1
node1.values = old_node.values[mid + 1:]
node1.keys = old_node.keys[mid + 1:]
node1.nextKey = old_node.nextKey
old_node.values = old_node.values[:mid + 1]
old_node.keys = old_node.keys[:mid + 1]
old_node.nextKey = node1
self.insert_in_parent(old_node, node1.values[0], node1)
def search(self, value):
current_node = self.root
while(current_node.check_leaf == False):
temp2 = current_node.values
for i in range(len(temp2)):
if (value == temp2[i]):
current_node = current_node.keys[i + 1]
break
elif (value < temp2[i]):
current_node = current_node.keys[i]
break
elif (i + 1 == len(current_node.values)):
current_node = current_node.keys[i + 1]
break
return current_node
def find(self, value, key):
l = self.search(value)
for i, item in enumerate(l.values):
if item == value:
if key in l.keys[i]:
return True
else:
return False
return False
def insert_in_parent(self, n, value, ndash):
if (self.root == n):
rootNode = Node(n.order)
rootNode.values = [value]
rootNode.keys = [n, ndash]
self.root = rootNode
n.parent = rootNode
ndash.parent = rootNode
return
parentNode = n.parent
temp3 = parentNode.keys
for i in range(len(temp3)):
if (temp3[i] == n):
parentNode.values = parentNode.values[:i] + \
[value] + parentNode.values[i:]
parentNode.keys = parentNode.keys[:i +
1] + [ndash] + parentNode.keys[i + 1:]
if (len(parentNode.keys) > parentNode.order):
parentdash = Node(parentNode.order)
parentdash.parent = parentNode.parent
mid = int(math.ceil(parentNode.order / 2)) - 1
parentdash.values = parentNode.values[mid + 1:]
parentdash.keys = parentNode.keys[mid + 1:]
value_ = parentNode.values[mid]
if (mid == 0):
parentNode.values = parentNode.values[:mid + 1]
else:
parentNode.values = parentNode.values[:mid]
parentNode.keys = parentNode.keys[:mid + 1]
for j in parentNode.keys:
j.parent = parentNode
for j in parentdash.keys:
j.parent = parentdash
self.insert_in_parent(parentNode, value_, parentdash)
def delete(self, value, key):
node_ = self.search(value)
temp = 0
for i, item in enumerate(node_.values):
if item == value:
temp = 1
if key in node_.keys[i]:
if len(node_.keys[i]) > 1:
node_.keys[i].pop(node_.keys[i].index(key))
elif node_ == self.root:
node_.values.pop(i)
node_.keys.pop(i)
else:
node_.keys[i].pop(node_.keys[i].index(key))
del node_.keys[i]
node_.values.pop(node_.values.index(value))
self.deleteEntry(node_, value, key)
else:
print("Value not in Key")
return
if temp == 0:
print("Value not in Tree")
return
def deleteEntry(self, node_, value, key):
if not node_.check_leaf:
for i, item in enumerate(node_.keys):
if item == key:
node_.keys.pop(i)
break
for i, item in enumerate(node_.values):
if item == value:
node_.values.pop(i)
break
if self.root == node_ and len(node_.keys) == 1:
self.root = node_.keys[0]
node_.keys[0].parent = None
del node_
return
elif (len(node_.keys) < int(math.ceil(node_.order / 2)) and node_.check_leaf == False) or (len(node_.values) < int(math.ceil((node_.order - 1) / 2)) and node_.check_leaf == True):
is_predecessor = 0
parentNode = node_.parent
PrevNode = -1
NextNode = -1
PrevK = -1
PostK = -1
for i, item in enumerate(parentNode.keys):
if item == node_:
if i > 0:
PrevNode = parentNode.keys[i - 1]
PrevK = parentNode.values[i - 1]
if i < len(parentNode.keys) - 1:
NextNode = parentNode.keys[i + 1]
PostK = parentNode.values[i]
if PrevNode == -1:
ndash = NextNode
value_ = PostK
elif NextNode == -1:
is_predecessor = 1
ndash = PrevNode
value_ = PrevK
else:
if len(node_.values) + len(NextNode.values) < node_.order:
ndash = NextNode
value_ = PostK
else:
is_predecessor = 1
ndash = PrevNode
value_ = PrevK
if len(node_.values) + len(ndash.values) < node_.order:
if is_predecessor == 0:
node_, ndash = ndash, node_
ndash.keys += node_.keys
if not node_.check_leaf:
ndash.values.append(value_)
else:
ndash.nextKey = node_.nextKey
ndash.values += node_.values
if not ndash.check_leaf:
for j in ndash.keys:
j.parent = ndash
self.deleteEntry(node_.parent, value_, node_)
del node_
else:
if is_predecessor == 1:
if not node_.check_leaf:
ndashpm = ndash.keys.pop(-1)
ndashkm_1 = ndash.values.pop(-1)
node_.keys = [ndashpm] + node_.keys
node_.values = [value_] + node_.values
parentNode = node_.parent
for i, item in enumerate(parentNode.values):
if item == value_:
p.values[i] = ndashkm_1
break
else:
ndashpm = ndash.keys.pop(-1)
ndashkm = ndash.values.pop(-1)
node_.keys = [ndashpm] + node_.keys
node_.values = [ndashkm] + node_.values
parentNode = node_.parent
for i, item in enumerate(p.values):
if item == value_:
parentNode.values[i] = ndashkm
break
else:
if not node_.check_leaf:
ndashp0 = ndash.keys.pop(0)
ndashk0 = ndash.values.pop(0)
node_.keys = node_.keys + [ndashp0]
node_.values = node_.values + [value_]
parentNode = node_.parent
for i, item in enumerate(parentNode.values):
if item == value_:
parentNode.values[i] = ndashk0
break
else:
ndashp0 = ndash.keys.pop(0)
ndashk0 = ndash.values.pop(0)
node_.keys = node_.keys + [ndashp0]
node_.values = node_.values + [ndashk0]
parentNode = node_.parent
for i, item in enumerate(parentNode.values):
if item == value_:
parentNode.values[i] = ndash.values[0]
break
if not ndash.check_leaf:
for j in ndash.keys:
j.parent = ndash
if not node_.check_leaf:
for j in node_.keys:
j.parent = node_
if not parentNode.check_leaf:
for j in parentNode.keys:
j.parent = parentNode
def printTree(tree):
lst = [tree.root]
level = [0]
leaf = None
flag = 0
lev_leaf = 0
node1 = Node(str(level[0]) + str(tree.root.values))
while (len(lst) != 0):
x = lst.pop(0)
lev = level.pop(0)
if (x.check_leaf == False):
for i, item in enumerate(x.keys):
print(item.values)
else:
for i, item in enumerate(x.keys):
print(item.values)
if (flag == 0):
lev_leaf = lev
leaf = x
flag = 1
record_len = 3
bplustree = BplusTree(record_len)
bplustree.insert('5', '33')
bplustree.insert('15', '21')
bplustree.insert('25', '31')
bplustree.insert('35', '41')
bplustree.insert('45', '10')
printTree(bplustree)
if(bplustree.find('5', '34')):
print("Found")
else:
print("Not found")

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 說明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
說明InnoDB全文搜索功能。
Apr 02, 2025 pm 06:09 PM
InnoDB的全文搜索功能非常强大,能够显著提高数据库查询效率和处理大量文本数据的能力。1)InnoDB通过倒排索引实现全文搜索,支持基本和高级搜索查询。2)使用MATCH和AGAINST关键字进行搜索,支持布尔模式和短语搜索。3)优化方法包括使用分词技术、定期重建索引和调整缓存大小,以提升性能和准确性。
 如何使用Alter Table語句在MySQL中更改表?
Mar 19, 2025 pm 03:51 PM
如何使用Alter Table語句在MySQL中更改表?
Mar 19, 2025 pm 03:51 PM
本文討論了使用MySQL的Alter Table語句修改表,包括添加/刪除列,重命名表/列以及更改列數據類型。
 與MySQL中使用索引相比,全表掃描何時可以更快?
Apr 09, 2025 am 12:05 AM
與MySQL中使用索引相比,全表掃描何時可以更快?
Apr 09, 2025 am 12:05 AM
全表掃描在MySQL中可能比使用索引更快,具體情況包括:1)數據量較小時;2)查詢返回大量數據時;3)索引列不具備高選擇性時;4)複雜查詢時。通過分析查詢計劃、優化索引、避免過度索引和定期維護表,可以在實際應用中做出最優選擇。
 可以在 Windows 7 上安裝 mysql 嗎
Apr 08, 2025 pm 03:21 PM
可以在 Windows 7 上安裝 mysql 嗎
Apr 08, 2025 pm 03:21 PM
是的,可以在 Windows 7 上安裝 MySQL,雖然微軟已停止支持 Windows 7,但 MySQL 仍兼容它。不過,安裝過程中需要注意以下幾點:下載適用於 Windows 的 MySQL 安裝程序。選擇合適的 MySQL 版本(社區版或企業版)。安裝過程中選擇適當的安裝目錄和字符集。設置 root 用戶密碼,並妥善保管。連接數據庫進行測試。注意 Windows 7 上的兼容性問題和安全性問題,建議升級到受支持的操作系統。
 如何為MySQL連接配置SSL/TLS加密?
Mar 18, 2025 pm 12:01 PM
如何為MySQL連接配置SSL/TLS加密?
Mar 18, 2025 pm 12:01 PM
文章討論了為MySQL配置SSL/TLS加密,包括證書生成和驗證。主要問題是使用自簽名證書的安全含義。[角色計數:159]
 InnoDB中的聚類索引和非簇索引(次級索引)之間的差異。
Apr 02, 2025 pm 06:25 PM
InnoDB中的聚類索引和非簇索引(次級索引)之間的差異。
Apr 02, 2025 pm 06:25 PM
聚集索引和非聚集索引的區別在於:1.聚集索引將數據行存儲在索引結構中,適合按主鍵查詢和範圍查詢。 2.非聚集索引存儲索引鍵值和數據行的指針,適用於非主鍵列查詢。
 哪些流行的MySQL GUI工具(例如MySQL Workbench,PhpMyAdmin)是什麼?
Mar 21, 2025 pm 06:28 PM
哪些流行的MySQL GUI工具(例如MySQL Workbench,PhpMyAdmin)是什麼?
Mar 21, 2025 pm 06:28 PM
文章討論了流行的MySQL GUI工具,例如MySQL Workbench和PhpMyAdmin,比較了它們對初學者和高級用戶的功能和適合性。[159個字符]

