
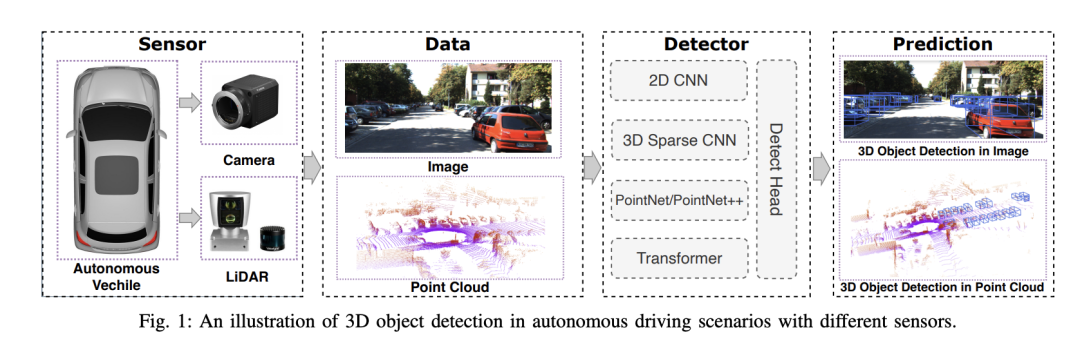
#自動駕駛系統依賴先進的感知、決策和控制技術,透過使用各種感測器(如相機、光達、雷達等)來感知周圍環境,並利用演算法和模型進行即時分析和決策。這使得車輛能夠識別道路標誌、檢測和追蹤其他車輛、預測行人行為等,從而安全地操作和適應複雜的交通環境。這項技術目前引起了廣泛的關注,並認為是未來交通領域的重要發展領域之一。但是,讓自動駕駛變得困難的是弄清楚如何讓汽車了解周圍發生的事情。這需要自動駕駛系統中的三維物體偵測演算法可以準確地感知和描述周圍環境中的物體,包括它們的位置、形狀、大小和類別。這種全面的環境意識有助於自動駕駛系統更了解駕駛環境,並做出更精確的決策。
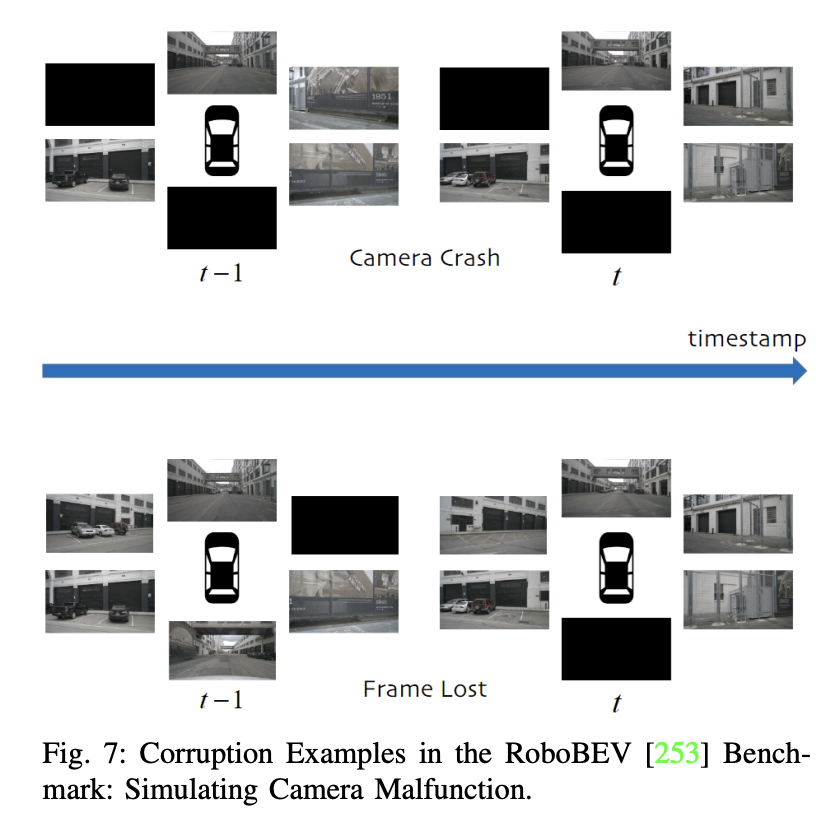
我們對自動駕駛中的3D物體偵測演算法進行了全面評估,主要考慮了穩健性。評估中確定了三個關鍵因素:環境變化性、感測器雜訊和誤對準。這些因素對於偵測演算法在真實世界多變條件下的效能表現非常重要。
也深入探討了效能評估的三個關鍵領域:準確性、延遲和穩健性。
論文指出了多模態3D檢測方法在安全感知方面的顯著優勢,透過融合不同感測器的數據,提供了更豐富、多樣化的感知能力,進而提高了自動駕駛系統的安全性。
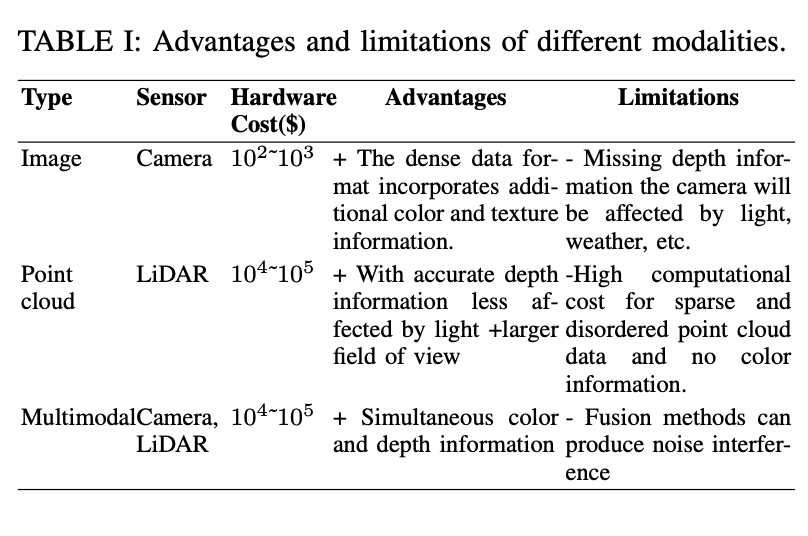
#上述簡要介紹了用於自動駕駛系統中的3D物件偵測資料集,主要關注評估不同感測器模式的優勢和局限性,以及公共資料集的特徵。
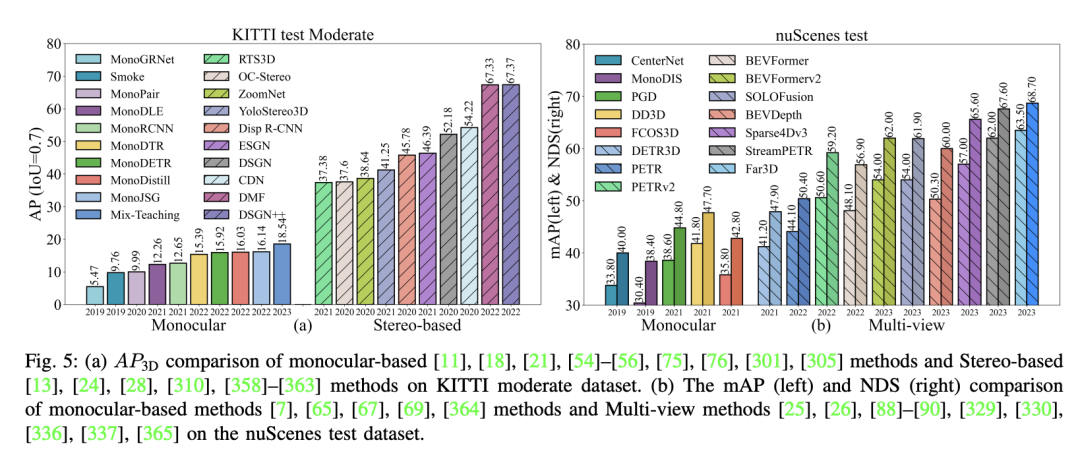
首先,表格中展示了三種類型的感測器:相機、點雲和多模態(相機和雷射雷達)。對於每種類型,列出了它們的硬體成本、優點和限制。相機數據的優點在於提供豐富的顏色和紋理訊息,但它的局限性是缺乏深度資訊且易受光線和天氣影響。光達則能提供準確的深度信息,但成本高且沒有顏色資訊。
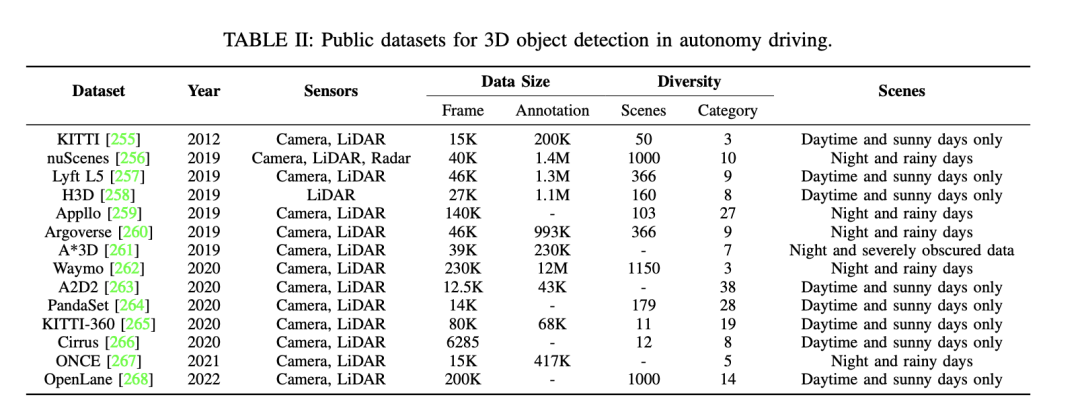
接下來,還有一些其他公共資料集可用於自動駕駛中的3D物件偵測。這些資料集包括KITTI、nuScenes和Waymo等。這些數據集的詳細資訊如下: - KITTI資料集包含了多個年份發布的數據,使用了不同類型的感測器。它提供了大量的幀數和註釋數量,以及各種場景的多樣性,包括場景數量和類別,以及不同的場景類型,如白天、晴天、夜晚和雨天等。 - nuScenes資料集也是一個重要的資料集,它同樣包含了多個年份發布的資料。該資料集使用了多種感測器,並提供了大量的幀數和註釋數量。它涵蓋了各種場景,包括不同的場景數量和類別,以及各種場景類型。 - Waymo資料集是另一個用於自動駕駛的資料集,同樣具有多個年份的資料。此資料集使用了不同類型的感測器,並提供了豐富的幀數和註釋數量。它涵蓋了各種場
此外,也提到了關於「乾淨」自動駕駛資料集的研究,並強調了在雜訊場景下評估模型穩健性的重要性。一些研究關注在惡劣條件下的相機單模態方法,而其他的多模態資料集則專注於雜訊問題。例如,GROUNDED數據集關注在不同天氣條件下地面穿透雷達的定位,而ApolloScape開放數據集包括了雷射雷達、相機和GPS數據,涵蓋了多種天氣和光照條件。
由於在真實世界中收集大規模雜訊資料的成本過高,許多研究轉向使用合成資料集。例如,ImageNet-C是在影像分類模型中對抗常見擾動的基準研究。這一研究方向隨後擴展到為自動駕駛中的3D物體檢測量身定制的穩健性資料集。
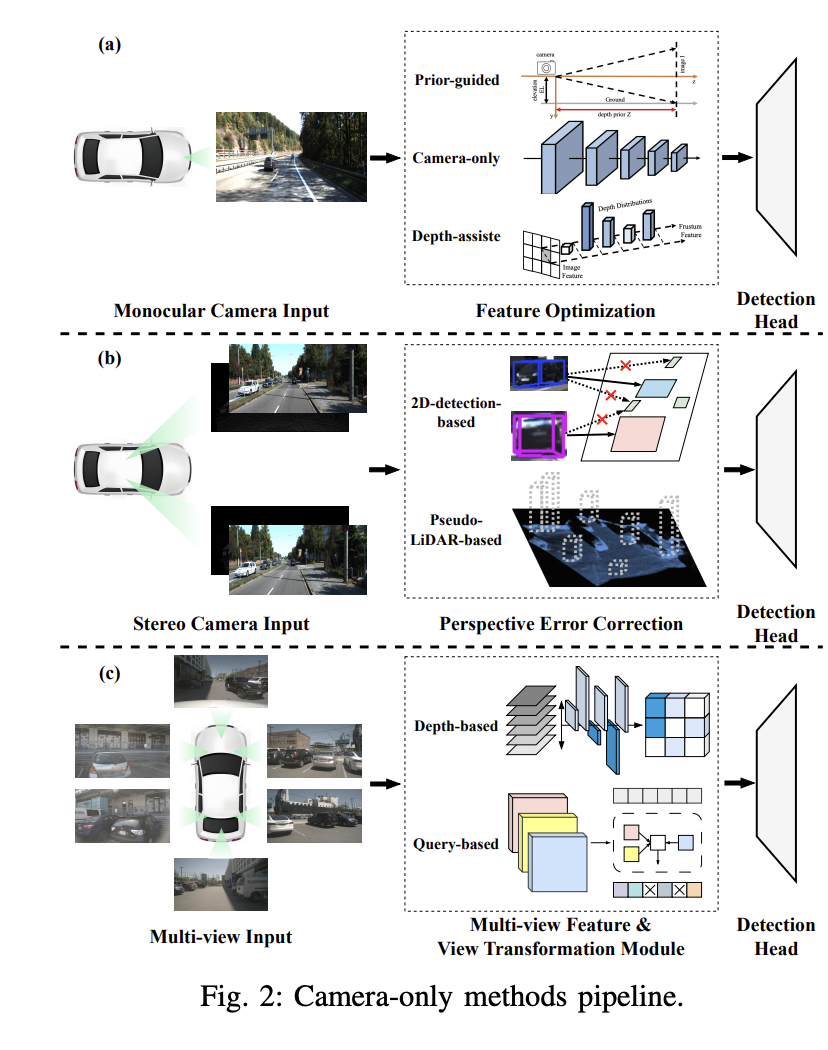
在這部分內容中,討論了單目3D物體檢測的概念以及三種主要的方法:基於先驗的單目3D物體檢測、僅相機的單目3D物體檢測和深度輔助的單目3D物體檢測。
這種方法利用隱藏在影像中的物體形狀和場景幾何學的先驗知識來解決單目3D物體檢測的挑戰。透過引入預先訓練的子網路或輔助任務,先驗知識可以提供額外資訊或限制來幫助精確定位3D物體,增強偵測的精確度和穩健性。常見的先驗知識包括物體形狀、幾何一致性、時間約束和分割資訊。例如,Mono3D演算法首先假設3D物體位於固定的地面平面上,然後使用物體的先驗3D形狀來在3D空間中重建邊界框。

這種方法僅使用單一相機捕獲的影像來偵測和定位3D物體。它採用卷積神經網路(CNN)直接從影像中回歸3D邊界框參數,從而估計物體在三維空間中的尺寸和姿態。這種直接迴歸方法可以以端到端的方式進行訓練,促進了3D物體的整體學習和推論。例如,Smoke演算法摒棄了2D邊界框的迴歸,透過結合單一關鍵點的估計值和3D變數的迴歸來預測每個偵測目標的3D框。
深度估計在深度輔助的單目3D物件偵測中扮演關鍵角色。為了實現更準確的單目檢測結果,許多研究利用預先訓練的輔助深度估計網路。這個過程首先透過使用預先訓練的深度估計器(如MonoDepth)將單眼影像轉換為深度影像。然後,採用兩種主要方法來處理深度影像和單眼影像。例如,Pseudo-LiDAR偵測器使用預先訓練的深度估計網路產生Pseudo-LiDAR表示,但由於影像到LiDAR產生的錯誤,Pseudo-LiDAR與基於LiDAR的偵測器之間存在著巨大的效能差距。
透過這些方法的探索和應用,單目3D物件偵測在電腦視覺和智慧型系統領域取得了顯著進展,為這些領域帶來了突破和機會。
在這部分內容中,討論了基於立體視覺的3D物件偵測技術。立體視覺3D物件偵測利用一對立體影像來辨識和定位3D物體。透過利用立體攝影機捕獲的雙重視角,這些方法在透過立體匹配和校準獲取高精度深度資訊方面表現出色,這是它們與單眼攝影機設定不同的特點。儘管存在這些優勢,與基於雷射雷達的方法相比,立體視覺方法仍存在相當大的性能差距。此外,從立體影像中進行3D物件偵測的領域相對較少被探索,僅有限的研究工作致力於這一領域。
最近,多視圖3D物件偵測在精確度和穩健性方面相較於前述的單目和立體視覺3D物體偵測方法表現出了優越性。與基於雷射雷達的3D物體偵測不同,最新的全景鳥瞰視圖(BEV)方法消除了對高精度地圖的需求,將偵測從2D提升到3D。這項進展帶來了多視角3D物體偵測的重大發展。在多相機3D物件偵測中,關鍵挑戰在於識別不同影像中的相同物體並從多重視角輸入中聚合物體特徵。目前的方法涉及將多視角統一映射到鳥瞰視圖(BEV)空間,這是一種常見的做法。
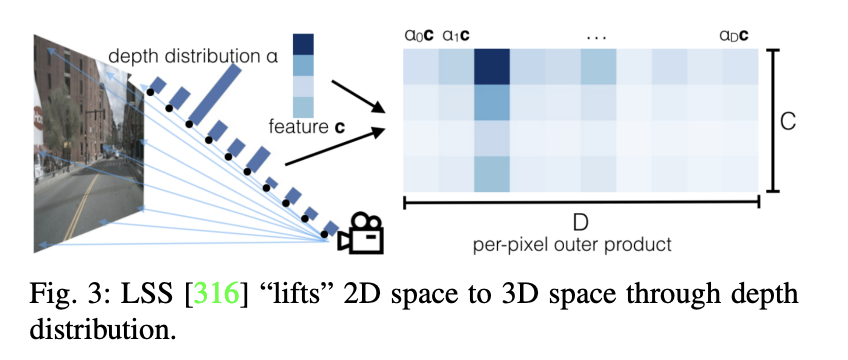
#從2D到BEV空間的直接轉換構成了一個重大挑戰。 LSS是第一個提出基於深度的方法的,它利用3D空間作為中介。這種方法首先預測2D特徵的網格深度分佈,然後將這些特徵提升到體素空間。這種方法為更有效地實現從2D到BEV空間的轉換提供了希望。繼LSS之後,CaDDN採用了類似的深度表示方法。透過將體素空間特徵壓縮到BEV空間,它執行最終的3D檢測。值得注意的是,CaDDN並不是多視角3D物體偵測的一部分,而是單視角3D物體偵測,它對隨後的深度研究產生了影響。 LSS和CaDDN的主要區別在於CaDDN使用實際的地面真實深度值來監督其分類深度分佈的預測,從而創建了一個能夠更準確地從2D空間提取3D資訊的出色深度網路。
在Transformer技術的影響下,基於query的多視角方法從3D空間檢索2D空間特徵。 DETR3D引入了3D物體query來解決多視角特徵的聚合問題。它透過從不同視角剪輯影像特徵,並使用學習到的3D參考點將它們投影到2D空間,從而在鳥瞰視圖(BEV)空間獲得影像特徵。與基於深度的多視角方法不同,基於query的多視角方法透過使用反向query技術來獲得稀疏BEV特徵,從根本上影響了後續基於query的發展。然而,由於與顯式3D參考點相關的潛在不準確性,PETR採用了隱式位置編碼方法來建構BEV空間,影響了後續的工作。
目前,基於鳥瞰視圖(BEV)感知的3D物體偵測解決方案正在迅速發展。儘管存在許多綜述文章,但對這一領域的全面回顧仍然不足。上海AI實驗室和商湯研究院提供了BEV解決方案技術路線圖的深入回顧。然而,與現有的綜述不同,我們考慮了自動駕駛安全感知等關鍵面向。在分析了基於相機解決方案的技術路線圖和當前發展狀態之後,我們打算基於`準確性、延遲、穩健性'的基本原則進行討論。我們將整合安全感知的視角,以指導自動駕駛中安全感知的實際實施。
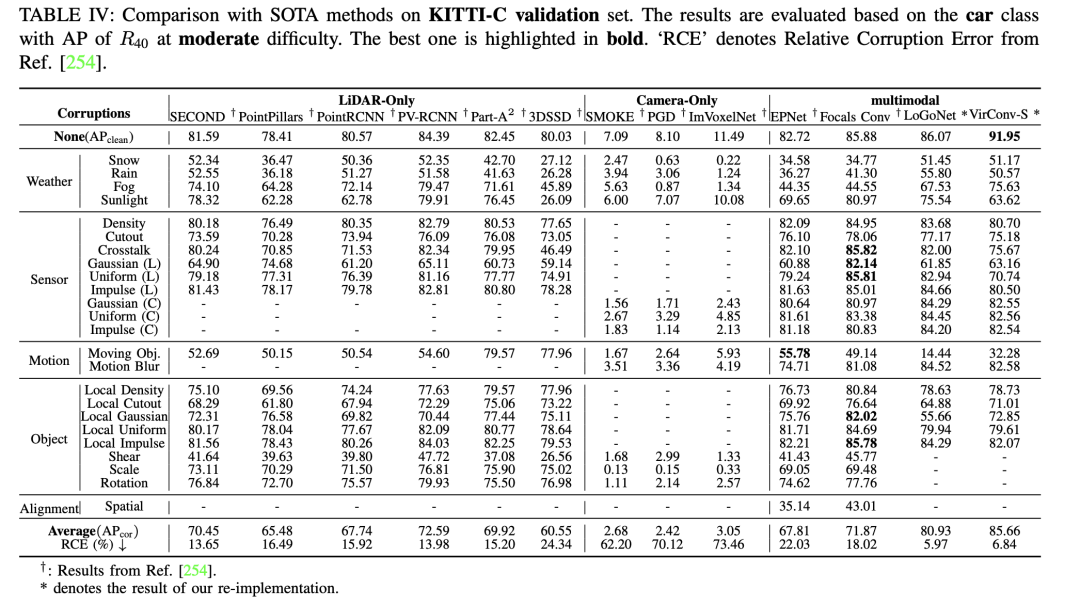
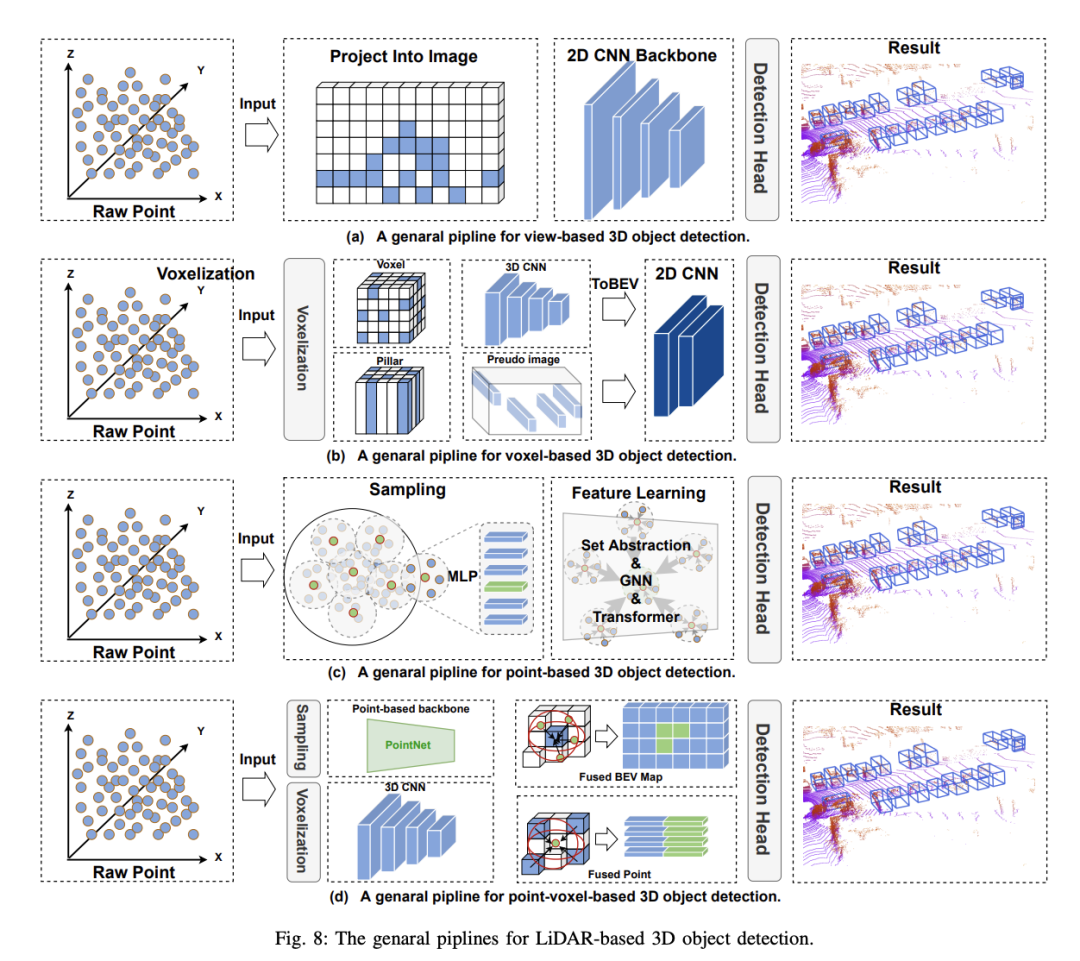
基于体素的3D物体检测方法提出了将稀疏点云分割并分配到规则体素中,从而形成密集的数据表示,这个过程称为体素化。与基于视图的方法相比,基于体素的方法利用空间卷积有效感知3D空间信息,实现更高的检测精度,这对自动驾驶中的安全感知至关重要。然而,这些方法仍面临以下挑战:
為了克服這些挑戰,需要解決資料表示的限制、提高網路特徵能力和目標定位精度,並加強演算法對複雜場景的理解。儘管最佳化策略各不相同,但通常都旨在從資料表示和模型結構方面進行最佳化。
得益於PC在深度學習中的繁榮,基於點的三維物件偵測繼承了其許多框架,並提出在不進行預處理的情況下直接從原始點偵測三維物件。與voxel-based方法相比,原始點雲保留了最大量的原始信息,這有利於細粒度的特徵獲取,result high accuracy。同時,PointNet的一系列工作自然為基於點的方法提供了強大的基礎。基於點的3D物件偵測器有兩個基本組成部分:點雲採樣和特徵學習%截至目前,Point-based方法的性能仍被兩個因素所影響:上下文點的數量和特徵學習中採用的上下文半徑。 e.g.增加上下文點的數量可以獲得更細緻的3D信息,但會顯著增加模型的推理時間。類似地,縮小上下文半徑可以獲得相同地效果。因此,為這兩個因素選擇合適的值,可以使模型在精確度和速度之間達到一個平衡。此外,由於需要對點雲中每一個點進行運算,因此點雲採樣過程是限制point-based方法即時運行的主要因素。具體來說,為解決上述問題,現有的方法大多圍繞基於點的3D物件偵測器的兩個基本組成部分進行最佳化:1) Point Sampling 2) feature learning
#基於點的3D物體偵測方法繼承了許多深度學習框架,並提出直接從原始點雲中偵測3D物體,而不進行預處理。與基於體素的方法相比,原始點雲最大限度地保留了原始訊息,有利於細粒度特徵的獲取,從而實現高精度。同時,PointNet系列工作為基於點的方法提供了強大的基礎。然而,到目前為止,基於點的方法的性能仍受兩個因素的影響:上下文點的數量和特徵學習中使用的上下文半徑。例如,增加上下文點的數量可以獲得更細緻的3D訊息,但會顯著增加模型的推理時間。類似地,縮小上下文半徑可以達到相同的效果。因此,為這兩個因素選擇適當的值可以使模型在精度和速度之間實現平衡。此外,由於需要對點雲中的每個點進行運算,因此點雲採樣過程是限制基於點方法即時運行的主要因素。為解決這些問題,現有方法主要圍繞基於點的3D物體偵測器的兩個基本組成部分進行最佳化:1) 點雲採樣;2) 特徵學習。
最遠點採樣(FPS)源自PointNet ,是一種在基於點的方法中廣泛使用的點雲採樣方法。它的目標是從原始點雲中選擇一組具有代表性的點,使它們之間的距離最大化,以最好地覆蓋整個點雲的空間分佈。 PointRCNN是基於點的方法中的開創性的兩階段檢測器,使用PointNet 作為骨幹網路。在第一階段,它以自下而上的方式從點雲中產生3D提議。在第二階段,透過結合語意特徵和局部空間特徵來精煉提議。然而,現有基於FPS的方法仍面臨一些問題:1) 與檢測無關的點同樣參與採樣過程,帶來額外的計算負擔;2) 點在物體的不同部分分佈不均勻,導致次優的採樣策略。為了解決這些問題,後續工作採用了類似FPS的設計範式,並進行了改進,例如,透過分割引導的背景點過濾、隨機採樣、特徵空間採樣、基於體素的採樣和基於光線分組的採樣。
基於點的3D物件偵測方法的特徵學習階段旨在從稀疏點雲資料中提取具有判別性的特徵表示。在特徵學習階段使用的神經網路應具備以下特性:1) 不變性,點雲骨幹網路應對輸入點雲的排列順序不敏感;2) 具有局部感知能力,能夠對局部區域進行感知和建模,提取局部特徵;3) 具有整合情境資訊的能力,能夠從全局和局部的上下文資訊中提取特徵。基於上述特性,大量的偵測器被設計用於處理原始點雲。大多數方法可以根據所使用的核心算子分為:1) 基於PointNet的方法;2) 基於圖神經網路的方法;3) 基於Transformer的方法。
基於PointNet的方法主要依賴集合抽象來對原始點進行降採樣,聚合局部信息,並整合上下文信息,同時保持原始點的對稱不變性。 Point-RCNN是基於點的方法中的第一個兩階段工作,取得了出色的性能,但仍面臨高計算成本的問題。後續工作透過在偵測過程中引入額外的語意分割任務來過濾掉對偵測貢獻最小的背景點,解決了這個問題。
圖神經網路(GNN)具有自適應結構、動態鄰域、構建局部和全局上下文關係的能力以及對不規則採樣的穩健性。 Point-GNN是一項開創性的工作,設計了一個單階段圖神經網絡,透過自動註冊機制、合併和評分操作來預測對象的類別和形狀,展示了使用圖神經網絡作為3D物體檢測新方法的潛力。
近年來,Transformer(Transformer)在點雲分析中得到了探索,並在許多任務上表現出色。例如,Pointformer引入了局部和全局注意模組來處理3D點雲,局部Transformer模組用於對局部區域中的點之間的交互進行建模,而全局Transformer旨在學習場景級別的上下文感知表示。 Group-free直接利用點雲中的所有點來計算每個物件候選的特徵,其中每個點的貢獻由自動學習的注意模組決定。這些方法展示了基於Transformer的方法在處理非結構化和無序的原始點雲方面的潛力。
點雲基礎的3D物件偵測方法提供高解析度並保留了原始資料的空間結構,但它們在處理稀疏資料時面臨高計算複雜性和低效率。相較之下,基於體素的方法提供了結構化的數據表示,提高了計算效率,並促進了傳統卷積神經網路技術的應用。然而,由於離散化過程,它們通常會失去細微的空間細節。為了解決這些問題,開發了點-體素(PV)基礎的方法。點-體素方法旨在利用基於點的方法的細粒度資訊捕獲能力和基於體素的方法的計算效率。透過整合這些方法,點-體素基礎的方法能夠更詳細地處理點雲數據,捕捉全局結構和微觀幾何細節。這對於自動駕駛中的安全感知至關重要,因為自動駕駛系統的決策精確度取決於高精確度的偵測結果。
點-體素方法的關鍵目標是透過點到體素或體素到點的轉換,實現體素和點之間的特徵互動。許多工作已經探索了在骨幹網路中利用點-體素特徵融合的想法。這些方法可分為兩類:1) 早期融合;2) 後期融合。
a) 早期融合:有些方法已經探討了使用新的捲積運算子來融合體素和點特徵,PVCNN可能是這方向的首個工作。在這種方法中,基於體素的分支首先將點轉換為低解析度的體素網格,並透過卷積聚合鄰近體素特徵。然後,透過稱為去體素化的過程,將體素級特徵轉換回點級特徵,並與基於點的分支獲得的特徵融合。基於點的分支為每個單獨的點提取特徵。由於它不聚合鄰近信息,該方法可以以更高的速度運行。接著,SPVCNN在PVCNN的基礎上擴展到物體偵測領域。其他方法則試圖從不同的角度進行改進,如輔助任務或多尺度特徵融合。
b) 後期融合:這一系列方法主要採用兩階段偵測框架。首先,使用基於體素的方法產生初步的物體提議。接著,利用點級特徵對偵測框進行精確劃分。 Shi等人提出的PV-RCNN是點-體素基礎方法中的一個里程碑。它使用SECOND作為第一階段檢測器,並提出了具有RoI網格池的第二階段精煉階段,用於關鍵點特徵的融合。後續工作主要遵循上述範式,並專注於第二階段檢測的進展。值得注意的發展包括注意力機制、尺度感知池化和點密度感知精煉模組。
點-體素基礎的方法同時具有基於體素方法的計算效率和基於點方法捕獲細粒度資訊的能力。然而,構建點到體素或體素到點的關係,以及體素和點的特徵融合,會帶來額外的計算開銷。因此,與基於體素的方法相比,點-體素基礎
的方法可以實現更好的檢測精度,但代價是增加了推理時間。
基於投影的3D物件偵測方法在特徵融合階段使用投影矩陣來實現點雲和影像特徵的整合。這裡的關鍵是關注在特徵融合期間的投影,而不是融合階段的其他投影過程,如資料增強等。根據融合階段所使用的不同類型的投影,可以將投影基礎的3D物件偵測方法進一步細分為以下幾類:
這些方法展示瞭如何在多模態3D物體檢測中使用投影技術來實現特徵融合,但它們在處理不同模態間的交互和準確性方面仍存在一定的局限性。
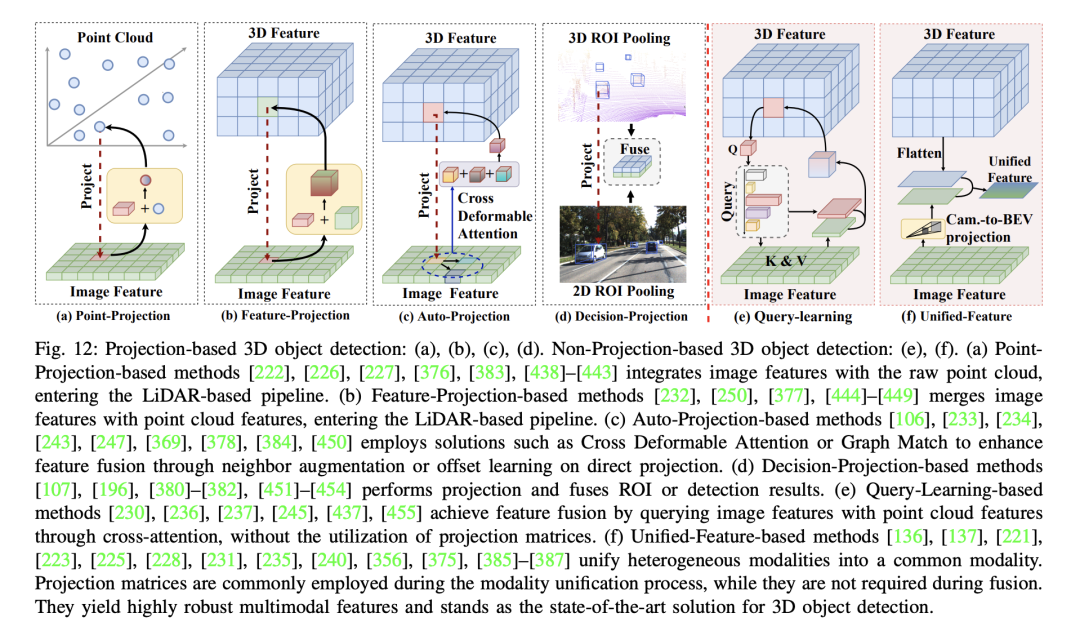
VirConv、MSMDFusion和SFD透過偽點雲建構統一空間,在特徵學習之前發生投影。透過後續特徵學習解決了直接投影引入的問題。總之,基於統一特徵的三維物體偵測方法目前代表了高精度和強魯棒性的解決方案。儘管它們包含投影矩陣,但這種投影不發生在多模態融合之間,因此被視為非投影式三維物體偵測方法。與自動投影式三維物體偵測方法不同,它們不會直接解決投影誤差問題,而是選擇建構統一空間,考慮多模態三維物體偵測的多個維度,從而獲得高度穩健的多模態特徵。
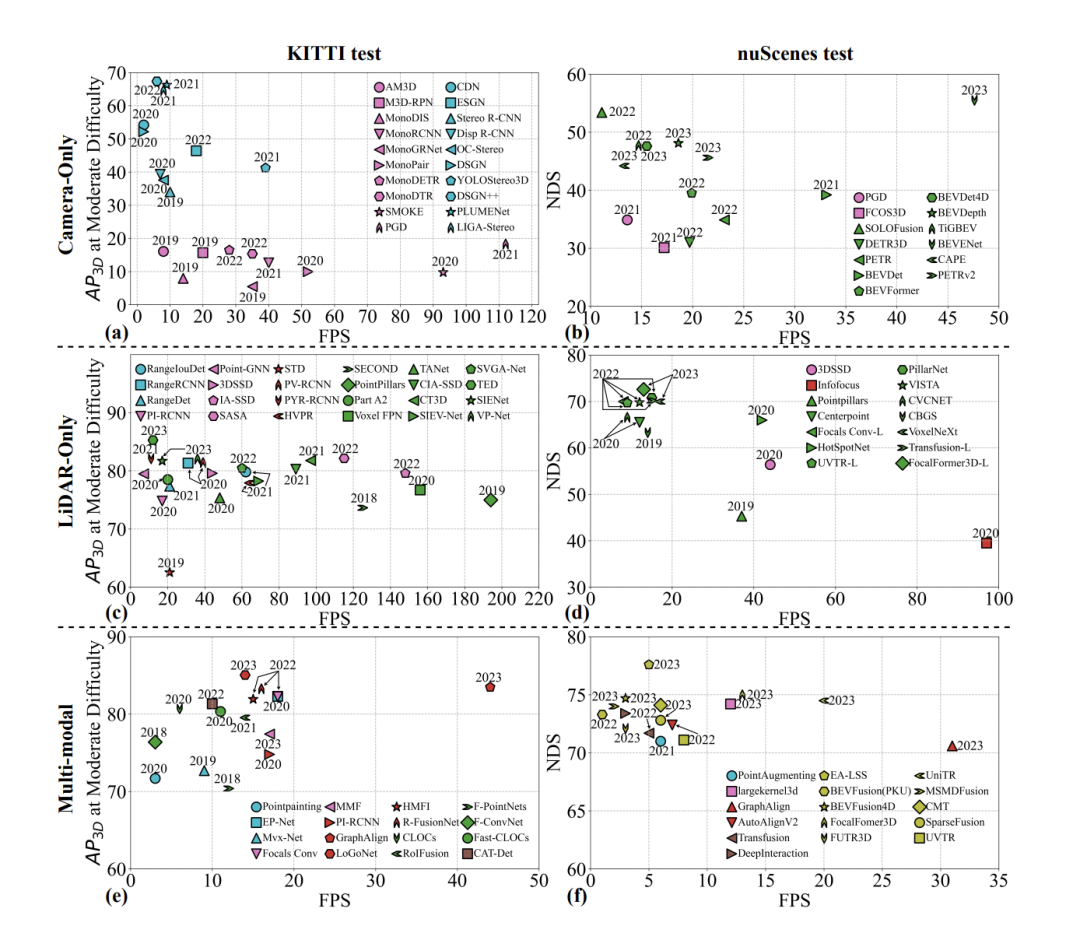
3D物件偵測在自動駕駛感知中扮演著至關重要的角色。近年來,這個領域快速發展,產生了大量的研究論文。基於感測器產生的多樣化資料形式,這些方法主要分為三種類型:基於影像的、基於點雲的和多模態的。這些方法的主要評估指標是高準確性和低延遲。許多綜述總結了這些方法,主要關注`高準確性和低延遲'的核心原則,描述它們的技術軌跡。
然而,在自動駕駛技術從突破轉向實際應用的過程中,現有的綜述沒有將安全感知作為核心關注點,未能涵蓋與安全感知相關的當前技術路徑。例如,最近的多模態融合方法在實驗階段通常會進行穩健性測試,這一方面在目前的綜述中並未得到充分考慮。
因此,重新審視3D物體偵測演算法,以`準確性、延遲和魯棒性'為關鍵面向進行重點關注。我們重新分類先前的綜述,特別強調從安全感知的角度進行重新劃分。希望這項工作能為未來3D物體檢測的研究提供新的見解,超越僅僅探索高準確性的限制。

以上是選擇相機還是光達?實現穩健的三維目標檢測的最新綜述的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















