

回顧NeurIPS 2023: 清華ToT推動大型模型成為焦點

近日,作為美國前十名的科技博客,Latent Space對於剛剛過去的NeurIPS 2023大會進行了精選回顧總結。
在NeurIPS會議中,共有3586篇論文被接受,其中6篇獲獎。雖然這些獲獎論文備受關注,但其他論文同樣具備出色的品質和潛力。實際上,這些論文甚至可能預示著AI領域的下一個重大突破。
那就讓我們來一起看看吧!

論文主題:QLoRA: Efficient Finetuning of Quantized LLMs

##論文地址:https://openreview.net/pdf?id=OUIFPHEgJU
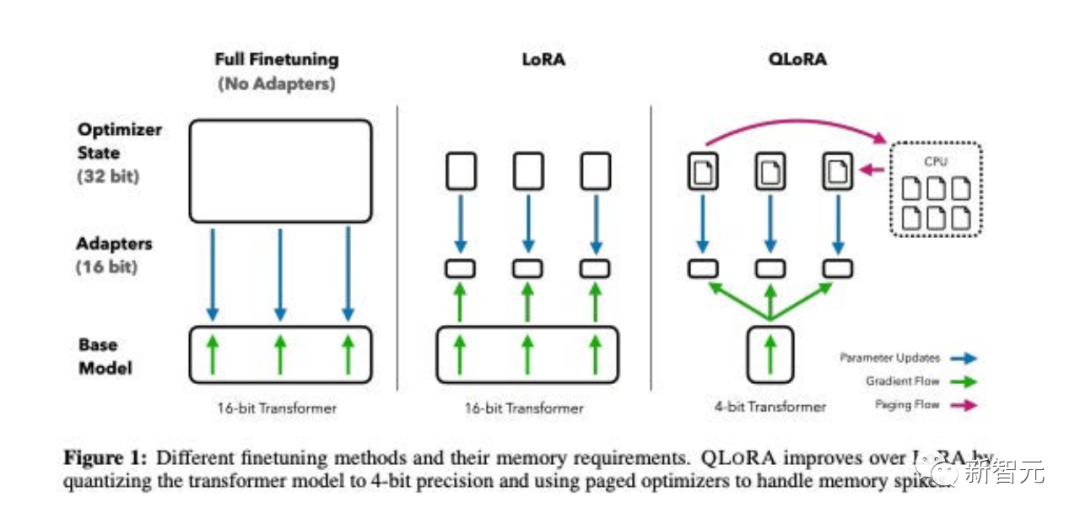
整體而言,QLoRA使得在對大型語言模型進行微調時可以使用更少的GPU記憶體。
他們對一個新模型進行了微調,命名為Guanaco,僅用一個GPU進行了為期24小時的訓練,結果在Vicuna基準測試中表現優於之前的模型。
同時,研究人員也發展了其他方法,如4-bit LoRA量化,其效果相似。
論文題目:DataComp: In search of the next generation of multimodal datasets
#論文網址:https://openreview.net/pdf?id=dVaWCDMBof
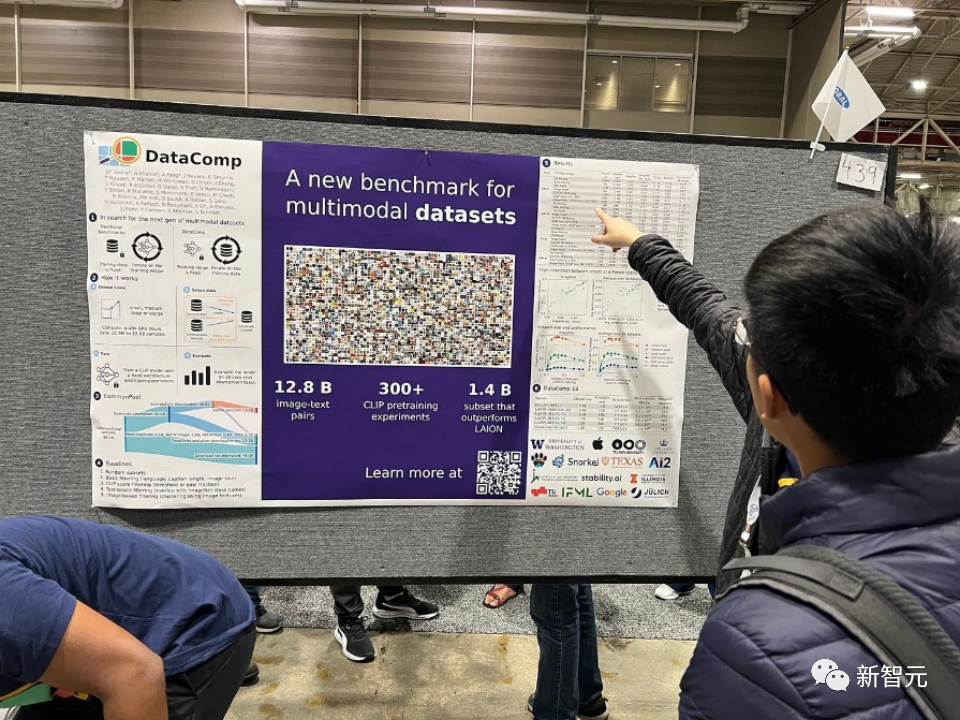
為了解決這個機器學習生態系統中的不足,研究人員引入了DataComp,這是一個圍繞Common Crawl的新候選池中的128億個圖文對進行數據集實驗的測試平台。
 使用者可以透過DataComp進行實驗,設計新的過濾技術或精心策劃新的資料來源,並透過執行標準化的CLIP訓練程式碼,以及在38個下游測試集上測試產生的模型,來評估他們的新資料集。
使用者可以透過DataComp進行實驗,設計新的過濾技術或精心策劃新的資料來源,並透過執行標準化的CLIP訓練程式碼,以及在38個下游測試集上測試產生的模型,來評估他們的新資料集。
結果顯示,最佳基準DataComp-1B,允許從頭開始訓練一個CLIP ViT-L/14模型,其在ImageNet上的零樣本準確度達到了79.2%,比OpenAI的CLIP ViT-L/14模型高出3.7個百分點,證明DataComp工作流程可以產生更好的訓練集。
論文題目:Visual Instruction Tuning
##### ####論文地址:#########https://www.php.cn/link/c0db7643410e1a667d5e01868827a9af################在這篇論文中,研究人員提出了首次嘗試使用僅依賴語言的GPT-4來產生多模態語言-影像指令跟隨資料的方法。 ############透過在這個產生的資料上進行指令調整,引入了LLaVA:Large Language and Vision Assistant,這是一個端到端訓練的大型多模態模型,連接了一個視覺編碼器和LLM,用於通用的視覺和語言理解。 ######
早期實驗證明LLaVA展示了令人印象深刻的多模態聊天能力,有時展現出多模態GPT-4在未見過的圖像/指令上的行為,並在合成的多模態指令跟隨資料集上與GPT-4相比取得了85.1%的相對分數。
在對科學問答進行微調時,LLaVA和GPT-4的協同作用實現了92.53%的新的最先進準確性。

論文主題:Tree of Thoughts: Deliberate Problem Solving with Large Language Models

#論文網址:https://arxiv.org/pdf/2305.10601.pdf
語言模式越來越多用於廣泛的任務進行一般性問題解決,但在推理過程中仍受限於標記層級、從左到右的決策過程。這意味著它們在需要探索、策略前瞻或初始決策中起關鍵作用的任務中可能表現不佳。
為了克服這些挑戰,研究人員引入了一種新的語言模型推理框架,Tree of Thoughts(ToT),它在促使語言模型方面推廣了流行的Chain of Thought方法,並允許在一致的文本單元(思想)上進行探索,這些單元作為解決問題的中間步驟。
ToT使語言模型能夠透過考慮多個不同的推理路徑和自我評估選擇來做出刻意的決策,以決定下一步行動,並在必要時展望或回溯以做出全局性的選擇。
實驗證明,ToT顯著提高了語言模型在需要非平凡規劃或搜尋的三個新任務上的問題解決能力:24點遊戲、創意寫作和迷你填字遊戲。例如,在24點遊戲中,雖然使用Chain of Thought提示的GPT-4只解決了4%的任務,但ToT實現了74%的成功率。
論文主題:Toolformer: Language Models Can Teach Themselves to Use Tools

#論文網址:https://arxiv.org/pdf/2302.04761.pdf
語言模式表現出在從少量範例或文字指令中解決新任務方面的顯著能力,尤其是在大規模情境下。然而,令人矛盾的是,它們在基本功能方面(如算術或事實查找),相較於更簡單且規模較小的專門模型,卻表現出困難。
在這篇論文中,研究人員展示了語言模型可以透過簡單的API自學使用外部工具,並實現兩者的最佳結合。
他們引入了Toolformer,他們經過訓練能夠決定要呼叫哪些API、何時呼叫它們、傳遞什麼參數以及如何最佳地將結果合併到未來的token預測中。
這是以自監督的方式完成的,每個API只需要少量演示。他們整合了各種工具,包括計算器、問答系統、搜尋引擎、翻譯系統和日曆等。
Toolformer在與更大模型競爭的時候,在各種下游任務中取得了明顯改善的零樣本效能,而不會犧牲其核心語言建模能力。
論文主題:Voyager: An Open-Ended Embodied Agent with Large Language Models

論文地址:https://arxiv.org/pdf/2305.16291.pdf
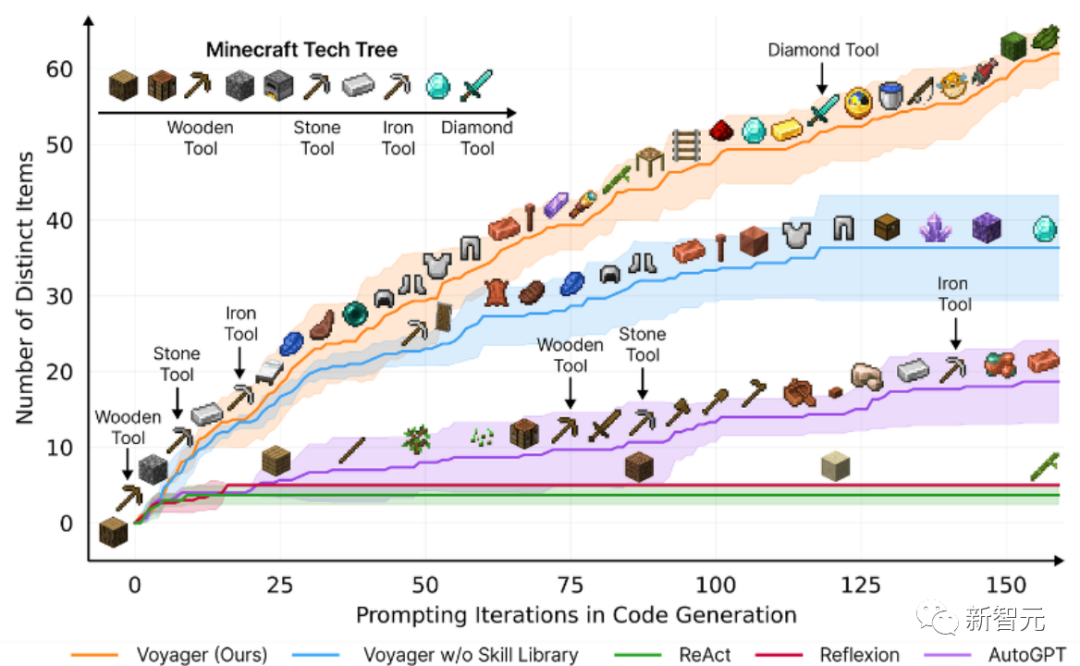
論文介紹了Voyager,這是第一個由大型語言模型(LLM)驅動的,可以在Minecraft中連續探索世界、獲得多樣化技能並進行獨立發現的learning agent。
Voyager包含三個關鍵組成部分:
#自動課程,旨在最大程度地推動探索,
#Растущая библиотека навыков исполняемого кода для хранения и извлечения сложного поведения,
#Новый итеративный механизм подсказок, который объединяет обратную связь от окружающей среды, ошибки выполнения и самопроверку для улучшения процедур .
Voyager взаимодействует с GPT-4 посредством запросов «черного ящика», что позволяет избежать необходимости точной настройки параметров модели.
Основываясь на эмпирических исследованиях, Voyager демонстрирует сильные способности к обучению на протяжении всей жизни в контексте окружающей среды и демонстрирует превосходное мастерство в игре в Minecraft.
Он получает доступ к уникальным предметам, которые в 3,3 раза выше, чем на предыдущем технологическом уровне, путешествует в 2,3 раза дольше и открывает ключевые этапы дерева технологий в 15,3 раза быстрее, чем на предыдущем технологическом уровне.
Но хотя «Вояджер» может использовать приобретенный набор навыков для решения новых задач с нуля в новых мирах Minecraft, другие методы сложнее обобщить.
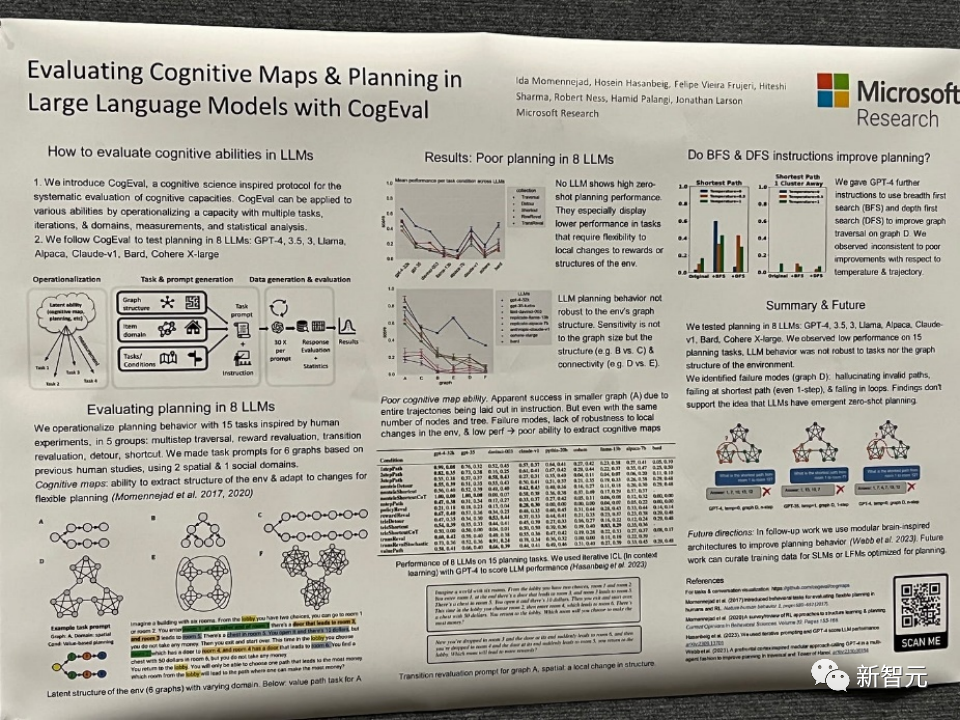
##Название диссертации: Оценка когнитивных карт и планирование в больших языковых моделях с помощью CogEval

Эта статья была первой предложил CogEval — протокол, вдохновленный когнитивной наукой, для систематической оценки когнитивных способностей больших языковых моделей.
Во-вторых, в статье используется система CogEval для оценки восьми LLM (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge - 52.4B, Anthropic Claude-1-52B, LLaMA-13B и Alpaca-7B) возможности когнитивного картирования и планирования. Подсказки к задачам основаны на экспериментах на людях и не присутствуют в обучающем наборе LLM.
Исследования показали, что, хотя LLM демонстрируют очевидные возможности в некоторых задачах планирования с более простой структурой, как только задачи становятся сложными, LLM попадают в «слепые зоны», включая обнаружение неверных траекторий. и застрял в петле.
Эти результаты не подтверждают идею о том, что LLM имеют возможности планирования по принципу «включай и работай». Возможно, что LLM не понимают основную реляционную структуру, лежащую в основе проблемы планирования, то есть когнитивную карту, и имеют проблемы с развертыванием целенаправленных траекторий на основе базовой структуры.
 Адрес статьи: https://openreview.net/pdf?id=AL1fq05o7H
Адрес статьи: https://openreview.net/pdf?id=AL1fq05o7H
Автор указал что в настоящее время многие архитектуры сублинейного времени, такие как линейное внимание, вентилируемая свертка и рекуррентные модели, а также модели структурированного пространства состояний (SSM), направлены на решение вычислительной неэффективности Transformer при обработке длинных последовательностей. Однако эти модели не работают так же хорошо, как модели внимания, в таких важных областях, как язык. Авторы полагают, что ключевой слабостью этих
типов является их неспособность выполнять содержательные рассуждения и вносить некоторые улучшения.
Во-первых, простое превращение параметров SSM в функцию входных данных может устранить недостатки его дискретной модальности, позволяя модели выборочно распространять или забывать информацию по измерению длины последовательности в зависимости от текущий токен.
Во-вторых, хотя это изменение не позволяет использовать эффективные свертки, авторы разработали аппаратно-ориентированный параллельный алгоритм в циклическом режиме. Интеграция этих выборочных SSM в упрощенную сквозную архитектуру нейронной сети не требует никакого механизма внимания или даже модуля MLP (Mamba).
Mamba хорошо работает по скорости вывода (в 5 раз быстрее, чем Transformers) и линейно масштабируется в зависимости от длины последовательности, улучшая производительность при работе с реальными данными, длина которых достигает миллионов миллионов.
Являясь основой универсальной модели последовательностей, Mamba достигла самых современных показателей во многих областях, включая язык, аудио и геномику. С точки зрения языкового моделирования модель Mamba-1.4B превосходит модель Transformers того же размера как при предварительном обучении, так и при последующей оценке, а также конкурирует со своей моделью Transformers, вдвое большей по размеру.

Хотя эти статьи не получили наград в 2023 году, такие как Мамба, как техническая модель, которая может произвести революцию в архитектуре языковой модели, еще слишком рано оценивать ее влияние.
Как будет развиваться NeurIPS в следующем году, и как будет развиваться сфера искусственного интеллекта и нейроинформационных систем в 2024 году?Хотя сейчас существуют разные мнения, кто может это гарантировать? давайте подождем и посмотрим.
以上是回顧NeurIPS 2023: 清華ToT推動大型模型成為焦點的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 使用ddrescue在Linux上恢復數據
Mar 20, 2024 pm 01:37 PM
使用ddrescue在Linux上恢復數據
Mar 20, 2024 pm 01:37 PM
DDREASE是一種用於從檔案或區塊裝置(如硬碟、SSD、RAM磁碟、CD、DVD和USB儲存裝置)復原資料的工具。它將資料從一個區塊設備複製到另一個區塊設備,留下損壞的資料區塊,只移動好的資料區塊。 ddreasue是一種強大的恢復工具,完全自動化,因為它在恢復操作期間不需要任何干擾。此外,由於有了ddasue地圖文件,它可以隨時停止和恢復。 DDREASE的其他主要功能如下:它不會覆寫恢復的數據,但會在迭代恢復的情況下填補空白。但是,如果指示工具明確執行此操作,則可以將其截斷。將資料從多個檔案或區塊還原到單
 Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
Google狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理訓練最快選擇
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基準測試中表現已經超過Pytorch和TensorFlow,7項指標排名第一。而且測試並不是JAX性能表現最好的TPU上完成的。雖然現在在開發者中,Pytorch依然比Tensorflow更受歡迎。但未來,也許有更多的大型模型會基於JAX平台進行訓練和運行。模型最近,Keras團隊為三個後端(TensorFlow、JAX、PyTorch)與原生PyTorch實作以及搭配TensorFlow的Keras2進行了基準測試。首先,他們為生成式和非生成式人工智慧任務選擇了一組主流
 你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
波士頓動力Atlas,正式進入電動機器人時代!昨天,液壓Atlas剛「含淚」退出歷史舞台,今天波士頓動力就宣布:電動Atlas上崗。看來,在商用人形機器人領域,波士頓動力是下定決心要跟特斯拉硬剛一把了。新影片放出後,短短十幾小時內,就已經有一百多萬觀看。舊人離去,新角色登場,這是歷史的必然。毫無疑問,今年是人形機器人的爆發年。網友銳評:機器人的進步,讓今年看起來像人類的開幕式動作、自由度遠超人類,但這真不是恐怖片?影片一開始,Atlas平靜地躺在地上,看起來應該是仰面朝天。接下來,讓人驚掉下巴
 iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
在iPhone上面臨滯後,緩慢的行動數據連線?通常,手機上蜂窩互聯網的強度取決於幾個因素,例如區域、蜂窩網絡類型、漫遊類型等。您可以採取一些措施來獲得更快、更可靠的蜂窩網路連線。修復1–強制重啟iPhone有時,強制重啟設備只會重置許多內容,包括蜂窩網路連線。步驟1–只需按一次音量調高鍵並放開即可。接下來,按降低音量鍵並再次釋放它。步驟2–過程的下一部分是按住右側的按鈕。讓iPhone完成重啟。啟用蜂窩數據並檢查網路速度。再次檢查修復2–更改資料模式雖然5G提供了更好的網路速度,但在訊號較弱
 特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人Optimus最新影片出爐,已經可以在工廠裡打工了。正常速度下,它分揀電池(特斯拉的4680電池)是這樣的:官方還放出了20倍速下的樣子——在小小的「工位」上,揀啊揀啊揀:這次放出的影片亮點之一在於Optimus在廠子裡完成這項工作,是完全自主的,全程沒有人為的干預。而且在Optimus的視角之下,它還可以把放歪了的電池重新撿起來放置,主打一個自動糾錯:對於Optimus的手,英偉達科學家JimFan給出了高度的評價:Optimus的手是全球五指機器人裡最靈巧的之一。它的手不僅有觸覺
 快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可靈」開放測試:生成超120s視頻,更懂物理,複雜運動也能精準建模
Jun 11, 2024 am 09:51 AM
什麼?瘋狂動物城被國產AI搬進現實了?與影片一同曝光的,是一款名為「可靈」全新國產影片生成大模型。 Sora利用了相似的技術路線,結合多項自研技術創新,生產的影片不僅運動幅度大且合理,還能模擬物理世界特性,具備強大的概念組合能力與想像。數據上看,可靈支持生成長達2分鐘的30fps的超長視頻,分辨率高達1080p,且支援多種寬高比。另外再劃個重點,可靈不是實驗室放出的Demo或影片結果演示,而是短影片領域頭部玩家快手推出的產品級應用。而且主打一個務實,不開空頭支票、發布即上線,可靈大模型已在快影
 超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
超級智能體生命力覺醒!可自我更新的AI來了,媽媽再也不用擔心資料瓶頸難題
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂煉大模型,一網路的資料不夠用,根本不夠用。訓練模型搞得跟《飢餓遊戲》似的,全球AI研究者,都在苦惱怎麼才能餵飽這群資料大胃王。尤其在多模態任務中,這問題尤其突出。一籌莫展之際,來自人大系的初創團隊,用自家的新模型,率先在國內把「模型生成數據自己餵自己」變成了現實。而且還是理解側和生成側雙管齊下,兩側都能產生高品質、多模態的新數據,對模型本身進行數據反哺。模型是啥?中關村論壇上剛露面的多模態大模型Awaker1.0。團隊是誰?智子引擎。由人大高瓴人工智慧學院博士生高一鑷創立,高
