
這是2016年8月份上海MOORACLE大會上陳宏義老師(老K)分享的一個案例,將一個merge SQL,透過改寫成plsql的方式,大大提高了執行效率。老虎劉在看到這個案例的時候,開始沒有註意到執行計劃裡面顯示的各表實際記錄數,不認為plsql的改寫方式比分析函數的寫法更高效,還與陳老師有過幾次郵件討論,直到後來仔細檢查了執行計劃。
原始SQL如下:#merge into t_customer c using
(
select a.cstno, a.amount from t_trade a,
(select cstno,max(trade_date) trade_date from t_trade
group by cstno) b
where a.cstno = b.cstno and a.trade_date=b.trade_date
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
#這個SQL是將使用者交易明細表(t_trade )的最近的一筆消費額,更新到使用者資訊表(t_customer)的消費額字段,使用的是merge操作。
執行計劃:

#老虎劉注:
在沒有掌握分析函數的寫法前,SQL的紅色部分是group by後取其他字段資訊的一個較為常見的寫法,也是這個SQL執行效率差的根本原因。
原SQL還有一個隱患,就是如果t_trade的某個cstno對應的最大trade_date有重複,那麼這個SQL會報ORA-30926 錯誤無法執行。
如果不仔細看執行計劃(兩表的真實資料量資訊),這種SQL的慣用最佳化方法是使用分析函數改寫:
改寫方法1:#merge into t_customer c using
(
select a.cstno,a.amount from
(select trade_date,cstno,amount,
row_number()over(partition by cstno order by trade_date desc) RNO from t_trade)a
where RNO=1
) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
#這種改寫方法會比原SQL效率提高很多,而且不存在某個cstno對應的max trade_date 重複時報錯的問題。
但是陳老師沒有使用分析函數的改寫方法,而是根據兩表資料量相差較大的特點,將SQL改寫成一段更為高效的plsql:
改寫方法2:#declare
vamount number;
begin
for v in (select * from t_customer )
loop
select amount into vamount from
##(select amount from t_trade where cstno=v.cstno order by trade_date desc)where rownum update t_customer set amount = vamount where cstno=v.cstno;
end loop
commit;
end;
/
根據原SQL的執行計劃我們知道,t_customer表的記錄數比較少,只有1000多條,而t_trade表有1000萬條,比例為1:10000(不知道這是真實數據還是測試數據,只有1000多個用戶,而且一個用戶平均1萬個消費明細,看起來不像真實數據)。
在這樣一個兩表資料相差較大的特殊情況下,plsql寫法確實是比分析函數的寫法要高效。 這個改寫非常巧妙
。 我們再來分析這兩種改寫的優缺點:#1、plsql的改寫方式,適合在t_customer表比較小,而且t_customer 和 t_trade 兩表的記錄數比例比較大的情況下,執行效率才會比分析函數的改寫高一些。在這個例子中,如果t_customer表的記錄數是10萬,那麼分析函數的寫法反而要比plsql的寫法快上幾十到上百倍。3、plsql這種改寫的前提是必須存在t_trade表cstno trade_date 兩個字段的聯合索引。而分析函數的改寫就不需要任何索引的支援。
4、對於t_trade這種千萬記錄等級的表,使用分析函數的寫法可以透過開啟並行來提速;plsql的改寫,如果要提高效率,需要先將t_customer表按cstno分組,用多個session並發執行。
我們再來看看,陳老師的這段plsql,是不是可以用單一sql來實現,我做了一個嘗試,SQL程式碼如下:
merge into t_customer c using
(
select tc.cstno,####
(select amount
from t_trade td1
where td1.cstno=tc.cstno and td1.trade_date = (select max(trade_date) from t_trade td2 where tc.cstno = td2.cstno) and rownum=1 ) as amount
from t_customer tc
#) m
on(c.cstno = m.cstno)
when matched then
update set c.amount = m.amount;
#執行計劃大致如下:
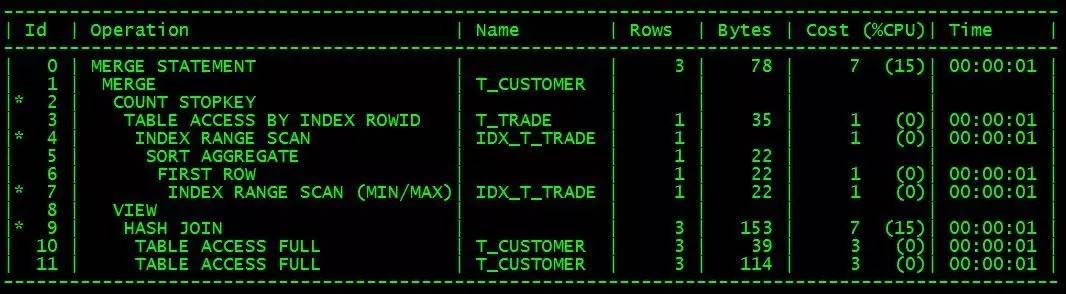
#這種寫法也是需要t_trade表存在cstno trade_date 聯合索引(IDX_T_TRADE),而T_customer 表的資料量遠低於T_trade。
根據執行計劃,這個sql的執行效率應該比plsql寫法的效率不相上下。
總結:SQL最佳化,除了要避免低效率的SQL寫法,主要還是要看表的資料量與資料分佈情況,plsql的改寫方法,在少數比較特殊的情況下會體現出較高的效率,在某些資料分佈的情況下,效率可能還不如原SQL。但是,優化想法非常值得借鏡。
而分析函數的改寫方式,不論資料如何分佈,都會比原SQL要高效,通用性更強。
對於本例改寫前的SQL,應該還有很多開發人員和DBA在使用,在了解了分析函數的使用方法後,原SQL的低效寫法就應該被徹底拋棄了。
最後的plsql改寫成單SQL,邏輯看起來比較複雜難懂,一般不會用到這樣的改寫,大家了解一下就好了。
還是那句話,優化無定式,優化器是死的,人腦是活的,只有掌握了原理,才能讓SQL執行效率越來越高。
以上是優化SQL效率的研究的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















