

網友曝光了OpenAI新模型所使用的嵌入技術

前幾天,OpenAI 來了一波重磅更新,一口氣宣布了 5 個新模型,其中就包括兩個新的文本嵌入模型。
嵌入是用數字序列來表示自然語言、程式碼等內容中的概念。它們能夠幫助機器學習模型和其他演算法更好地理解內容之間的關係,並且更容易執行聚類或檢索等任務。
通常,使用較大的嵌入模型(如儲存在向量記憶體中以供檢索)會消耗更多的成本、算力、記憶體和儲存資源。然而,OpenAI推出的兩個文本嵌入模型提供了不同的選擇。 首先,text-embedding-3-small模型是一個較小但有效率的模型。它可以在資源有限的環境下使用,並且在處理文字嵌入任務時表現出色。 另一方面,text-embedding-3-large模型則更大且更強大。這個模型可以處理更複雜的文字嵌入任務,並提供更準確和詳細的嵌入表示。然而,使用該模型需要更多的運算資源和儲存空間。 因此,根據具體的需求和資源限制,可以選擇適合的模型來平衡成本和效能之間的關係。
這兩個新的嵌入模型都是使用一種訓練技術來進行的,這使得開發人員可以在嵌入的效能和成本之間進行權衡。具體來說,開發者可以透過在 dimensions API 參數中傳遞嵌入來縮短嵌入的大小,同時不失去其概念表徵屬性。舉個例子,在 MTEB 基準上,text-embedding-3-large 可以縮短為 256 的大小,但其效能仍優於未縮短的 text-embedding-ada-002 嵌入(大小為 1536)。這樣一來,開發者可以根據具體需求來選擇適合的嵌入模型,既可以滿足效能要求,又可以控製成本。

這項技術的應用非常靈活。例如,當使用僅支援最高1024 維嵌入的向量資料儲存時,開發者可以選擇最好的嵌入模型text-embedding-3-large,並透過指定dimensions API 參數的值為1024,將嵌入維數從3072縮短為1024。雖然這樣做可能會犧牲一些準確度,但可以獲得較小的向量大小。
OpenAI 所使用的「縮短嵌入」方法,隨後引起了研究者們的廣泛注意。
人們發現,這種方法和 2022 年 5 月的一篇論文所提出的「Matryoshka Representation Learning」方法是相同的。
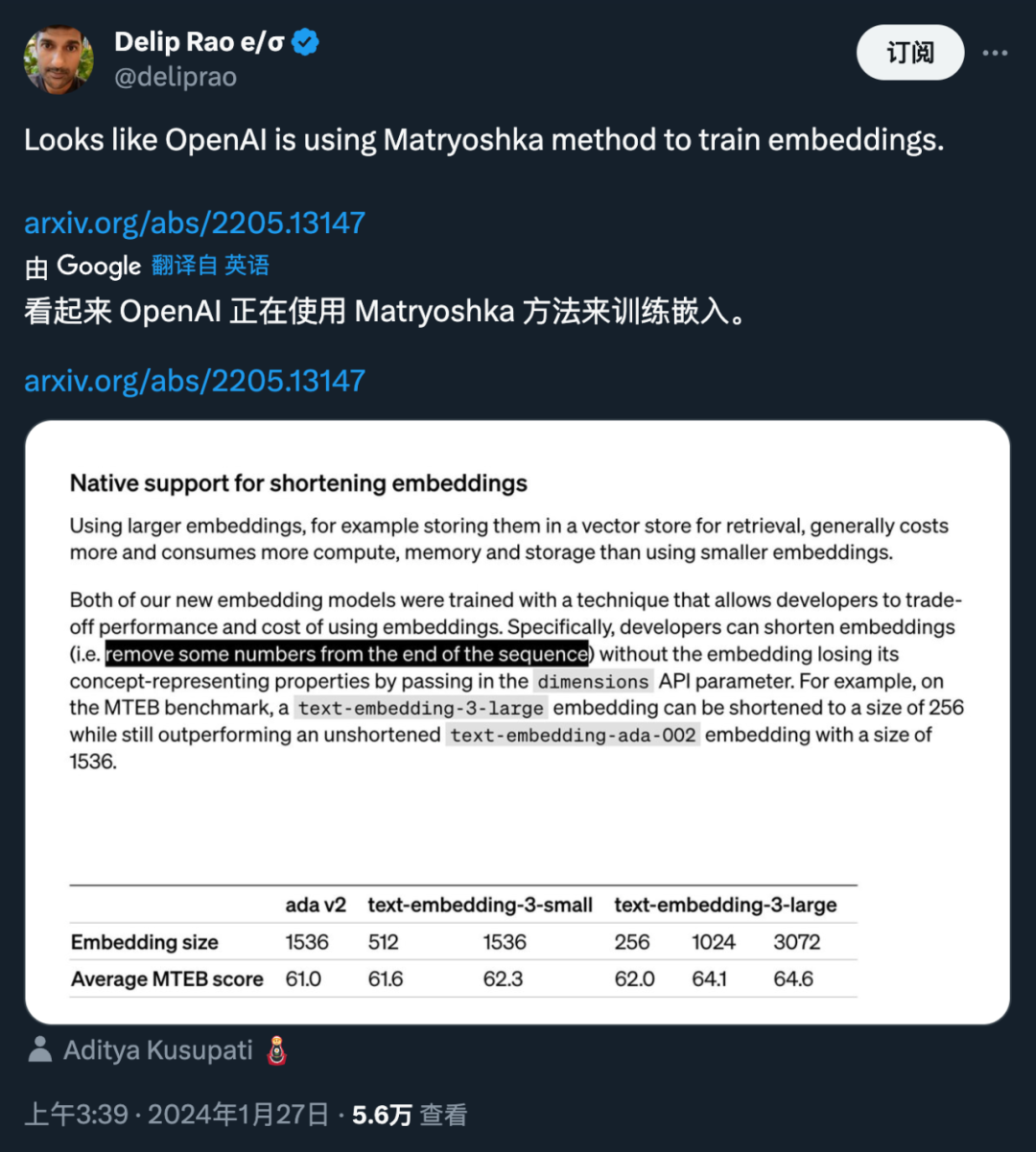
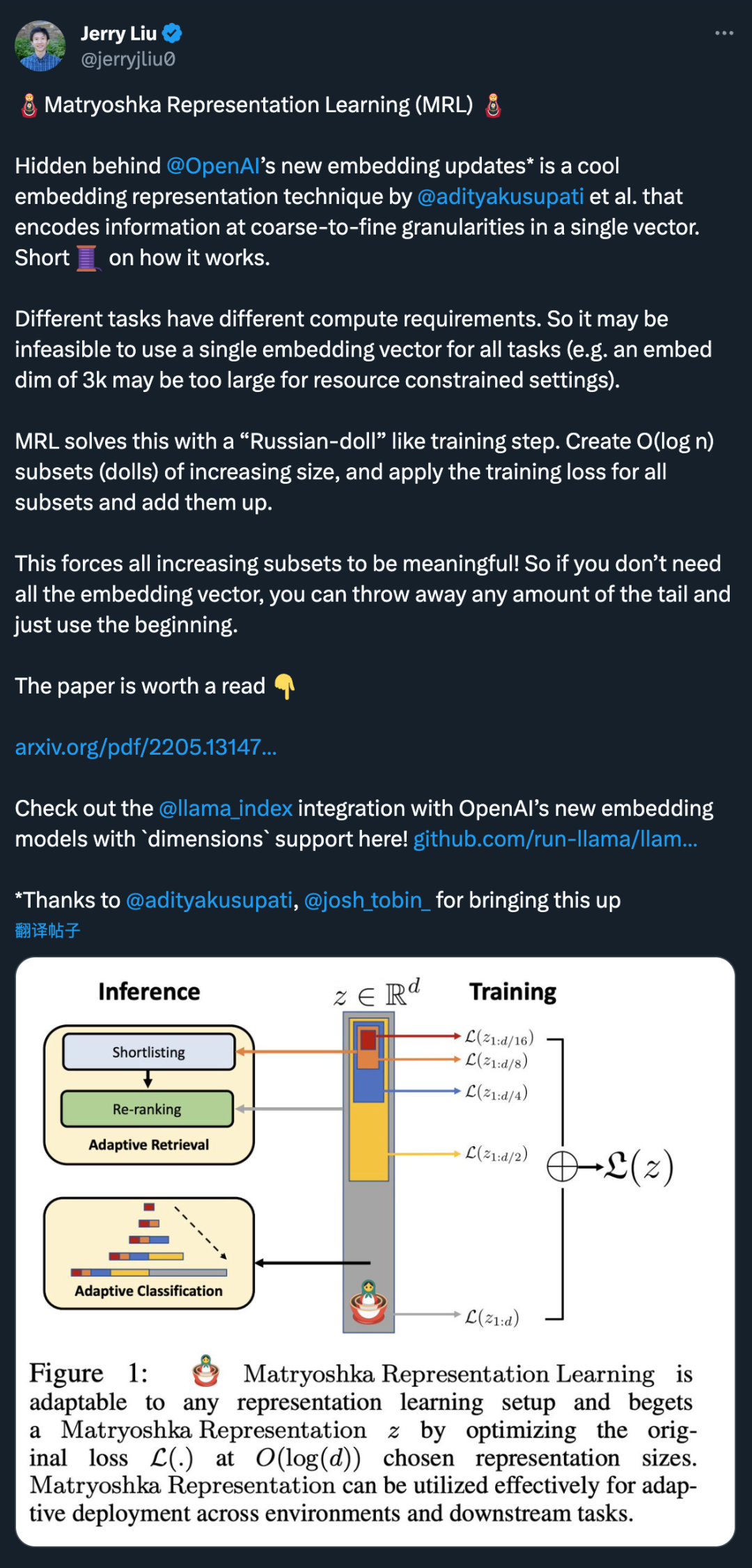
OpenAI 的新嵌入模型更新背後隱藏的是@adityakusupati 等人提出的一種很酷的嵌入表徵技術。
而MRL 的一作Aditya Kusupati 也現身說法:「OpenAI 在v3 嵌入API 中預設使用MRL 用於檢索和RAG!其他模型和服務應該很快就會迎頭趕上。」
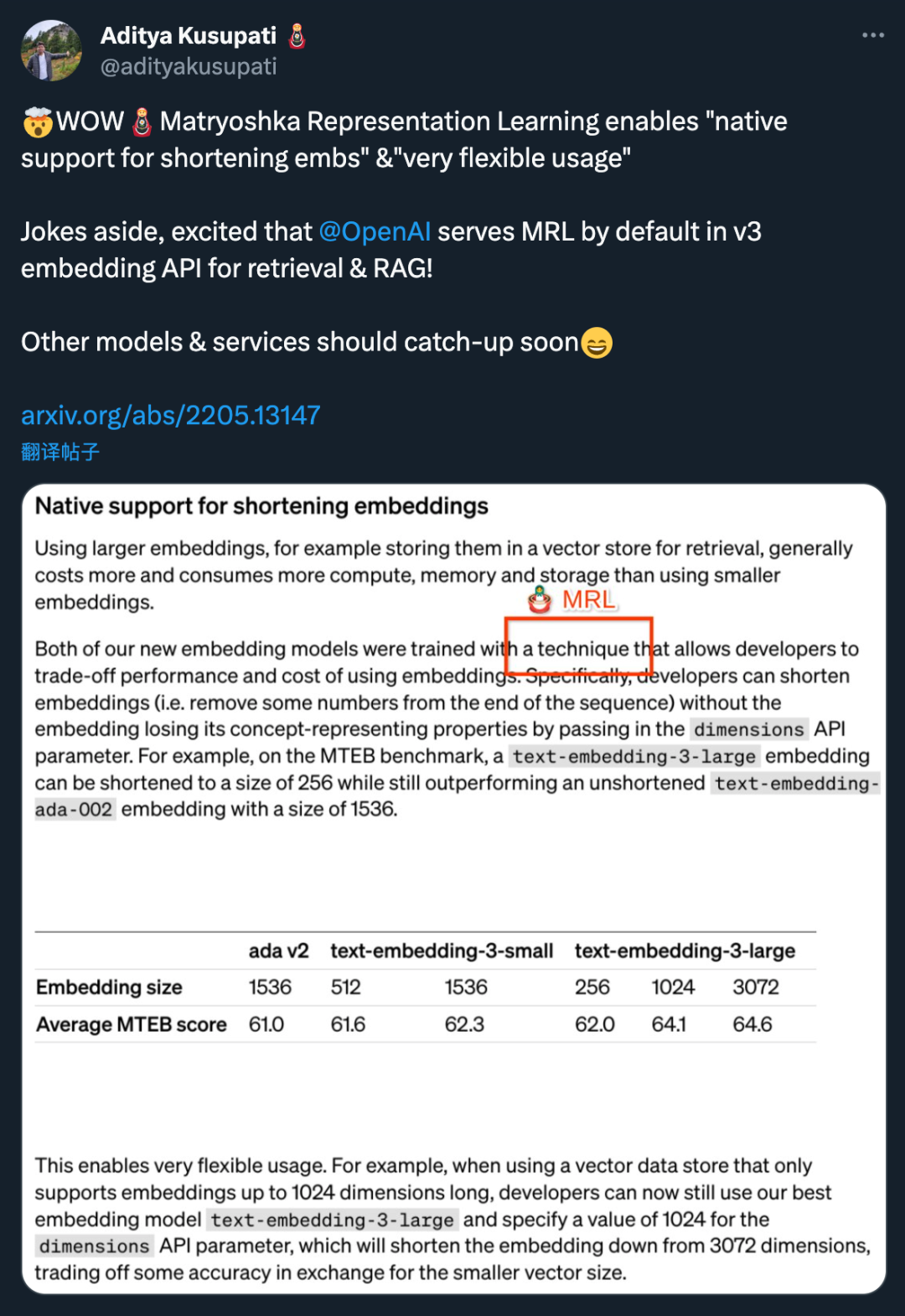
那麼MRL 到底是什麼?效果如何?都在下面這篇 2022 年的論文裡。
MRL 論文介紹

- #論文標題:Matryoshka Representation Learning
- 論文連結:https://arxiv.org/pdf/2205.13147.pdf
研究者提出的問題是:能否設計一個靈活的表徵方法,以適應計算資源不同的多個下游任務?
MRL 透過以巢狀方式對O (log (d)) 低維向量進行明確優化在同一個高維向量中學習不同容量的表徵,因此被稱為Matryoshka「俄羅斯娃娃」。 MRL 可適用於任何現有的表徵 pipeline,並可輕鬆擴展到電腦視覺和自然語言處理中的許多標準任務。
圖1 展示了MRL 的核心概念以及所學習Matryoshka 表徵的自適應部署設定:
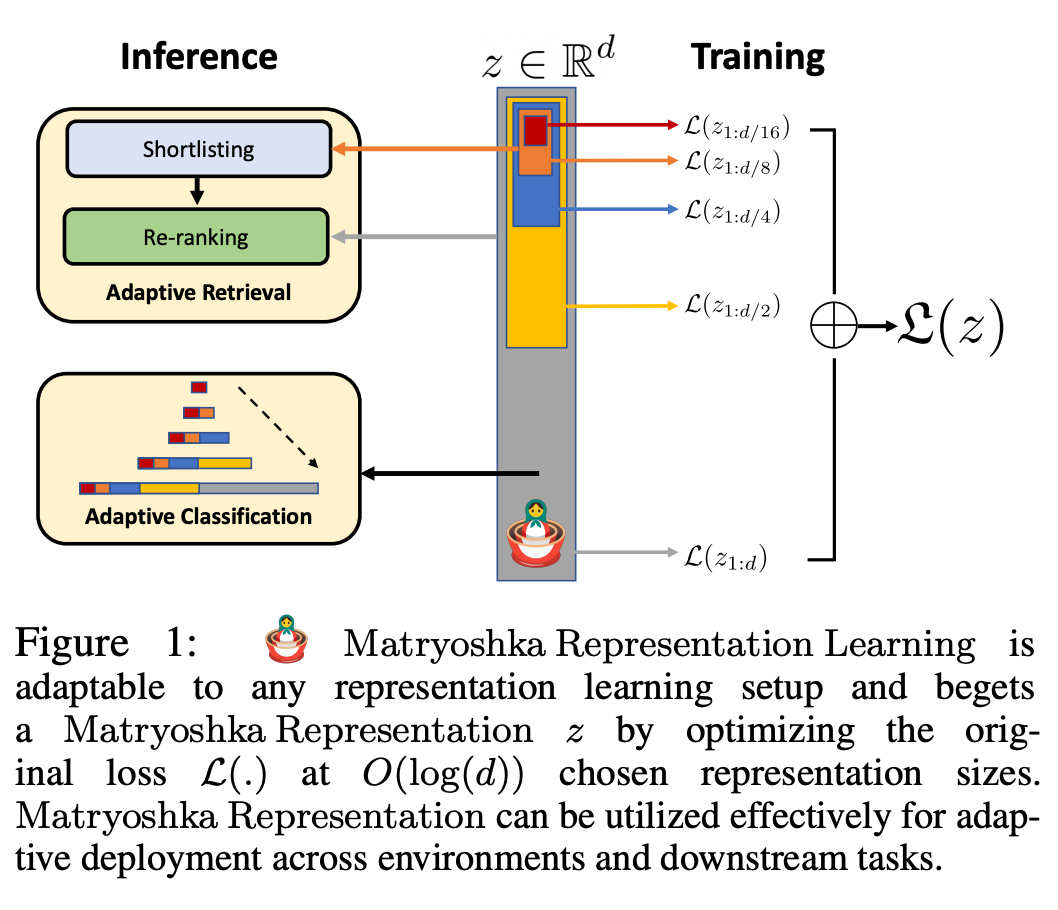
Matryoshka 表徵的第一個m-dimensions(m∈[d])是一個資訊豐富的低維向量,不需要額外的訓練成本,其精確度不亞於獨立訓練的m 維表徵法。 Matryoshka 表徵的資訊量隨著維度的增加而增加,形成了一種從粗到細的表徵法,而且無需大量的訓練或額外的部署開銷。 MRL 為表徵向量提供了所需的靈活性和多保真度,可確保在準確性與計算量之間實現近乎最佳的權衡。憑藉這些優勢,MRL 可根據精度和計算約束條件進行自適應部署。
在這項工作中,研究者將重點放在了現實世界 ML 系統的兩個關鍵構件上:大規模分類和檢索。
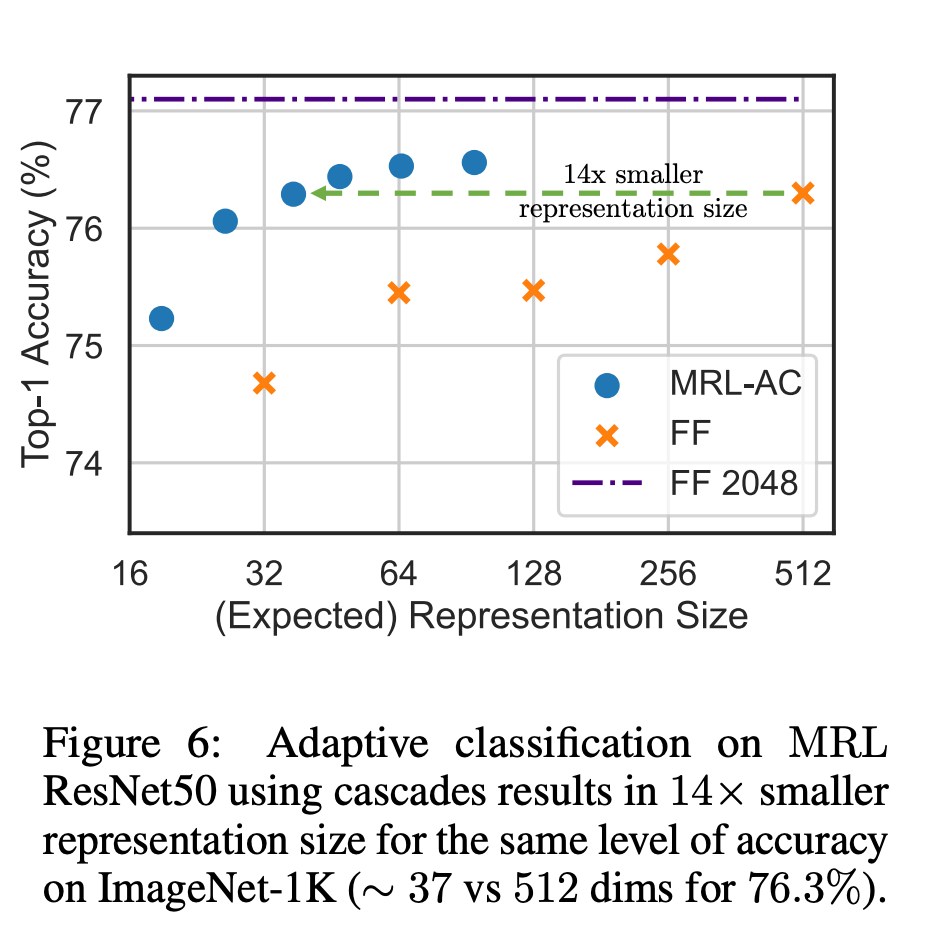
在分類方面,研究者使用了自適應級聯,並使用由MRL 訓練的模型產生的可變大小表徵,從而大大降低了達到特定準確率所需的嵌入式平均維數。例如,在 ImageNet-1K 上,MRL 自適應分類的結果是,在精確度與基線相同的情況下,表徵大小最多可縮小 14 倍。
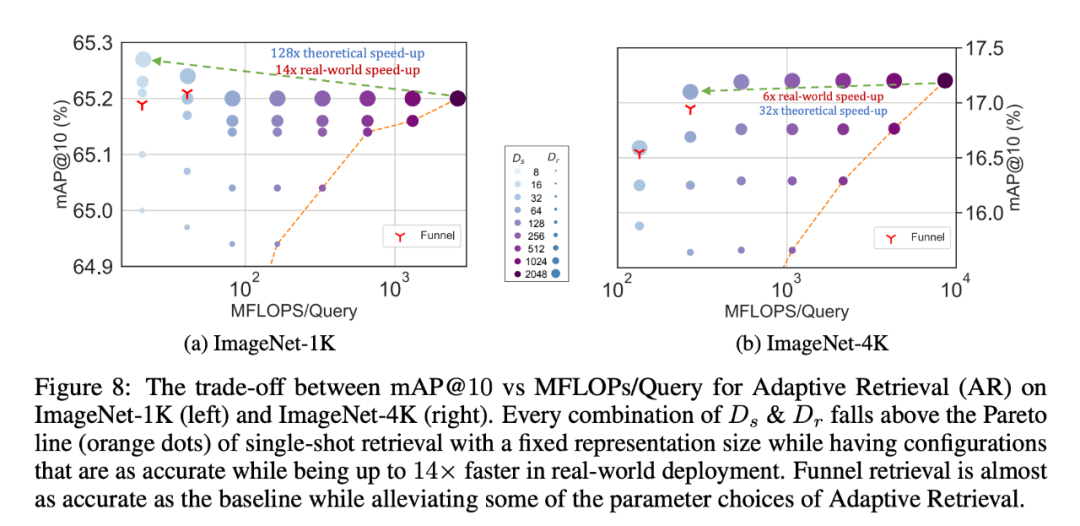
同樣地,研究者在自適應檢索系統中也使用了 MRL。在給定一個查詢的情況下,使用查詢嵌入的前幾個 dimensions 來篩選檢索候選對象,然後連續使用更多的 dimensions 對檢索集進行重新排序。與使用標準嵌入向量的單次檢索系統相比,此方法的簡單實現可實現128 倍的理論速度(以FLOPS 計)和14 倍的牆上時鐘時間速度;需要注意的是,MRL 的檢索精度與單次檢索的精確度相當(第4.3.1 節)。
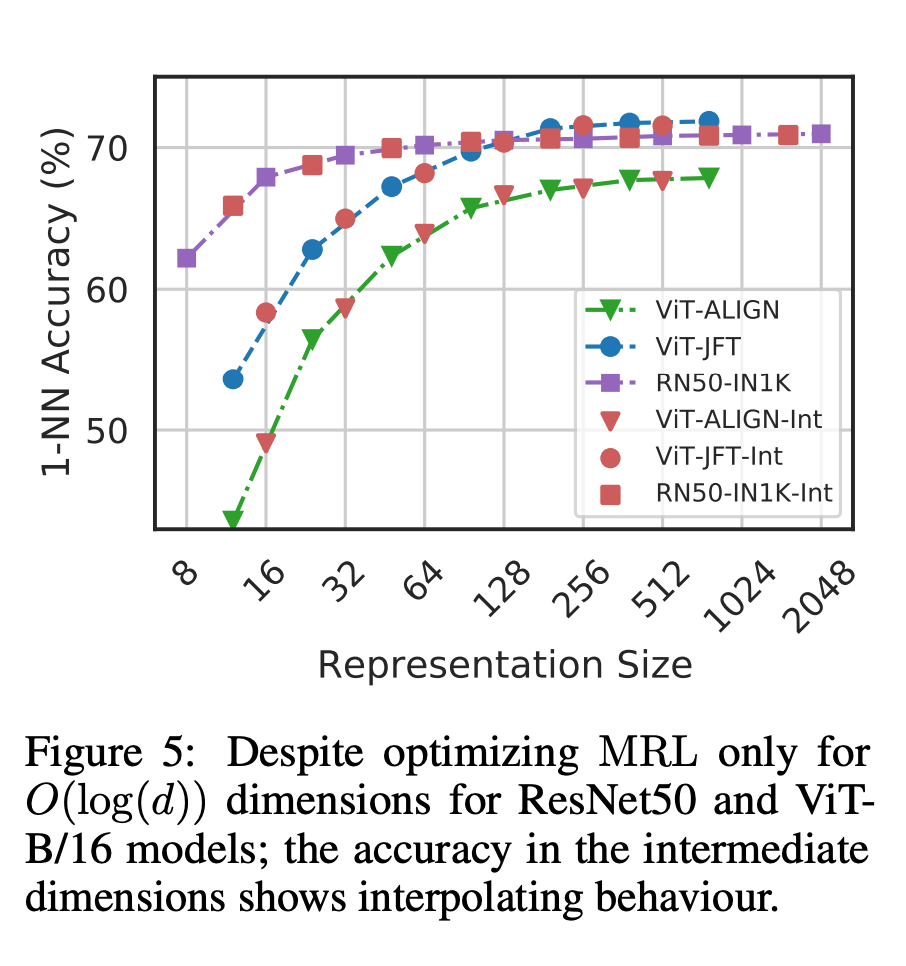
最後,由於MRL 明確地學習了從粗到細的表徵向量,因此直觀地說,它應該在不同dimensions 之間共享更多的語意資訊(圖5)。這反映在長尾持續學習設定中,準確率最多可提高 2%,同時與原始嵌入一樣穩健。此外,由於 MRL 具有粗粒度到細粒度的特性,因此它也可以用作分析實例分類難易程度和資訊瓶頸的方法。
更多研究細節,可參考論文原文。
以上是網友曝光了OpenAI新模型所使用的嵌入技術的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
Navicat查看MongoDB數據庫密碼的方法
Apr 08, 2025 pm 09:39 PM
直接通過 Navicat 查看 MongoDB 密碼是不可能的,因為它以哈希值形式存儲。取回丟失密碼的方法:1. 重置密碼;2. 檢查配置文件(可能包含哈希值);3. 檢查代碼(可能硬編碼密碼)。
 Navicat 連接數據庫錯誤代碼及解決辦法
Apr 08, 2025 pm 11:06 PM
Navicat 連接數據庫錯誤代碼及解決辦法
Apr 08, 2025 pm 11:06 PM
Navicat 連接數據庫時常見的錯誤及解決方案:用戶名或密碼錯誤(Error 1045)防火牆阻止連接(Error 2003)連接超時(Error 10060)無法使用套接字連接(Error 1042)SSL 連接錯誤(Error 10055)連接嘗試過多導致主機被阻止(Error 1129)數據庫不存在(Error 1049)沒有權限連接到數據庫(Error 1000)
 sql插入語句怎麼寫最新教程
Apr 09, 2025 pm 01:48 PM
sql插入語句怎麼寫最新教程
Apr 09, 2025 pm 01:48 PM
SQL INSERT 語句用於向數據庫表中添加新行,其語法為:INSERT INTO table_name (column1, column2, ..., columnN) VALUES (value1, value2, ..., valueN);。該語句支持插入多個值,並允許向列中插入 NULL 值,但需確保插入的值與列的數據類型兼容,避免違反唯一性約束。
 Navicat 連接超時:如何解決
Apr 08, 2025 pm 11:03 PM
Navicat 連接超時:如何解決
Apr 08, 2025 pm 11:03 PM
Navicat連接超時原因:網絡不穩定、數據庫繁忙、防火牆阻攔、服務器配置問題、Navicat設置不當。解決步驟:檢查網絡連接、數據庫狀況、防火牆設置,調整服務器配置,檢查Navicat設置,重啟軟件和服務器,聯繫管理員尋求幫助。
 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通過使用 ALTER TABLE 語句為現有表添加新列。具體步驟包括:確定表名稱和列信息、編寫 ALTER TABLE 語句、執行語句。例如,為 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 Navicat for MongoDB如何查看數據庫密碼?
Apr 08, 2025 pm 09:21 PM
Navicat for MongoDB如何查看數據庫密碼?
Apr 08, 2025 pm 09:21 PM
Navicat for MongoDB 無法查看數據庫密碼,原因是密碼被加密存儲,僅持有連接信息。找回密碼需要通過MongoDB本身,具體操作取決於部署方式。安全第一,養成良好密碼習慣,切勿嘗試從第三方工具獲取密碼,避免安全風險。
 除了 Navicat,還有什麼工具可以連接達夢數據庫
Apr 08, 2025 pm 10:06 PM
除了 Navicat,還有什麼工具可以連接達夢數據庫
Apr 08, 2025 pm 10:06 PM
除了 Navicat,連接達夢數據庫的替代方案包括:達夢官方客戶端工具,提供基本功能。 SQL Developer,支持高級功能。 Toad for Data Engineers,集成多種功能。 DbVisualizer,免費開源且支持數據建模。 DataGrip,提供智能代碼支持。 HeidiSQL,簡單易用但需要插件。
 SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 添加列的語法是什麼
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的語法為 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是數據類型,NOT NULL 指定是否允許空值,DEFAULT default_value 指定默認值。
