
建立會做影片的世界模型,也能透過Transformer來實現了!
來自清華和極佳科技的研究人員聯手,推出了全新的影片生成通用世界模型-WorldDreamer。
它可以完成多種影片生成任務,包括自然場景和自動駕駛場景,如文生影片、圖生影片、影片編輯、動作序列生影片等。

根據團隊介紹,透過預測Token的方式來建立通用場景世界模型,WorldDreamer是業界首個。
它把影片產生轉換為一個序列預測任務,可以對物理世界的變化和運動規律進行充分地學習。
視覺化實驗已經證明,WorldDreamer已經深刻地理解了通用世界的動態變化規律。
那麼,它都能完成哪些影片任務,效果如何呢?
#WorldDreamer可以基於單一影像預測未來的幀。
只需首張圖片輸入,WorldDreamer將剩餘的視訊影格視為被遮罩的視覺Token,並對這部分Token進行預測。
如下圖所示,WorldDreamer具有產生高品質電影級影片的能力。
其生成的影片呈現出無縫的逐幀運動,類似於真實電影中流暢的攝影機運動。
而且,這些影片嚴格遵循原始影像的約束,確保幀構圖的顯著一致性。

#WorldDreamer也可以基於文字進行影片產生。
僅僅給定語言文字輸入,此時WorldDreamer認為所有的視訊框架都是被遮罩的視覺Token,並對這部分Token進行預測。
下圖展示了WorldDreamer在各種風格範式下從文字生成影片的能力。
產生的影片與輸入語言無縫契合,其中使用者輸入的語言可以塑造影片內容、風格和相機運動。

#WorldDreamer進一步可以實作影片的inpainting任務。
具體來說,給定一段視頻,用戶可以指定mask區域,然後根據語言的輸入可以更改被mask區域的視頻內容。
如下圖所示,WorldDreamer可以將水母更換為熊,也可以將蜥蜴換成猴子,更換後的影片高度符合使用者的語言描述。

除此之外,WorldDreamer可以實現影片的風格化。
如下圖所示,輸入一個影片段,其中某些像素被隨機掩碼,WorldDreamer可以改變影片的風格,例如根據輸入語言建立秋季主題效果。

#WorldDreamer也可以實現在自動駕駛場景下的駕駛動作到影片的生成。
如下圖所示,給定相同的初始幀以及不同的駕駛策略(如左轉、右轉),WorldDreamer可以產生高度符合首幀約束以及駕駛策略的影片。

那麼,WorldDreamer又是怎麼實現這些功能的呢?
研究人員認為,目前最先進的影片產生方法主要分為兩類-基於Transformer的方法和基於擴散模型的方法。
利用Transformer進行Token預測可以高效學習到視訊訊號的動態訊息,並且可以重複使用大語言模型社群的經驗,因此,基於Transformer的方案是學習通用世界模型的有效途徑。
而基于扩散模型的方法难以在单一模型内整合多种模态,且难以拓展到更大参数,因此很难学习到通用世界的变化和运动规律。
而当前的世界模型研究主要集中在游戏、机器人和自动驾驶领域,缺乏全面捕捉通用世界变化和运动规律的能力。
所以,研究团队提出了WorldDreamer来加强对通用世界的变化和运动规律的学习理解,从而显著增强视频生成的能力。
借鉴大型语言模型的成功经验,WorldDreamer采用Transformer架构,将世界模型建模框架转换为一个无监督的视觉Token预测问题。
具体的模型结构如下图所示:
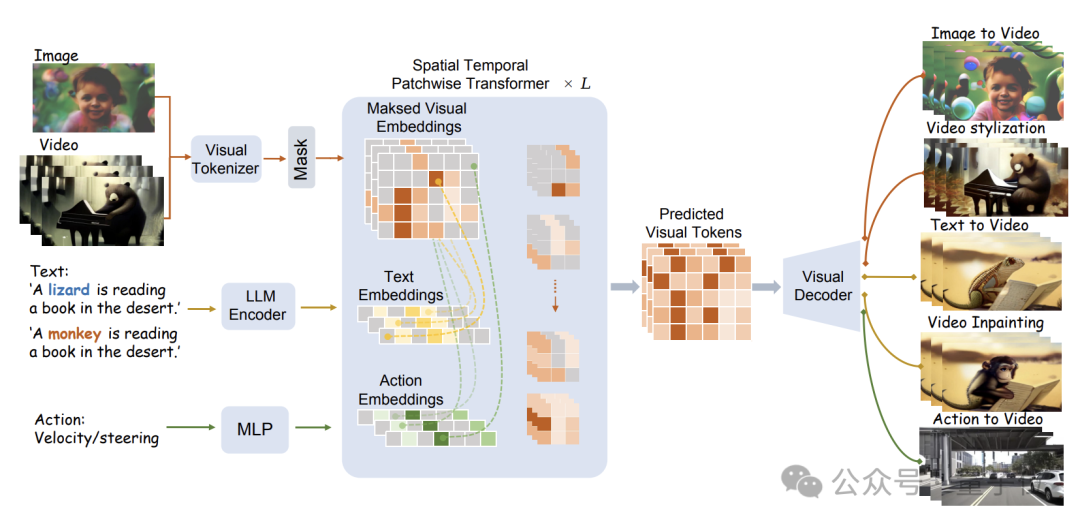
WorldDreamer首先使用视觉Tokenizer将视觉信号(图像和视频)编码为离散的Token。
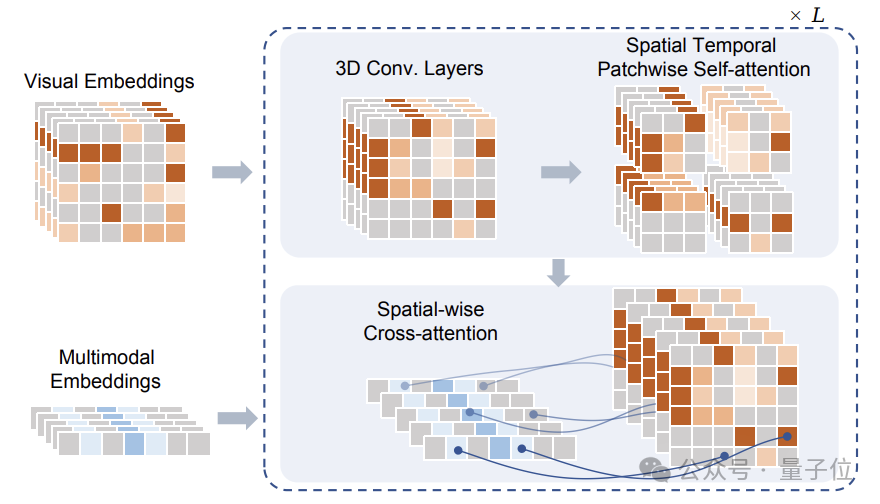
这些Token在经过掩蔽处理后,输入给研究团队提出的Sptial Temporal Patchwuse Transformer(STPT)模块。
同时,文本和动作信号被分别编码为对应的特征向量,以作为多模态特征一并输入给STPT。
STPT在内部对视觉、语言、动作等特征进行充分的交互学习,并可以预测被掩码部分的视觉Token。
最终,这些预测出的视觉Token可以用来完成各种各样的视频生成和视频编辑任务。
值得注意的是,在训练WorldDreamer时,研究团队还构建了Visual-Text-Action(视觉-文本-动作)数据的三元组,训练时的损失函数仅涉及预测被掩蔽的视觉Token,没有额外的监督信号。
而在团队提出的这个数据三元组中,只有视觉信息是必须的,也就是说,即使在没有文本或动作数据的情况下,依然可以进行WorldDreamer的训练。
这种模式不仅降低了数据收集的难度,还使得WorldDreamer可以支持在没有已知或只有单一条件的情况下完成视频生成任务。
研究团队使用大量数据对WorldDreamer进行训练,其中包括20亿经过清洗的图像数据、1000万段通用场景的视频、50万段高质量语言标注的视频、以及近千段自动驾驶场景视频。
团队对10亿级别的可学习参数进行了百万次迭代训练,收敛后的WorldDreamer逐渐理解了物理世界的变化和运动规律,并拥有了各种的视频生成和视频编辑能力。
论文地址:https://arxiv.org/abs/2401.09985
项目主页:https://world-dreamer.github.io/
以上是Transformer模型在挑戰視訊生成中成功利用20億個數據點學習物理世界的詳細內容。更多資訊請關注PHP中文網其他相關文章!




















