

最新推出的適合中文LMM體質的基準CMMMU:包含超過30個細分學科和12K個專家級題目

隨著多模態大模型(LMM)的不斷進步,對於評估LMM性能的需求也在增長。尤其在中文環境下,評估LMM的高階知識和推理能力變得更加重要。
在這個背景下,為了評估基本模型在中文各種任務中的專家級多模態理解能力,M-A-P 開源社群、港科大、滑鐵盧大學和零一萬物共同推出了CMMMU(Chinese Massive Multi-discipline Multimodal Understanding and Reasoning)基準。該基準旨在提供一個全面的中文大規模多學科多模態理解和推理的評估平台。透過此基準,研究人員可以測試模型在多種任務中的表現,並比較其專業程度的多模態理解能力。這個聯合計畫的目標是促進中文多模態理解和推理領域的發展,並為相關研究提供一個標準化的參考。
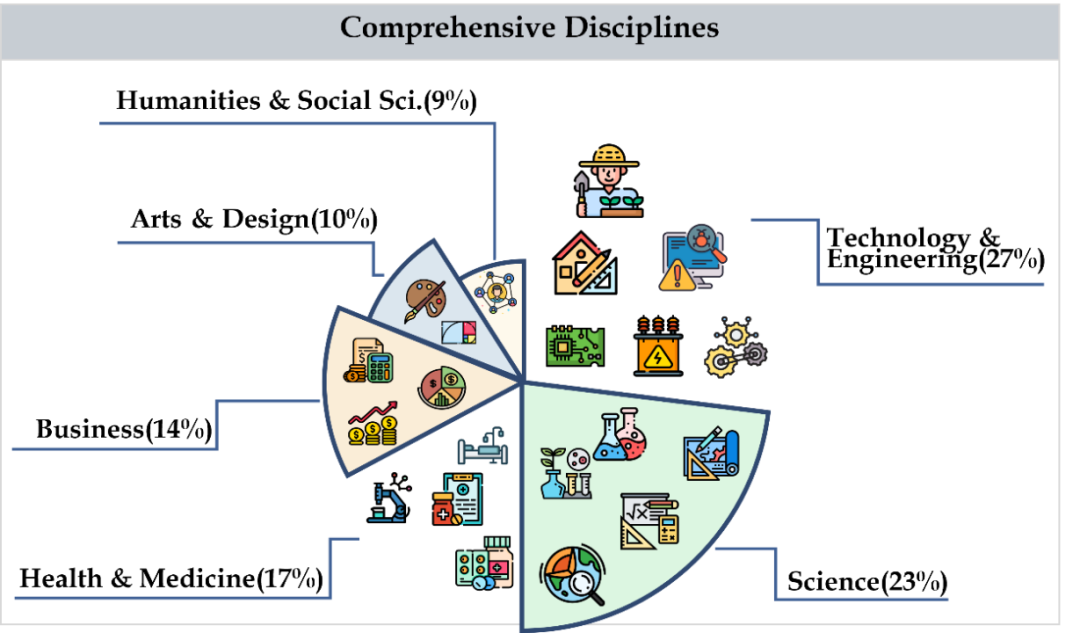
CMMMU 涵蓋了六個大類學科,包括藝術、商業、健康和醫學、科學、人文與社會科學、技術與工程,涉及30多個細分領域學科。下圖展示了每個細分領域學科的一個題目範例。 CMMMU 是第一個在中文背景下的多模態基準之一,也是少數幾個檢視LMM複雜理解和推理能力的多模態基準之一。

資料集建構
資料擷取
資料收集分為三個階段。首先,研究者為每科收集符合版權許可要求的題目來源,包括網頁或書籍。在此過程中,他們努力避免題源重複,以確保資料的多樣性和準確性。 其次,研究者將題源轉送給眾包標註者進一步的標註。所有的標註者都是擁有本科或更高學位的人員,以確保他們能夠驗證標註的問題和相關的解釋。在標註過程中,研究者要求標註者嚴格遵循標註原則。例如,過濾掉那些不需要圖片就能回答的問題,盡可能地過濾掉使用相同影像的問題,以及過濾掉那些不需要專家知識來回答的問題。 最後,為了平衡資料集中每個科目題目的數量,研究者們專門補充問題收集較少的科目。這樣做可以確保資料集的完整性和代表性,使得後續的分析和研究更準確和全面。
資料集清洗
為了進一步提高CMMMU的資料質量,研究者們遵循嚴格的資料品質控制協定.首先,每個問題都由至少一位論文作者親自驗證。其次,為了避免資料污染問題,他們也篩選了那些幾個LLM也能回答出來的問題,而不需要藉助OCR技術。這些措施確保了CMMMU數據的可靠性和準確性。
資料集概覽
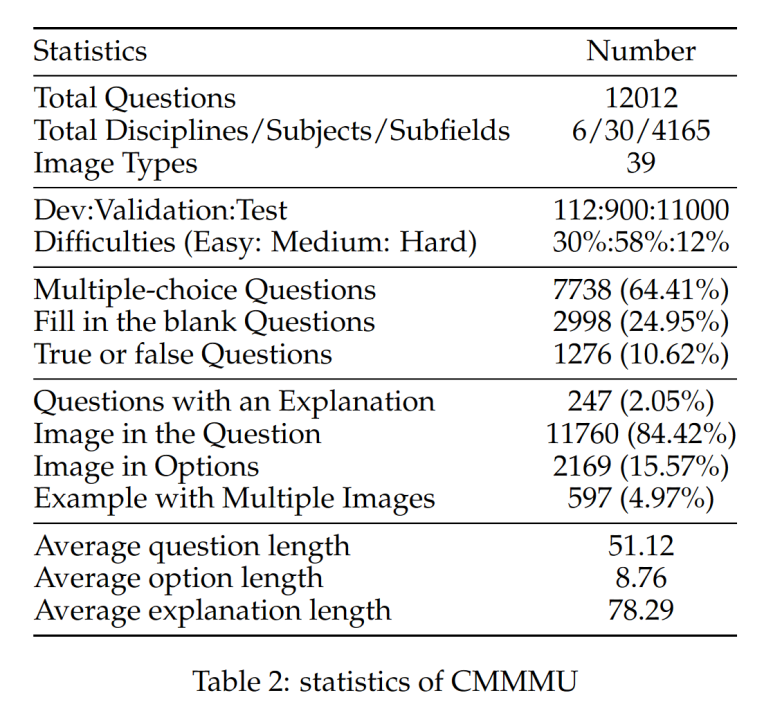
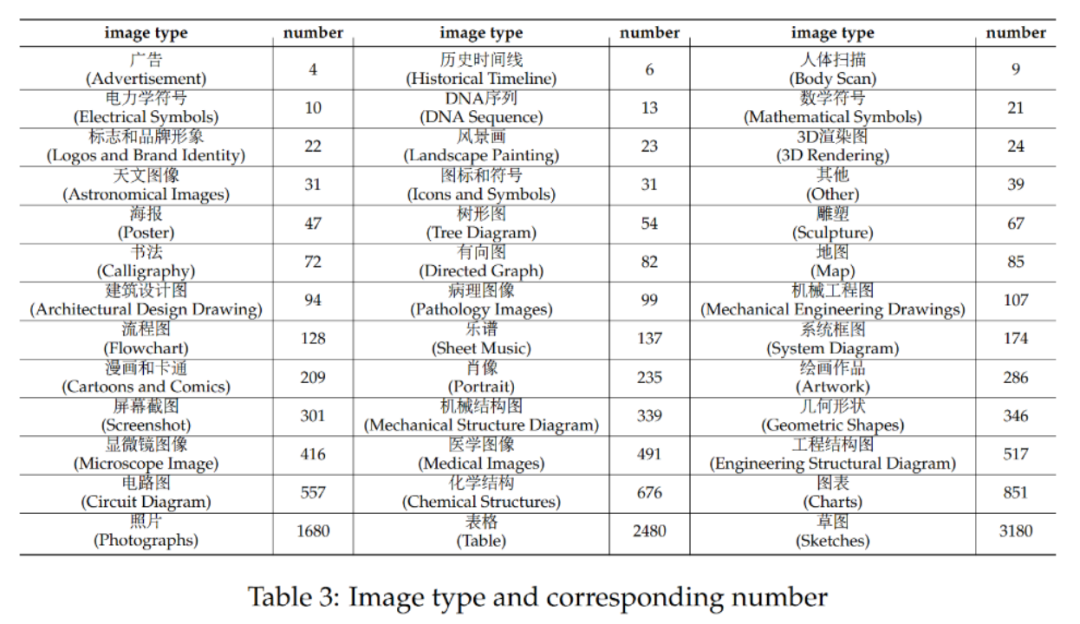
#CMMMU共有12K個題目,分為少樣本開發集、驗證集、測試集。少樣本開發集包含每個學科約5個題目,驗證集有900個題目,測試集有11K個題目。題目涵蓋了39種類型的圖片,包括病理圖、樂譜圖、電路圖、化學結構圖等。這些題目依邏輯難度而非智力難度分為簡單(30%)、中等(58%)和困難(12%)三個難度等級。更多題目統計資料可見表2和表3。
實驗
團隊測試了多種主流的中英文雙語LMM 以及幾個LLM 在CMMMU 上的表現。其中包含了閉源和開源模型。評估過程使用 zero-shot 設置,而不是微調或 few-shot 設置,以檢查模型的原始能力。 LLM 也加入了圖片 OCR 結果 text 作為輸入的實驗。所有的實驗都是在 NVIDIA A100 圖形處理器上進行的。
主要結果
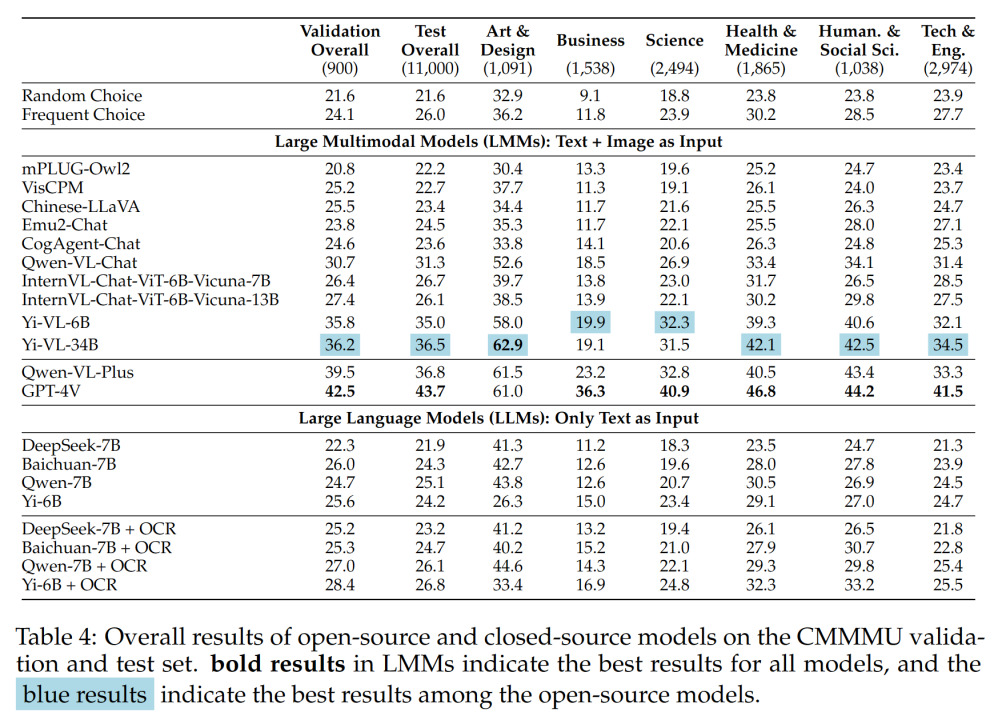
#表 4 展示了實驗結果:
一些重要發現包括:
#- CMMMU 比MMMU 更具挑戰性,而這是在MMMU 已經非常具有挑戰性的前提下。
GPT-4V 在中文情境下的準確率僅為 41.7% ,而在英語情境下的準確率為 55.7% 。這表明,現有的跨語言泛化方法甚至對於最先進的閉源 LMM 都不夠好。
- 與 MMMU 相比,國內代表性的開源模型與 GPT-4V 之間的差距相對較小。
Qwen-VL-Chat 和GPT-4V 在MMMU 上的差異為13.3% ,而BLIP2-FLAN-T5-XXL 和GPT-4V 在MMMU 上的差異為21.9% 。令人驚訝的是,Yi-VL-34B 甚至將CMMMU 上開源雙語LMM 和GPT-4V 之間的差距縮小到了7.5% ,這意味著在中文環境下,開源雙語LMM 與GPT-4V 相當,這在開源社群中是一個有希望的進步。
- 在開源社群中,追求中文專家多模態人工通用智慧 (AGI) 的遊戲才剛開始。
團隊指出,除了最近發布的Qwen-VL-Chat、 Yi-VL-6B 和Yi-VL-34B 外,所有來自開源社群的雙語LMM 只能達到與CMMMU 的frequent choice 相當的精度。
對不同題目難度與題目的分析
- 不同題目類型
Yi-VL 系列、 Qwen-VL-Plus 和GPT-4V 之間的差異主要還是因為它們回答選擇題的能力不同。
不同題目類型的結果如表5 所示:
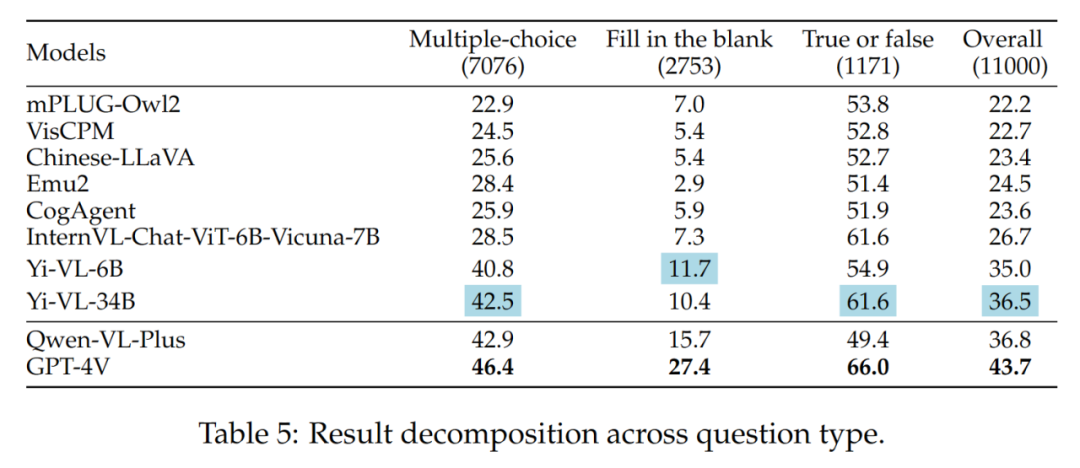
- 不同題目難度
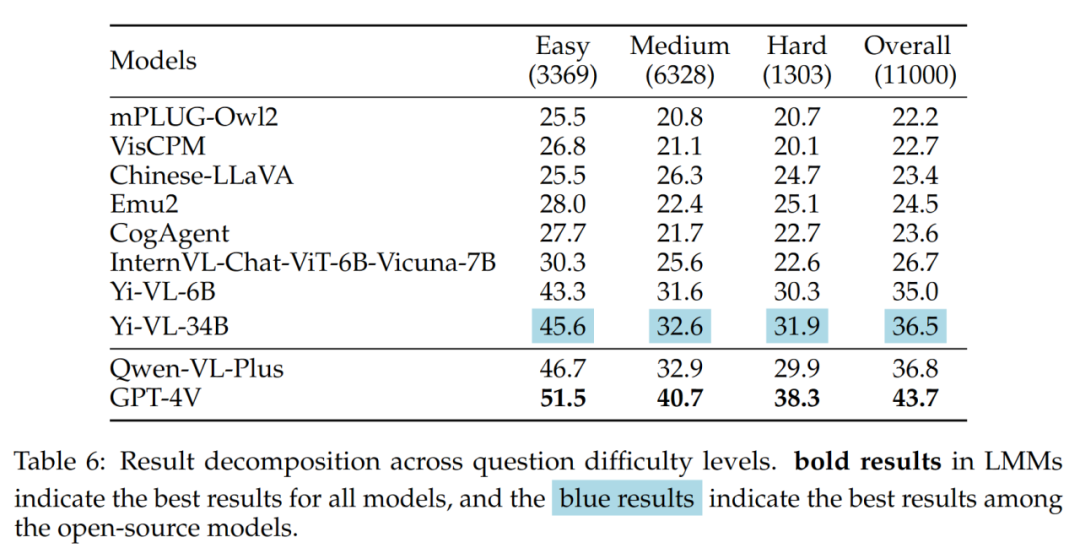
結果中值得注意的是,最好的開源LMM (即Yi-VL-34B) 和GPT-4V 在面對中等和困難的問題時存在較大的差距。這進一步有力地證明,開源 LMM 和 GPT-4V 之間的關鍵差異在於在複雜條件下的計算和推理能力。
不同題目難度的結果如表6 所示:
##錯誤分析
研究者仔細分析了GPT-4V 的錯誤答案。如下圖所示,錯誤的主要類型有感知錯誤、缺乏知識、推理錯誤、拒絕回答和註釋錯誤。分析這些錯誤類型是理解當前 LMM 的能力和限制的關鍵,也可以指導未來設計和培訓模型的改進。
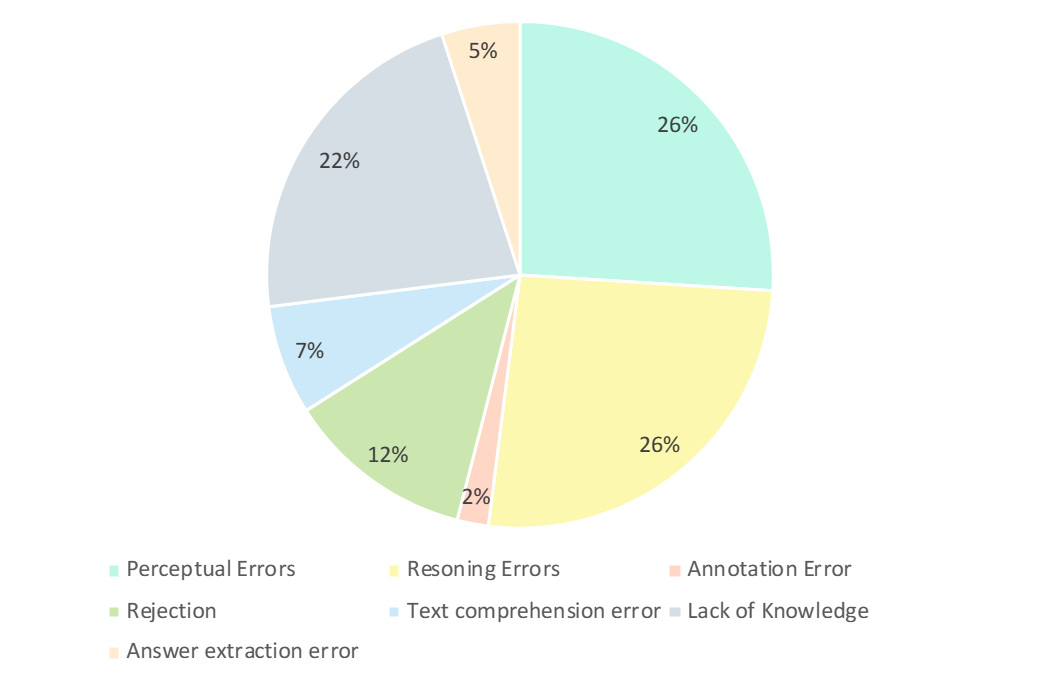
- 知覺錯誤(26%) : 知覺錯誤是GPT-4V 產生錯誤範例的主要原因之一。一方面,當模型無法理解圖像時,會引入對圖像基本感知的偏差,從而導致不正確的反應。另一方面,當模型遇到特定領域知識、隱含意義或不明確的公式中的歧義時,它往往表現出特定領域的知覺錯誤。在這種情況下,GPT-4V 傾向於更多地依賴基於文字訊息的回答 (即問題和選項) ,優先考慮文字訊息而不是視覺輸入,從而導致理解多模態資料的偏差。
- 推理錯誤 (26%) :# 推理錯誤是 GPT-4V 產生錯誤範例的另一個主要因素。在模型正確地感知到圖像和文字所傳達的意義的情況下,在解決需要複雜邏輯和數學推理的問題時,推理過程中仍會出現錯誤。通常,這種錯誤是由於模型較弱的邏輯和數學推理能力所造成的。
- 缺乏知識 (22%) : 缺乏專業知識也是 GPT-4V 錯誤作答的原因之一。由於 CMMMU 是評估 LMM 專家 AGI 的基準,因此需要不同學科和次領域的專家級知識。因此,將專家級知識注入 LMM 也是可以努力的方向之一。
- 拒絕回答 (12%) : 模型拒絕回答也是常見的現象。透過分析,他們指出模型拒絕回答問題的幾個原因: (1) 模型未能從圖像中感知到資訊;(2) 是涉及宗教問題或個人現實生活資訊的問題,模型會主動迴避;(3)當問題涉及性別和主觀因素時,模型避免直接提供答案。
- 其錯誤:其餘的錯誤包括文字理解錯誤(7%)、標註錯誤(2%) 和答案提取錯誤(5%)。這些錯誤是由於複雜的結構追蹤能力、複雜的文字邏輯理解、回應產生的限制、資料標註的錯誤以及答案匹配提取中遇到的問題等多種因素造成的。
結論
CMMMU 基準測試標誌著高階通用人工智慧 (AGI) 開發的重大進展。 CMMMU 的設計是為了嚴格評估最新的大型多模態模型 (LMMs) ,並測試基本的感知技能,複雜的邏輯推理,以及在特定領域的深刻專業知識。研究透過比較中英雙語語境下 LMM 的推理能力,指出其中的差異。這種詳盡的評估對於判定模型水準與各領域經驗豐富的專業人員的熟練程度的差距至關重要。
以上是最新推出的適合中文LMM體質的基準CMMMU:包含超過30個細分學科和12K個專家級題目的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
開源!超越ZoeDepth! DepthFM:快速且精確的單目深度估計!
Apr 03, 2024 pm 12:04 PM
0.這篇文章乾了啥?提出了DepthFM:一個多功能且快速的最先進的生成式單目深度估計模型。除了傳統的深度估計任務外,DepthFM還展示了在深度修復等下游任務中的最先進能力。 DepthFM效率高,可以在少數推理步驟內合成深度圖。以下一起來閱讀這項工作~1.論文資訊標題:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想像一下,一個人工智慧模型,不僅擁有超越傳統運算的能力,還能以更低的成本實現更有效率的效能。這不是科幻,DeepSeek-V2[1],全球最強開源MoE模型來了。 DeepSeek-V2是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由236B個參數組成,其中21B個參數用於啟動每個標記。與DeepSeek67B相比,DeepSeek-V2效能更強,同時節省了42.5%的訓練成本,減少了93.3%的KV緩存,最大生成吞吐量提高到5.76倍。 DeepSeek是一家探索通用人工智
 AI顛覆數學研究!菲爾茲獎得主、華裔數學家領銜11篇頂刊論文|陶哲軒轉贊
Apr 09, 2024 am 11:52 AM
AI顛覆數學研究!菲爾茲獎得主、華裔數學家領銜11篇頂刊論文|陶哲軒轉贊
Apr 09, 2024 am 11:52 AM
AI,的確正在改變數學。最近,一直十分關注這個議題的陶哲軒,轉發了最近一期的《美國數學學會通報》(BulletinoftheAmericanMathematicalSociety)。圍繞著「機器會改變數學嗎?」這個話題,許多數學家發表了自己的觀點,全程火花四射,內容硬核,精彩紛呈。作者陣容強大,包括菲爾茲獎得主AkshayVenkatesh、華裔數學家鄭樂雋、紐大電腦科學家ErnestDavis等多位業界知名學者。 AI的世界已經發生了天翻地覆的變化,要知道,其中許多文章是在一年前提交的,而在這一
 替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被開源專案擴展到卷積了
Jun 01, 2024 pm 10:03 PM
本月初,來自MIT等機構的研究者提出了一種非常有潛力的MLP替代方法—KAN。 KAN在準確性和可解釋性方面表現優於MLP。而且它能以非常少的參數量勝過以更大參數量運行的MLP。例如,作者表示,他們用KAN以更小的網路和更高的自動化程度重現了DeepMind的結果。具體來說,DeepMind的MLP有大約300,000個參數,而KAN只有約200個參數。 KAN與MLP一樣具有強大的數學基礎,MLP基於通用逼近定理,而KAN基於Kolmogorov-Arnold表示定理。如下圖所示,KAN在邊上具
 你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
你好,電動Atlas!波士頓動力機器人復活,180度詭異動作嚇到馬斯克
Apr 18, 2024 pm 07:58 PM
波士頓動力Atlas,正式進入電動機器人時代!昨天,液壓Atlas剛「含淚」退出歷史舞台,今天波士頓動力就宣布:電動Atlas上崗。看來,在商用人形機器人領域,波士頓動力是下定決心要跟特斯拉硬剛一把了。新影片放出後,短短十幾小時內,就已經有一百多萬觀看。舊人離去,新角色登場,這是歷史的必然。毫無疑問,今年是人形機器人的爆發年。網友銳評:機器人的進步,讓今年看起來像人類的開幕式動作、自由度遠超人類,但這真不是恐怖片?影片一開始,Atlas平靜地躺在地上,看起來應該是仰面朝天。接下來,讓人驚掉下巴
 iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
iPhone上的蜂窩數據網路速度慢:修復
May 03, 2024 pm 09:01 PM
在iPhone上面臨滯後,緩慢的行動數據連線?通常,手機上蜂窩互聯網的強度取決於幾個因素,例如區域、蜂窩網絡類型、漫遊類型等。您可以採取一些措施來獲得更快、更可靠的蜂窩網路連線。修復1–強制重啟iPhone有時,強制重啟設備只會重置許多內容,包括蜂窩網路連線。步驟1–只需按一次音量調高鍵並放開即可。接下來,按降低音量鍵並再次釋放它。步驟2–過程的下一部分是按住右側的按鈕。讓iPhone完成重啟。啟用蜂窩數據並檢查網路速度。再次檢查修復2–更改資料模式雖然5G提供了更好的網路速度,但在訊號較弱
 特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人進廠打工,馬斯克:手的自由度今年將達到22個!
May 06, 2024 pm 04:13 PM
特斯拉機器人Optimus最新影片出爐,已經可以在工廠裡打工了。正常速度下,它分揀電池(特斯拉的4680電池)是這樣的:官方還放出了20倍速下的樣子——在小小的「工位」上,揀啊揀啊揀:這次放出的影片亮點之一在於Optimus在廠子裡完成這項工作,是完全自主的,全程沒有人為的干預。而且在Optimus的視角之下,它還可以把放歪了的電池重新撿起來放置,主打一個自動糾錯:對於Optimus的手,英偉達科學家JimFan給出了高度的評價:Optimus的手是全球五指機器人裡最靈巧的之一。它的手不僅有觸覺
 牛津大學最新! Mickey:3D中的2D影像匹配SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大學最新! Mickey:3D中的2D影像匹配SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
寫在前面項目連結:https://nianticlabs.github.io/mickey/給定兩張圖片,可以透過建立圖片之間的對應關係來估計它們之間的相機姿態。通常,這些對應關係是二維到二維的,而我們估計的姿態在尺度上是不確定的。一些應用,例如隨時隨地實現即時增強現實,需要尺度度量的姿態估計,因此它們依賴外部的深度估計器來恢復尺度。本文提出了MicKey,這是一個關鍵點匹配流程,能夠夠預測三維相機空間中的度量對應關係。透過學習跨影像的三維座標匹配,我們能夠在沒有深度測試的情況下推斷度量相對
