

MoE大模型製作指南:零基礎手打法,大神級教學揭秘
Jan 30, 2024 pm 02:42 PM傳說中GPT-4的「致勝法寶」-MoE(混合專家)架構,自己也能手搓了!
Hugging Face上有一位機器學習大神,分享如何從頭開始建立一套完整的MoE系統。

這個專案被作者叫做MakeMoE,詳細講述了從注意力建構到形成完整MoE模型的過程。
作者介紹,MakeMoE是受到OpenAI創始成員Andrej Karpathy的makemore啟發並以之為基礎編寫的。
makemore是一個針對自然語言處理和機器學習的教學項目,旨在幫助學習者理解並實現一些基本模型。
同樣,MakeMoE也是在一步一步的建構過程中,幫助學習者更深刻地理解混合專家模型。
那麼,這份「手搓攻略」具體都講了些什麼呢?
從頭開始建立MoE模型
和Karpathy的makemore相比,MakeMoE用稀疏的專家混合體取代了孤立的前饋神經網絡,同時加入了必要的門控邏輯。
同時,由於過程中需要用到ReLU激活函數,makemore中的預設初始化方式被替換成了Kaiming He方法。

想要建立一個MoE模型,首先要理解自註意力機制。
模型先透過線性變換,將輸入序列轉換成用查詢(Q)、鍵(K)和值(V)表示的參數。
這些參數隨後被用於計算注意力分數,這些分數決定了在生成每個token時,模型對序列中每個位置的關注程度。
為了確保模型在生成文本時的自回歸特性,即只能基於已經生成的token來預測下一個token,作者使用了多頭因果自註意力機制。
這個機制透過一個遮罩來實現將未處理的位置的注意力分數設為負無窮大,這樣這些位置的權重就會變成零。
多頭因果則是讓模型並行地執行多個這樣的注意力計算,每個頭關注序列的不同部分。
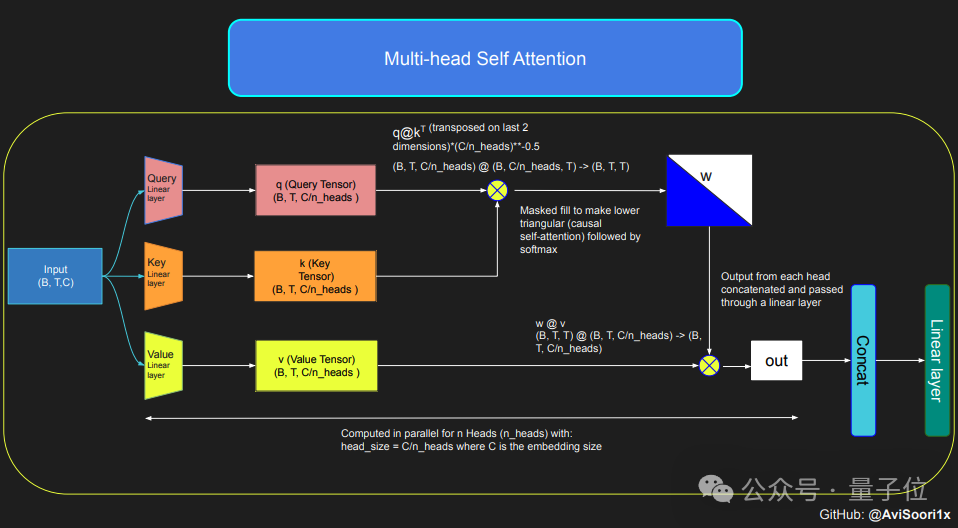
完成自註意力機制的配置後,就可以創建專家模組了,這裡的「專家模組」是一種多層感知器。
每個專家模組包含一個線性層,它將嵌入向量映射到一個更大的維度,然後透過非線性激活函數(如ReLU),再透過另一個線性層將向量映射回原始的嵌入維度。
這樣的設計使得每個專家能夠專注於處理輸入序列的不同部分,並透過門控網路來決定在產生每個token時應該啟動哪些專家。
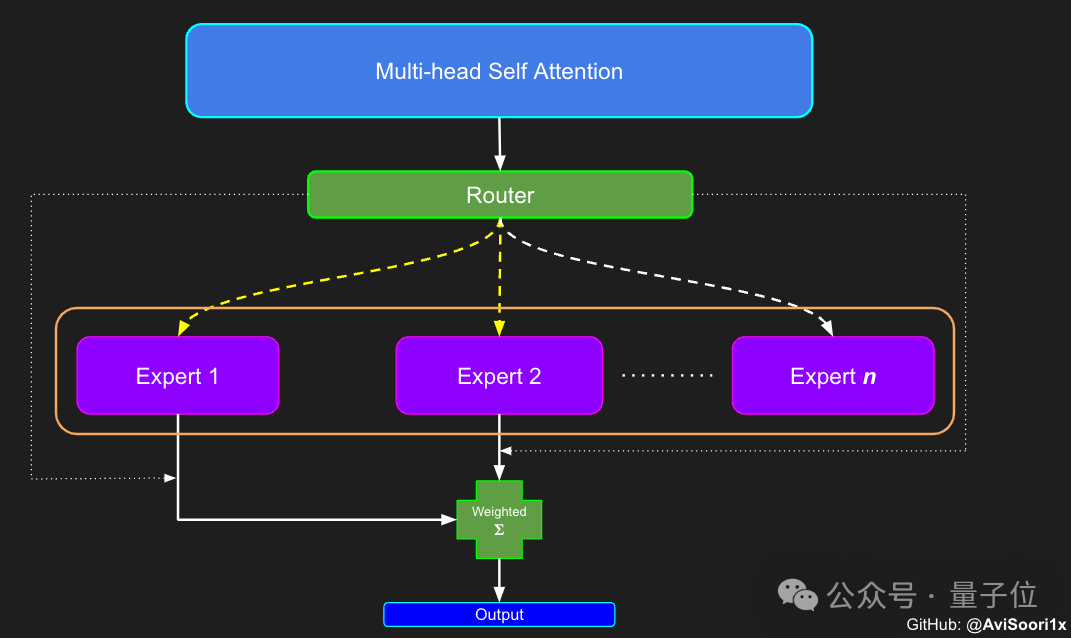
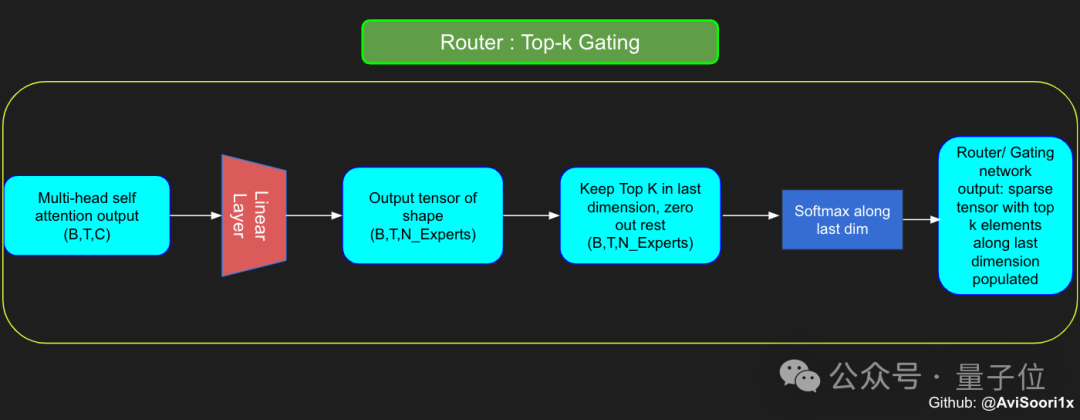
於是,接下來就要開始建構分配和管理專家的元件-門控網路。
這裡的門控網路同樣是透過一個線性層實現,該層將自註意力層的輸出映射到專家模組的數量。
這個線性層的輸出是一個分數向量,每個分數代表了對應專家模組對於目前處理的token的重要性。
門控網路會計算這個分數向量的top-k值並記錄其索引,然後從中選擇top-k個最大的分數,用來加權對應的專家模組輸出。
為了在訓練過程中增加模型的探索性,作者也引入了噪聲,避免所有token都傾向於被相同的專家處理。
這種雜訊通常透過在分數向量上添加隨機的高斯雜訊來實現。
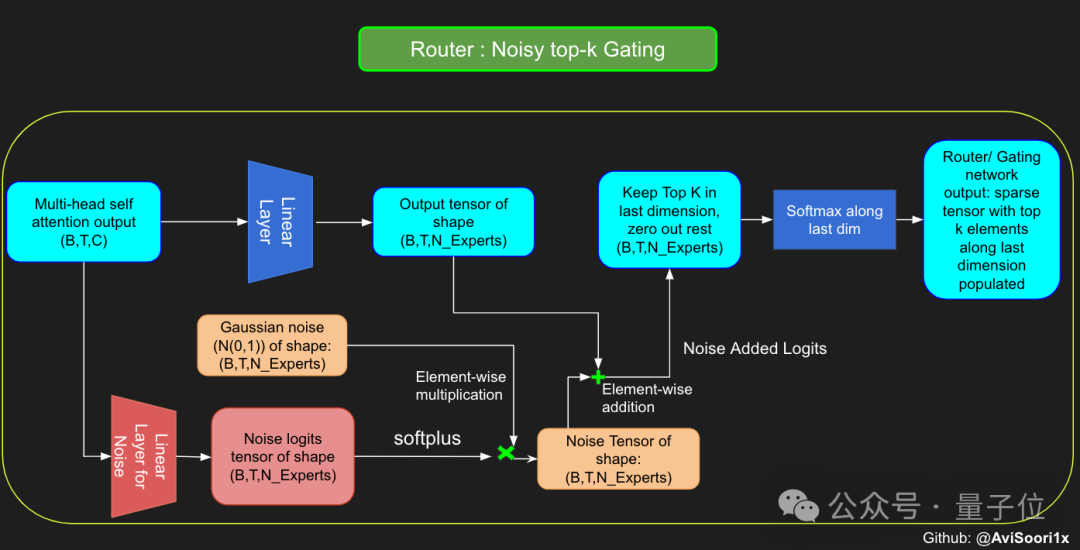
獲得結果後,模型選擇性地將前k個值與對應token的前k個專家的輸出相乘,然後相加形成加權和,構成模型的輸出。
最後,將這些模組在一起,就得到一個MoE模型了。
針對以上的整個過程,作者都提供了對應的程式碼,可以到原文中具體了解。
另外,作者也製作了端到端的Jupyter筆記,可以在學習各模組的同時直接運作。
有興趣的話,就趕快學起來吧!
原文網址:https://huggingface.co/blog/AviSoori1x/makemoe-from-scratch
筆記版本(GitHub):https://github. com/AviSoori1x/makeMoE/tree/main
以上是MoE大模型製作指南:零基礎手打法,大神級教學揭秘的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱門文章


熱門文章

熱門文章標籤

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)











