

揭露NVIDIA大模型推理架構:TensorRT-LLM

一、TensorRT-LLM 的產品定位
#TensorRT-LLM是NVIDIA為大型語言模型(LLM)所開發的可擴展推理方案。它基於TensorRT深度學習編譯框架建構、編譯和執行計算圖,並藉鑒了FastTransformer中高效的Kernels實作。此外,它還利用NCCL實現設備間的通訊。開發者可以根據技術發展和需求差異,客製化算子以滿足特定需求,例如基於cutlass開發客製化的GEMM。 TensorRT-LLM是NVIDIA官方推理方案,致力於提供高效能並不斷完善其實用性。

TensorRT-LLM在GitHub上開源,分成兩個分支:Release branch和Dev branch。 Release branch每月更新一次,而Dev branch會更頻繁地更新來自官方或社群中的功能,方便開發者體驗和評估最新功能。下圖展示了TensorRT-LLM的框架結構,除了綠色TensorRT編譯部分和涉及硬體資訊的kernels外,其他部分都是開源的。

TensorRT-LLM 也提供了類似Pytorch 的API 來降低開發者的學習成本,並提供了許多預先定義好的模型供用戶使用。

由於大語言模型的尺寸較大,可能無法在單張顯示卡上完成推理,因此TensorRT-LLM提供了兩種平行機制:Tensor Parallelism和Pipeline Parallelism,以支援多卡或多機推理。這些機制允許將模型分割成多個部分,並將其分佈在多個顯示卡或機器上進行平行計算,以提高推理效能。 Tensor Parallelism透過將模型參數分佈在不同裝置上,並同時計算不同部分的輸出來實現平行計算。而Pipeline Parallelism則將模型分割成多個階段,每個階段在不同裝置上並行計算,將輸出傳遞給下一個階段,從而實現整體

##二、TensorRT-LLM 的重要特性
TensorRT-LLM是強大的工具,具有豐富的模型支援和低精度推理功能。 首先,TensorRT-LLM支持主流的大語言模型,包括開發者完成的模型適配,例如Qwen(千問),並已納入官方支援。這意味著用戶可以輕鬆地基於這些預先定義的模型進行擴展或定制,方便快速地應用到自己的專案中。 其次,TensorRT-LLM預設採用FP16/BF16的精確推理方式。這種低精度推理不僅可以提高推理性能,還可以利用業界的量化方法進一步優化硬體吞吐。透過降低模型的精確度,TensorRT-LLM可以在不犧牲太多準確性的前提下,大幅提升推理的速度和效率。 綜上所述,TensorRT-LLM的豐富模型支援和低精度推理功能使得它成為一個非常實用的工具。無論是對於開發者或研究人員來說,TensorRT-LLM都能夠提供高效的推理解決方案,幫助他們在深度學習應用中取得更好的表現表現。

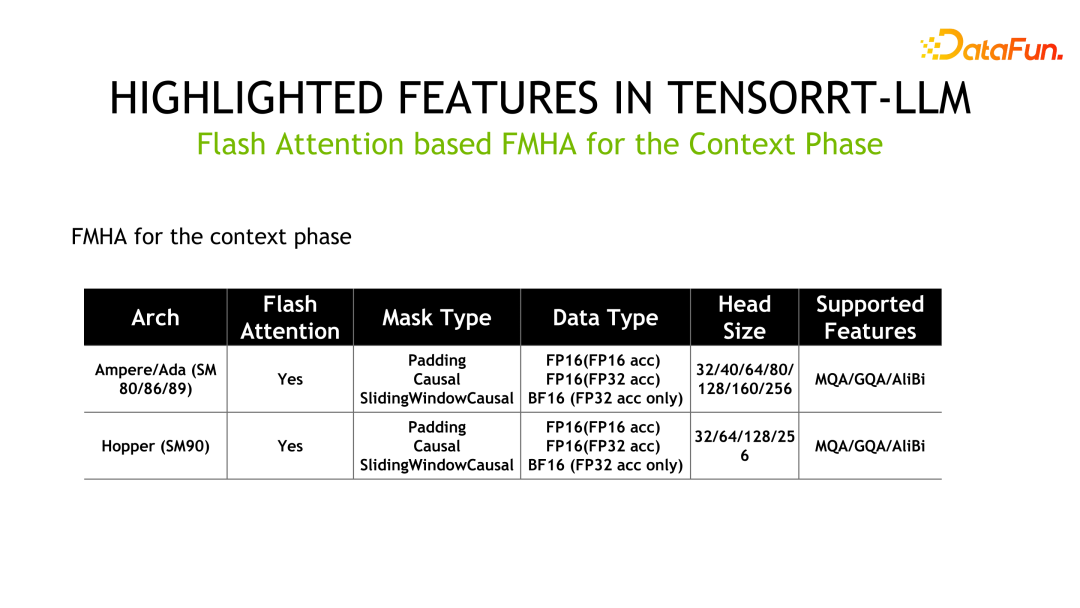
另一個特性就是 FMHA(fused multi-head attention) kernel 的實作。由於 Transformer 中最耗時的部分是 self-attention 的計算,因此官方設計了 FMHA 來優化 self-attention 的計算,並提供了累加器分別為 fp16 和 fp32 不同的版本。另外,除了速度上的提升外,對記憶體的佔用也大大降低。我們也提供了基於 flash attention 的實現,可以將 sequence-length 擴展到任意長度。

如下為 FMHA 的詳細信息,其中 MQA 為 Multi Query Attention,GQA 為 Group Query Attention。
 #
#
另外一個 Kernel 是 MMHA(Masked Multi-Head Attention)。 FMHA 主要用於 context phase 階段的計算,而 MMHA 主要提供 generation phase 階段 attention 的加速,並提供了 Volta 和之後架構的支援。相較於 FastTransformer 的實現,TensorRT-LLM 有進一步優化,效能提升高達 2x。

另一個重要特性是量化技術,以更低精度的方式實現推理加速。常用量化方式主要分為 PTQ(Post Training Quantization)和 QAT(Quantization-aware Training),對於 TensorRT-LLM 而言,這兩種量化方式的推理邏輯是相同的。對於 LLM 量化技術,一個重要的特點是演算法設計和工程實現的 co-design,也就是對應量化方法設計之初,就要考慮硬體的特性。否則,有可能達不到預期的推理速度提升。

TensorRT 中PTQ 量化步驟一般分為以下幾步,首先對模型做量化,然後對權重和模型轉化成TensorRT-LLM 的表示。對於一些客製化的操作,也需要使用者自己編寫 kernels。常用的 PTQ 量化方法包括 INT8 weight-only、SmoothQuant、GPTQ 和 AWQ,這些方法都是典型的 co-design 的方法。

INT8 weight-only 直接把權重化到 INT8,但啟動值還是保持在 FP16。此方法的好處是模型儲存2x減小,載入 weights 的儲存頻寬減半,達到了提升推理效能的目的。這種方式業界稱為 W8A16,即權重為 INT8,激活值為 FP16/BF16——以 INT8 精度存儲,以 FP16/BF16 格式計算。此方法直觀,不改變 weights,容易實現,具有較好的泛化性能。

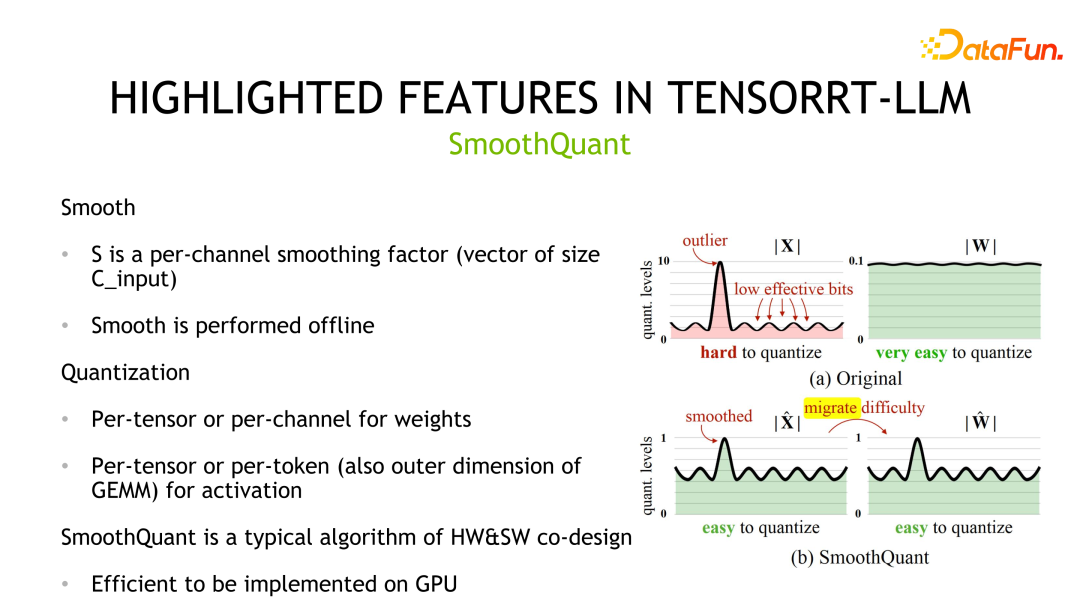
第二個量化方法是 SmoothQuant,是 NVIDIA 和社群共同設計的。它觀察到權重通常服從高斯分佈,容易量化,但是活化值存在離群點,量化比特位利用不高。

SmoothQuant 透過先對激活值做平滑操作即除以一個scale將對應分佈進行壓縮,同時為了保證等價性,需要對權重乘以相同的scale。之後,權重和活化都可以量化。對應的儲存和運算精度都可以是 INT8 或 FP8,可以利用 INT8 或 FP8 的 TensorCore 進行運算。在實作細節上,權重支援 Per-tensor 和 Per-channel 的量化,活化值支援 Per-tensor 和 Per-token 的量化。
第三個量化方法是 GPTQ,一種逐層量化的方法,透過最小化重構損失來實現。 GPTQ 屬於 weight-only 的方式,計算採用 FP16 的資料格式。此方法用在量化大模型時,由於量化本身開銷就比較大,所以作者設計了一些 trick 來降低量化本身的開銷,例如 Lazy batch-updates 和以相同順序量化所有行的權重。 GPTQ 也可以與其他方法結合如 grouping 策略。並且,針對不同的情況,TensorRT-LLM 提供了不同的實現最佳化效能。具體地,對 batch size 較小的情況,用 cuda core 實作;相對地,batch size 較大時,採用 tensor core 實作。

第四種量化方式是 AWQ。此方法認為不是所有權重都是同等重要的,其中只有 0.1%-1% 的權重(salient weights)對模型精確度貢獻較大,且這些權重取決於活化值分佈而不是權重分佈。此方法的量化過程類似 SmoothQuant,差異主要在於 scale 是基於活化值分佈計算所得的。


除了量化方式之外,TensorRT-LLM 另外一個提升效能的方式是利用多機多卡推理。在一些場景中,大模型過大無法放在單一 GPU 上推理,或者可以放下但是影響了計算效率,都需要多卡或多機進行推理。

TensorRT-LLM 目前提供了兩種平行策略,Tensor Parallelism 和 Pipeline Parallelism。 TP 是垂直地分割模型然後將各個部分置於不同的設備上,這樣會引入設備之間頻繁的資料通訊,一般用於設備之間有高度互聯的場景,如 NVLINK。另一種分割方式是橫向切分,此時只有一個橫前面,對應通信方式是點對點的通信,適合於設備通信頻寬較弱的場景。

最後一個要強調的特性是 In-flight batching。 Batching 是提高推理效能一個比較常用的做法,但在 LLM 推理場景中,一個 batch 中每個 sample/request 的輸出長度是無法預測的。如果依照靜態batching的方法,一個batch的延遲取決於 sample/request 中輸出最長的那個。因此,雖然輸出較短的 sample/request 已經結束,但是並未釋放計算資源,其時延與輸出最長的那個 sample/request 時延相同。 In-flight batching 的做法是在已經結束的 sample/request 處插入新的 sample/request。這樣,不但減少了單一 sample/request 的延遲,避免了資源浪費問題,同時也提升了整個系統的吞吐。

#三、TensorRT-LLM 的使用流程
TensorRT-LLM 與TensorRT的使用方法類似,首先需要獲得一個預先訓練好的模型,然後利用TensorRT-LLM 提供的API 對模型計算圖進行改寫和重建,接著用TensorRT 進行編譯最佳化,然後儲存為序列化的engine 進行推理部署。

以Llama 為例,先安裝TensorRT-LLM,然後下載預訓練模型,接著利用TensorRT-LLM 對模型進行編譯,最後進行推理。

對於模型推理的調試,TensorRT-LLM 的調試方式與 TensorRT 一致。由於深度學習編譯器,即 TensorRT,提供的最佳化之一是 layer 融合。因此,如果要輸出某層的結果,就需要將對應層標記為輸出層,以防止被編譯器最佳化掉,然後再與 baseline 進行比較分析。同時,每標記一個新的輸出層,都要重新編譯 TensorRT 的 engine。

對於自訂的層,TensorRT-LLM 提供了許多 Pytorch-like 算子可協助使用者實作功能而不必自己編寫 kernel。如範例所示,利用 TensorRT-LLM 提供的 API 實作了 rms norm 的邏輯,TensorRT 會自動產生 GPU 上對應的執行程式碼。

如果使用者有更高的效能需求或TensorRT-LLM 並未提供實作對應功能的building blocks,此時需要使用者自訂kernel ,並封裝為plugin 供TensorRT-LLM 使用。範例程式碼是將 SmoothQuant 定制 GEMM 實作並封裝成 plugin 後,供 TensorRT-LLM 呼叫的範例程式碼。

#四、TensorRT-LLM 的推理表現
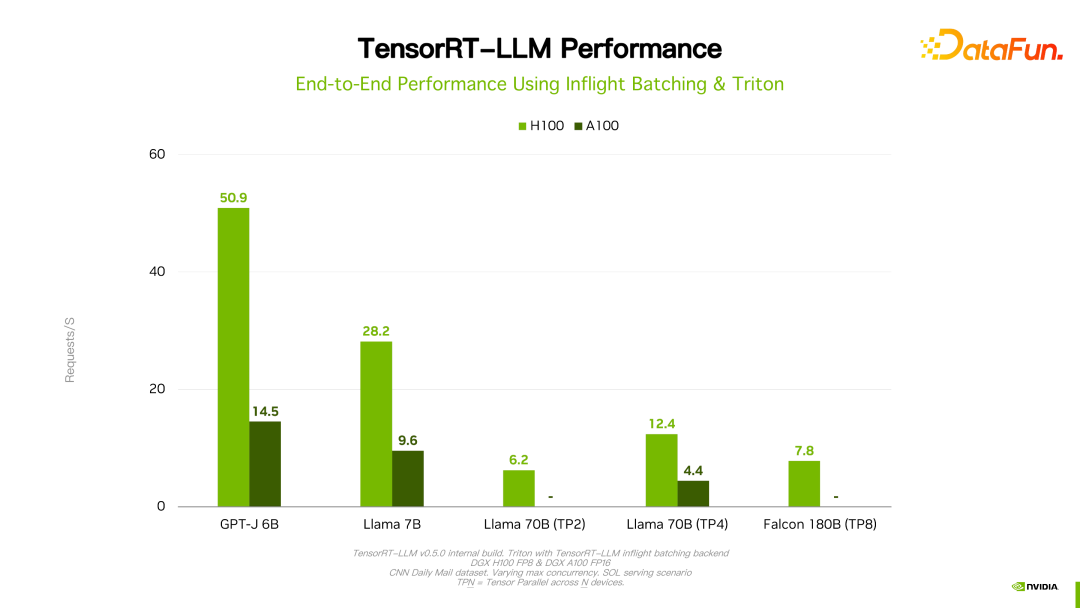
關於效能、設定等細節都可以在官網看到,在此不做詳細介紹。該產品從立項開始一直與國內許多大廠都有合作。透過回饋,一般情況下,TensorRT-LLM 從效能角度來說是目前最好的方案。由於技術迭代、最佳化手段、系統最佳化等眾多因素會影響效能,且變化非常快,這裡就不詳細展開介紹 TensorRT-LLM 的效能資料。大家如果有興趣,可以去官方了解細節,這些表現都是可重現的。
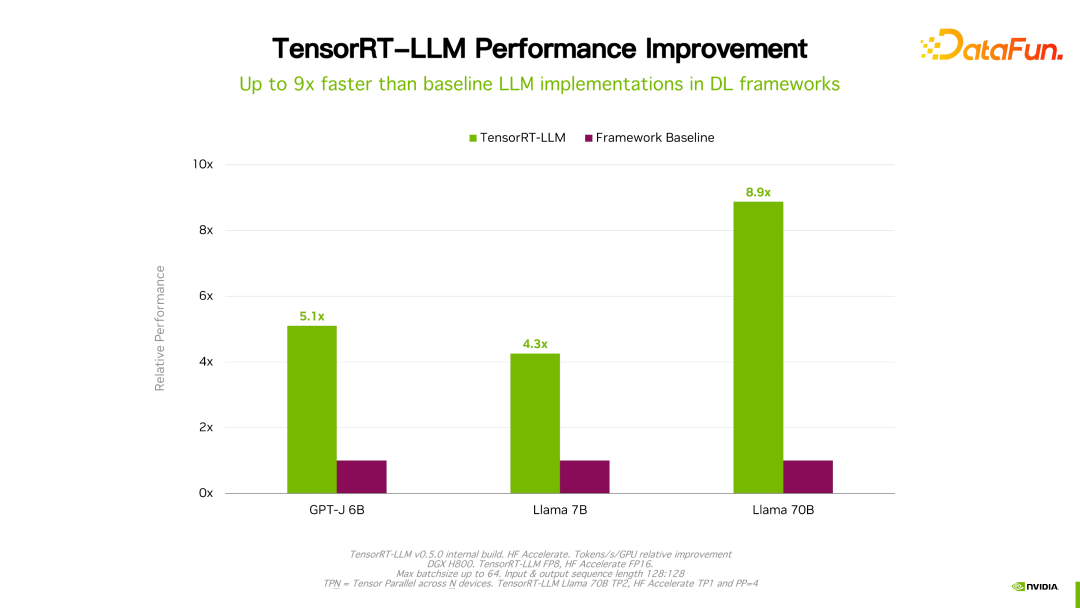
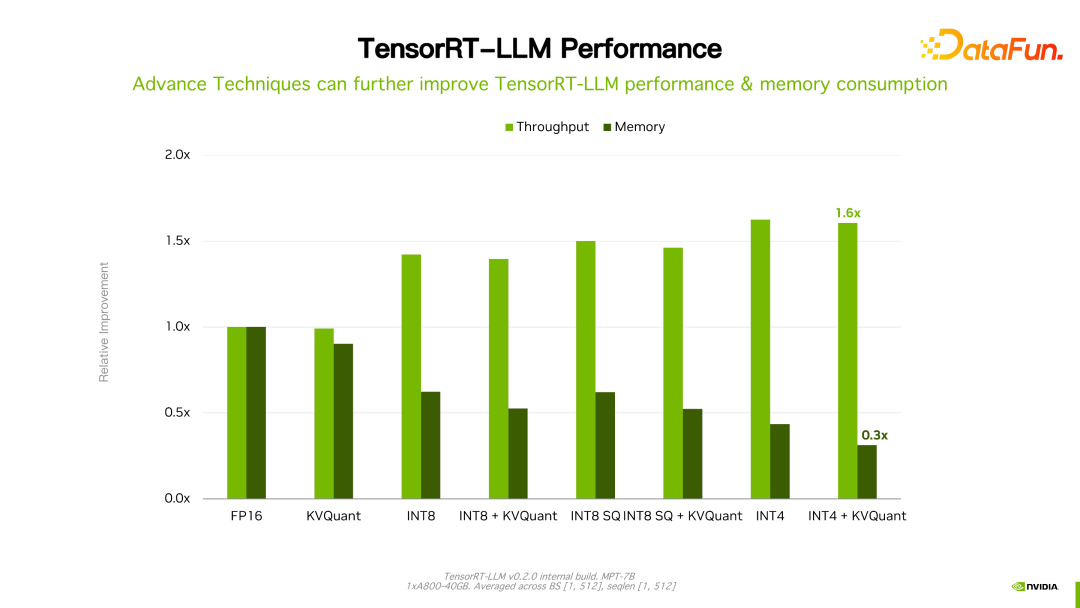
值得一提的是,TensorRT-LLM 跟自己之前的版本比,效能有持續地提升。如上圖所示,在 FP16 基礎上,採用了 KVQuant 後,速度一致的情況下降低了顯存的使用量。使用 INT8,可以看到明顯的吞吐的提升,同時顯存用量進一步降低。可見,隨著 TensorRT-LLM 最佳化技術的持續演進,效能會有持續地提升。這個趨勢會持續維持。


################################################################################################################################################。 LLM 是一個推理成本很高、成本敏感的場景。我們認為,為了實現下一個百倍的加速效果,需要演算法和硬體的共同迭代,透過軟硬體之間 co-design 來達到這個目標。硬體提供更低精度的量化,而軟體角度則利用最佳化量化、網路剪枝等演算法,進一步提升效能。 #####################TensorRT-LLM,未來 NVIDIA 會持續致力於提升 TensorRT-LLM 的效能。同時透過開源,收集回饋和意見,提高它的易用性。另外,圍繞易用性,會開發、開源更多應用工具,如 Model zone 或量化工具等,完善與主流框架的兼容性,提供從訓練到推理和部署端到端的解決方案。 ################################################################################################################## #####Q1:是否每一次計算輸出都要反量化?做量化出現精度溢出怎麼辦? ############A1:目前 TensorRT-LLM 提供了兩類方法,即 FP8 和剛才提到的 INT4/INT8 量化方法。低精確度如果 INT8 做 GEMM 時,累加器會採用高精確度資料類型,如 fp16,甚至 fp32 以防止 overflow。關於反量化,以 fp8 量化為例,TensorRT-LLM 最佳化計算圖時,可能動自動移動反量化結點,合併到其它的操作中達到最佳化目的。但對於前面介紹的 GPTQ 和 QAT,目前是透過硬編碼寫在 kernel 中,沒有統一量化或反量化節點的處理。 ############Q2:目前是針對具體模型專門做反量化嗎? ############A2:目前的量化的確是這樣,針對不同的模型做支援。我們有計劃做一個更乾淨的api或透過配置項的方式來統一支持模型的量化。 ############Q3:針對最佳實踐,是直接使用 TensorRT-LLM 還是與 Triton Inference Server 結合在一起使用?如果結合使用是否會有特性上的缺失? ############A3:因為有些功能未開源,如果是自己的 serving 需要做適配工作,如果是 triton 則是一套完整的方案。 ######
Q4:對於量化校準有幾種量化方法,加速比如何?這幾種量化方案效果損失有幾個點? In-flight branching 中每個 example 的輸出長度是不知道的,如何做動態的 batching?
A4:關於量化性能可以私下聊,關於效果,我們只做了基本的驗證,確保實現的kernel 沒問題,並不能保證所有量化算法在實際業務中的結果,因為還有些無法控制的因素,例如量化用到的資料集及影響。關於 in-flight batching,是指在 runtime 的時候去偵測、判斷某個 sample/request 的輸出是否結束。如果是,再將它到達的 requests 插進來,TensorRT-LLM 不會也無法預告預測輸出的長度。
Q5:In-flight branching 的 C 介面和 python 介面是否會保持一致? TensorRT-LLM 安裝成本高,今後是否有改進計畫? TensorRT-LLM 會和 VLLM 發展角度有不同嗎?
A5:我們會盡量提供 c runtime 和 python runtime 一致的接口,已經在規劃當中。先前團隊的重點在提升效能、完善功能上,以後在易用性方面也會不斷改善。這裡不好直接跟 vllm 的比較,但 NVIDIA 會持續加大在 TensorRT-LLM 開發、社群和客戶支援的投入,為業界提供最好的 LLM 推理方案。
以上是揭露NVIDIA大模型推理架構:TensorRT-LLM的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 比特幣誕生至今價格2009-2025 最完整的BTC歷史價格總表
Jan 15, 2025 pm 08:11 PM
比特幣誕生至今價格2009-2025 最完整的BTC歷史價格總表
Jan 15, 2025 pm 08:11 PM
自 2009 年問世以來,比特幣成為加密貨幣界的領頭羊,其價格經歷了巨大的波動。為了提供全面的歷史概述,本文匯集了從 2009 年到 2025 年的比特幣價格數據,涵蓋了重大的市場事件、市場情緒變化和影響價格走勢的重要因素。
 比特幣誕生至今歷史價格總覽 比特幣歷史價格趨勢大全
Jan 15, 2025 pm 08:14 PM
比特幣誕生至今歷史價格總覽 比特幣歷史價格趨勢大全
Jan 15, 2025 pm 08:14 PM
比特币,作为一种加密货币,自问世以来经历了显著的市场波动。本文将提供比特币自诞生以来的历史价格总览,帮助读者了解其价格趋势和关键时刻。通过分析比特币的历史价格数据,我们可以了解市场对其价值评估、影响其波动的因素,并为未来投资决策提供依据。
 比特幣誕生至今歷史價格一覽 BTC歷史價格行情趨勢圖(最新匯總)
Feb 11, 2025 pm 11:36 PM
比特幣誕生至今歷史價格一覽 BTC歷史價格行情趨勢圖(最新匯總)
Feb 11, 2025 pm 11:36 PM
比特幣自 2009 年創世以來,價格經歷多次大幅波動,最高漲至 2021 年 11 月的 69,044.77 美元,最低跌至 2018 年 12 月的 3,191.22 美元。截至 2024 年 12 月,最新價格突破 100,204 美元。
 2018-2024年比特幣最新價格美元大全
Feb 15, 2025 pm 07:12 PM
2018-2024年比特幣最新價格美元大全
Feb 15, 2025 pm 07:12 PM
實時比特幣美元價格 影響比特幣價格的因素 預測比特幣未來價格的指標 以下是 2018-2024 年比特幣價格的一些關鍵信息:
 H5頁面製作是前端開發嗎
Apr 05, 2025 pm 11:42 PM
H5頁面製作是前端開發嗎
Apr 05, 2025 pm 11:42 PM
是的,H5頁面製作是前端開發的重要實現方式,涉及HTML、CSS和JavaScript等核心技術。開發者通過巧妙結合這些技術,例如使用<canvas>標籤繪製圖形或使用JavaScript控制交互行為,構建出動態且功能強大的H5頁面。
 如何通過CSS自定義resize符號並使其與背景色統一?
Apr 05, 2025 pm 02:30 PM
如何通過CSS自定義resize符號並使其與背景色統一?
Apr 05, 2025 pm 02:30 PM
CSS自定義resize符號的方法與背景色統一在日常開發中,我們經常會遇到需要自定義用戶界面細節的情況,比如調...

 如何使用CSS的clip-path屬性實現分段器的45度曲線效果?
Apr 04, 2025 pm 11:45 PM
如何使用CSS的clip-path屬性實現分段器的45度曲線效果?
Apr 04, 2025 pm 11:45 PM
如何實現分段器的45度曲線效果?在實現分段器的過程中,如何讓點擊左側按鈕時右側邊框變成45度曲線,而點�...
