

純文字模型訓出「視覺」表徵! MIT最新研究:語言模型用程式碼就能作畫

只會「看書」的大語言模型,有現實世界的視覺感知力嗎?透過對字串之間的關係進行建模,關於視覺世界,語言模型到底能學會什麼?
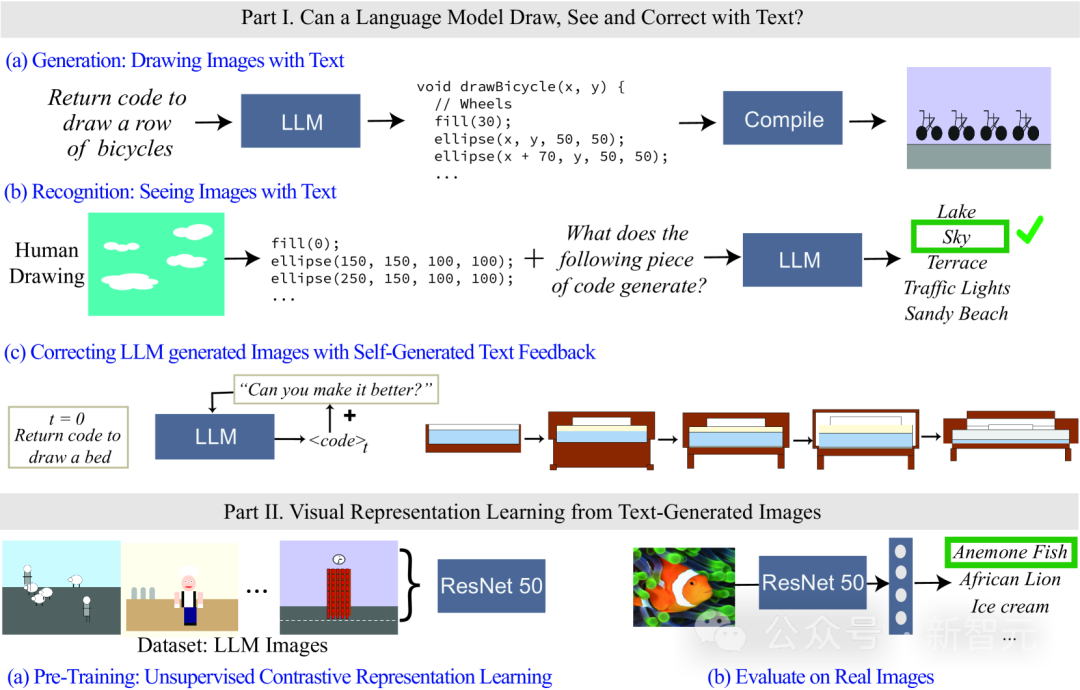
最近,麻省理工學院電腦科學與人工智慧實驗室(MIT CSAIL)的研究人員對語言模型進行了評估,重點是其視覺能力。他們透過要求模型生成和識別出越來越複雜的視覺概念,從簡單形狀和物體到複雜場景,來測試模型的能力。研究人員也展示如何使用純文字模型訓練一個初步的視覺表徵學習系統。透過這項研究,他們為進一步發展和改進視覺表徵學習系統奠定了基礎。

論文連結:https://arxiv.org/abs/2401.01862
由於語言模型無法處理視覺訊息,研究中使用程式碼渲染圖像。
儘管LLM生成的圖像可能不像自然圖像那樣逼真,但從生成結果和模型的自我糾正來看,它能夠準確地建模字串/文本,這使得語言模型能夠學習關於視覺世界中的許多概念。
研究人員也研究了利用文字模型產生的圖像進行自監督視覺表徵學習的方法。結果顯示,這種方法有潛力用於訓練視覺模型,並且僅使用LLM就可以對自然圖像進行語義評估。
語言模型的視覺概念
先問一個問題:對人來說,理解「青蛙」的視覺概念意味著什麼?
知道它皮膚的顏色、有多少腳、眼睛的位置、跳躍時的樣子等細節就足夠了嗎?
人們通常認為要理解青蛙的概念,需要觀察青蛙的圖像,並從多個角度和真實場景中觀察。
如果只觀察文本的話,可以多大程度上理解不同概念的視覺意義?
換到模型訓練角度來看,大型語言模型(LLM)的訓練輸入就只有文字數據,但模型已經被證明可以理解有關形狀、顏色等概念的信息,甚至還能透過線性轉換到視覺模型的表徵中。
也就是說,視覺模型和語言模型在世界表徵上是很相似的。
但現有的關於模型表徵方法大多基於一組預先選擇的屬性集合來探索模型編碼哪些訊息,這種方法無法動態擴展屬性,而且還需要存取模型的內部參數。
所以研究者提出了兩個問題:
1、關於視覺世界,語言模型到底了解多少?
2、能否「只用文字模型」訓練出一個可用於自然圖像的視覺系統?
為了找到答案,研究人員透過測試不同語言模型在渲染(render, 即draw)和識別(recognize, 即see)真實世界的視覺概念,來評估哪些資訊包含在模型中,從而實現了測量任意屬性的能力,而無需針對每個屬性單獨訓練特徵分類器。
雖然語言模型無法產生圖像,但像GPT-4等大模型可以產生出渲染物體的程式碼,文中透過textual prompt -> code -> image的過程,逐步增加渲染物體的難度來測量模型的能力。
研究人員發現LLM在產生由多個物件組成的複雜視覺場景方面出奇的好,可以有效地對空間關係進行建模,但無法很好地捕捉視覺世界,包括物體的屬性,如紋理、精確的形狀,以及與影像中其他物體的表面接觸等。
文中也評估LLM識別感知概念的能力,輸入以程式碼表示的繪畫,程式碼包含形狀的序列、位置和顏色,然後要求語言模型回答程式碼中所描述的視覺內容。

實驗結果發現,LLM與人類正好相反:對人來說,寫程式碼的過程很難,但驗證圖像內容很容易;而模型則是很難解釋/辨識出程式碼的內容,但卻可以產生複雜場景。
此外,研究結果也證明了語言模型的視覺生成能力可以透過文字糾錯(text-based corrections)來進一步改善。
研究人員先使用語言模型來產生說明概念的程式碼,然後不斷輸入提示「improve its generated code」(改善產生的程式碼)作為條件來修改程式碼,最終模型可以透過這種迭代的方式來改善視覺效果。

視覺能力資料集:指向場景
#研究人員建立了三個文字描述資料集來測量模型在創建、辨識並修改影像渲染程式碼的能力,其複雜度從低到高分別為簡單的形狀及組合、物件和複雜的場景。

#1. 圖形及其組成(Shapes and their compositions)
包含來自不同類別的形狀組成,如點、線、2D形狀和3D形狀,具有32種不同的屬性,如顏色、紋理、位置和空間排列。
完整的資料集包含超過40萬個範例,使用其中1500個樣本進行實驗測試。
2. 物體(Objects)
#包含ADE 20K資料集的1000個最常見的物體,生成和辨識的難度更高,因為包含更多形狀的複雜的組合。
3. 場景(Scenes)
#由複雜的場景描述組成,包括多個物件以及不同位置,從MS-COCO資料集中隨機均勻抽樣1000個場景描述得到。
資料集中的視覺概念都是用語言進行描述的,例如場景描述為「一個陽光明媚的夏日,在海灘上,有著蔚藍的天空和平靜的海洋」 (a sunny summer day on a beach, with a blue sky and calm ocean)。
在測試過程中,要求LLM根據所描繪的場景來產生程式碼並編譯渲染圖像。
實驗結果
評估模型的任務主要由三個:
1. 產生/繪製文字:評估LLM在產生對應於特定概念的圖像渲染程式碼方面的能力。
2. 辨識/檢視文字:測試LLM在辨識以程式碼表示的視覺概念和場景方面的表現。我們測試每個模型上的人類繪畫的程式碼表示。
3. 使用文字回饋修正繪圖:評估LLM使用自身產生的自然語言回饋迭代修改其產生程式碼的能力。
測試中模型輸入的提示為:write code in the programming language [programming language name] that draws a [concept]
#然後根據模型的輸出程式碼進行編譯並渲染,對生成圖像的視覺品質和多樣性進行評估:
1. 忠實度(Fidelity)
透過檢索影像的最佳描述來計算產生的影像與真實描述之間的忠實度。首先使用CLIP分數計算每個影像與同一類別(形狀/物體/場景)中所有潛在描述之間的一致性,然後以百分比報告真實描述的排序(例如,得分100%意味著真實概念排名第一) 。
2. 多樣性(Diversity)
#為了評估模型渲染不同內容的能力,在代表相同視覺概念的圖像對上使用LPIPS多樣性得分。
3. 逼真度(realism)
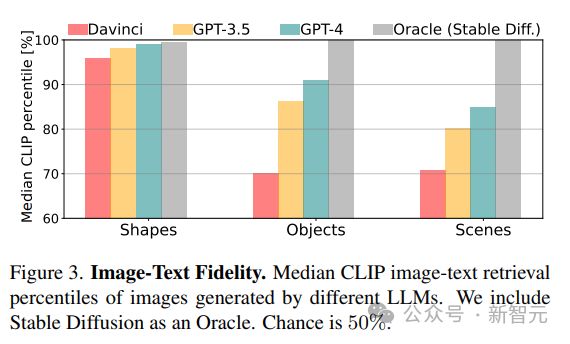
意料之中的是,從CLIP分數結果來看,模型的能力會隨著從形狀到場景的概念複雜性的增加而下降。
對於更複雜的視覺概念,例如繪製包含多個物件的場景,GPT-3.5和GPT-4在使用processing和tikz繪製具有複雜描述的場景時比python-matplotlib和python-turtle更準確。
對於物件和場景,CLIP分數顯示包含「人」,「車輛」和「戶外場景」的概念最容易繪製,這種渲染複雜場景的能力來自於渲染程式碼的表現力,模型在每個場景中的編程能力,以及所涉及的不同概念的內部表徵品質。
LLM不能視覺化什麼?
在某些情況下,即使是相對簡單的概念,模型也很難繪製,研究人員總結了三種常見的故障模式:1. 語言模型無法處理一組形狀和特定空間組織(space organization)的概念;
2. 繪畫粗糙,缺乏細節,最常出現在Davinci中,尤其是在使用matplotlib和turtle編碼時;
#3. 描述是不完整的、損壞的,或只表示某個概念的子集(典型的場景類別)。
4. 所有模型都無法畫出數字。

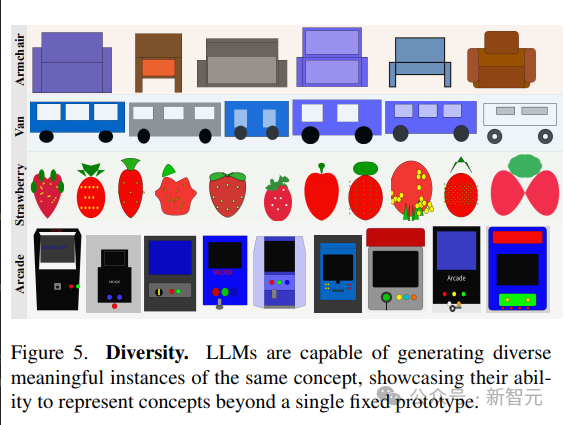
多樣性和逼真度
#語言模型展示了產生相同概念的不同視覺化的能力。
為了產生相同場景的不同樣本,文中比較了兩種策略:1. 從模型中重複取樣;
2. 對參數化函數進行取樣,此參數化函數允許透過更改參數來建立概念的新繪圖。
模型呈現視覺概念的多樣化實現的能力反映在高LPIPS多樣性分數中;生成不同圖像的能力表明,LLM能夠以多種方式表示視覺概念,而不限於一組有限的原型。
 LLM產生的圖像遠不如自然圖像真實,與Stable Diffusion相比,模型在FID指標上得分很低,但現代模型的性能比舊模型更好。
LLM產生的圖像遠不如自然圖像真實,與Stable Diffusion相比,模型在FID指標上得分很低,但現代模型的性能比舊模型更好。
從文本中學習視覺系統
訓練和評估研究人員使用無監督學習得到的預訓練視覺模型作為網路骨幹,使用MoCo-v2方法在LLM生成的130萬384×384影像資料集上訓練ResNet-50模型,總共200個epoch;訓練後,使用兩種方法評估在每個資料集上訓練的模型的效能:
#########1. 在ImageNet-1 k分類的凍結主幹上訓練線性層100 epoch,########### ##2. 在ImageNet-100上使用5-最近鄰(kNN)檢索。 #####################從結果可以看到,僅使用LLM產生的資料訓練得到的模型,就可以為自然影像提供強大的表徵能力,而無需再訓練線性層。 ###############結果分析################研究人員將LLM產生的圖像與現有程式產生的圖像進行對比,包括簡單的生成程序,如dead-levaves,fractals和StyleGAN,以產生高度多樣化的圖像。
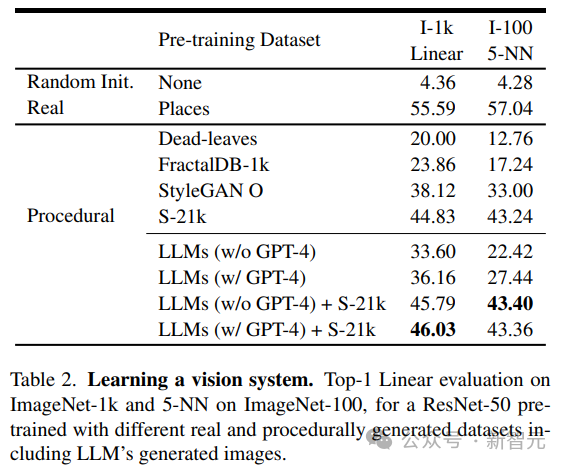
從結果來看,LLM方法要優於dead-levaves和fractals,但還不是sota;在對資料進行人工檢查後,研究人員將這種劣效性(inferiority)歸因於大多數LLM生成的圖像中缺乏紋理。
為了解決這個問題,研究人員將機Shaders-21k資料集與從LLM獲得的樣本結合以產生紋理豐富的影像。
從結果可以看到,該方案可以大幅提升效能,並且優於其他基於程式產生的方案。
以上是純文字模型訓出「視覺」表徵! MIT最新研究:語言模型用程式碼就能作畫的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 虛擬幣十大交易平台有哪些?全球十大虛擬幣交易平台排行
Feb 20, 2025 pm 02:15 PM
虛擬幣十大交易平台有哪些?全球十大虛擬幣交易平台排行
Feb 20, 2025 pm 02:15 PM
隨著加密貨幣的普及,虛擬幣交易平台應運而生。全球十大虛擬幣交易平台根據交易量和市場份額排名如下:幣安、Coinbase、FTX、KuCoin、Crypto.com、Kraken、Huobi、Gate.io、Bitfinex、Gemini。這些平台提供各種服務,從廣泛的加密貨幣選擇到衍生品交易,適合不同水平的交易者。
 芝麻開門交易所怎麼調成中文
Mar 04, 2025 pm 11:51 PM
芝麻開門交易所怎麼調成中文
Mar 04, 2025 pm 11:51 PM
芝麻開門交易所怎麼調成中文?本教程涵蓋電腦、安卓手機端詳細步驟,從前期準備到操作流程,再到常見問題解決,幫你輕鬆將芝麻開門交易所界面切換為中文,快速上手交易平台。
 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap 圖片居中方法多樣,不一定要用 Flexbox。如果僅需水平居中,text-center 類即可;若需垂直或多元素居中,Flexbox 或 Grid 更合適。 Flexbox 兼容性較差且可能增加複雜度,Grid 則更強大且學習成本較高。選擇方法時應權衡利弊,並根據需求和偏好選擇最適合的方法。
 十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台包括:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
C35 的計算本質上是組合數學,代表從 5 個元素中選擇 3 個的組合數,其計算公式為 C53 = 5! / (3! * 2!),可通過循環避免直接計算階乘以提高效率和避免溢出。另外,理解組合的本質和掌握高效的計算方法對於解決概率統計、密碼學、算法設計等領域的許多問題至關重要。
 十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 安全的虛擬幣軟件app推薦 十大數字貨幣交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虛擬幣軟件app推薦 十大數字貨幣交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虛擬幣軟件app推薦:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
