

Warning!遠距離LiDAR感知

一、引言
去年舉辦了圖森AI Day後,一直有個念頭,想以文字形式概述一下我們在遠距離感知方面的工作。最近剛好有時間,於是決定寫一篇文章,記錄這幾年的研究歷程。本文所涉及的內容都可以在圖森AI Day的影片[0]和我們公開發表的論文中找到,但並不包含具體的工程細節或技術秘密。
眾所周知,圖森專注於卡車自動駕駛技術。與轎車相比,卡車的煞車距離和變換車道時間更長。因此,圖森在與其他自動駕駛公司的競爭中擁有獨特的優勢。身為圖森的一員,我負責LiDAR感知技術,現在我將詳細介紹使用LiDAR進行遠距離感知的相關內容。
在公司剛加入時,主流的LiDAR感知方案通常是BEV(Bird's Eye View)方案。然而,這裡的BEV並不是大家所熟知的電動車(Battery Electric Vehicle)的縮寫,而是指將LiDAR點雲投影到BEV空間下,並結合2D卷積和2D檢測頭進行目標檢測的方案。我個人認為,特斯拉所採用的LiDAR感知技術應該被稱為「多視角相機在BEV空間下的融合技術」。 據我所查,最早關於BEV方案的紀錄是百度在CVPR17會議上發表的論文《MV3D》[1]。隨後的許多研究工作,包括我所了解的許多公司實際使用的方案,都採用將LiDAR點雲投影到BEV空間進行目標檢測的方法,並可歸類為BEV方案。這種方案在實際應用中被廣泛採用。 總結一下,剛加入公司時,主流的LiDAR感知方案通常是將LiDAR點雲投影到BEV空間下,然後結合2D卷積和2D偵測頭進行目標偵測。特斯拉所採用的LiDAR感知技術可以稱為「多視角相機在BEV空間下的融合技術」。百度在CVPR17會議上發表的論文《MV3D》是關於BEV方案的早期記錄,隨後許多公司也採用了類似的方案進行目標檢測。
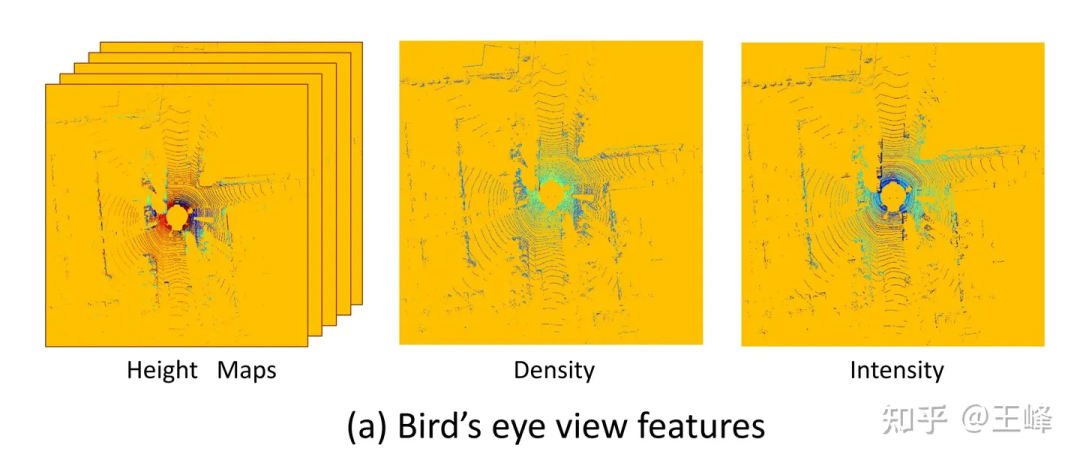 MV3D[1]使用的BEV視角特徵
MV3D[1]使用的BEV視角特徵
BEV方案的一大優點是可以直接套用成熟的2D偵測器,但也有一個很致命的缺點:它限制住了感知範圍。從上圖可以看到,因為要套2D偵測器,它必須形成一個2D的feature map,此時就必須為它設定一個距離閾值,而在上圖範圍之外其實也還是有LiDAR點的,只是被這個截斷操作給丟棄了。那可不可以把這個距離門檻拉大,直到包包住所有點呢?硬要這麼做也不是不行,只是LiDAR在掃描模式、反射強度(隨距離呈4次方衰減)、遮擋等問題作用下,遠處的點雲是非常少的,這麼做很不划算。
學術界對於BEV方案的這個問題並沒有引起太多關注,主要原因是資料集的限制。目前主流資料集的標註範圍通常只有不到80公尺(如nuScenes的50公尺、KITTI的70公尺和Waymo的80公尺),在這個距離範圍內,BEV特徵圖的尺寸並不需要很大。然而,在工業界,使用的中距離LiDAR普遍能夠達到200公尺的掃描範圍,而近年來也有一些遠距離LiDAR問世,它們能夠實現500公尺的掃描範圍。需要注意的是,特徵圖的面積和計算量隨著距離的增加而呈現二次方成長。在BEV方案下,處理200公尺範圍的計算量已經相當龐大,更不用說處理500公尺範圍的情況了。因此,這個問題需要在工業界中得到更多的關注和解決。
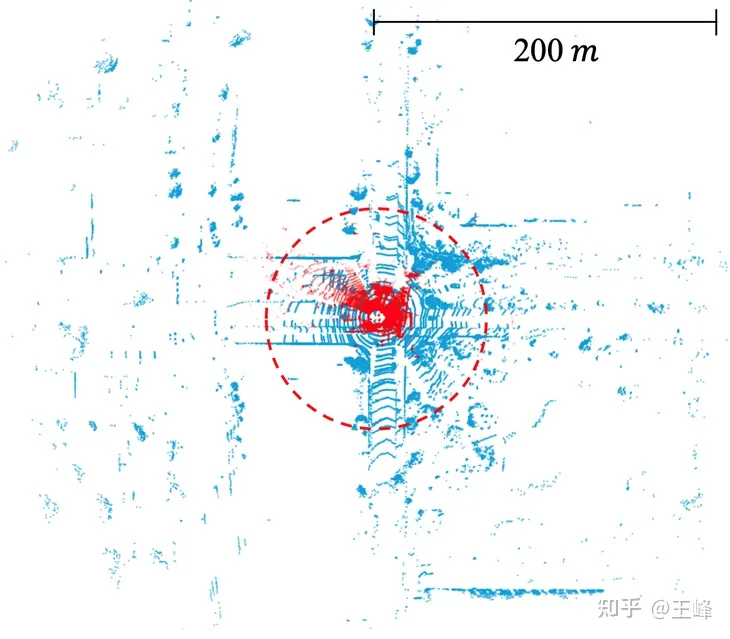
公開資料集中雷射雷達的掃描範圍。 KITTI(紅點, 70m) vs. Argoverse 2 (藍點, 200m)
在認識到BEV方案的限制之後,我們經過多年的研究,最終找到了一個可行的替代方案。研究過程並非一帆風順,我們經歷了許多次挫折。一般情況下,論文和報告只會強調成功而不提及失敗,但失敗的經驗同樣是非常寶貴的。因此,我們決定透過部落格來分享我們的研究歷程。接下來,我將按時間軸逐步敘述。
二、Point-based方案
在CVPR19上,香港中文發表了一項名為PointRCNN[2]的點雲偵測器。與傳統方法不同,PointRCNN直接在點雲資料上進行運算,而不需要轉換為BEV(鳥瞰圖)形式。因此,這種基於點雲的方案理論上可以實現遠距離感知。
但我們試吃發現了一個問題,KITTI一幀的點雲數量可以降採樣到1.6萬個點來檢測而不怎麼掉點,但我們的LiDAR組合一幀有10多萬個點,如果降採樣10倍顯然偵測精度會大幅受影響。而如果不降採樣的話,在PointRCNN的backbone中甚至有O(n^2)的操作,導致它雖然不拍bev,但計算量仍然無法承受。這些比較耗時的op主要是因為點雲本身的無序性,導致不論是降採樣還是檢索鄰域,都必須遍歷所有的點。由於涉及的op較多且都是沒有經過優化的標準op,短期內感覺也沒有能優化到實時的希望,所以這條路線就放棄了。
不過這段研究也並沒有浪費,雖然backbone計算量過大,但它的二階段因為只在前景上進行,所以計算量還是比較小的。把PointRCNN的二階段直接套用在BEV方案的一階段偵測器之後,偵測框的準確度會有比較大的提升。在應用過程中我們也發現了它的一個小問題,解決之後總結發表成了一篇文章[3]發表在了CVPR21上,大家也可以到這篇博客上看看:
王峰:LiDAR R-CNN:快速、通用的二階段3D檢測器
三、Range-View方案
在Point-based方案嘗試失敗之後,我們將目光轉向了Range View,當年的LiDAR都是機械旋轉式的,例如64線雷射雷達就會掃描出64行具有不同俯仰角的點雲,例如每行都掃描到2048個點的話,就可以形成一張64*2048的range image。
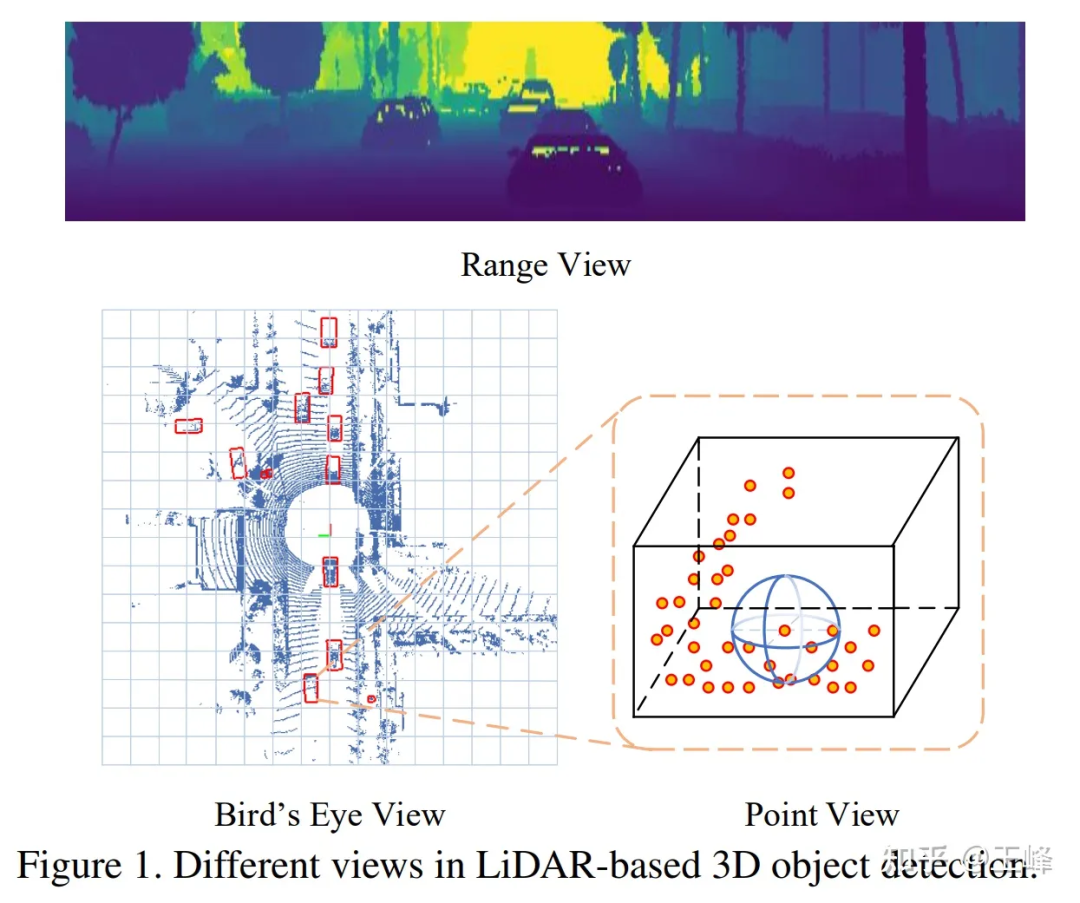 RV、BEV、PV的對比
RV、BEV、PV的對比
在Range View下,點雲不再是稀疏的形式而是緻密地排列在一起,遠距離的目標在range image上只是比較小,但並不會被丟掉,所以理論上也是能被偵測到的。
可能是因為與圖像更相似,對於RV的研究其實比BEV還早,我能找到的最早記錄也是來自於百度的論文[4],百度真的是自動駕駛的黃埔軍校啊,不論是RV或BEV的最早應用都來自於百度。
於是當時我就隨手試了一把,結果跟BEV方法相比,RV的AP狂掉30-40個點...我發現其實在2d的range image上檢測得還可以,但輸出出來的3d框效果就差了。當時分析RV的特性,感覺它具備影像的所有缺點:物體尺度不統一、前背景特徵混雜、遠距離目標特徵不明顯,但又不具備影像語意特徵豐富的優勢,所以當時對這個方案比較悲觀。
因為正式員工畢竟還是要做落地的工作,對於這種探索性問題還是交給實習生比較好。後來招了兩位實習生一起來研究這個問題,在公開資料集上一試,果然也是掉了30個點...還好兩位實習生比較給力,透過一系列的努力,還有參考其他論文修正了一些細節之後,將點數刷到了跟主流BEV方法差不多的水平,最終論文發表在了ICCV21上[5]。
雖然點數刷上來了,但問題並沒有被徹底解決,當時lidar需要多幀融合來提高信噪比的做法已經成為共識,遠距離目標因為點數少,更加需要疊幀來增加資訊量。在BEV方案裡,多幀融合非常簡單,直接在輸入點雲上加上一個時間戳然後多幀疊加起來,整個網路都不用改動就可以漲點,但在RV下變換了很多花樣都沒有得到類似的效果。
並且在這個時候,LiDAR從硬體的技術方案上也從機械旋轉式走向了固態/半固態的方式,大部分固態/半固態的LiDAR不再能夠形成range image,強行構造range image會損失訊息,所以這條路徑最後也是被放棄了。
四、Sparse Voxel方案
先前說過Point-based方案的問題在於點雲不規整的排列使得降採樣和鄰域檢索等問題需要遍歷所有點雲導致運算量過高,而BEV方案下資料規整了但又有太多空白區域導致運算量過高。這兩者結合一下,在有點的地方進行voxelization使其變得規整,而沒點的地方不進行表達來防止無效計算似乎也是一條可行的路徑,這也就是sparse voxel方案。
因為SECOND[6]的作者髕岩加入了圖森,所以我們在早期就曾經嘗試過sparse conv的backbone,但因為spconv並不是一個標準的op,自己實現出來的spconv仍然過慢,不足以即時進行檢測,有時甚至慢於dense conv,所以就暫時擱置了。
後來第一款能掃描500m的LiDAR:Livox Tele15到貨,遠距離LiDAR感知演算法迫在眉睫,嘗試了一下BEV的方案實在是代價太高,就又把spconv的方案拿出來試了一下,因為Tele15的fov比較窄,而且在遠處的點雲也非常稀疏,所以spconv勉強是可以做到即時的。
但不拍bev的話,檢測頭這塊就不能用2D檢測中比較成熟的anchor或者center assign了,這主要是因為lidar掃描的是物體的表面,中心位置並不一定有點(如下圖所示),沒有點自然也無法assign上前景目標。其實我們在內部嘗試了很多種assign方式,這裡就不細講公司實際使用的方式了,實習生在之後也嘗試了一種assign方案發表在了NIPS2022上[7],可以看看他寫的解讀:
明月不諳離苦:全稀疏的3D物件偵測器
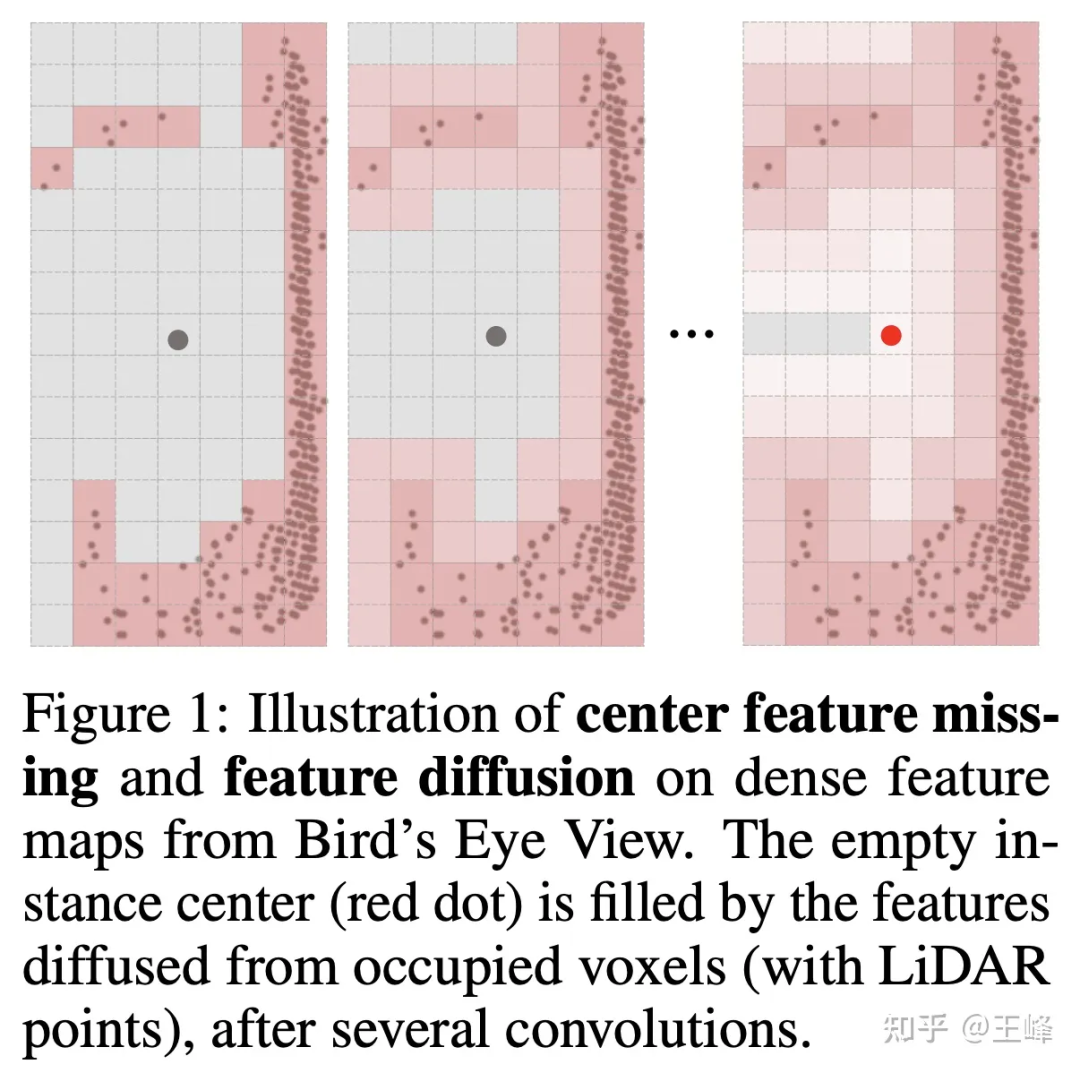
但如果要把這個演算法應用在向前500m,向後和左右各150m的LiDAR組合下,還是力有不抓。剛好實習生之前追熱度曾經也藉鑒Swin Transformer的思想做過一篇Sparse Transformer的文章[8],也是費了好大的功夫從掉20多個點一點點刷起來(感謝實習生帶飛,tql ),當時覺得Transformer的方法還是很適合不規律的點雲資料的,所以在公司資料集上也試了一下。
可惜的是,這個方法在公司資料集上一直刷不過BEV類方法,差了接近5個點的樣子,現在回想起來可能還是有一些trick或者訓練技巧沒有掌握,按理說Transformer的表達能力是不弱於conv的,但後來也沒有再繼續嘗試。不過這個時候已經對assign方式進行了優化降低了很多計算量,所以就想再嘗試一把spconv,結果令人驚訝的是,直接把Transformer替換為spconv就可以做到近距離與BEV類方法的精度相當,同時還能偵測遠距離目標的效果了。
也是在這個時候,髕岩同學做出了第二版spconv[9],速度有了大幅提升,所以計算延遲不再是瓶頸,終於遠距離的LiDAR感知掃清了所有障礙,能夠在車上即時地跑起來了。
後來我們更新了LiDAR排列方式,將掃描範圍提升到了向前500m,向後300m,向左向右各150m,這套演算法也運作良好,相信隨著未來算力的不斷提升,計算延遲會越來越不成問題。
下面展示一下最終的遠距離偵測效果,大家也可以看看圖森ai day的影片的01:08:30左右的位置看一下動態的偵測效果:
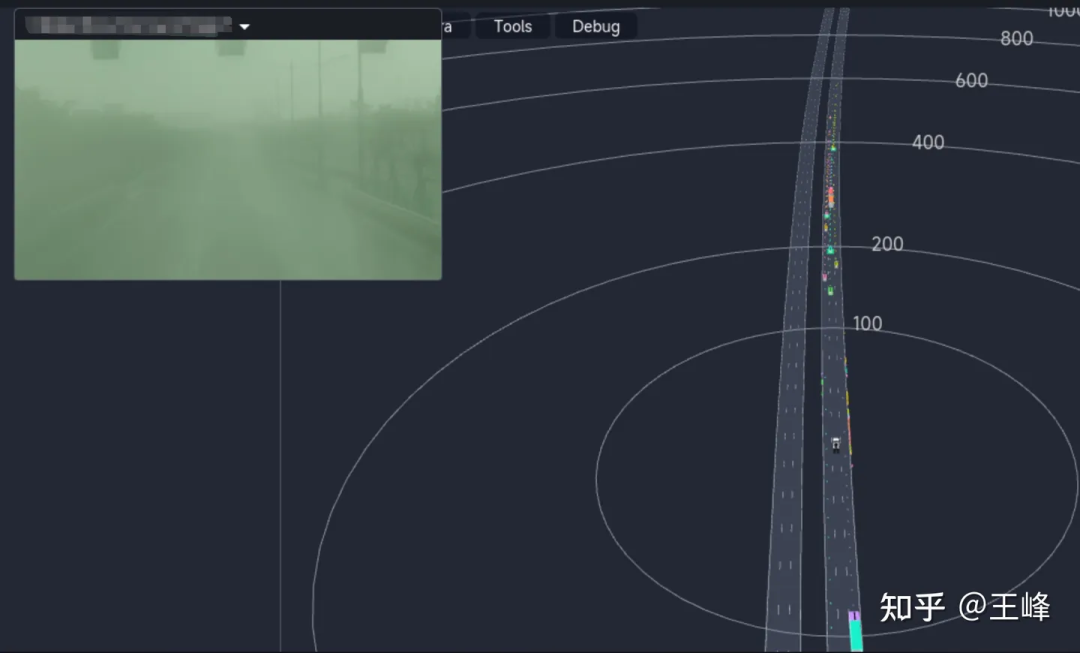
雖然是最終的融合結果,但因為這天起霧影像能見度很低,所以結果基本上都來自於LiDAR感知。
五、後記
從point-based方法,到range image方法,再到基於sparse voxel的Transformer和sparse conv方法,對於遠距離感知的探索不能說是一帆風順,簡直就是滿路荊棘。最後其實也是隨著算力的不斷提升加上許多同事的不斷努力才做到了今天這一步。在此感謝圖森首席科學家王乃岩和圖森的各位同事、實習生們,這裡面大部分的idea和工程實現都不是我做出來的,很慚愧,更多地是起到了承上啟下的作用。
很久不寫這麼長的文章了,寫得跟個流水帳似的而沒有形成一個動聽的故事。近年來,堅持做L4的同行越來越少,L2的同行們也逐漸轉向純視覺的研究,LiDAR感知肉眼可見地逐步被邊緣化,雖然我仍然堅信多一種直接測距的傳感器是更好的選擇,但業內人士似乎越來越不這麼認為。看著新鮮血液們的履歷上越來越多的BEV、Occupancy,不知道LiDAR感知還能再撐多久,我又能撐多久,寫這麼一篇文章也是起到一個紀念作用吧。
深夜涕零,不知所云,見諒。
以上是Warning!遠距離LiDAR感知的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 虛擬幣十大交易平台有哪些?全球十大虛擬幣交易平台排行
Feb 20, 2025 pm 02:15 PM
虛擬幣十大交易平台有哪些?全球十大虛擬幣交易平台排行
Feb 20, 2025 pm 02:15 PM
隨著加密貨幣的普及,虛擬幣交易平台應運而生。全球十大虛擬幣交易平台根據交易量和市場份額排名如下:幣安、Coinbase、FTX、KuCoin、Crypto.com、Kraken、Huobi、Gate.io、Bitfinex、Gemini。這些平台提供各種服務,從廣泛的加密貨幣選擇到衍生品交易,適合不同水平的交易者。
 芝麻開門交易所怎麼調成中文
Mar 04, 2025 pm 11:51 PM
芝麻開門交易所怎麼調成中文
Mar 04, 2025 pm 11:51 PM
芝麻開門交易所怎麼調成中文?本教程涵蓋電腦、安卓手機端詳細步驟,從前期準備到操作流程,再到常見問題解決,幫你輕鬆將芝麻開門交易所界面切換為中文,快速上手交易平台。
 Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap圖片居中需要用到flexbox嗎
Apr 07, 2025 am 09:06 AM
Bootstrap 圖片居中方法多樣,不一定要用 Flexbox。如果僅需水平居中,text-center 類即可;若需垂直或多元素居中,Flexbox 或 Grid 更合適。 Flexbox 兼容性較差且可能增加複雜度,Grid 則更強大且學習成本較高。選擇方法時應權衡利弊,並根據需求和偏好選擇最適合的方法。
 十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台 幣圈交易平台app排行前十名推薦
Mar 17, 2025 pm 06:03 PM
十大加密貨幣交易平台包括:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
c上標3下標5怎麼算 c上標3下標5算法教程
Apr 03, 2025 pm 10:33 PM
C35 的計算本質上是組合數學,代表從 5 個元素中選擇 3 個的組合數,其計算公式為 C53 = 5! / (3! * 2!),可通過循環避免直接計算階乘以提高效率和避免溢出。另外,理解組合的本質和掌握高效的計算方法對於解決概率統計、密碼學、算法設計等領域的許多問題至關重要。
 十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025 加密貨幣交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虛擬幣交易平台2025:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠譜的數字貨幣平台:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
 安全的虛擬幣軟件app推薦 十大數字貨幣交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虛擬幣軟件app推薦 十大數字貨幣交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虛擬幣軟件app推薦:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。選擇平台時應考慮安全性、流動性、手續費、幣種選擇、用戶界面和客戶支持。
