

UCLA華人提出全新自我對弈機制! LLM自己訓練自己,效果碾壓GPT-4專家指導

合成資料已經成為了大語言模型演化之路上最重要的一塊基石了。
去年底,有網友曝出前OpenAI首席科學家Ilya多次表示LLM的發展沒有資料瓶頸,合成資料可以解決大部分問題。
 圖片
圖片
英偉達資深科學家Jim Fan在研究了最新一批論文後得出結論,他認為將合成數據與傳統遊戲和影像生成技術結合,可以讓LLM實現巨大的自我進化。
 圖片
圖片
而正式提出這個方法的論文,是由來自UCLA的華人團隊。
 圖片
圖片
論文網址:https://www.php.cn/link/236522d75c8164f90a85448456e1d1aa
他們使用自我對弈機制(SPIN)產生合成數據,並透過自我微調的方法,不依賴新的數據集,將表現較弱的LLM在Open LLM Leaderboard Benchmark上的平均分數從58.14提升至63.16。 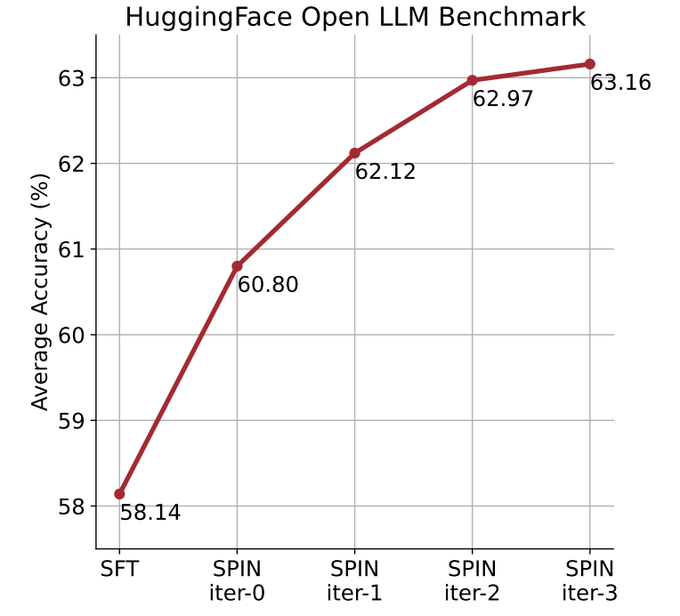
研究人員提出了一種名為SPIN的自我微調的方法,透過自我對弈的方式-LLM與其前一輪迭代版本進行對抗,從而逐步提升語言模型的效能。 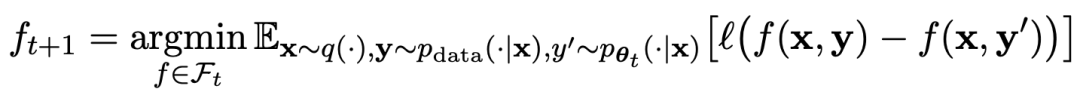
圖片
這樣就不需要額外的人類標註資料或更高階語言模型的回饋,也能完成模型的自我進化。
主模型和對手模型的參數完全一致。用兩個不同的版本進行自我對弈。
對弈過程用公式可以概括為: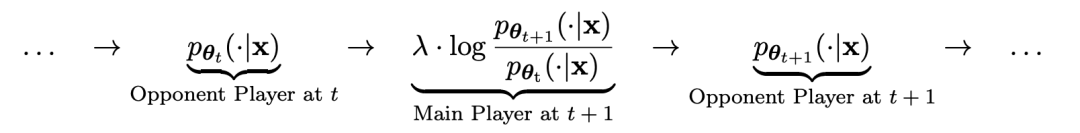
#自我對弈的訓練方式,總結起來思路大概是這樣:
透過訓練主模型來區分對手模型產生的反應和人類目標反應,對手模型是輪迭代獲得的語言模型,目標是產生盡可能難以區分的響應。
假設第t輪迭代得到的語言模型參數為θt,則在第t 1輪迭代中,使用θt作為對手玩家,針對監督微調資料集中每個prompt x,使用θt產生響應y'。
然後優化新語言模型參數θt 1,使其可以區分y'和監督微調資料集中人類響應y。如此可以形成一個漸進的過程,逐步逼近目標響應分佈。
這裡,主模型的損失函數採用對數損失,考慮y和y'的函數值差。
對手模型加入KL散度正規化,防止模型參數偏離太多。
具體的對抗賽局訓練目標如公式4.7所示。從理論分析可以看出,當語言模型的反應分佈等於目標反應分佈時,最佳化過程收斂。
如果使用對弈之後產生的合成資料進行訓練,再使用SPIN進行自我微調,能有效提升LLM的效能。 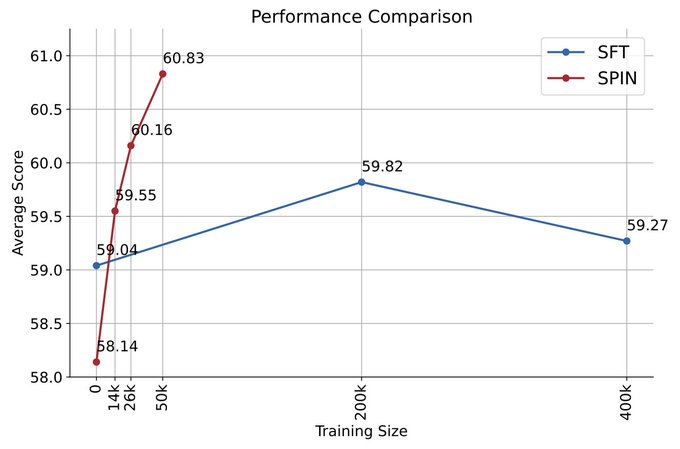
圖片
###但之後在初始的微調資料上再次簡單地微調卻又會導致效能下降。 ######而SPIN只需要初始模型本身和現有的微調資料集,就能讓LLM透過SPIN獲得自我提升。
特別是,SPIN甚至超越了透過DPO使用額外的GPT-4偏好資料訓練的模型。
 圖片
圖片
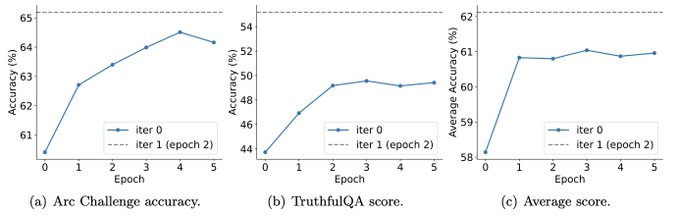
而且實驗也表明,迭代訓練比更多epoch的訓練能更有效地提升模型表現。
 圖片
圖片
延長單次迭代的訓練持續時間不會降低SPIN的效能,但會達到極限。
迭代次數越多,SPIN的效果的就越明顯。
網友在看完這篇論文之後感嘆:
#合成資料將主宰大語言模型的發展,對於大語言模型的研究者來說將會是非常好的消息!
 圖片
圖片
自我對弈讓LLM能持續提升
具體來說,研究人員所發展的SPIN系統,是由兩個相互影響的模型相互促進的系統。
用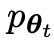 表示的前一次迭代t的LLM,研究人員使用它來產生對人工註解的SFT資料集中的提示x的回應y 。
表示的前一次迭代t的LLM,研究人員使用它來產生對人工註解的SFT資料集中的提示x的回應y 。
接下來的目標是找到一個新的LLM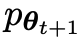 #,能夠區分
#,能夠區分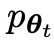 生成的反應y和人類生成的響應y'。
生成的反應y和人類生成的響應y'。
這個過程可以看作是一個兩人遊戲:
#主要玩家或新的LLM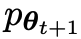 試圖辨別對手玩家的反應和人類生成的反應,而對手或舊的LLM
試圖辨別對手玩家的反應和人類生成的反應,而對手或舊的LLM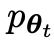 產生反應與人工註解的SFT資料集中的資料盡可能相似。
產生反應與人工註解的SFT資料集中的資料盡可能相似。
透過對舊的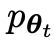 進行微調而獲得的新LLM
進行微調而獲得的新LLM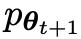 更喜歡
更喜歡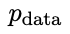 的回應,從而產生與
的回應,從而產生與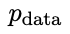 更一致的分佈
更一致的分佈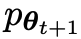 。
。
在下一次迭代中,新獲得的LLM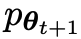 成為反應生成的對手,自我對弈過程的目標是LLM最終收斂到
成為反應生成的對手,自我對弈過程的目標是LLM最終收斂到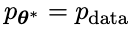 ,使得最強的LLM不再能夠區分其先前產生的反應版本和人類生成的版本。
,使得最強的LLM不再能夠區分其先前產生的反應版本和人類生成的版本。
如何使用SPIN提升模型效能
#研究人員設計了雙人遊戲,其中主要模型的目標是區分LLM產生的反應和人類生成的回應。同時,對手的作用是產生與人類的反應無法區分的反應。研究人員的方法的核心是訓練主要模型。
首先說明如何訓練主要模型來區分LLM的回覆和人類的回應。
研究人員方法的核心是自我賽局機制,其中主玩家和對手都是相同的LLM,但來自不同的迭代。
更具體地說,對手是上一次迭代中的舊LLM,而主玩家是當前迭代中要學習的新LLM。在迭代t 1時包括以下兩個步驟:(1)訓練主模型,(2)更新對手模型。
訓練主模型
#首先,研究人員將說明如何訓練主玩家區分LLM反應和人類反應。受積分機率度量(IPM)的啟發,研究人員制定了目標函數:
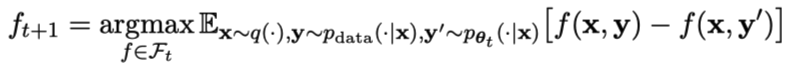
#更新對手模型
對手模型的目標是找到更好的LLM,使其產生的反應與主模型的p資料無異。
實驗
SPIN有效提升基準效能
研究者使用HuggingFace Open LLM Leaderboard作為廣泛的評估來證明SPIN的有效性。
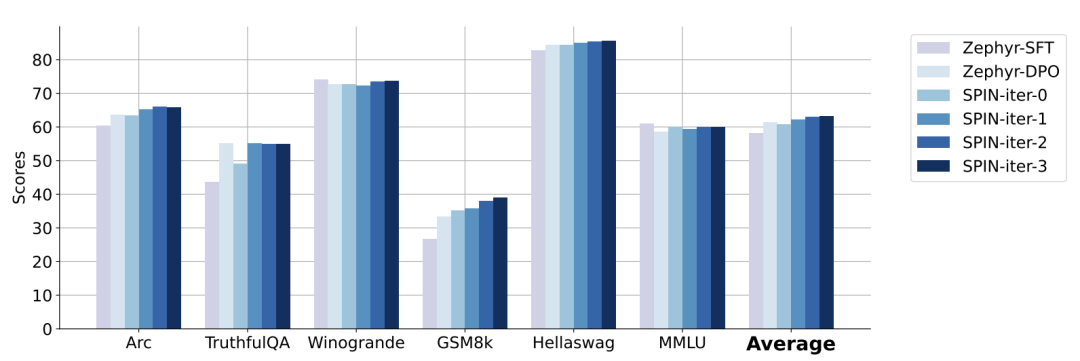
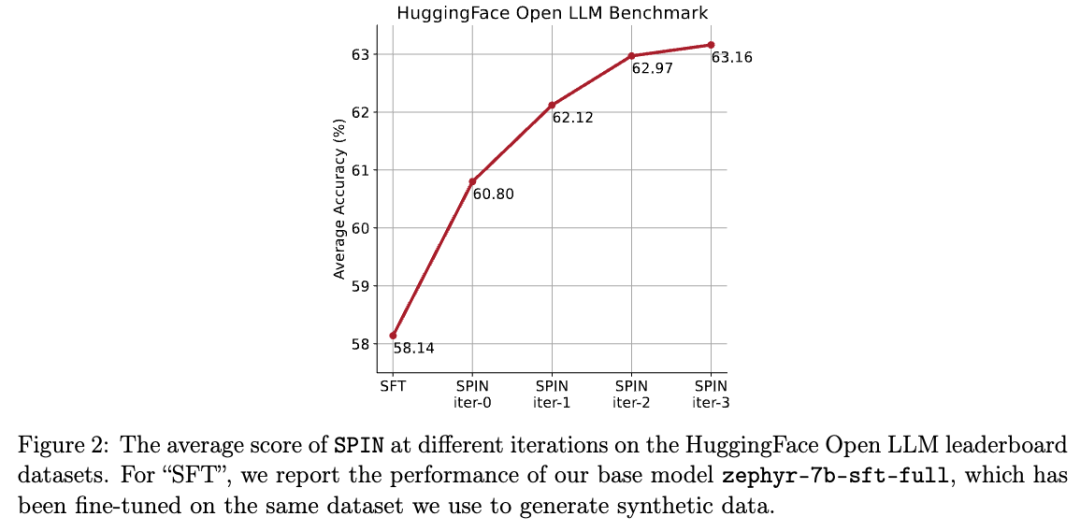
在下圖中,研究人員將經過0到3次迭代後透過SPIN微調的模型與基本模型zephyr-7b-sft-full的性能進行了比較。
研究人員可以觀察到,SPIN透過進一步利用SFT資料集,在提高模型效能方面表現出了顯著的效果,而基礎模型已經在該資料集上進行了充分的微調。
在第0次迭代中,模型反應是從zephyr-7b-sft-full產生的,研究人員觀察到平均分數總體提高了2.66%。
在TruthfulQA和GSM8k基準測試中,這項改進尤其顯著,分別提高了超過5%和10%。
在迭代1中,研究人員採用迭代0中的LLM模型來產生SPIN的新回應,並遵循演算法1中概述的流程。
此迭代平均產生1.32%的進一步增強,在Arc Challenge和TruthfulQA基準測試中尤其顯著。
隨後的迭代延續了各種任務增量改進的趨勢。同時,迭代t 1時的改進自然更小
 圖片
圖片
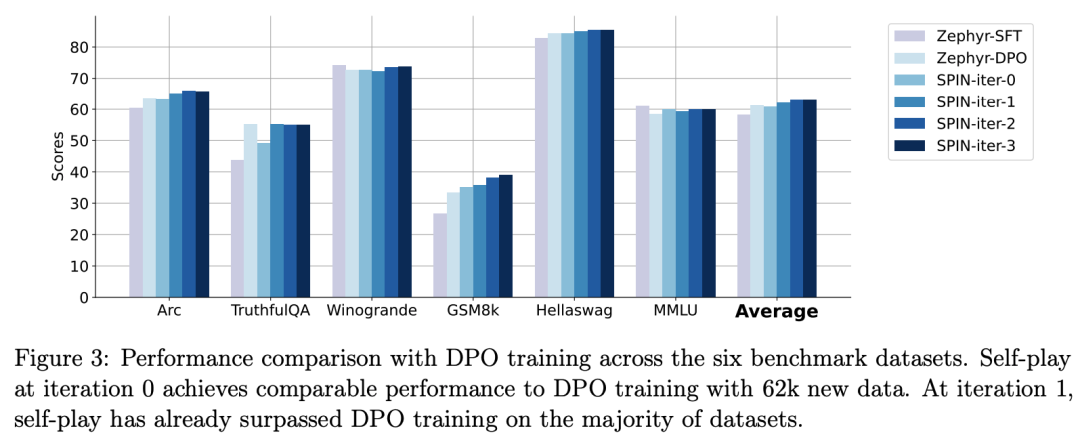
zephyr-7b-beta是從zephyr-7b- sft-full衍生出來的模型,使用DPO在大約62k個偏好資料上訓練而成。
研究人員注意到,DPO需要手動輸入或高階語言模型回饋來確定偏好,因此資料產生是一個相當昂貴的過程。
相較之下,研究者的SPIN只需要初始模型本身就可以。
此外,與需要新資料來源的DPO不同,研究人員的方法完全利用現有的SFT資料集。
下圖顯示了SPIN在迭代0和1(採用50k SFT資料)與DPO訓練的表現比較。
 圖片
圖片
研究人員可以觀察到,雖然DPO利用了更多新來源的數據,但基於現有SFT數據的SPIN從迭代1開始,SPIN甚至超越了DPO的性能、SPIN在排行榜基準測試中的表現甚至超過了DPO。
參考資料:
以上是UCLA華人提出全新自我對弈機制! LLM自己訓練自己,效果碾壓GPT-4專家指導的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 加州理工華人用AI顛覆數學證明!提速5倍震驚陶哲軒,80%數學步驟全自動化
Apr 23, 2024 pm 03:01 PM
加州理工華人用AI顛覆數學證明!提速5倍震驚陶哲軒,80%數學步驟全自動化
Apr 23, 2024 pm 03:01 PM
LeanCopilot,讓陶哲軒等眾多數學家讚不絕口的這個形式化數學工具,又有超強進化了?就在剛剛,加州理工學院教授AnimaAnandkumar宣布,團隊發布了LeanCopilot論文的擴展版本,更新了程式碼庫。圖片論文地址:https://arxiv.org/pdf/2404.12534.pdf最新實驗表明,這個Copilot工具,可以自動化80%以上的數學證明步驟了!這個紀錄,比以前的基線aesop還要好2.3倍。並且,和以前一樣,它在MIT許可下是開源的。圖片他是一位華人小哥宋沛洋,他是
 本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
譯者|布加迪審校|重樓本文介紹如何使用GroqLPU推理引擎在JanAI和VSCode中產生超快速反應。每個人都致力於建立更好的大語言模型(LLM),例如Groq專注於AI的基礎設施方面。這些大模型的快速響應是確保這些大模型更快捷響應的關鍵。本教學將介紹GroqLPU解析引擎以及如何在筆記型電腦上使用API和JanAI本地存取它。本文也將把它整合到VSCode中,以幫助我們產生程式碼、重構程式碼、輸入文件並產生測試單元。本文將免費創建我們自己的人工智慧程式設計助理。 GroqLPU推理引擎簡介Groq
 從'人+RPA”到'人+生成式AI+RPA”,LLM如何影響RPA人機互動?
Jun 05, 2023 pm 12:30 PM
從'人+RPA”到'人+生成式AI+RPA”,LLM如何影響RPA人機互動?
Jun 05, 2023 pm 12:30 PM
圖片來源@視覺中國文|王吉偉從“人+RPA”到“人+生成式AI+RPA”,LLM如何影響RPA人機互動?換個角度,從人機互動看LLM如何影響RPA?影響程式開發與流程自動化人機互動的RPA,現在也要被LLM改變了? LLM如何影響人機互動?生成式AI怎麼改變RPA人機互動?一文看得懂:大模型時代來臨,基於LLM的生成式AI正在快速變革RPA人機交互;生成式AI重新定義人機交互,LLM正在影響RPA軟體架構變遷。如果問RPA對程式開發以及自動化有哪些貢獻,其中一個答案便是它改變了人機互動(HCI,h
 全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最強開源 MoE 模型來了,中文能力比肩 GPT-4,價格僅 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想像一下,一個人工智慧模型,不僅擁有超越傳統運算的能力,還能以更低的成本實現更有效率的效能。這不是科幻,DeepSeek-V2[1],全球最強開源MoE模型來了。 DeepSeek-V2是一個強大的專家混合(MoE)語言模型,具有訓練經濟、推理高效的特點。它由236B個參數組成,其中21B個參數用於啟動每個標記。與DeepSeek67B相比,DeepSeek-V2效能更強,同時節省了42.5%的訓練成本,減少了93.3%的KV緩存,最大生成吞吐量提高到5.76倍。 DeepSeek是一家探索通用人工智
 大模型一對一戰鬥75萬輪,GPT-4奪冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
大模型一對一戰鬥75萬輪,GPT-4奪冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
關於Llama3,又有測試結果新鮮出爐-大模型評測社群LMSYS發布了一份大模型排行榜單,Llama3位列第五,英文單項與GPT-4並列第一。圖片不同於其他Benchmark,這份榜單的依據是模型一對一battle,由全網測評者自行命題並評分。最終,Llama3取得了榜單中的第五名,排在前面的是GPT-4的三個不同版本,以及Claude3超大杯Opus。而在英文單項榜單中,Llama3反超了Claude,與GPT-4打成了平手。對於這一結果,Meta的首席科學家LeCun十分高興,轉發了推文並
 Plaud 推出 NotePin AI 穿戴式錄音機,售價 169 美元
Aug 29, 2024 pm 02:37 PM
Plaud 推出 NotePin AI 穿戴式錄音機,售價 169 美元
Aug 29, 2024 pm 02:37 PM
Plaud Note AI 錄音機(亞馬遜上有售,售價 159 美元)背後的公司 Plaud 宣布推出一款新產品。該設備被稱為 NotePin,被描述為人工智慧記憶膠囊,與 Humane AI Pin 一樣,它是可穿戴的。 NotePin 是
 知識圖譜檢索增強的GraphRAG(基於Neo4j程式碼實作)
Jun 12, 2024 am 10:32 AM
知識圖譜檢索增強的GraphRAG(基於Neo4j程式碼實作)
Jun 12, 2024 am 10:32 AM
圖檢索增強生成(GraphRAG)正逐漸流行起來,成為傳統向量搜尋方法的強大補充。這種方法利用圖資料庫的結構化特性,將資料以節點和關係的形式組織起來,從而增強檢索資訊的深度和上下文關聯性。圖在表示和儲存多樣化且相互關聯的資訊方面具有天然優勢,能夠輕鬆捕捉不同資料類型間的複雜關係和屬性。而向量資料庫則處理這類結構化資訊時則顯得力不從心,它們更專注於處理高維度向量表示的非結構化資料。在RAG應用中,結合結構化的圖資料和非結構化的文字向量搜索,可以讓我們同時享受兩者的優勢,這也是本文將要探討的內容。構
 七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
七個很酷的GenAI & LLM技術性面試問題
Jun 07, 2024 am 10:06 AM
想了解更多AIGC的內容,請造訪:51CTOAI.x社群https://www.51cto.com/aigc/譯者|晶顏審校|重樓不同於網路上隨處可見的傳統問題庫,這些問題需要跳脫常規思維。大語言模型(LLM)在數據科學、生成式人工智慧(GenAI)和人工智慧領域越來越重要。這些複雜的演算法提升了人類的技能,並在許多產業中推動了效率和創新性的提升,成為企業保持競爭力的關鍵。 LLM的應用範圍非常廣泛,它可以用於自然語言處理、文字生成、語音辨識和推薦系統等領域。透過學習大量的數據,LLM能夠產生文本
