
一週前,OpenAI送給使用者福利。他們解決了GPT-4變懶的問題,並推出了5個新模型,其中包括text-embedding-3-small嵌入模型,它更小巧高效。
嵌入是用來表示自然語言、程式碼等內容中的概念的數字序列。它們幫助機器學習模型和其他演算法更好地理解內容之間的關聯,也更容易執行聚類或檢索等任務。在 NLP 領域,嵌入扮演著非常重要的角色。
不過,OpenAI 的嵌入模型並不是免費給大家使用的,例如 text-embedding-3-small 的收費價格是每 1k tokens 0.00002 美元。
現在,比 text-embedding-3-small 更好的嵌入模型來了,而且還不收費。
Nomic AI,一家AI新創公司,最近發布了首個開源、開放資料、開放權重、開放訓練程式碼的嵌入模型-Nomic Embed。此模型具有完全可複現和可審核的特點,其上下文長度為8192。在短上下文和長上下文的基準測試中,Nomic Embed擊敗了OpenAI的text-embeding-3-small和text-embedding-ada-002模型。這項成就標誌著Nomic AI在嵌入模型領域的重要進展。

文字嵌入是現代NLP應用程式中的關鍵組成部分,用於提供檢索增強生成(RAG)功能,為LLM和語義搜尋提供支援。該技術透過將句子或文件的語義資訊編碼為低維向量,並將其應用於下游應用程序,如資料視覺化、分類和資訊檢索的聚類,以實現更高效的處理。 目前,OpenAI的text-embedding-ada-002是最受歡迎的長上下文文字嵌入模型之一,它支援高達8192個上下文長度。然而,遺憾的是,Ada是閉源的,並且無法對其訓練資料進行審計,這使得其可信度受到一定的限制。儘管如此,該模型仍然被廣泛使用,並在許多NLP任務中表現出色。 未來,我們希望能夠開發更透明和可審計的文本嵌入模型,以提高其可信度和可靠性。這將有助於推動NLP領域的發展,並為各類應用提供更有效率和準確的文字處理能力。
效能最佳的開源長上下文文字嵌入模型,如E5-Mistral和jina-embeddings-v2-base-en,可能會有一些限制。一方面,由於模型大小較大,可能不適合用於通用用途。另一方面,這些模型可能無法超越OpenAI對應模型的表現水準。因此,在選擇適合特定任務的模型時,需要考慮這些因素。
Nomic-embed 的發布改變了這一點。模型的參數量只有 137M ,非常方便部署,5 天就訓練好了。

論文網址:https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
論文主題:Nomic Embed: Training a Reproducible Long Context Text Embedder
專案網址:https://github.com/nomic-ai/ contrastors
現有文字編碼器的主要缺點之一是受到序列長度限制,僅限於512 個token。為了訓練更長序列的模型,首先要做的就是調整 BERT,使其能夠適應長序列長度,研究的目標序列長度為 8192。
訓練上下文長度為2048 的BERT
該研究遵循多階段對比學習pipeline 來訓練nomic-embed 。首先研究進行 BERT 初始化,由於 bert-base 只能處理最多 512 個 token 的上下文長度,因此研究決定訓練自己的 2048 個 token 上下文長度的 BERT——nomic-bert-2048。
受 MosaicBERT 的啟發,研究團隊對 BERT 的訓練流程進行了一些修改,包括:
并进行了以下训练优化:
训练时,该研究以最大序列长度 2048 来训练所有阶段,并在推理时采用动态 NTK 插值来扩展到 8192 序列长度。
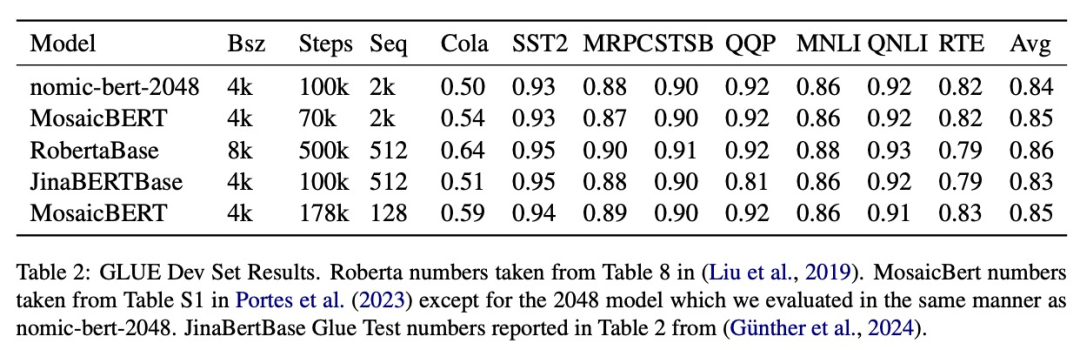
该研究在标准 GLUE 基准上评估了 nomic-bert-2048 的质量,发现它的性能与其他 BERT 模型相当,但具有显著更长的上下文长度优势。
nomic-embed 的对比训练
该研究使用 nomic-bert-2048 初始化 nomic-embed 的训练。对比数据集由约 2.35 亿文本对组成,并在收集过程中使用 Nomic Atlas 广泛验证了其质量。
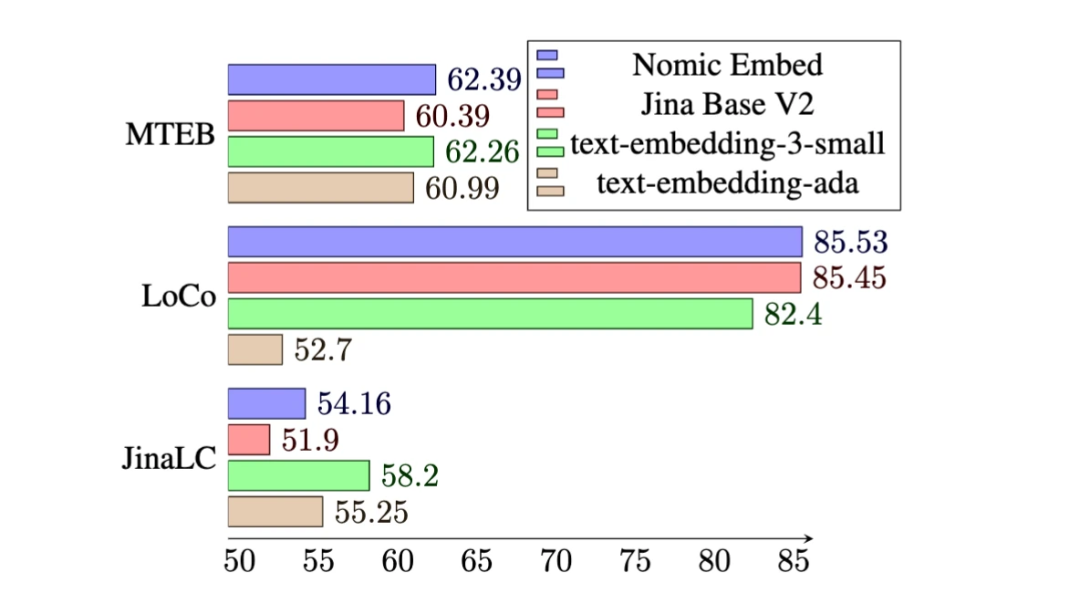
在 MTEB 基准上,nomic-embed 的性能优于 text-embedding-ada-002 和 jina-embeddings-v2-base-en。
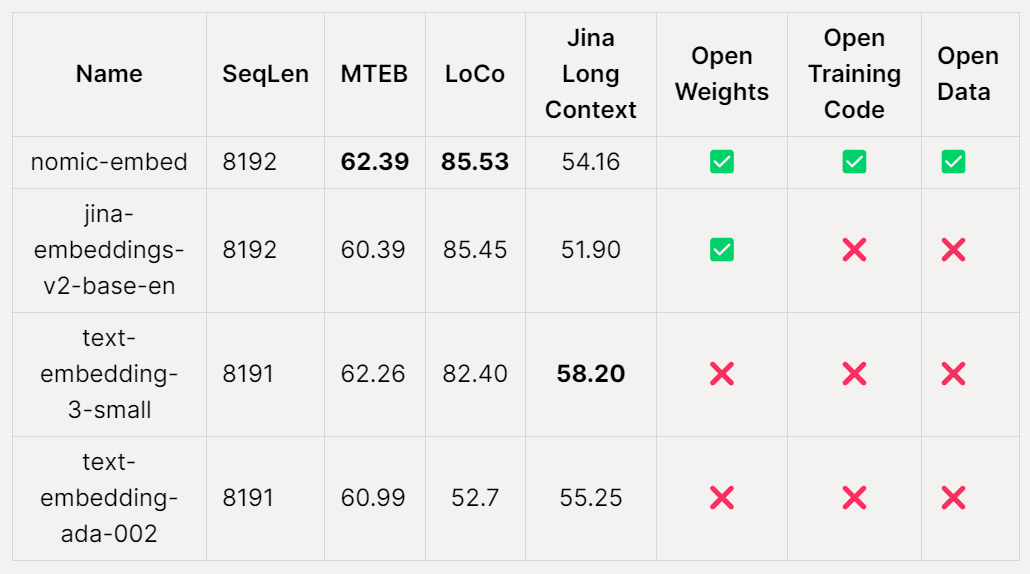
然而,MTEB 不能评估长上下文任务。因此,该研究在最近发布的 LoCo 基准以及 Jina Long Context 基准上评估了 nomic-embed。
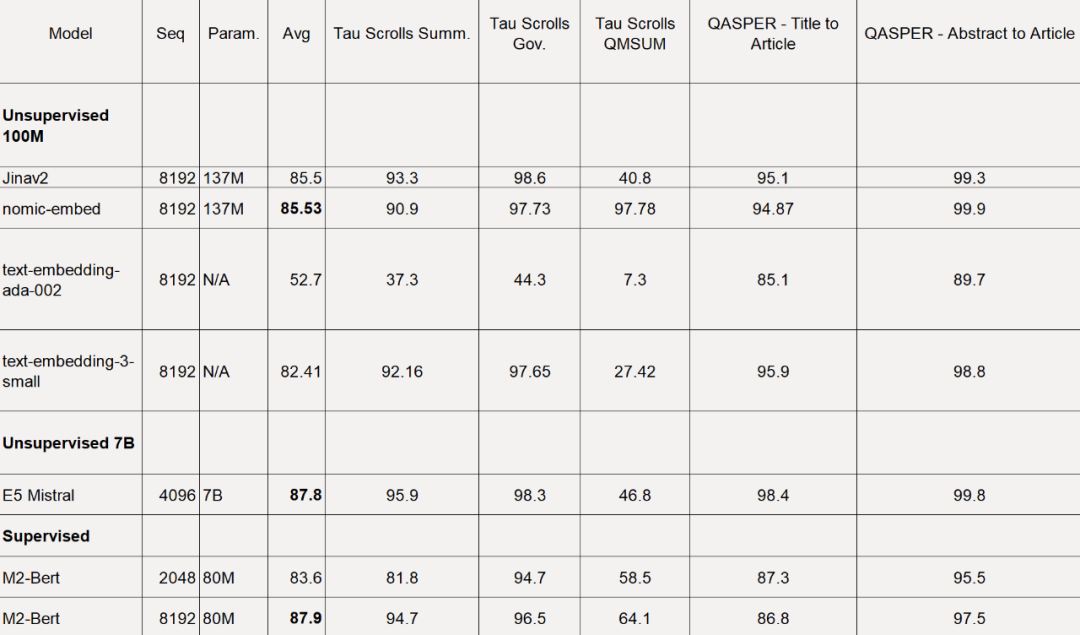
对于 LoCo 基准,该研究按照参数类别以及评估是在监督或无监督设置中执行的分别进行评估。
如下表所示,Nomic Embed 是性能最佳的 100M 参数无监督模型。值得注意的是,Nomic Embed 可与 7B 参数类别中表现最好的模型以及专门针对 LoCo 基准在监督环境中训练的模型媲美:
在 Jina Long Context 基准上,Nomic Embed 的总体表现也优于 jina-embeddings-v2-base-en,但 Nomic Embed 在此基准测试中的表现并不优于 OpenAI ada-002 或 text-embedding-3-small:
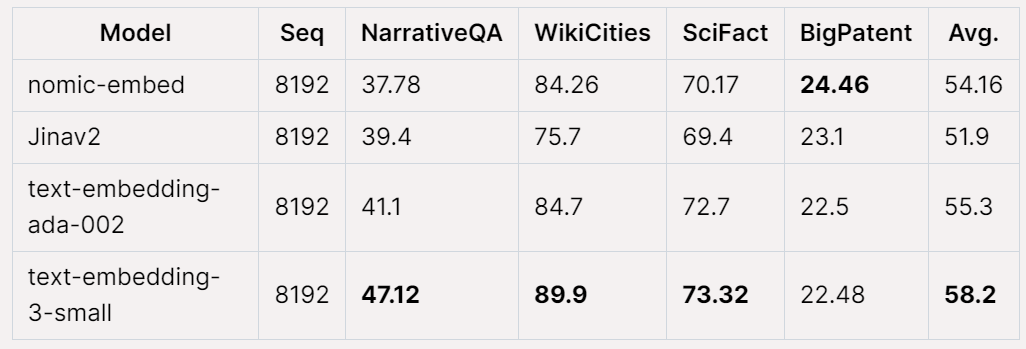
总体而言,Nomic Embed 在 2/3 基准测试中优于 OpenAI Ada-002 和 text-embedding-3-small。
该研究表示,使用 Nomic Embed 的最佳选择是 Nomic Embedding API,获得 API 的途径如下所示:

最后是数据访问:为了访问完整数据,该研究向用户提供了 Cloudflare R2 (类似 AWS S3 的对象存储服务)访问密钥。要获得访问权限,用户需要先创建 Nomic Atlas 帐户并按照 contrastors 存储库中的说明进行操作。
contrastors 地址:https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
以上是擊敗OpenAI,權重、資料、程式碼全開源,能完美重現的嵌入模型Nomic Embed來了的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















