

Linux位元組對齊的那些事

最近,我正在進行一個項目,遇到了一個問題。在ARM上執行的ThreadX與DSP通訊時採用了訊息佇列的方式傳遞訊息(最終實作使用了中斷和共享記憶體的方法)。然而,在實際的操作過程中,發現ThreadX經常崩潰。經過排查,發現問題出在傳遞訊息的結構體沒有考慮位元組對齊的問題。
我想順便整理一下關於C語言中位元組對齊的問題,並與大家分享。
一、概念
#位元組對齊與資料在記憶體中的位置有關。如果一個變數的記憶體位址恰好是它長度的整數倍,那麼它就被稱為自然對齊。例如,在32位元CPU下,假設一個整數變數的位址為0x00000004,那麼它就是自然對齊的。
先了解什麼位元、位元組、字
| 名稱 | #英文名 | 意義 |
|---|---|---|
| 位元 | bit | 1個二進位位元稱為1個bit |
| 位元組 | Byte | 8個二進位位元稱為1個Byte |
| 字 | word | 電腦用來一次處理交易的一個固定長度 |
字長
#一個字的位數,現代電腦的字長通常為16,32, 64位。 (一般N位元系統的位元長是N/8位元組。)
不同的CPU一次可以處理的數據位數是不同的,32位CPU可以一次處理32位數據,64位CPU可以一次處理64位數據,這裡的位,指的就是字長。
而所謂的字長,我們有時會稱為字(word)。在16位元的CPU中,一個字剛好為兩個位元組,而32位元CPU中,一個字是四個位元組。若以字為單位,向上還有雙字(兩個字),四個字(四個字)。
二、對齊規則
#對於標準資料類型,它的位址只要是它的長度的整數倍就行了,而非標準資料類型按下面的原則對齊: 數組:按照基本資料類型對齊,第一個對齊了後面的自然也就對齊了。聯合 :按其包含的長度最大的資料類型對齊。結構體:結構體中每個資料型態都要對齊。
三、如何限制定位元組對齊位數?
1. 缺省
#在預設情況下,C編譯器為每一個變數或是資料單元依其自然對界條件分配空間。一般地,可以透過下面的方法來改變缺省的對界條件:
2. #pragma pack(n)
#· 使用偽指令#pragma pack (n),C編譯器將依照n個位元組對齊。 · 使用偽指令#pragma pack (),取消自訂位元組對齊方式。
#pragma pack(n) 用來設定變數以n位元組對齊方式。 n位元組對齊就是說變數存放的起始位址的偏移有兩種情況:
- 如果n大於等於該變數所佔用的位元組數,那麼偏移量必須滿足預設的對齊方式
- 如果n小於該變數的類型所佔用的位元組數,那麼偏移量為n的倍數,就不用滿足預設的對齊方式。
結構的總大小也有一個限制條件,如果n大於等於所有成員變數類型所佔用的位元組數,那麼結構的總大小必須為佔用空間最大的變數所佔用的空間數的倍數;否則必須是n的倍數。
3. __attribute
另外,還有如下的方式:· __attribute((aligned (n))),讓所作用的結構成員對齊在n位元組自然邊界上。如果結構中有成員的長度大於n,則依照最大成員的長度來對齊。 · attribute ((packed)),取消結構在編譯過程中的最佳化對齊,並依照實際佔用位元組數進行對齊。
3. 彙編.align
彙編程式碼通常用.align來制定位元組對齊的位數。
.align:用來指定資料的對齊方式,格式如下:
.align [absexpr1, absexpr2]
以某種對齊方式,在未使用的儲存區域填入值. 第一個值表示對齊方式,4, 8,16或 32. 第二個表達式值表示填滿的值。
四、为什么要对齐?
操作系统并非一个字节一个字节访问内存,而是按2,4,8这样的字长来访问。因此,当CPU从存储器读数据到寄存器,IO的数据长度通常是字长。如32位系统访问粒度是4字节(bytes), 64位系统的是8字节。当被访问的数据长度为n字节且该数据地址为n字节对齐时,那么操作系统就可以高效地一次定位到数据, 无需多次读取,处理对齐运算等额外操作。数据结构应该尽可能地在自然边界上对齐。如果访问未对齐的内存,CPU需要做两次内存访问。
字节对齐可能带来的隐患:
代码中关于对齐的隐患,很多是隐式的。比如在强制类型转换的时候。例如:
unsigned int i = 0x12345678; unsigned char *p=NULL; unsigned short *p1=NULL; p=&i; *p=0x00; p1=(unsigned short *)(p+1); *p1=0x0000;
最后两句代码,从奇数边界去访问unsignedshort型变量,显然不符合对齐的规定。在x86上,类似的操作只会影响效率,但是在MIPS或者sparc上,可能就是一个error,因为它们要求必须字节对齐.
五、举例
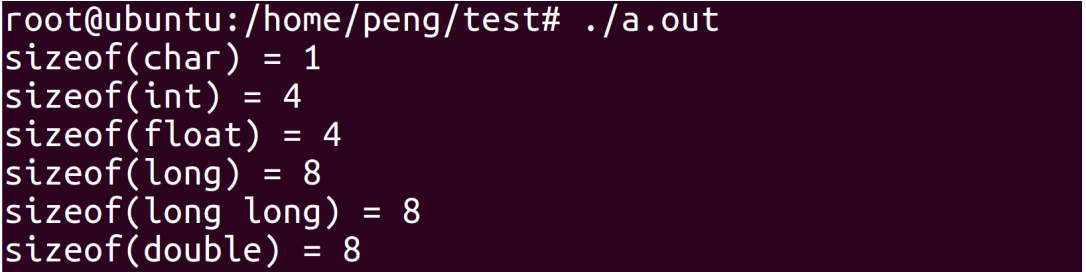
例1:os基本数据类型占用的字节数
首先查看操作系统的位数
在64位操作系统下查看基本数据类型占用的字节数:
#include
int main()
{
printf("sizeof(char) = %ld\n", sizeof(char));
printf("sizeof(int) = %ld\n", sizeof(int));
printf("sizeof(float) = %ld\n", sizeof(float));
printf("sizeof(long) = %ld\n", sizeof(long));
printf("sizeof(long long) = %ld\n", sizeof(long long));
printf("sizeof(double) = %ld\n", sizeof(double));
return 0;
}
例2:结构体占用的内存大小–默认规则
考虑下面的结构体占用的位数
struct yikou_s
{
double d;
char c;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 16
在内容中各变量位置关系如下:
其中成员C的位置
还受字节序的影响,有的可能在位置8
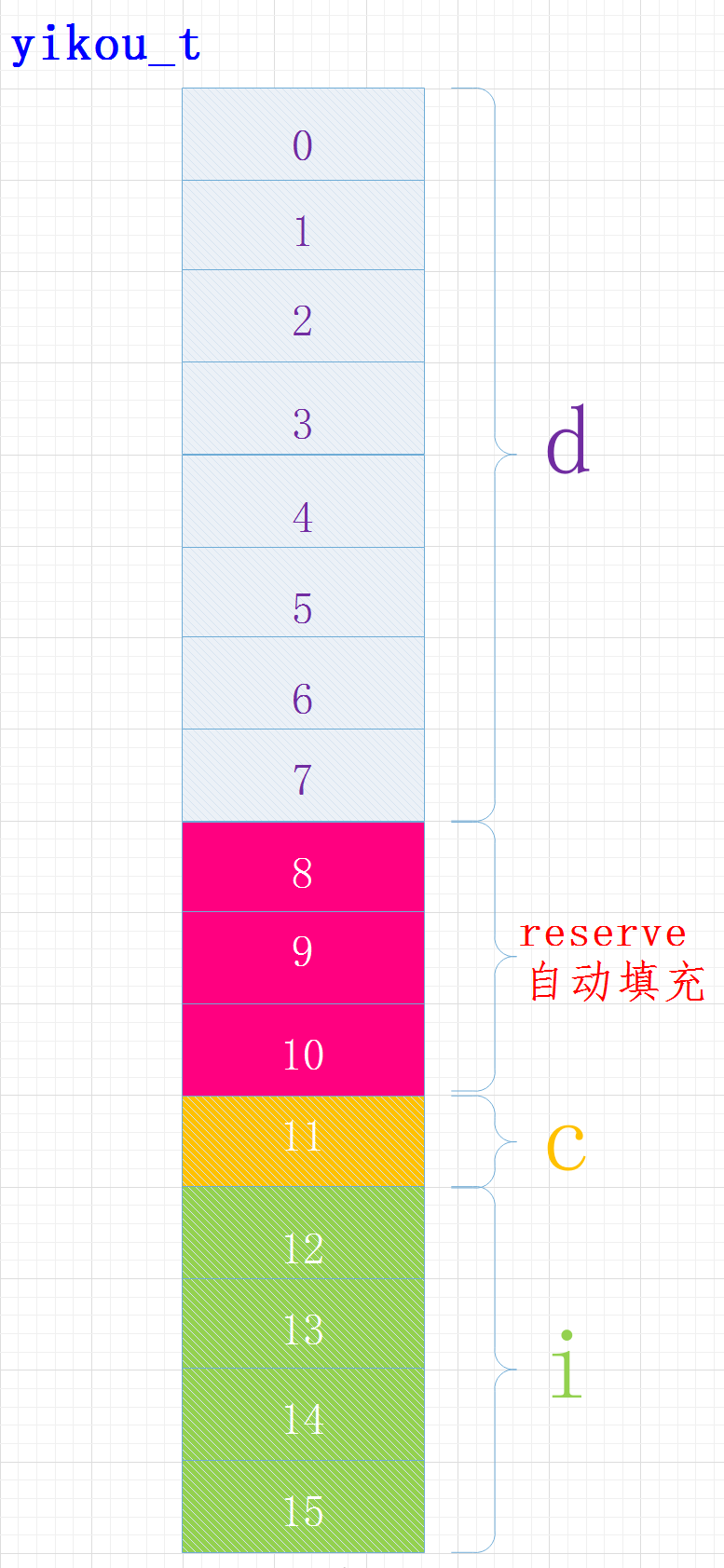 还受字节序的影响,有的可能在位置8
还受字节序的影响,有的可能在位置8编译器给我们进行了内存对齐,各成员变量存放的起始地址相对于结构的起始地址的偏移量必须为该变量类型所占用的字节数的倍数, 且结构的大小为该结构中占用最大空间的类型所占用的字节数的倍数。
对于偏移量:变量type n起始地址相对于结构体起始地址的偏移量必须为sizeof(type(n))的倍数结构体大小:必须为成员最大类型字节的倍数
char: 偏移量必须为sizeof(char) 即1的倍数 int: 偏移量必须为sizeof(int) 即4的倍数 float: 偏移量必须为sizeof(float) 即4的倍数 double: 偏移量必须为sizeof(double) 即8的倍数
例3:调整结构体大小
我们将结构体中变量的位置做以下调整:
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
执行结果
sizeof(yikou_t) = 24
各变量在内存中布局如下:
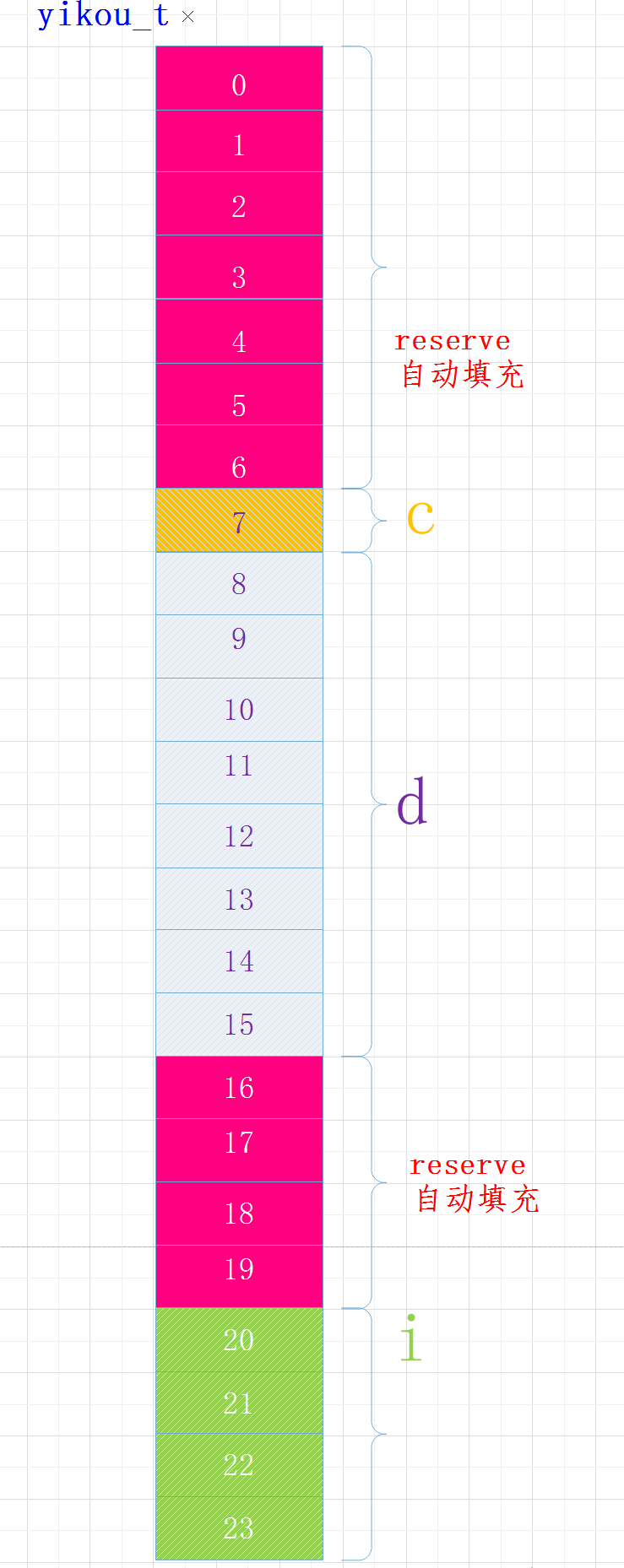
当结构体中有嵌套符合成员时,复合成员相对于结构体首地址偏移量是复合成员最宽基本类型大小的整数倍。
例4:#pragma pack(4)
#pragma pack(4)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 16
例5:#pragma pack(8)
#pragma pack(8)
struct yikou_s
{
char c;
double d;
int i;
} yikou_t;
sizeof(yikou_t) = 24
例6:汇编代码
举例:以下是截取的uboot代码中异常向量irq、fiq的入口位置代码: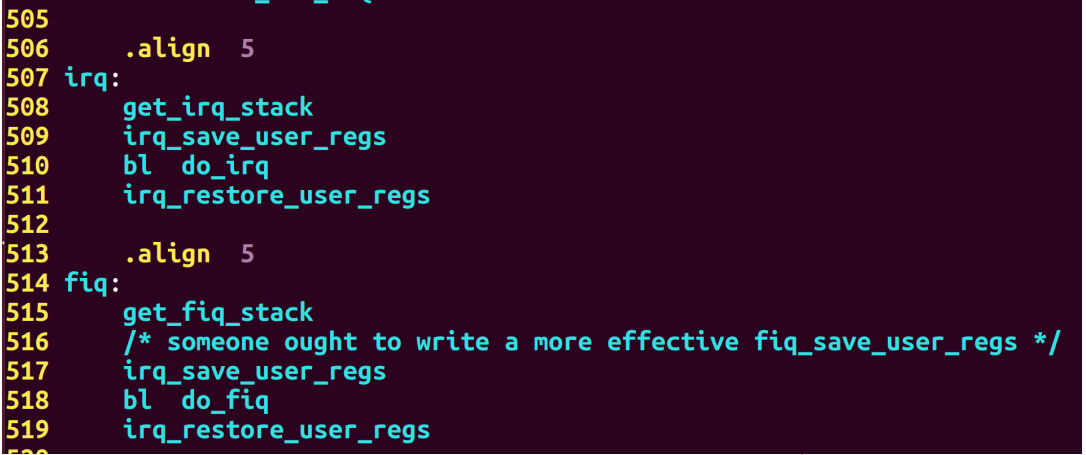
六、汇总实力
有手懒的同学,直接贴一个完整的例子给你们:
#include
main()
{
struct A {
int a;
char b;
short c;
};
struct B {
char b;
int a;
short c;
};
struct AA {
// int a;
char b;
short c;
};
struct BB {
char b;
// int a;
short c;
};
#pragma pack (2) /*指定按2字节对齐*/
struct C {
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
#pragma pack (1) /*指定按1字节对齐*/
struct D {
char b;
int a;
short c;
};
#pragma pack ()/*取消指定对齐,恢复缺省对齐*/
int s1=sizeof(struct A);
int s2=sizeof(struct AA);
int s3=sizeof(struct B);
int s4=sizeof(struct BB);
int s5=sizeof(struct C);
int s6=sizeof(struct D);
printf("%d\n",s1);
printf("%d\n",s2);
printf("%d\n",s3);
printf("%d\n",s4);
printf("%d\n",s5);
printf("%d\n",s6);
}
以上是Linux位元組對齊的那些事的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 vscode需要什麼電腦配置
Apr 15, 2025 pm 09:48 PM
vscode需要什麼電腦配置
Apr 15, 2025 pm 09:48 PM
VS Code 系統要求:操作系統:Windows 10 及以上、macOS 10.12 及以上、Linux 發行版處理器:最低 1.6 GHz,推薦 2.0 GHz 及以上內存:最低 512 MB,推薦 4 GB 及以上存儲空間:最低 250 MB,推薦 1 GB 及以上其他要求:穩定網絡連接,Xorg/Wayland(Linux)
 Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux系統的五個基本組件是:1.內核,2.系統庫,3.系統實用程序,4.圖形用戶界面,5.應用程序。內核管理硬件資源,系統庫提供預編譯函數,系統實用程序用於系統管理,GUI提供可視化交互,應用程序利用這些組件實現功能。
 notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
雖然 Notepad 無法直接運行 Java 代碼,但可以通過借助其他工具實現:使用命令行編譯器 (javac) 編譯代碼,生成字節碼文件 (filename.class)。使用 Java 解釋器 (java) 解釋字節碼,執行代碼並輸出結果。
 vscode終端使用教程
Apr 15, 2025 pm 10:09 PM
vscode終端使用教程
Apr 15, 2025 pm 10:09 PM
vscode 內置終端是一個開發工具,允許在編輯器內運行命令和腳本,以簡化開發流程。如何使用 vscode 終端:通過快捷鍵 (Ctrl/Cmd ) 打開終端。輸入命令或運行腳本。使用熱鍵 (如 Ctrl L 清除終端)。更改工作目錄 (如 cd 命令)。高級功能包括調試模式、代碼片段自動補全和交互式命令歷史。
 git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
要查看 Git 倉庫地址,請執行以下步驟:1. 打開命令行並導航到倉庫目錄;2. 運行 "git remote -v" 命令;3. 查看輸出中的倉庫名稱及其相應的地址。
 vscode 無法安裝擴展
Apr 15, 2025 pm 07:18 PM
vscode 無法安裝擴展
Apr 15, 2025 pm 07:18 PM
VS Code擴展安裝失敗的原因可能包括:網絡不穩定、權限不足、系統兼容性問題、VS Code版本過舊、殺毒軟件或防火牆干擾。通過檢查網絡連接、權限、日誌文件、更新VS Code、禁用安全軟件以及重啟VS Code或計算機,可以逐步排查和解決問題。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 vscode 可以用於 mac 嗎
Apr 15, 2025 pm 07:36 PM
vscode 可以用於 mac 嗎
Apr 15, 2025 pm 07:36 PM
VS Code 可以在 Mac 上使用。它具有強大的擴展功能、Git 集成、終端和調試器,同時還提供了豐富的設置選項。但是,對於特別大型項目或專業性較強的開發,VS Code 可能會有性能或功能限制。
