

Linux管道和FIFO應用筆記

概述
管道最常見的地方是shell中,例如:
$ ls | wc -l
為了執行上面的指令,shell建立了兩個行程來分別執行ls 和wc (透過fork() 和exec( ) 完成),如下:
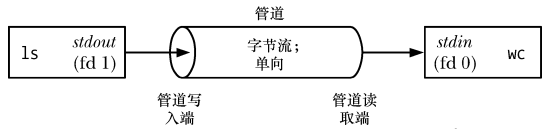
從上圖可以看出,可以將管道看成是一組水管,它允許資料從一個進程流向另一個進程,這也是管道名稱的由來。
從上圖可以看出,由兩個進程連接到了管道上,這樣寫入進程ls 就將其標準輸出(檔案描述符為1)連接到來管道的寫入段,讀取進程wc 就將其標準輸入(檔案描述符為0)連接到管道的讀取端。實際上,這兩個進程並不知道管道的存在,它們只是從標準檔案描述符中讀取和寫入資料。 shell 必須要完成相關的工作。
一個管道是一個位元組流
管道是一個位元組流,即在使用管道時是不存在訊息或訊息邊界的概念的:
- 從管道中讀取資料的進程可以讀取任意大小的資料區塊,而不管寫入進程寫入管道的資料塊的大小是什麼
-
透過管道傳遞的資料是順序的,從管道中讀取出來的位元組的順序與它們被寫入管道的順序是完全一樣的,在管道中無法使用
lseek()來隨機的存取資料
如果需要在管道中實現離散訊息的概念,那麼就必須在應用程式中完成這些工作。雖然這是可行的,但如果碰到這種需求的話最好使用其他 IPC 機制,如訊息佇列和資料封包 socket。
從管道讀取資料
#試圖從一個目前為空的管道讀取資料將會被阻塞直到至少有一個位元組被寫入到管道中為止。
如果管道的寫入端都關閉了,那麼從管道中讀取資料的進程在讀完管道中剩餘的所有資料之後將會看到檔案結束(即read() 回傳0 )。
管道是單向的
#在管道中資料的傳遞方向是單向的。管道的一端用於寫入,另一端則用於讀取。
在其他一些 UNIX 實作上,特別是那些從 System V Release 4 演化而來的系統,管道是雙向的(所謂的流管道)。雙向管道並沒有在任何 UNIX 標準中進行規定,因此即使在提供了雙向管道的實作上最好也避免依賴這種語義。作為替代方案,可以使用 UNIX domain 流 socket 對(透過 socketpair() 系統呼叫來建立),它提供了一種標準的雙向通訊機制,並且其語義與流管道是等價的。
可以確保寫入不超過 PIPE_BUF 位元組的運算是原子的
#如果多個進程寫入同一個管道,那麼如果它們在一個時刻寫入的資料量不超過 PIPE_BUF 字節,那麼就可以確保寫入的資料不會發生相互混合的情況。
SUSv3 要求 PIPE_BUF 至少為 _POSIX_PIPE_BUF(512)。一個實作應該定義 PIPE_BUF(在 <limits.h></limits.h> 中)並/或允許呼叫 fpathconf(fd,_PC_PIPE_BUF) 來傳回原子寫入操作的實際上限。不同 UNIX 實作上的 PIPE_BUF 不同,如在 FreeBSD 6.0 其值為 512 字節,在 Tru64 5.1 上其值為 4096 字節,在 Solaris 8 上其值為 5120 位元組。在 Linux 上,PIPE_BUF 的值為 4096。
-
當寫入管道的資料區塊的大小超過了PIPE_BUF 字節,那麼核心可能會將資料分割成幾個較小的片段來傳輸,在讀者從管道中消耗資料時再附加上後繼的資料(
write()呼叫會阻塞直到所有資料被寫入到管道為止) - 當只有一個程序向管道寫入資料時(通常的情況),PIPE_BUF 的取值就沒有關係了
- 但如果有多個寫入進程,那麼大資料塊的寫入可能會被分解成任意大小的段(可能會小於PIPE_BUF 位元組),並且可能會出現與其他進程寫入的資料交叉的現象
只有在資料被傳輸到管道的時候 PIPE_BUF 限制才會起作用。當寫入的資料達到 PIPE_BUF 位元組時,write() 會在必要的時候阻塞知道管道中的可用空間足以原子的完成此操作。如果寫入的資料大於 PIPE_BUF 字節,那麼 write() 會盡可能的多傳輸資料以充滿整個管道,然後阻塞直到一些讀取程序從管道中移除了資料。如果此類阻塞的write() 被一個訊號處理器中斷了,那麼這個呼叫會被解除阻塞並傳回成功傳送到管道中的位元組數,這個位元組數會少於請求寫入的位元組數(所謂的部分寫入)。
管道的容量是有限的
管道其實是一個在核心記憶體中維護的緩衝器,這個緩衝器的儲存能力是有限的。一旦管道被填滿之後,後繼向管道的寫入操作就會被阻塞直到讀者從管道中移除了一些資料為止。
SUSv3 並沒有規定管道的儲存能力。在早於2.6.11 的Linux 核心中,管道的儲存能力與系統頁面的大小是一致的(如在x86-32 上是4096 位元組),而從Linux 2.6.11 起,管道的儲存能力是65,536位元組.其他 UNIX 實作上的管道的儲存能力可能是不同的。
一般来讲,一个应用程序无需知道管道的实际存储能力。如果需要防止写者进程阻塞,那么从管道中读取数据的进程应该被设计成以尽可能快的速度从管道中读取数据。
创建和使用管道
#include int pipe(int fd[2]);
-
pipe()创建一个新管道 -
成功的调用在数组
fd中返回两个打开的文件描述符,一个表示管道的读取端fd[0],一个表示管道的写入端fd[1]
调用 pipe() 函数时,首先在内核中开辟一块缓冲区用于通信,它有一个读端和一个写端,然后通过 fd 参数传出给用户进程两个文件描述符,fd[0] 指向管道的读端,fd[1] 指向管道的写段。
不要用 fd[0] 写数据,也不要用 fd[1] 读数据,其行为未定义的,但在有些系统上可能会返回 -1 表示调用失败。数据只能从 fd[0] 中读取,数据也只能写入到fd[1],不能倒过来。
与所有文件描述符一样,可以使用 read() 和 write() 系统调用来在管道上执行 IO,一旦向管道的写入端写入数据之后立即就能从管道的读取端读取数据。管道上的 read() 调用会读取的数据量为所请求的字节数与管道中当前存在的字节数两者之间的较小值。当管道为空时,读取操作阻塞。
也可以在管道上使用stdio 函數(printf()、scanf() 等),只需要先使用fdopen() 取得一個與filedes 中的某個描述子對應的檔案流即可。但在這樣做的時候需要解決 stdio 緩衝問題。
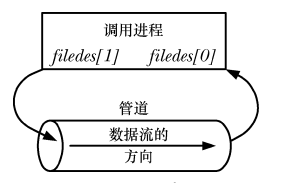
管道可以用於進程內部自己通訊:
管道可以用於親緣關係(子進程會繼承父進程中的檔案描述符的副本)進程中通訊:
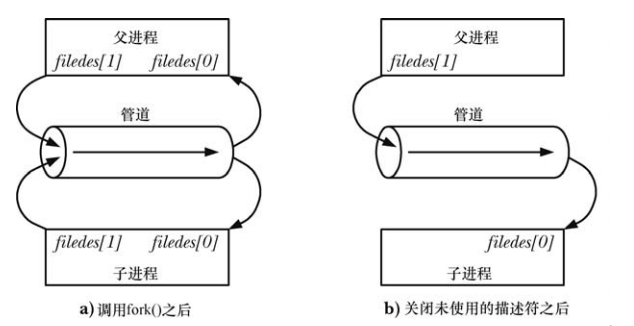
不建議將單一pipe 用作全雙工的,或不關閉用作半雙工而不關閉相應的讀端/寫端,這樣很可能導致死鎖:如果兩個進程同時試圖從管道中讀取數據,那麼就無法確定哪個進程會先讀取成功,產生兩個進程競爭數據了。要防止這種競爭情境的出現就需要使用某種同步機制。這時,就需要考慮死鎖問題了,因為如果兩個進程都試圖從空管道中讀取資料或嘗試向已滿的管道寫入資料就可能會發生死鎖。
如果我們想要一個雙向資料流時,可以建立兩個管道,每個方向一個。
管道允許相關進程間的通訊
其實管道可以用於任意兩個甚至更多相關進程之間的通信,只要在創建子進程的系列 fork() 調用之前通過一個共同的祖先進程創建管道即可。
關閉未使用管道檔案描述符
關閉未使用管道檔案描述符不僅僅是為了確保進程不會消耗盡其檔案描述符的限制。
從管道中讀取資料的進程會關閉其持有的管道的寫入描述符,這樣當其他進程完成輸出並關閉其寫入描述符之後,讀者就能夠看到檔案結束。反之,如果讀取的進程沒有關閉管道的寫入端,那麼在其他進程關閉了寫入描述符之後,即使讀者已經讀完了管道中的所有數據,也不會看到檔案結束。因為此時內核知道至少還有一個管道的寫入描述符打開著,從而導致 read() 阻塞。
当一个进程视图向一个管道中写入数据但没有任何进程拥有该管道的打开着的读取描述符时,内核会向写入进程发送一个 SIGPIPE 信号,默认情况下,这个信号将会杀死进程,但进程可以选择忽略或者设置信号处理器,这样 write() 将因为 EPIPE 错误而失败。收到 SIGPIPE 信号和得到 EPIPE 错误对于标识管道的状态是有意义的,这就是为什么需要关闭管道的未使用读取描述符的原因。如果写入进程没有关闭管道的读取端,那么即使在其他进程已经关闭了管道的读取端之后,写入进程仍然能够向管道写入数据,最后写入进程会将数据充满整个管道,后续的写入请求会将永远阻塞。
使用管道连接过滤器
当管道被创建之后,为管道的两端分配的文件描述符是可用描述符中数值最小的两个,由于通常情况下,进程已经使用了描述符 0,1,2,因此会为管道分配一些数值更大的描述符。如果需要使用管道连接两个过滤器(即从 stdin 读取和写入到 stdout),使得一个程序的标准输出被重定向到管道中,就需要采用复制文件描述符技术。
int pfd[2]; pipe(pfd); close(STDOUT_FILENO); dup2(pfd[1],STDOUT_FILENO);
上面这些调用的最终结果是进程的标准输出被绑定到管道的写入端,而对应的一组调用可以用来将进程的标准的输入绑定到管道的读取端上。
通过管道与 shell 命令进行通信: popen()
#include FILE *popen (const char *command, const char *mode);
-
pipe()和close()是最底层的系统调用,它的进一步封装是popen()和pclose() -
popen()函数创建了一个管道,然后创建了一个子进程来执行 shell,而 shell 又创建了一个子进程来执行command字符串 -
mode参数是一个字符串: -
-
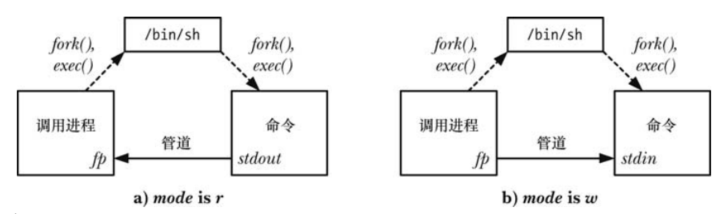
它确定调用进程是从管道中读取数据(
mode是r)还是将数据写入到管道中(mode是w) -
由于管道是向的,因此无法在执行的
command中进行双向通信 -
mode的取值确定了所执行的命令的标准输出是连接到管道的写入端还是将其标准输入连接到管道的读取端
-
它确定调用进程是从管道中读取数据(
-
popen()在成功时会返回可供stdio库函数使用的文件流指针。当发生错误时,popen()会返回NULL并设置errno以标示出发生错误的原因 -
在
popen()调用之后,调用进程使用管道来读取command的输出或使用管道向其发送输入。与使用pipe()创建的管道一样,当从管道中读取数据时,调用进程在command关闭管道的写入端之后会看到文件结束;当向管道写入数据时,如果command已经关闭了管道的读取端,那么调用进程就会收到SIGPIPE信号并得到EPIPE错误
#include int pclose ( FILE * stream);
-
一旦IO结束之后可以使用
pclose()函数关闭管道并等待子进程中的 shell 终止(不应该使用fclose()函数,因为它不会等待子进程。) -
pclose()在成功時會傳回子程序中 shell 的終止狀態(即 shell 所執行的最後一條指令的終止狀態,除非 shell 是被訊號殺死的) -
和
system()一樣,如果無法執行shell,那麼pclose()會回傳一個值就像子程序中的shell 透過呼叫_exit(127)來終止一樣 -
如果發生了其他錯誤,那麼
pclose()傳回 −1。其中可能發生的一個錯誤是無法取得終止狀態
#當執行等待以取得子行程中shell 的狀態時,SUSv3 要求pclose() 與system() 一樣,即在內部的waitpid () 呼叫被一個訊號處理器中斷之後自動重啟該呼叫。
與 system() 一樣,在特權程序中永遠都不應該使用 popen()。
popen優缺點:
-
優點:在 Linux 中所有的參數擴充都是由 shell 來完成的。所以在啟動
command指令之前程式先啟動shell 來分析command字串,就可以使用各種shell 擴充(例如通配符),這樣我們可以透過popen()呼叫非常複雜的shell 指令 -
缺點:對於每個
popen()調用,不僅要啟動一個被請求的程序,還需要啟動一個 shell。即每一個popen()將啟動兩個進程。从效率和资源的角度看,popen()函数的调用比正常方式要慢一些
pipe()` VS `popen()
-
pipe()是一个底层调用,popen()是一个高级的函数 -
pipe()单纯的创建管道,而popen()创建管道的同时fork()子进程 -
popen()在两个进程中传递数据时需要调用 shell 来解释请求命令;pipe()在两个进程中传递数据不需要启动 shell 来解释请求命令,同时提供了对读写数据的更多控制(popen()必须时 shell 命令,pipe()则无硬性要求) -
popen()函数是基于文件流(FILE)工作的,而pipe()是基于文件描述符工作的,所以在使用pipe()后,数据必须要用底层的read()和write()调用来读取和发送
管道和 stdio 缓冲
由于 popen() 调用返回的文件流指针没有引用一个终端,因此 stdio 库会对这种流应用块缓冲。这意味着当 mode 的值为 w 来调用 popen() 时,默认情况下只有当 stdio 缓冲区被充满或者使用 pclose() 关闭了管道之后才会被发送到管道的另一端的子进程。在很多情况下,这种处理方式是不存在问题的。但如果需要確保子進程能夠立即從管道中接收數據,那麼就需要定期呼叫 fflush() 或使用 setbuf(fp, NULL) 呼叫停用 stdio 緩衝。當使用 pipe() 系統呼叫建立管道,然後使用 fdopen() 取得一個與管道的寫入端對應的 stdio 流時也可以使用這項技術
如果呼叫 popen() 的進程正在從管道中讀取資料(即 mode 是 r),那麼事情就不是那麼簡單了。在這樣情況下如果子程序正在使用stdio 庫,那麼——除非它明確地調用了fflush() 或setbuf() ,其輸出只有在子進程填滿stdio 緩衝器或呼叫了fclose() 之後才會對呼叫程序可用。 (如果正在從使用pipe() 建立的管道中讀取資料並且向另一端寫入資料的進程正在使用stdio 庫,那麼同樣的規則也是適用的。)如果這是一個問題,那麼能採取的措施就比較有限的,除非能夠修改在子進程中運行的程式的原始程式碼使之包含對setbuf() 或fflush() 呼叫。
如果無法修改原始程式碼,那麼可以使用偽終端來替換管道。一個偽終端是一個 IPC 通道,對進程來講它就像是一個終端。其結果是 stdio 函式庫會逐行輸出緩衝器中的資料。
命名管道(FIFO)
上述管道雖然實現了進程間通信,但是它具有一定的限制:
- 匿名管道只能是具有血緣關係的進程之間通訊
- 它只能實作一個行程寫另一個行程讀,而如果需要兩者同時進行時,就得重新開啟一個管道
為了讓任兩個行程之間能夠通信,就提出了命名管道(named pipe 或 FIFO):
- FIFO 与管道的区别:FIFO 在文件系统中拥有一个名称,并且其打开方式与打开一个普通文件一样,能够实现任何两个进程之间通信。而匿名管道对于文件系统是不可见的,它仅限于在父子进程之间的通信
-
一旦打开了 FIFO,就能在它上面使用与操作管道和其他文件的系统调用一样的 IO 系统调用
read(),write(),close()。与管道一样,FIFO 也有一个写入端和读取端,并且总是遵循先进先出的原则,即第一个进来的数据会第一个被读走 - 与管道一样,当所有引用 FIFO 的描述符都关闭之后,所有未被读取的数据都将被丢弃
-
使用
mkfifo命令可以在 shell 中创建一个 FIFO:
mkfifo [-m mode] pathname
-
pathname是创建的 FIFO 的名称,-m选项指定权限mode,其工作方式与chmod命令一样 -
fstat()和stat()函数会在stat结构的st_mode字段返回S_IFIFO,使用ls -l列出文件时,FIFO 文件在第一列的类型为p,ls -F会在 FIFO 路径名后面附加管道符|
#include #include int mkfifo(const char *pathname,mode_t mode);
-
mode参数指定了新 FIFO 的权限,这些权限会按照进程的umask值来取掩码 - 一旦创建了 FIFO,任何进程都能够打开它,只要它通过常规的文件权限检测
-
使用 FIFO 时唯一明智的做法是在两端分别设置一个读取进程和一个写入进程。这样在默认情况下,打开一个 FIFO 以便读取数据(
open() O_RDONLY标记)将会阻塞直到另一个进程打开 FIFO 以写入数(open() O_WRONLY标记)为止。相应地,打开一个 FIFO 以写入数据将会阻塞直到另一个进程打开 FIFO 以读取数据为止。换句话说,打开一个 FIFO 会同步读取进程和写入进程。如果一个 FIFO 的另一端已经打开(可能是因为一对进程已经打开了 FIFO 的两端),那么open()调用会立即成功。
在大多数 Unix 实现上(包含 Linux),当打开一个 FIFO 时可以通过指定 O_RDWR 标记来绕过打开 FIFO 时的阻塞行为。这样,open() 会立即返回,但无法使用返回的文件描述符在 FIFO 上读取和写入数据。这种做法破坏了 FIFO 的 IO 模型,SUSv3 明确指出以 O_RDWR 标记打开一个 FIFO 的结果是未知的,因此出于可移植性的原因,开发人员不应该使用这项技术。对于那些需要避免在打开 FIFO 时发生阻塞的需求,open() 的 O_NONBLOCK 标记提供了一种标准化的方法来完成这个任务:
open(const char *path, O_RDONLY | O_NONBLOCK); open(const char *path, O_WRONLY | O_NONBLOCK);
在打开一个 FIFO 时避免使用 O_RDWR 标记还有另外一个原因,当采用那种方式调用 open() 之后,调用进程在从返回的文件描述符中读取数据时永远都不会看到文件结束,因为永远都至少存在一个文件描述符被打开着以等待数据被写入 FIFO,即进程从中读取数据的那个描述符。
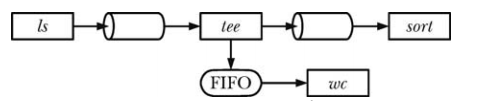
使用 FIFO 和 tee 创建双重管道线
shell 管道线的其中一个特征是它们是线性的,管道线中的每个进程都能读取前一个进程产生的数据并将数据发送到其后一个进程中,使用 FIFO 就能够在管道线中创建子进程,这样除了将一个进程的输出发送给管道线中的后面一个进程之外,还可以复制进程的输出并将数据发送到另一个进程中,要完成这个任务就需要使用 tee 命令,它将其从标准输入中读取到的数据复制两份并输出:一份写入标准输出,另一份写入到通过命令行参数指定的文件中。
mkfifo myfifo wc -l
非阻塞 IO
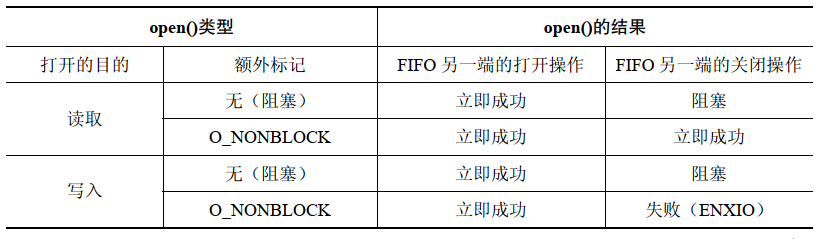
当一个进程打开一个 FIFO 的一端时,如果 FIFO 的另一端还没有被打开,那么该进程会被阻塞。但有些时候阻塞并不是期望的行为,而这可以通过在调用 open() 时指定 O_NONBLOCK 标记来实现。
如果 FIFO 的另一端已经被打开,那么 O_NONBLOCK 对 open() 调用不会产生任何影响,它会像往常一样立即成功地打开 FIFO。只有当 FIFO 的另一端还没有被打开的时候 O_NONBLOCK 标记才会起作用,而具体产生的影响则依赖于打开 FIFO 是用于读取还是用于写入的:
-
如果打开 FIFO 是为了读取,并且 FIFO 的写入端当前已经被打开,那么
open()调用会立即成功(就像 FIFO 的另一端已经被打开一样) -
如果打开 FIFO 是为了写入,并且还没有打开 FIFO 的另一端来读取数据,那么
open()调用会失败,并将errno设置为ENXIO
为读取而打开 FIFO 和为写入而打开 FIFO 时 O_NONBLOCK 标记所起的作用不同是有原因的。当 FIFO 的另一个端没有写者时打开一个 FIFO 以便读取数据是没有问题的,因为任何试图从 FIFO 读取数据的操作都不会返回任何数据。但当试图向没有读者的 FIFO 中写入数据时将会导致 SIGPIPE 信号的产生以及 write() 返回 EPIPE 错误。
在 FIFO 上调用 open() 的语义总结如下:
在打开一个 FIFO 时,使用 O_NOBLOCK 标记存在两个目的:
-
它允许单个进程打开一个 FIFO 的两端,这个进程首先会在打开 FIFO 时指定
O_NOBLOCK标记以便读取数据,接着打开 FIFO 以便写入数据 - 它防止打开两个 FIFO 的进程之间产生死锁
例如,下面的情况将会发生死锁:

非阻塞 read() 和 write()
O_NONBLOCK 标记不仅会影响 open() 的语义,而且还会影响——因为在打开的文件描述中这个标记仍然被设置着——后续的 read() 和 write() 调用的语义。
有些时候需要修改一个已经打开的 FIFO(或另一种类型的文件)的 O_NONBLOCK 标记的状态,具体存在这个需求的场景包括以下几种:
-
使用
O_NONBLOCK打开了一个 FIFO 但需要后续的read()和write()在阻塞模式下运行 -
需要启用从
pipe()返回的一个文件描述符的非阻塞模式。更一般地,可能需要更改从除open()调用之外的其他调用中,如每个由 shell 运行的新程序中自动被打开的三个标准描述符的其中一个或socket()返回的文件描述符,取得的任意文件描述符的非阻塞状态 -
出于一些应用程序的特殊需求,需要切换一个文件描述符的
O_NONBLOCK设置的开启和关闭状态
当碰到上面的需求时可以使用 fcntl() 启用或禁用打开着的文件的 O_NONBLOCK 状态标记。通过下面的代码(忽略的错误检查)可以启用这个标记:
int flags; flags = fcntl(fd, F_GETFL); flags != O_NONBLOCK; fcntl(fd, F_SETFL, flags);
通过下面的代码可以禁用这个标记:
flags = fcntl(fd, F_GETFL); flags &= ~O_NONBLOCK; fcntl(fd, F_SETFL, flags);
管道和 FIFO 中 read() 和 write() 的语义
FIFO 上的 read() 操作:
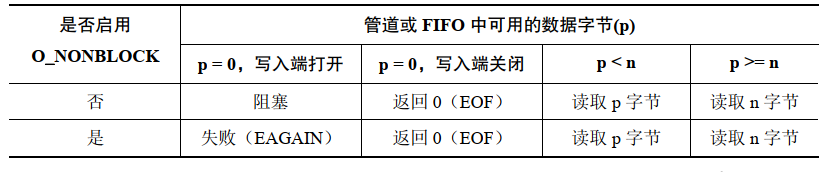
只有当没有数据并且写入端没有被打开时阻塞和非阻塞读取之间才存在差别。在这种情况下,普通的 read() 会被阻塞,而非阻塞 read() 会失败并返回 EAGAIN 错误。
当 O_NONBLOCK 标记与 PIPE_BUF 限制共同起作用时 O_NONBLOCK 标记对象管道或 FIFO 写入数据的影响会变得复杂。
FIFO 上的 write() 操作:
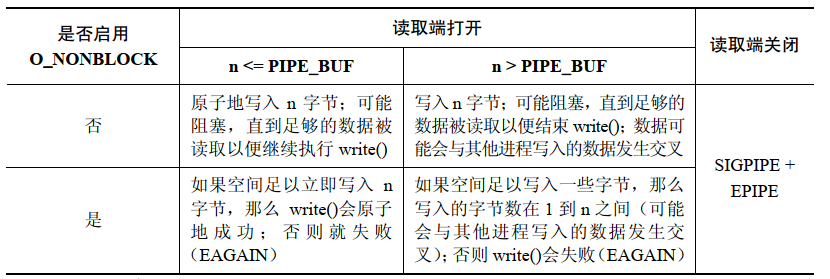
- #
當資料無法立即被傳輸時
O_NONBLOCK標記會導致在一個管道或 FIFO 上的write()失敗(錯誤是EAGAIN)。這意味著當寫入了PIPE_BUF位元組之後,如果在管道或FIFO 中沒有足夠的空間了,那麼write()會失敗,因為核心無法立即完成這個操作且無法執行部分寫入,否則就會破壞不超過PIPE_BUF位元組的寫入操作的原子性的要求 - #
當一次寫入的資料量超過
PIPE_BUF位元組時,該寫入操作無需是原子的。因此,write()會盡可能傳送位元組(部分寫入)以充滿管道或 FIFO。在這種情況下,從write()傳回的值是實際傳輸的位元組數,並且呼叫者隨後必須進行重試以寫入剩餘的位元組。但如果管道或 FIFO 已經滿了,從而導致即使連一個位元組都無法傳輸了,那麼write()會失敗並回傳EAGAIN錯誤
以上是Linux管道和FIFO應用筆記的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux系統的五個基本組件是:1.內核,2.系統庫,3.系統實用程序,4.圖形用戶界面,5.應用程序。內核管理硬件資源,系統庫提供預編譯函數,系統實用程序用於系統管理,GUI提供可視化交互,應用程序利用這些組件實現功能。
 git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
要查看 Git 倉庫地址,請執行以下步驟:1. 打開命令行並導航到倉庫目錄;2. 運行 "git remote -v" 命令;3. 查看輸出中的倉庫名稱及其相應的地址。
 notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
雖然 Notepad 無法直接運行 Java 代碼,但可以通過借助其他工具實現:使用命令行編譯器 (javac) 編譯代碼,生成字節碼文件 (filename.class)。使用 Java 解釋器 (java) 解釋字節碼,執行代碼並輸出結果。
 sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
在 Sublime 中運行代碼的方法有六種:通過熱鍵、菜單、構建系統、命令行、設置默認構建系統和自定義構建命令,並可通過右鍵單擊項目/文件運行單個文件/項目,構建系統可用性取決於 Sublime Text 的安裝情況。

 laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
要安裝 Laravel,需依序進行以下步驟:安裝 Composer(適用於 macOS/Linux 和 Windows)安裝 Laravel 安裝器創建新項目啟動服務訪問應用程序(網址:http://127.0.0.1:8000)設置數據庫連接(如果需要)
 如何設置重要的 Git 配置全局屬性
Apr 17, 2025 pm 12:21 PM
如何設置重要的 Git 配置全局屬性
Apr 17, 2025 pm 12:21 PM
自定義開發環境的方法有很多種,但全局 Git 配置文件是最有可能用於自定義設置(例如用戶名、電子郵件、首選文本編輯器和遠程分支)的一種。以下是您需要了解的有關全局 Git 配置文件的關鍵事項。
 sublime快捷鍵怎麼使用
Apr 16, 2025 am 08:57 AM
sublime快捷鍵怎麼使用
Apr 16, 2025 am 08:57 AM
Sublime Text 提供了提高开发效率的快捷键,包括常用的(保存、复制、剪切等)、编辑(缩进、格式化等)、导航(项目面板、文件浏览等)以及查找和替换快捷键。熟练使用这些快捷键可显著提升 Sublime 的使用效率。
