

三篇論文解決「語意分割的最佳化和評估」難題!魯汶/清華/牛津等聯合提出全新方法

常用的最佳化語意分割模型的損失函數包括Soft Jaccard損失、Soft Dice損失和Soft Tversky損失。然而,這些損失函數與軟標籤不相容,因此無法支援一些重要的訓練技術,例如標籤平滑、知識蒸餾、半監督學習和多標註員等。這些訓練技術對於提高語意分割模型的表現和穩健性非常重要,因此需要進一步研究和最佳化損失函數,以支援這些訓練技術的應用。
另一方面,常用的語意分割評估指標包括mAcc和mIoU。然而,這些指標會對尺寸較大的物體有偏好,嚴重影響模型的安全性能評估。
為了解決這些問題,研究人員在魯汶大學和清華首先提出了JDT損失。 JDT損失是對原有損失函數的微調,它包括了Jaccard Metric損失、Dice Semimetric損失和Compatible Tversky損失。 JDT損失在處理硬標籤時與原有的損失函數相等,同時也能完全適用於軟標籤。這項改進使得模型的訓練更加準確和穩定。
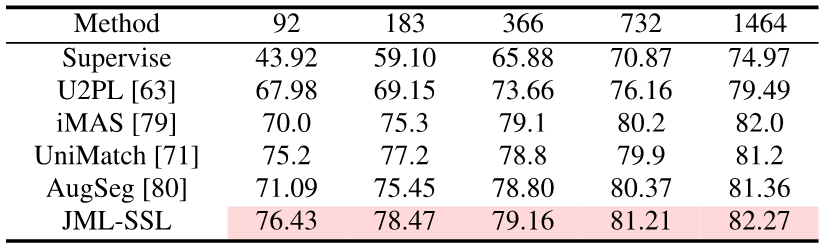
研究人員在四個重要場景中成功應用了JDT損失:標籤平滑、知識蒸餾、半監督學習和多標註員。這些應用展示了JDT損失對於提高模型準確性和校準性的能力。
 圖片
圖片
論文連結:https://arxiv.org/pdf/2302.05666.pdf
 #圖片
#圖片
論文連結:https://arxiv.org/pdf/2303.16296.pdf
除此之外,研究人員也提出了細粒度的評估指標。這些細粒度的評估指標對大尺寸物體的偏見較小,能提供更豐富的統計信息,並能為模型和數據集審計提供有價值的見解。
並且,研究人員進行了一項廣泛的基準研究,強調了不應基於單一指標進行評估的必要性,並發現了神經網路結構和JDT損失對優化細粒度指標的重要作用。
 圖片
圖片
論文連結:https://arxiv.org/pdf/2310.19252.pdf
#程式碼連結:https://github.com/zifuwanggg/JDTLosses
現有的損失函數
由於Jaccard Index和Dice Score是定義在集合上的,所以並不可導。為了使它們可導,目前常見的做法有兩種:一種是利用集合和相應向量的Lp模之間的關係,例如Soft Jaccard損失(SJL),Soft Dice損失(SDL)和Soft Tversky損失(STL )。
它們把集合的大小寫成對應向量的L1模,把兩個集合的交集寫成兩個對應向量的內積。另一種則是利用Jaccard Index的submodular性質,在集合函數上做Lovasz拓展,例如Lovasz-Softmax損失(LSL)。
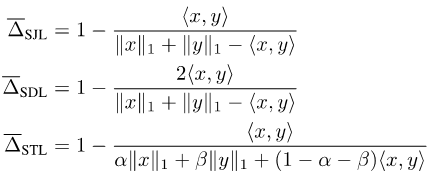 圖片
圖片
#這些損失函數都假定神經網路的輸出x是一個連續的向量,而標籤y則是離散的二值向量。如果標籤為軟標籤,即y不再是離散的二值向量,而是在一個連續向量時,這些損失函數就不再相容。
以SJL為例,考慮一個簡單的單一像素情況:
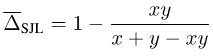 圖片
圖片
可以發現,對於任意的y > 0,SJL都會在x = 1時最小化,而在x = 0時最大化。因為一個損失函數應該在x = y時最小化,所以這顯然是不合理的。
與軟標籤相容的損失函數
為了讓原有的損失函數與軟標籤相容,需要在計算兩個集合的交集和並集時,引入兩個集合的對稱差:
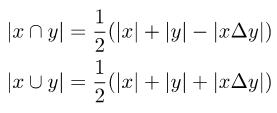 圖片
圖片
注意兩個集合的對稱差可以寫成兩個對應向量的差的L1模:
#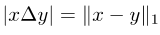 圖片
圖片
把以上綜合起來,我們提出了JDT損失。它們分別是SJL的變體Jaccard Metric損失(JML),SDL的變體Dice Semimetric 損失(DML)以及STL的變體Compatible Tversky損失(CTL)。
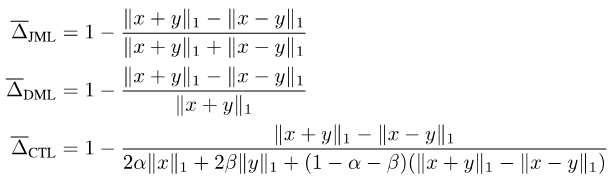 圖片
圖片
#JDT損失的性質
我們證明了JDT損失有著以下的一些性質。
性質1:JML是一個metric,DML是一個semimetric。
性質2:當y為硬標籤時,JML與SJL等價,DML與SDL等價,CTL與STL等價。
性質3:當y為軟標籤時,JML,DML,CTL都與軟標籤相容,即x = y ó f(x,y) = 0。
由於性質1,它們也因此被稱為Jaccard Metric損失和Dice Semimetric損失。性質2說明在僅以硬標籤進行訓練的一般情境下,JDT損失可以直接用來取代現有的損失函數,而不會造成任何的改變。
如何使用JDT損失
我們進行了大量的實驗,總結出了使用JDT損失的一些注意事項。
注意1:根據評價指標選擇對應的損失函數。如果評估指標是Jaccard Index,那麼應該選擇JML;如果評估指標是Dice Score,那麼應該選擇DML;如果想給予假陽性和假陰性不同的權重,那麼應該選擇CTL。其次,在優化細粒度的評估指標時,JDT損失也應做相對應的更改。
注意2:結合JDT損失和像素級的損失函數(例如Cross Entropy損失,Focal損失)。本文發現0.25CE 0.75JDT一般是不錯的選擇。
注意3:最好採用一個較短的epoch來訓練。加上JDT損失後,一般只需要Cross Entropy損失訓練時一半的epoch。
注意4:在多個GPU上進行分散式訓練時,如果GPU之間沒有額外的通信,JDT損失會錯誤的最佳化細粒度的評估指標,從而導致其在傳統的mIoU上效果變差。
注意5:在極端的類別不平衡的資料集上進行訓練時,需注意JDL損失是在每個類別上分別求損失再取平均,這可能會使訓練變得不穩定。
實驗結果
實驗證明,與Cross Entropy損失的基準相比,在用硬標籤訓練時,加上JDT損失可以有效提高模型的準確性。引入軟標籤後,可以進一步提高模型的準確性和校準性。
 圖片
圖片
#只要在訓練時加入JDT損失項,本文取得了語意分割上的知識蒸餾,半監督學習和多標註員的SOTA。
 圖片
圖片
 #圖片
#圖片

現有的評估指標
語意分割是一個像素層級的分類任務,因此可以計算每個像素的準確度:overall pixel-wise accuracy(Acc)。但因為Acc會偏向多數類,所以PASCAL VOC 2007採用了分別計算每個類別的像素準確率再取平均的評價指標:mean pixel-wise accuracy(mAcc)。
但由於mAcc不會考慮假陽性,從PASCAL VOC 2008之後,就一直採用平均交並比(per-dataset mIoU, mIoUD)來作為評估指標。 PASCAL VOC是最早的引入了語意分割任務的資料集,它所使用的評估指標也因此被之後的各個資料集所廣泛採用。
具體來說,IoU可以寫成:
#######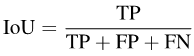 圖片
圖片
為了計算mIoUD,我們首先需要對每個類別c統計其在整個資料集上所有I張照片的true positive(真陽性,TP),false positive(假陽性,FP)和false negative(假陰性,FN):
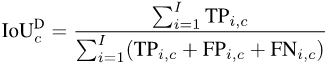 ##圖片
##圖片
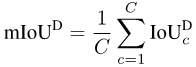
圖片
 因為mIoUD把整個資料集上所有像素的TP,FP和FN合計在一起,它會不可避免的偏向於那些大尺寸的物體。
因為mIoUD把整個資料集上所有像素的TP,FP和FN合計在一起,它會不可避免的偏向於那些大尺寸的物體。
在一些對安全要求較高的應用場景中,例如自動駕駛和醫療圖像,經常會存在一些尺寸小但是不可忽略的物體。
如下圖所示,不同照片上的汽車的大小有著明顯的差異。因此,mIoUD對大尺寸物體的偏好會嚴重的影響其對模型安全性能的評估。
細粒度的評價指標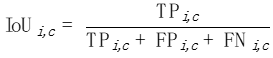 為了解決mIoUD的問題,我們提出細粒度的評價指標。這些指標在每張照片上分別計算IoU,從而能有效的降低對大尺寸物體的偏好。
為了解決mIoUD的問題,我們提出細粒度的評價指標。這些指標在每張照片上分別計算IoU,從而能有效的降低對大尺寸物體的偏好。
mIoUI
對每一個類別c,我們在每一張照片i上分別計算一個IoU:
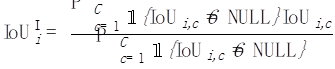
接著,對每一張照片i,我們把這張照片上出現過的所有類別進行平均:
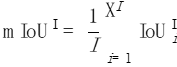
#最後,我們將所有照片的數值再進行平均:
圖片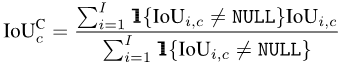
#mIoUC
類似的,正在計算出每個類別c在每一張照片i上的IoU之後,我們可以把每個類別c出現過的所有照片進行平均: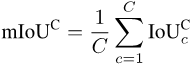
最後,把所有類別的數值再進行平均:
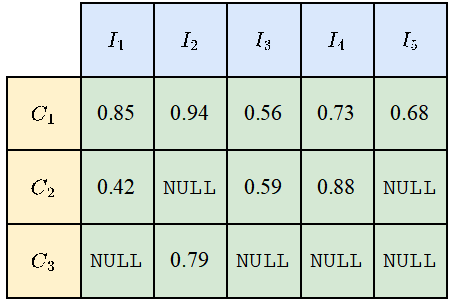
#由於不是所有的類別都會出現在所有的照片上,所以對於一些類別和照片的組合,會出現NULL值,如下圖所示。計算mIoUI時先將類別取平均再對照片取平均,計算mIoUC時先將照片取平均再對類別取平均。
這樣的結果是mIoUI可能會偏向那些出現得很頻繁的類別(例如下圖的C1),而這一般是不好的。但另一方面,在計算mIoUI時,因為每張照片都有一個IoU數值,這能幫助我們對模型和資料集進行一些審計和分析。
###圖片################最差情況的評估指標########## ##對於一些很注重安全的應用場景,我們很多時候更關心的是最差情況的分割質量,而細粒度指標的一個好處就是能計算相應的最差情況指標。我們以mIoUC為例,類似的方法也可以計算mIoUI對應的最差情況指標。 ##########對於每一個類別c,我們先把其出現過的所有照片(假設有Ic個這樣的照片)的IoU數值進行升序排序。接著,我們設q為一個很小的數字,例如1或5。然後,我們只用排序好的前Ic * q%張照片來計算最後的數值:
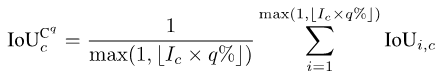 圖片
圖片
#有了每個類別c的數值之後,我們可以像之前那樣按類別取平均,從而得到mIoUC的最差情況指標。
實驗結果
我們在12個資料集上訓練了15個模型,發現如下的一些現象。
現象1:沒有一個模型在所有的評估指標上都能達到最好的效果。每個評量指標都有不同的重點,因此我們需要同時考慮多個評量指標來進行綜合的評估。
現象2:有些資料集上存在部分照片使得幾乎所有的模型都取得一個很低的IoU數值。這一方面是因為這些照片本身就很有挑戰性,例如一些很小的物體和強烈的明暗對比,另一方面也是因為這些照片的標籤有問題。因此,細粒度的評估指標能幫助我們進行模型審計(發現模型會犯錯的場景)和資料集審計(發現錯誤的標籤)。
現象3:神經網路的結構對優化細粒度的評估指標有著至關重要的作用。一方面,由ASPP(被DeepLabV3和DeepLabV3 採用)等結構所帶來的感受野的提升能幫助模型識別出大尺寸的物體,從而能有效提高mIoUD的數值;另一方面,encoder和decoder之間的長連結(被UNet和DeepLabV3 採用)能使模型辨識出小尺寸的物體,進而提升細粒度評估指標的數值。
現象4:最差情況指標的數值遠低於對應的平均指標的數值。下表展示了DeepLabV3-ResNet101在多個資料集上的mIoUC和對應的最差情況指標的數值。一個值得以後考慮的問題是,我們應該如何設計神經網路結構和最佳化方法來提高模型在最差情況指標下的表現?
 圖片
圖片
#現象5:損失函數對最佳化細粒度的評估指標有著至關重要的作用。與Cross Entropy損失的基準相比,如下表的(0,0,0)所示,當評估指標變得細粒度,使用相應的損失函數能極大的提升模型在細粒度評估指標上的性能。例如,在ADE20K上,JML和Cross Entropy損失的mIoUC的差異會大於7%。
 圖片
圖片
#未來工作
我們只考慮了JDT損失作為語義分割上的損失函數,但它們也可以應用在其他的任務上,例如傳統的分類任務。
其次,JDT損失只用在標籤空間中,但我們認為它們能被用來最小化任意兩個向量在特徵空間上的距離,例如用來取代Lp模和cosine距離。
參考資料:
https://arxiv.org/pdf/2302.05666.pdf
https://arxiv.org/pdf/ 2303.16296.pdf
https://arxiv.org/pdf/2310.19252.pdf
以上是三篇論文解決「語意分割的最佳化和評估」難題!魯汶/清華/牛津等聯合提出全新方法的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 國產開源MoE指標爆炸:GPT-4等級能力,API價格僅百分之一
May 07, 2024 pm 05:34 PM
國產開源MoE指標爆炸:GPT-4等級能力,API價格僅百分之一
May 07, 2024 pm 05:34 PM
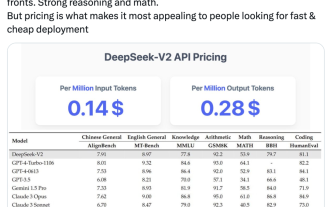
最新國產開源MoE大模型,剛亮相就火紅了。 DeepSeek-V2效能達GPT-4級別,但開源、可免費商用、API價格僅為GPT-4-Turbo的百分之一。因此一發布,立刻引發不小討論。圖片透過公佈的性能指標來看,DeepSeekV2的中文綜合能力超越一眾開源模型,同時GPT-4Turbo、文快4.0等閉源模型同處第一梯隊。英文綜合能力也和LLaMA3-70B同處第一梯隊,並且超過了同是MoE的Mixtral8x22B。在知識、數學、推理、程式設計等方面也表現出不錯性能。並支援128K上下文。圖片這
 十個常用的損失函數解釋以及Python程式碼實現
Apr 13, 2023 am 09:37 AM
十個常用的損失函數解釋以及Python程式碼實現
Apr 13, 2023 am 09:37 AM
什麼是損失函數?損失函數是一種衡量模型與資料吻合程度的演算法。損失函數測量實際測量值和預測值之間差距的一種方式。損失函數的值越高預測就越錯誤,損失函數值越低則預測越接近真實值。對每個單獨的觀測(數據點)計算損失函數。將所有損失函數(loss function)的值取平均值的函數稱為代價函數(cost function),更簡單的理解就是損失函數是針對單一樣本的,而代價函數是針對所有樣本的。損失函數與度量指標一些損失函數也可以被用來作為評估指標。但是損失函數和度量指標(metrics)有不同的目的。雖然
 常用的損失函數及Python實作範例
Apr 26, 2023 pm 01:40 PM
常用的損失函數及Python實作範例
Apr 26, 2023 pm 01:40 PM
什麼是損失函數?損失函數是一種衡量模型與資料吻合程度的演算法。損失函數測量實際測量值和預測值之間差距的一種方式。損失函數的值越高預測就越錯誤,損失函數值越低則預測越接近真實值。對每個單獨的觀測(數據點)計算損失函數。將所有損失函數(lossfunction)的值取平均值的函數稱為代價函數(costfunction),更簡單的理解就是損失函數是針對單一樣本的,而代價函數是針對所有樣本的。損失函數與度量指標一些損失函數也可以被用來作為評估指標。但是損失函數和度量指標(metrics)有不同的目的。雖然度量
 Java實現的視訊內容理解中的語意分割和視訊概念檢測技術和應用
Jun 18, 2023 pm 07:51 PM
Java實現的視訊內容理解中的語意分割和視訊概念檢測技術和應用
Jun 18, 2023 pm 07:51 PM
在現今的數位影片時代,影片內容理解技術在各個領域中起著重要的作用,如影片推薦、影片搜尋、影片自動標註等。其中,語義分割和視訊概念檢測技術是視訊內容理解的兩個主要面向。本文將從Java實現的角度出發,介紹語意分割和視訊概念偵測技術的基本概念及其在實際應用中的價值。一、語義分割技術語義分割技術是電腦視覺領域的重要研究方向,其目的是對影像或影片進行像素級別
 從指標到實作:如何利用PHPDepend測量軟體指標來改進PHP程式碼
Sep 15, 2023 am 09:33 AM
從指標到實作:如何利用PHPDepend測量軟體指標來改進PHP程式碼
Sep 15, 2023 am 09:33 AM
從指標到實務:如何利用PHPDepend測量軟體指標來改善PHP程式碼簡介:在軟體開發過程中,程式碼品質的評估是至關重要的。透過測量各種軟體指標,我們可以更了解程式碼的品質和效能,進而採取相應的措施來改進程式碼。本文將介紹如何使用PHPDepend工具來測量PHP程式碼的各項指標,並透過具體的程式碼範例來示範如何根據測量結果來改進程式碼。 PHP程式碼的指標測量PHPDep
 山寨幣市場即將迎來「爆炸性反彈」嗎?關注這三個指標就夠了
Jun 03, 2024 pm 05:15 PM
山寨幣市場即將迎來「爆炸性反彈」嗎?關注這三個指標就夠了
Jun 03, 2024 pm 05:15 PM
密切關註三個技術指標的加密貨幣交易員表示,山寨幣市場目前正處於“難以置信的階段”,如果歷史重演,可能很快就會進入“爆炸性反彈階段”。加密貨幣分析師MikybullCrypto在5月11日的一篇貼文中對他們的66,600X粉絲表示:「山寨幣市值目前正處於令人難以置信的階段,從歷史上看,隨後會出現爆炸性反彈。」懷疑階段是指儘管市場跡象積極,但投資者仍然持懷疑態度,過去30天加密貨幣恐懼和貪婪指數大幅下跌24個點就反映了這一點。目前&ldq
 語意分割中的像素層級準確度問題
Oct 09, 2023 am 08:13 AM
語意分割中的像素層級準確度問題
Oct 09, 2023 am 08:13 AM
語義分割是電腦視覺領域中一項重要的任務,旨在將影像中的每個像素分配給特定的語義類別。在語義分割中,像素層級的準確度是一個重要的指標,它衡量了模型對於每個像素的分類是否準確。然而,在實際應用中,我們往往會面臨準確度不高的問題。本文將討論語意分割中的像素層級準確度問題,並提供一些具體的程式碼範例。首先,我們需要了解語意分割的基本原理。常用的語意分割模型包括FCN
 深入淺出科技營運指標體系
Jun 08, 2023 pm 06:43 PM
深入淺出科技營運指標體系
Jun 08, 2023 pm 06:43 PM
引言提起科技營運指標,每個科技人都能說出幾個,例如交易量、回應時間、回應率、成功率等。這些指標都是對營運工作中某個領域工作的量化評估。但是,要評估科技運營的整體水平,就必須建立科技運營的指標體系,獲取全局性信息,進而透過這些信息去驅動運營工作的發展,達成組織目標。建置目標及定位G行建立科技營運可觀測指標體系,為管理人員提供多維度、精細化的營運管理分析框架,並以此為抓手,提升中心營運管理能力、決策水準及服務品質。指標體系建構遵循可量化、可比較、具備行動導向、多場景適配四個原則,聚焦實際業務場景,
