

斯奇拉姆排序 - 基於公平性的排序學習

在 2023 年舉行的國際學術會議 AIBT 2023 上,Ratidar Technologies LLC 發表了一篇基於公平性的排序學習演算法,並榮獲該會議的最佳論文報告獎。該演算法名為斯奇拉姆排序 (Skellam Rank),充分利用了統計學原理,結合了Pairwise Ranking和矩陣分解技術,以解決推薦系統中的準確率和公平性問題。由於推薦系統中創新的排序學習演算法很少,斯奇拉姆排序演算法表現出色,因此在會議上獲得了研究獎項。以下將介紹斯奇拉姆演算法的基本原理:
我們先回想一下泊松分佈:
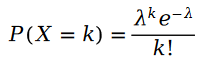
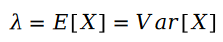
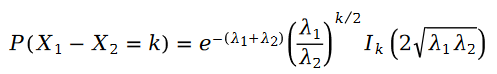
#泊松分佈的參數 的計算公式如下: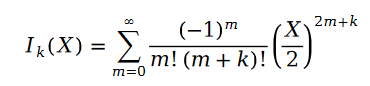
#兩個泊松變數的差異是斯奇拉姆分佈:
在公式中,我們有:
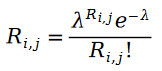
函數 叫做第一類貝塞爾函數。
有了這些最基本的統計學中的概念,以下讓我們來建立一個 Pairwise Ranking 的排序學習推薦系統吧!
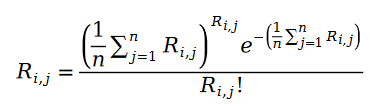
我們先認為使用者給物品的評分是個泊松分佈的概念。也就是說,使用者物品評分值服從以下機率分佈:
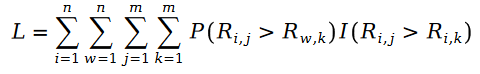
#之所以我們可以把使用者給物品打分數的過程描述為泊松過程,是因為用戶物品評分存在馬太效應,也就是說評分越高的用戶,評分的人越多,以至於我們可以用某個物品的評分的人的數量來近似該物品的評分的分佈。給某個物品打分數的人數服從什麼隨機過程?自然而然的,我們就會想到泊松過程。因為使用者給物品打分數的機率和該物品有多少人打分的機率相近,我們自然也就可以用泊松過程來近似使用者給物品打分的這一過程了。
我們下面把泊松過程的參數用樣本資料的統計量取代,得到下面的公式: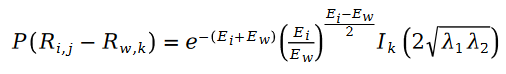
我們下面定義Pariwise Ranking 的最大似然函數公式。眾所周知,所謂Pairwise Ranking 指的是我們利用最大似然函數來求解模型參數,使得模型能夠最大程度地保持資料樣本中已知的排序對的關係: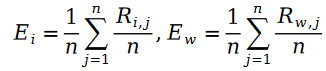
因為公式中的R 是泊松分佈,所以它們的差值,就是斯奇拉姆分佈,也就是說: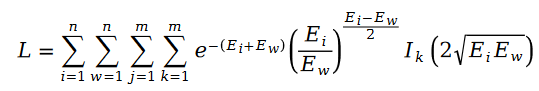
##其中變數E 是如下定義的:######################我們把斯奇拉姆分佈的公式帶入最大似然函數的損失函數L ,得到如下公式:######################在變數E 中出現的使用者評分值R ,我們利用矩陣分解的方式進行求解。將矩陣分解中的參數使用者特徵向量 U 和物品特徵向量 V 作為待求解變數:######
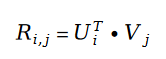
這裡我們先回顧矩陣分解的概念。矩陣分解的概念是在 2010 年左右的時候提出的推薦系統演算法,該演算法可以說是歷史上最成功的推薦系統演算法之一。時至今日,仍有大量的推薦系統公司利用矩陣分解演算法作為線上系統的baseline,而時下大熱的經典推薦演算法DeepFM 中的重要組件Factorization Machine,也是推薦系統演算法中的矩陣分解演算法後續的改進版本,和矩陣分解有千絲萬縷的關係。矩陣分解演算法有一個里程碑論文,是 2007 年的 Probabilistic Matrix Factorization,作者利用統計學習模型對矩陣分解這個線性代數中的概念重新建模,使得矩陣分解第一次有了紮實的數學理論基礎。
矩陣分解的基本概念,是利用向量的點乘,在對使用者評分矩陣進行降維的同時高效的預測未知的使用者評分。矩陣分解的損失函數如下:
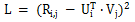
矩陣分解演算法有許多的變種,例如上海交大提出的SVDFeature,把向量U 和V 用線性組合的形式進行建模,使得矩陣分解的問題變成了特徵工程的問題。 SVDFeature 也是矩陣分解領域的里程碑論文。矩陣分解可以被應用在Pairwise Ranking 中用以取代未知的用戶評分,從而達到建模的目的,經典的應用案例包括Bayesian Pairwise Ranking 中的BPR-MF 演算法,而斯奇拉姆排序演算法就是藉鑑了同樣的思路。
我們用隨機梯度下降對斯奇拉姆排序演算法進行求解。因為隨機梯度下降在求解過程中,可以對損失函數進行大量的簡化從而達到求解的目的,我們的損失函數變成了下面的公式:
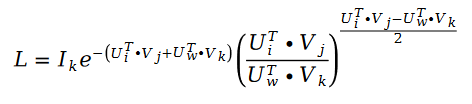
利用隨機梯度下降對未知參數U 和V 進行求解,我們得到了迭代公式如下:
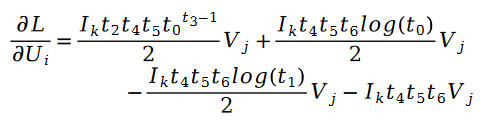
##其中:
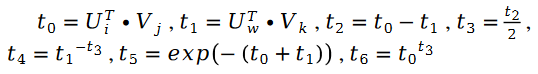
另外有:
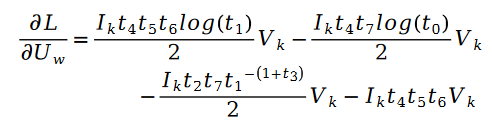
其中:
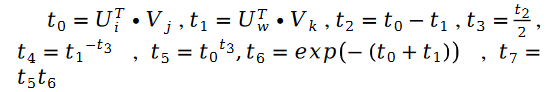
對於未知參數變數V 的求解類似,我們有以下公式:
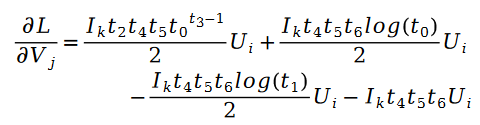
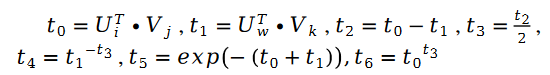
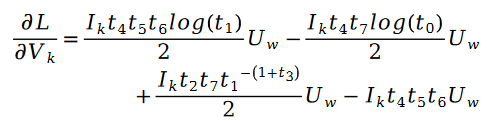
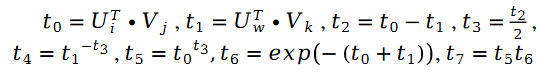
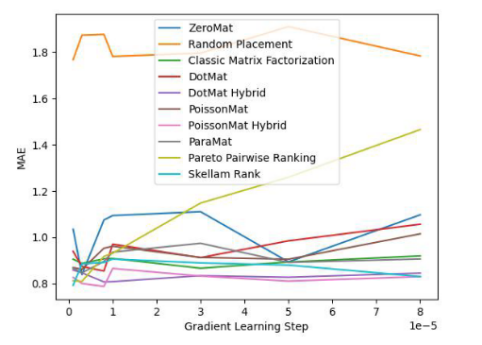
為了驗證演算法的有效性,論文作者在 MovieLens 1 Million Dataset 和 LDOS-CoMoDa Dataset 上進行了測試。第一個數據集包含了 6040 個用戶和 3706 部電影的評分,整個評分數據集大概有 100 萬評分數據,是推薦系統領域最知名的評分數據集合之一。第二個資料集合來自斯洛維尼亞,是網路上不多見的基於場景的推薦系統資料集合。該數據集合包含了 121 個用戶和 1232 部電影的評分。作者將斯奇拉姆排序和另外9 種推薦系統演算法進行了對比,主要評估指標為MAE (Mean Absolute Error,用來測試準確性)和Degree of Matthew Effect (主要用來測試公平性):
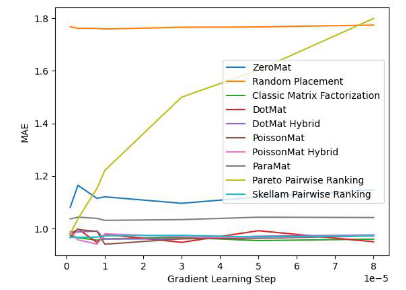
圖1. MovieLens 1 Million Dataset (MAE 指標)
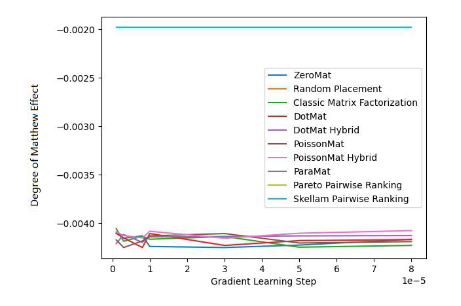
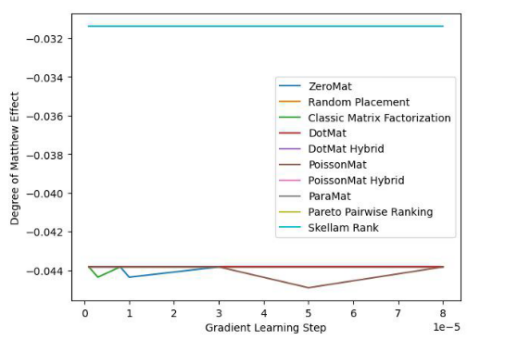
#圖2. MovieLens 1 Million Dataset (Degree of Matthew Effect 指標)
透過圖1 和圖2 ,我們發現斯奇拉姆排序在MAE 這項指標上表現優異,但在Grid Search 的整個實驗過程中,無法一直保證效能優於其他演算法。但在圖 2 中,我們發現斯奇拉姆排序在公平性指標上一騎絕塵,遙遙領先另外 9 種推薦系統演算法。
下面我們來看看演算法在LDOS-CoMoDa 資料集合上的表現:
以上是斯奇拉姆排序 - 基於公平性的排序學習的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 數字貨幣如何滾倉?數字貨幣滾倉平台有哪些?
Mar 31, 2025 pm 07:36 PM
數字貨幣如何滾倉?數字貨幣滾倉平台有哪些?
Mar 31, 2025 pm 07:36 PM
數字貨幣滾倉,即利用借貸放大交易槓桿以提高收益的投資策略。 本文詳解數字貨幣滾倉流程,包括選擇支持滾倉的交易平台(如Binance、OKEx、gate.io、Huobi、Bybit等),開通槓桿賬戶,設置槓桿倍數,借入資金進行交易,以及實時監控市場並調整倉位或追加保證金以避免爆倉等關鍵步驟。 然而,滾倉交易風險極高,投資者需謹慎操作並製定完善的風險管理策略。 了解更多數字貨幣滾倉技巧,請繼續閱讀。
 gate.io交易平台交易手續費怎麼計算?
Mar 31, 2025 pm 09:15 PM
gate.io交易平台交易手續費怎麼計算?
Mar 31, 2025 pm 09:15 PM
Gate.io交易平台手續費因交易類型、交易對、用戶VIP等級等因素而異。現貨交易默認費率為0.15%(VIP0等級,Maker和Taker),但會根據用戶30天交易量和GT持倉量調整VIP等級,等級越高費率越低,並支持GT平台幣抵扣,最低可享55折優惠。合約交易默認費率為Maker 0.02%,Taker 0.05%(VIP0等級),同樣受VIP等級影響,且不同合約類型和槓桿
 歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
歐易okex賬號怎麼註冊、使用、註銷教程
Mar 31, 2025 pm 04:21 PM
本文詳細介紹了歐易OKEx賬號的註冊、使用和註銷流程。註冊需下載APP,輸入手機號或郵箱註冊,完成實名認證。使用方面涵蓋登錄、充值提現、交易以及安全設置等操作步驟。而註銷賬號則需要聯繫歐易OKEx客服,提供必要信息並等待處理,最終獲得賬號註銷確認。 通過本文,用戶可以輕鬆掌握歐易OKEx賬號的完整生命週期管理,安全便捷地進行數字資產交易。
 幣安binance電腦版入口幣安binance電腦版pc官網登錄入口
Mar 31, 2025 pm 04:36 PM
幣安binance電腦版入口幣安binance電腦版pc官網登錄入口
Mar 31, 2025 pm 04:36 PM
本文提供Binance幣安電腦版登錄與註冊的完整指南。首先,詳細講解了幣安電腦版登錄步驟:在瀏覽器搜索“幣安官網”,點擊登錄按鈕,輸入郵箱和密碼(啟用2FA需輸入驗證碼)即可登錄。其次,文章闡述了註冊流程:點擊“註冊”按鈕,填寫郵箱地址,設置強密碼,驗證郵箱即可完成註冊。最後,文章還特別強調了賬戶安全,提醒用戶注意官方域名、網絡環境以及定期更新密碼,確保賬戶安全,更好地使用幣安電腦版提供的各項功能,例如查看行情、進行交易和管理資產。
 虛擬幣app軟件推薦網站有哪些?
Mar 31, 2025 pm 09:06 PM
虛擬幣app軟件推薦網站有哪些?
Mar 31, 2025 pm 09:06 PM
本文推薦十個知名的虛擬幣相關APP推薦網站,涵蓋幣安學院(Binance Academy)、OKX Learn、CoinGecko、CryptoSlate、CoinDesk、Investopedia、CoinMarketCap、火幣大學(Huobi University)、Coinbase Learn和CryptoCompare。這些網站不僅提供虛擬貨幣市場數據、價格走勢分析等信息,還提供豐富的學習資源,包括區塊鏈基礎知識、交易策略、以及各個交易平台APP的使用教程和評測,幫助用戶更好地了解和使
 貨幣交易網官方網站大全2025
Mar 31, 2025 pm 03:57 PM
貨幣交易網官方網站大全2025
Mar 31, 2025 pm 03:57 PM
全球用户量排名前列,支持现货、合约、Web3钱包等全品类交易,安全性高且手续费低。历史悠久的综合交易平台,以合规性和高流动性著称,支持多语言服务。行业龙头,覆盖币币交易、杠杆、期权等,流动性强且支持BNB抵扣费用。
 web3在哪個平台交易?
Mar 31, 2025 pm 07:54 PM
web3在哪個平台交易?
Mar 31, 2025 pm 07:54 PM
本文盤點十大知名Web3交易平台,包括幣安(Binance)、歐易(OKX)、Gate.io(芝麻開門)、Kraken、Bybit、Coinbase、KuCoin、Bitget、Gemini和Bitstamp。 文章詳細對比了各平台的特色,例如幣種數量、交易類型(現貨、期貨、期權、NFT等)、手續費、安全性、合規性、用戶群體等,旨在幫助投資者選擇最合適的交易平台。無論是高頻交易者、合約交易愛好者,還是注重合規性和安全性的投資者,都能從中找到參考信息。
 芝麻交易所gate網頁版進入 芝麻gate交易所官方網頁版點擊進入
Mar 31, 2025 pm 06:18 PM
芝麻交易所gate網頁版進入 芝麻gate交易所官方網頁版點擊進入
Mar 31, 2025 pm 06:18 PM
芝麻交易所Gate.io網頁版登錄便捷,只需在瀏覽器地址欄輸入“gate.io”並回車即可訪問官方網站。簡潔的主頁提供清晰的“登錄”和“註冊”選項,用戶可根據自身情況選擇登錄已註冊賬戶或註冊新賬戶。註冊或登錄後,即可進入交易主界面,進行加密貨幣交易、查看行情及賬戶管理等操作。 Gate.io網頁版界面友好,操作簡便,適合新手和專業交易者使用。
