
趕在春節前,通義千問大模型(Qwen)的 1.5 版上線了。今天上午,新版本的消息引發了 AI 社群關注。
新版大機型包括六個型號尺寸:0.5B、1.8B、4B、7B、14B和72B。其中,最強版本的效能超越了GPT 3.5和Mistral-Medium。此版本包含Base模型和Chat模型,並提供多語言支援。
阿里通義千問團隊表示,相關技術也已經上線到了通義千問官網和通義千問 App。
除此之外,今天Qwen 1.5 的發布還有以下一些重點:
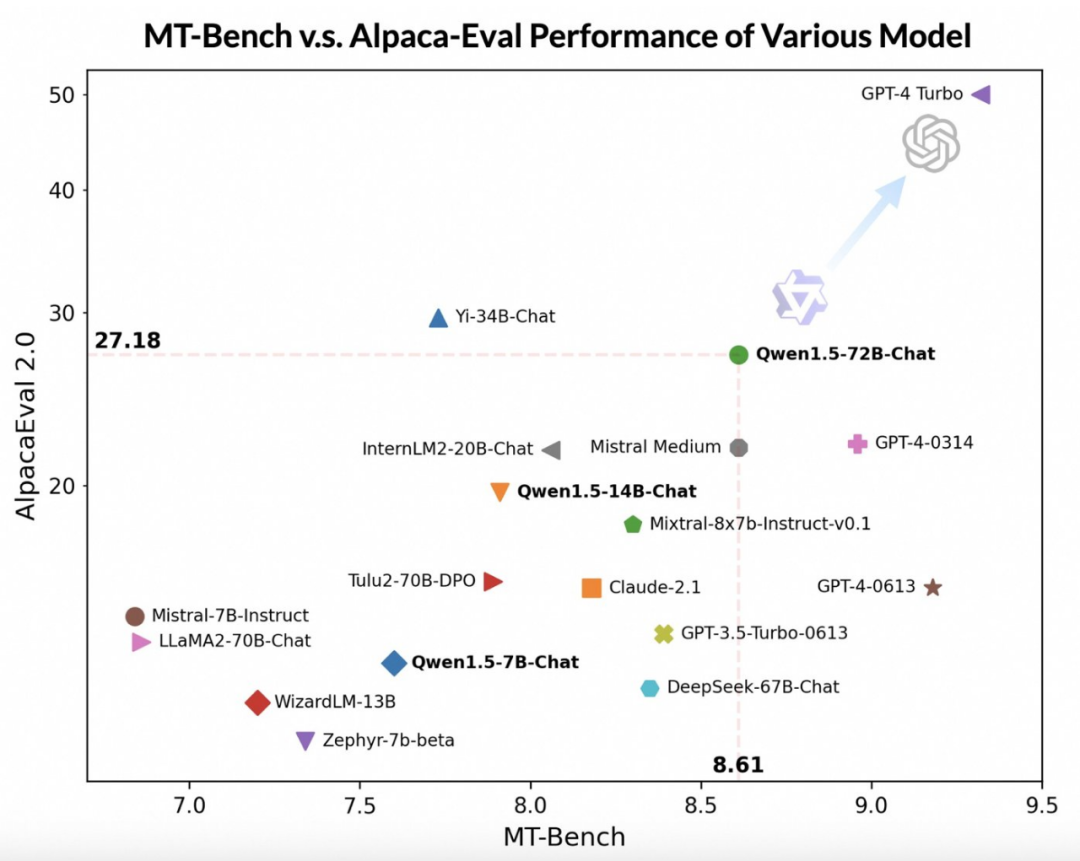
通義千問團隊指出,儘管大模型的評分可能與回答的長度有關,但人類的觀察結果表明,Qwen1.5並沒有因為產生過長的回答而影響評分。根據AlpacaEval 2.0的數據,Qwen1.5-Chat的平均長度為1618,與GPT-4的長度相同,比GPT-4-Turbo短。
通義千問的開發者表示,近幾個月以來,他們一直致力於建立一個卓越的模型,並不斷提升開發者的使用體驗。

基礎能力
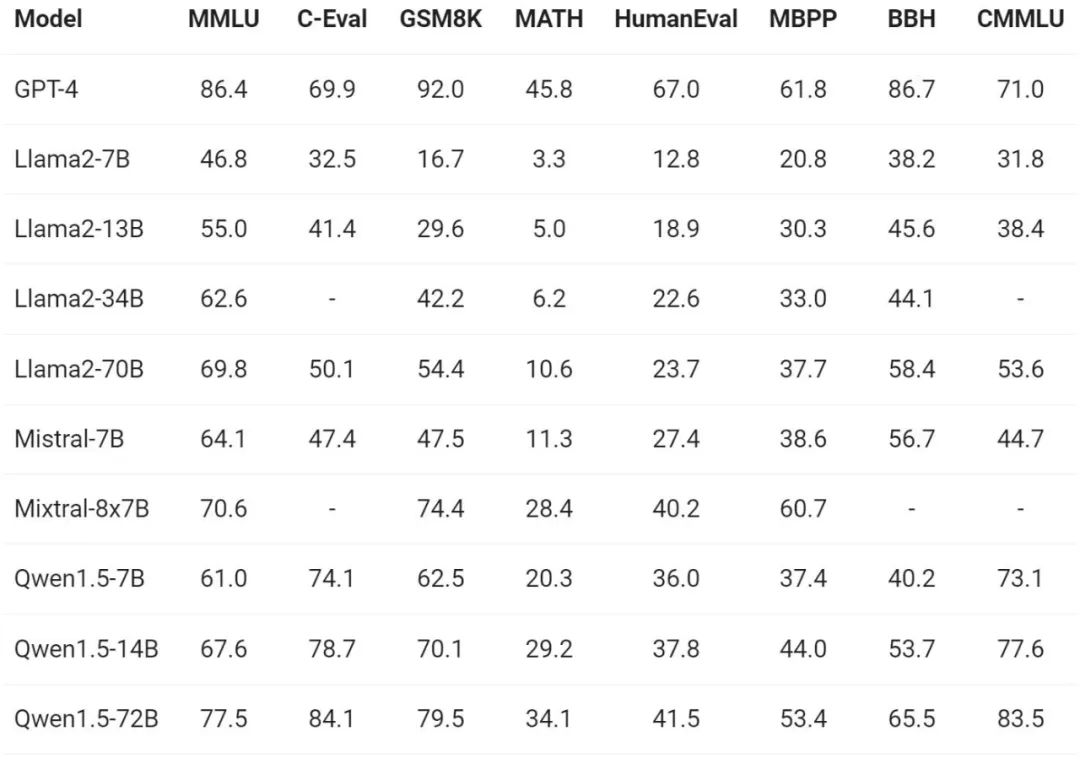
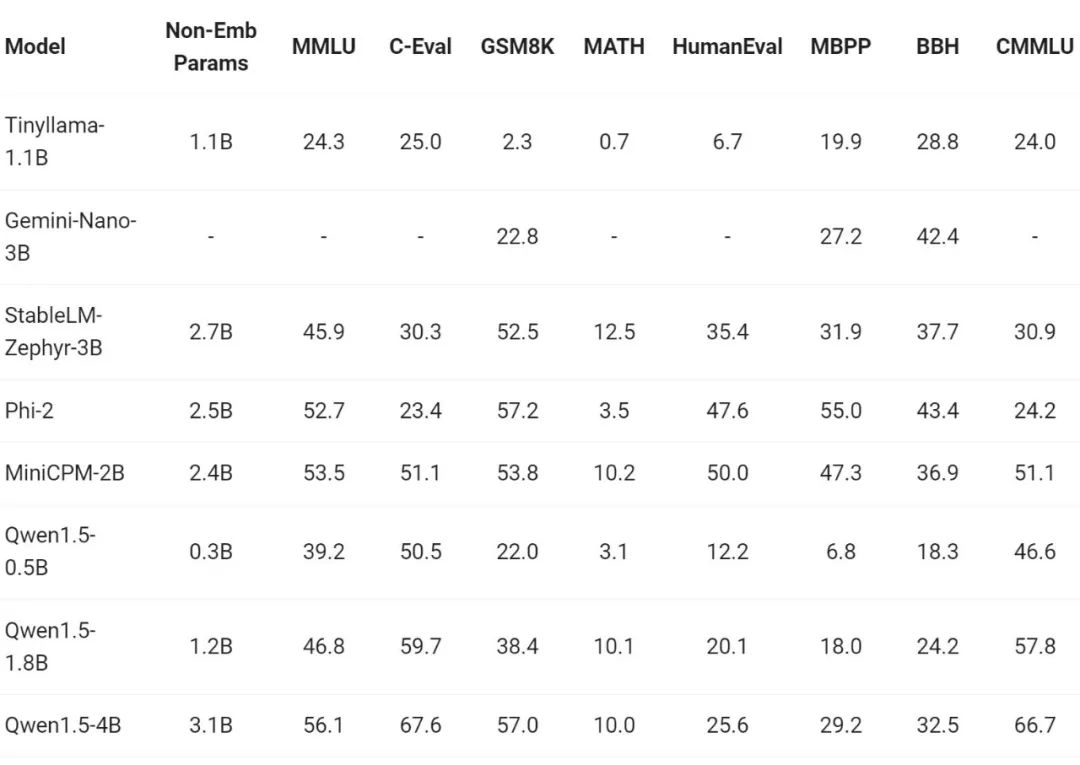
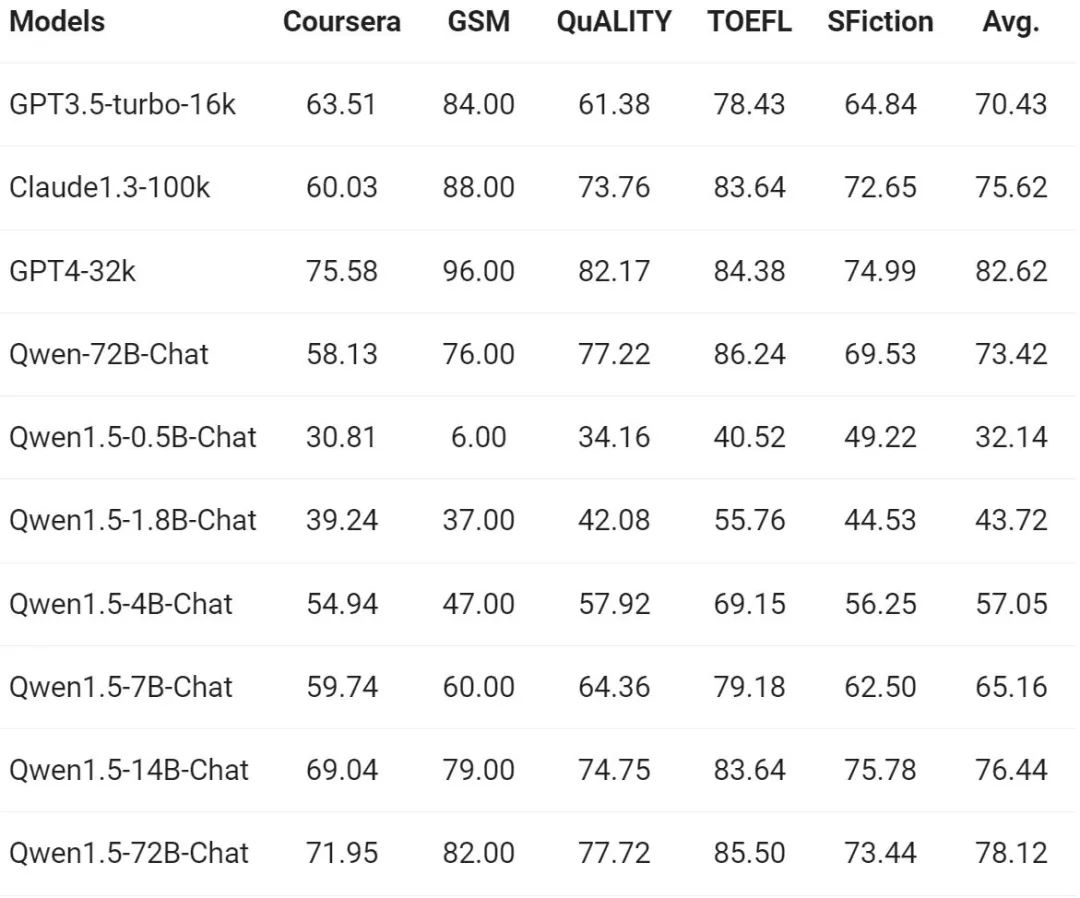
最近一段時間,小型模型的建構是業內熱點之一,通義千問團隊將模型參數小於70 億的Qwen1.5 模型與社區中重要的小型模型進行了比較:
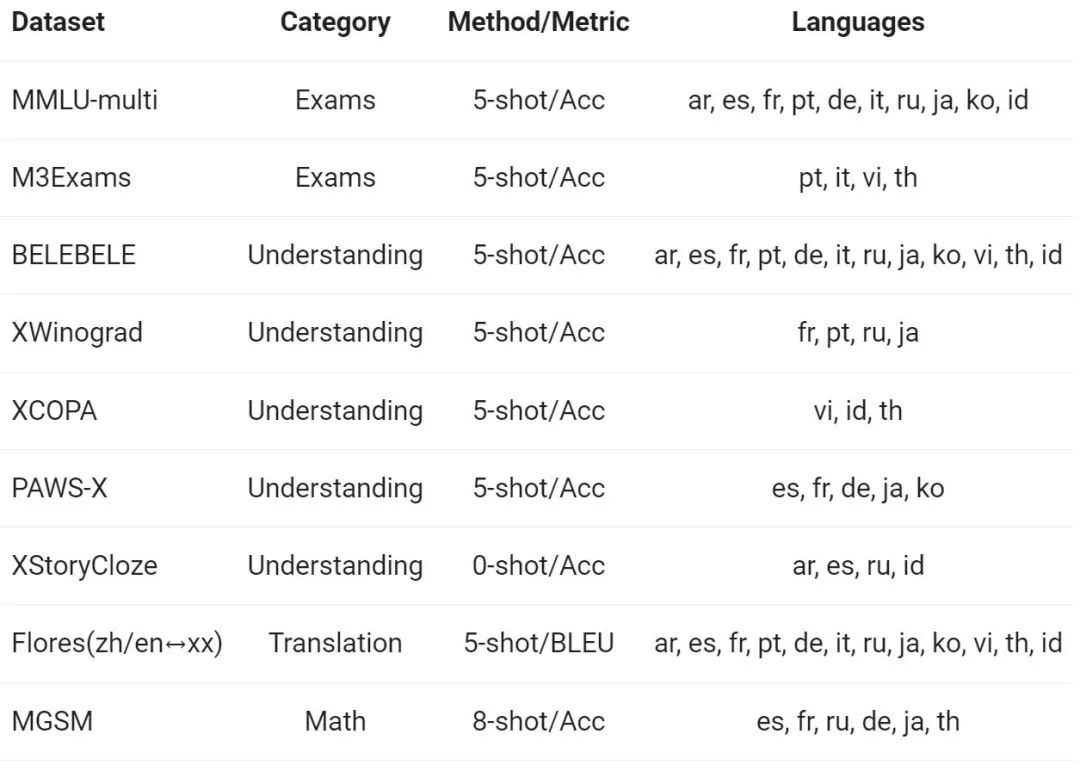
多語言能力
#
上述結果表明,Qwen1.5 Base 模型在12 種不同語言的多語言能力方面表現出色,在學科知識、語言理解、翻譯、數學等各個維度的評估中,均展現了不錯的結果。更進一步地,在Chat 模型的多語言能力上,可以觀察到如下結果:
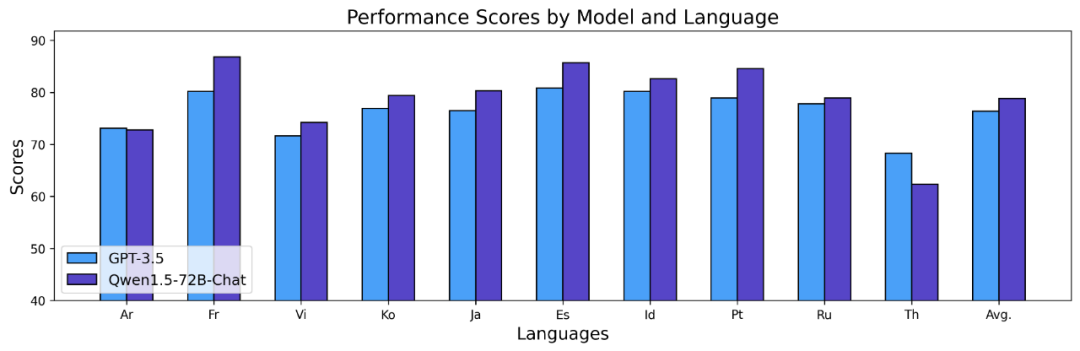
隨著長序列理解的需求不斷增加,阿里在新版本上提升了千問模型的相應能力,全系列Qwen1.5 模型支援32K tokens 的上下文。通義千問團隊在 L-Eval 基準上評估了 Qwen1.5 模型的性能,該基準衡量了模型根據長上下文產生響應的能力。結果如下:
從結果來看,即使像Qwen1.5-7B-Chat 這樣的小規模模型,也能表現出與GPT -3.5 可比較的性能,而最大的模型Qwen1.5-72B-Chat 僅略微落後於GPT4-32k。
值得一提的是,以上結果僅展示了 Qwen 1.5 在 32K tokens 長度下的效果,並不代表模型最大隻能支持 32K 長度。開發者可以在 config.json 中,將 max_position_embedding 嘗試修改為更大的值,觀察模型在更長上下文理解場景下,是否可以實現令人滿意的效果。
如今,通用語言模型的一大魅力在於其與外部系統對接的潛在能力。 RAG 作為一個在社群中快速興起的任務,有效應對了大語言模型面臨的一些典型挑戰,例如幻覺、無法取得即時更新或私人資料等問題。此外,語言模型在使用 API 和根據指令及範例編寫程式碼方面,展現出了強大的能力。大模型能夠使用程式碼解釋器或扮演 AI 智能體,發揮更廣闊的價值。
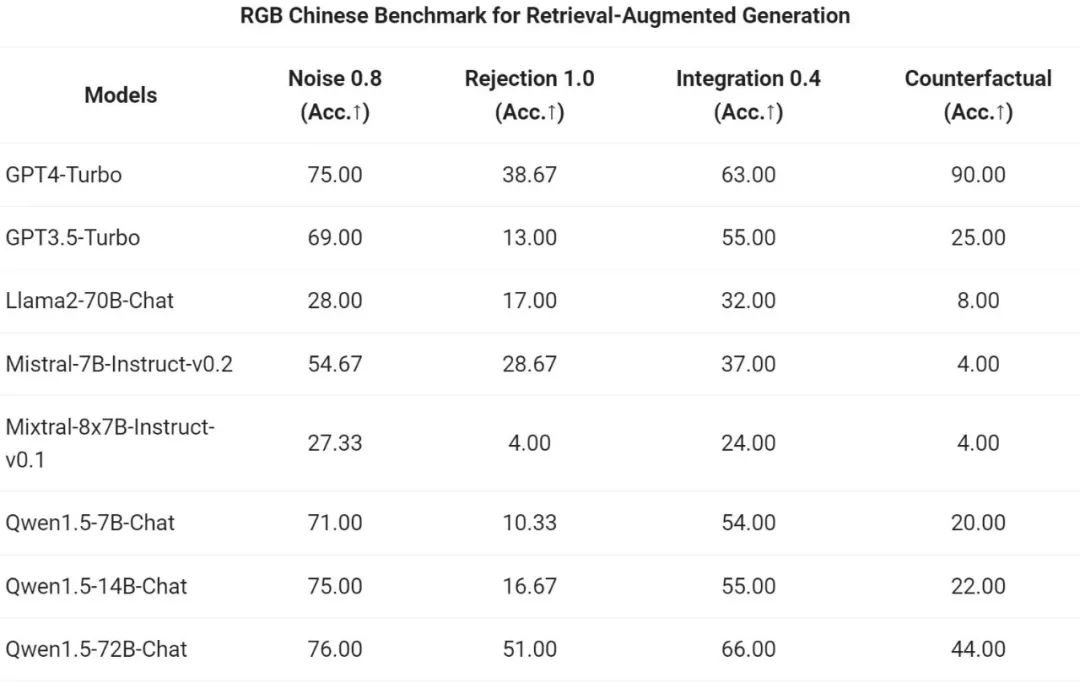
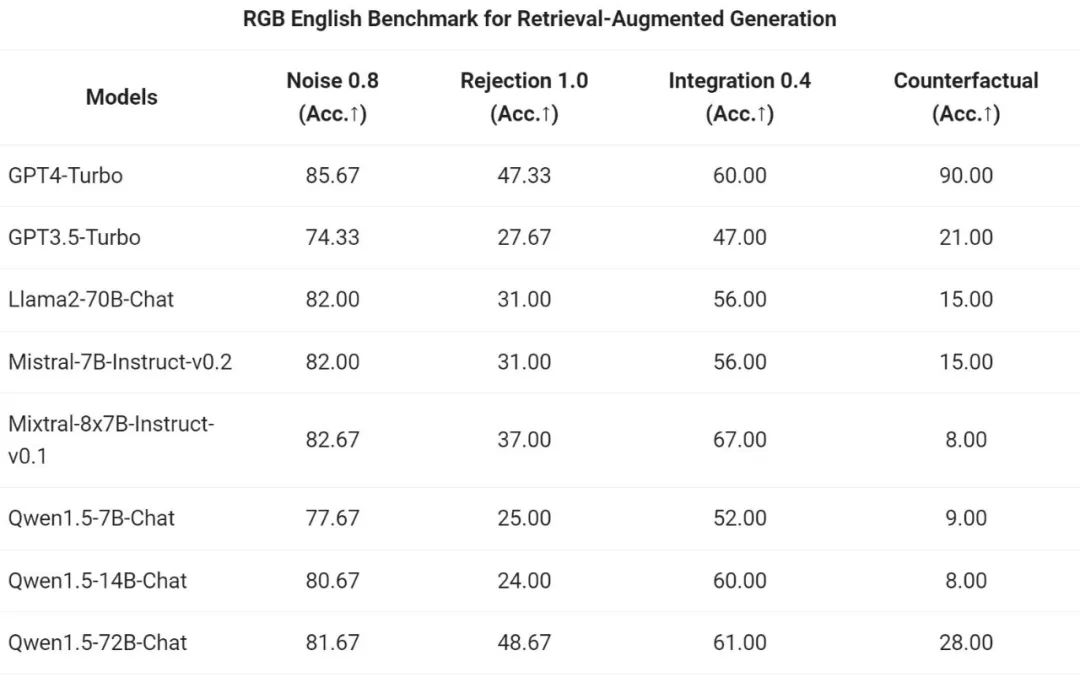
通義千問團隊對 Qwen1.5 系列 Chat 模型在 RAG 任務上的端到端效果進行了評估。評測基於RGB 測試集,是用於中英文RAG 評估的集合:
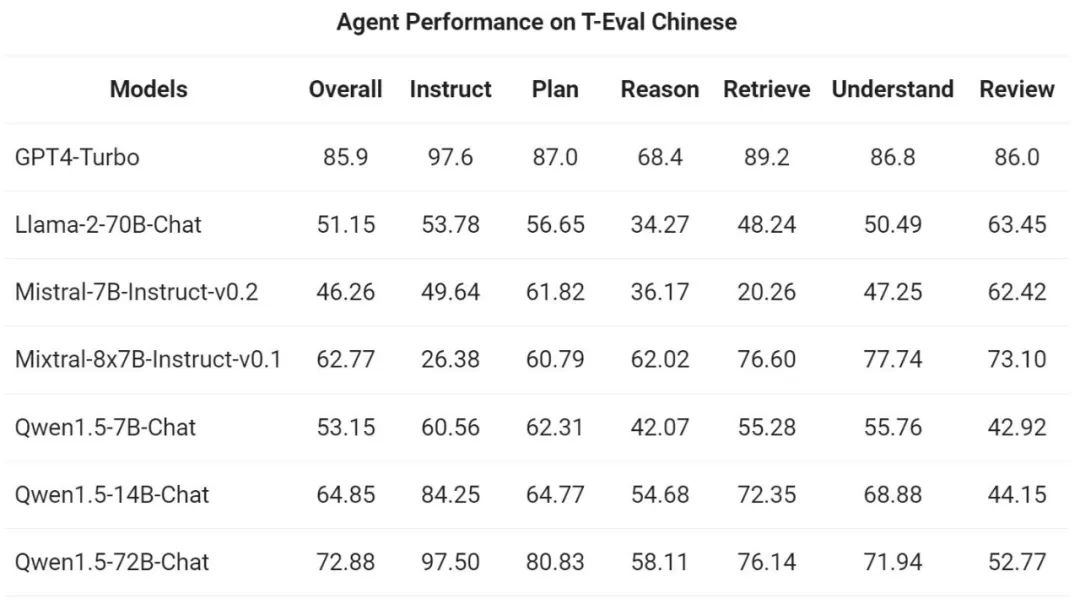
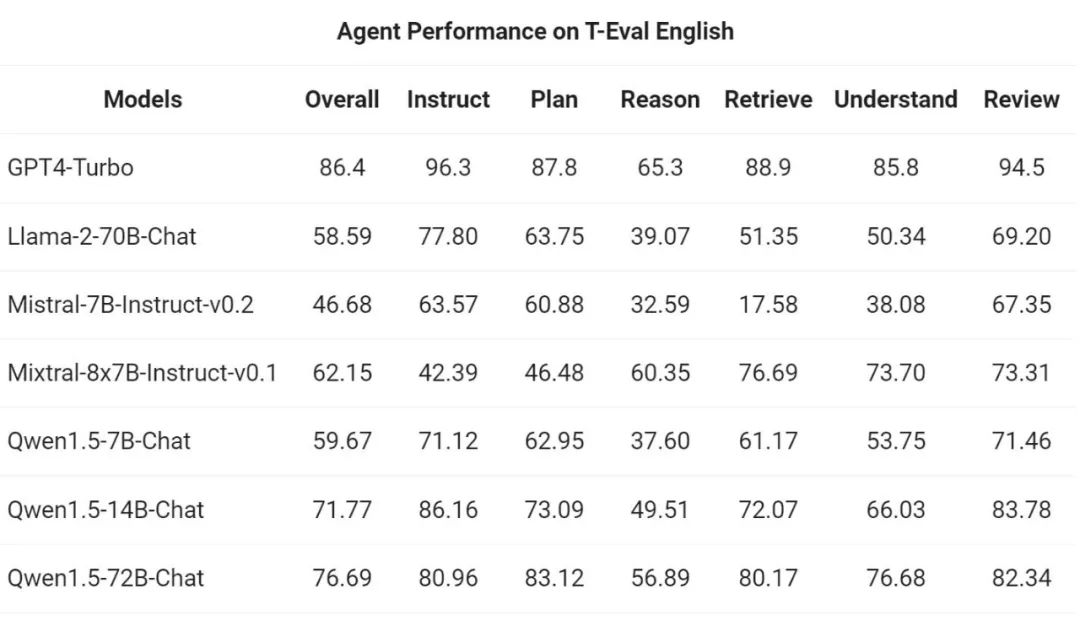
然後,通義千問團隊在T-Eval 基準測試中評估了Qwen1.5 作為通用智能體運作的能力。所有Qwen1.5 模型都沒有專門面向基準進行最佳化:
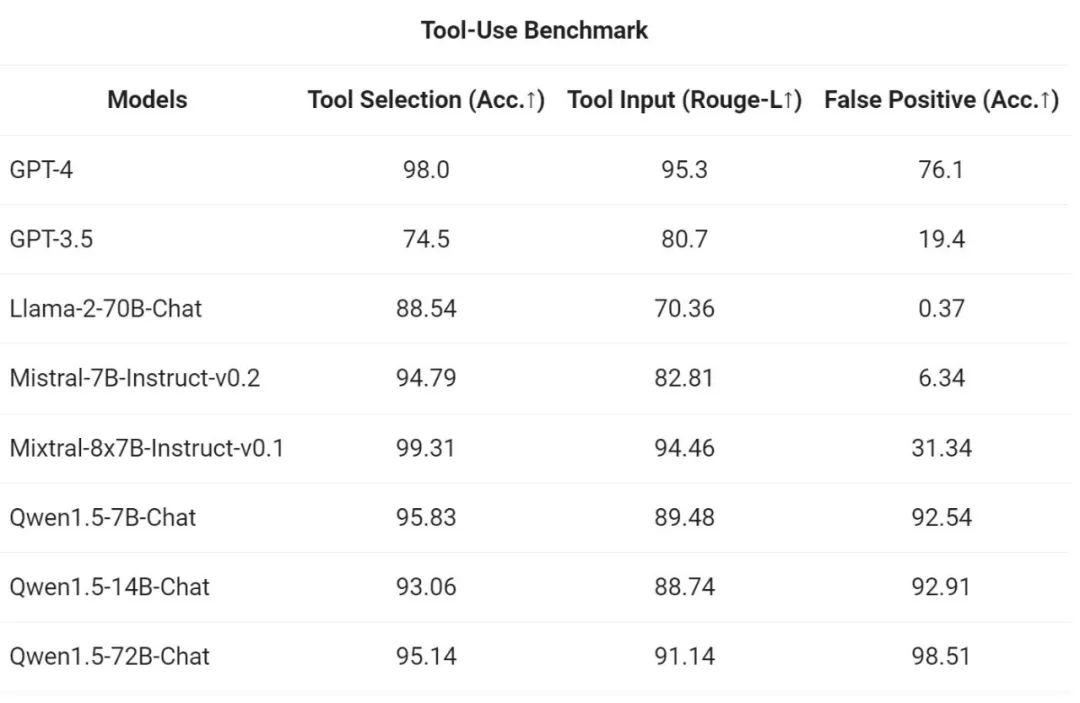
為了測試工具呼叫能力,阿里使用自身開源的評估基準測試模型正確選擇、呼叫工具的能力,結果如下:
#最後,由於Python 程式碼解釋器已成為高級LLM 越來越強大的工具,通義千問團隊也在先前開源的評估基準上評估了新模型利用這工具的能力:
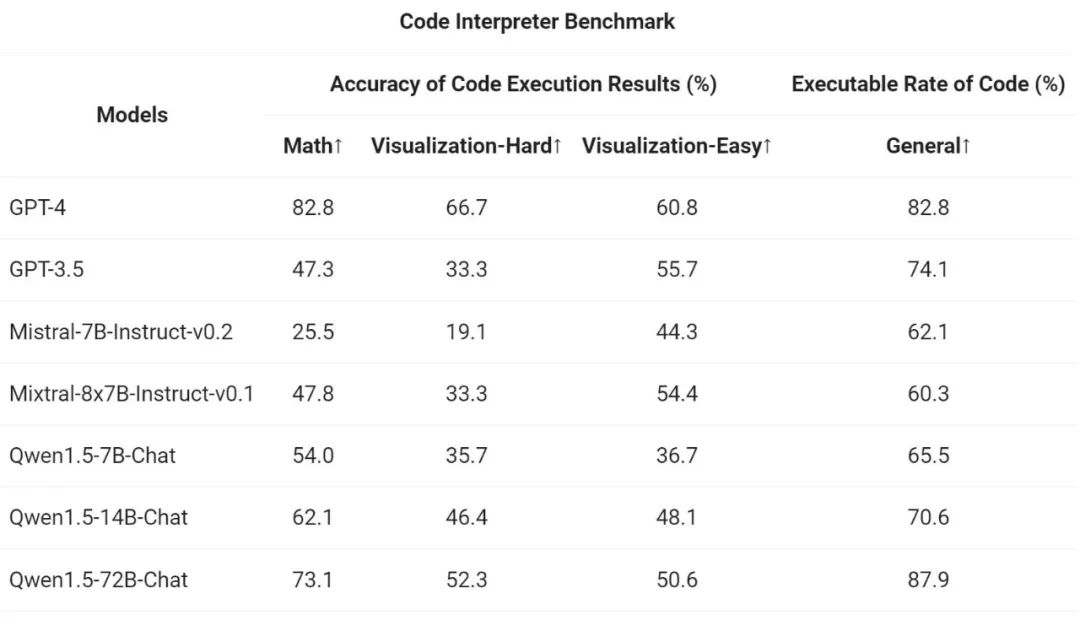
結果表明,較大的Qwen1.5-Chat 模型通常優於較小的模型,其中Qwen1.5-72B-Chat 接近GPT-4 的工具使用效能。不過,在數學解題和視覺化等代碼解釋器任務中,即使是最大的 Qwen1.5-72B-Chat 模型也會因編碼能力而明顯落後於 GPT-4。阿里表示,將在未來的版本中,在預訓練和對齊過程中提高所有 Qwen 模型的編碼能力。
Qwen1.5 與 HuggingFace transformers 程式碼庫進行了整合。從 4.37.0 版本開始,開發者可以直接使用 transformers 庫原生程式碼,而不載入任何自訂程式碼(指定 trust_remote_code 選項)來使用 Qwen1.5。
在開源生態上,阿里已經與vLLM、SGLang(用於部署)、AutoAWQ、AutoGPTQ(用於量化)、Axolotl、LLaMA-Factory(用於微調)以及llama.cpp(用於本地LLM 推理)等框架合作,所有這些框架現在都支持Qwen1.5。 Qwen1.5 系列目前也可以在 Ollama 和 LMStudio 等平台上使用。
以上是通義千問再開源,Qwen1.5帶來六種體量模型,表現超越GPT3.5的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















