

從大物件釋放記憶體


php小編柚子為您介紹一種優化記憶體使用的技巧-從大物件中釋放記憶體。在開發過程中,我們經常會創建一些大對象,例如大數組或大型資料庫查詢結果,這些對象會佔用大量記憶體資源。當我們使用完這些物件後,及時釋放記憶體是一種良好的程式設計習慣。本文將向您展示如何從大物件中釋放內存,以提高應用程式的效能和效率。
問題內容
我遇到了一些我不明白的事情。希望大家幫忙!
資源:
- https://medium.com/@chaewonkong/solving-memory-leak-issues-in-go-http-clients-ba0b04574a83
- https://www.golinuxcloud.com/golang-garbage-collector/
我在幾篇文章中讀到建議,在我們不再需要它們之後,我們可以透過將大切片和映射(我想這適用於所有引用類型)設定為nil 來簡化gc 的工作。這是我讀過的範例之一:
func ProcessResponse(resp *http.Response) error {
data, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
// Process data here
data = nil // Release memory
return nil
}據我了解,當函數 processresponse 完成時,data 變數將超出範圍,基本上將不再存在。然後,gc 將驗證是否沒有對 []byte 切片(data 指向的切片)的引用,並將清除記憶體。
將 data 設定為 nil 如何改善垃圾收集?
謝謝!
解決方法
正如其他人已經指出的那樣:在返回之前設定data = nil 不會改變 gc 方面的任何內容。 go 編譯器將應用最佳化,並且 golang 的垃圾收集器在不同的階段工作。用最簡單的術語(有許多遺漏和過度簡化):設定 data = nil ,並刪除對底層切片的所有引用不會觸發不再引用的記憶體的原子樣式釋放。一旦切片不再被引用,它就會被標記為這樣,並且關聯的記憶體直到下一次掃描才會被釋放。
垃圾收集是一個難題,很大程度上是因為它不是那種具有能為所有用例產生最佳結果的最佳解決方案的問題。多年來,go 運行時已經發展了很多,重要的工作正是在運行時垃圾收集器上完成的。結果是,在極少數情況下,簡單的 somevar = nil 會產生即使很小的差異,更不用說明顯的差異了。
如果您正在尋找一些簡單的經驗法則類型提示,這些提示可能會影響與垃圾收集(或一般的運行時記憶體管理)相關的運行時開銷,我確實知道這句話似乎模糊地涵蓋了一個在你的問題中:
建議我們可以透過設定大切片和映射來簡化 gc 的工作
在分析程式碼時,這可以產生顯著的結果。假設您正在讀取需要處理的大量數據,或者您必須執行某種其他類型的批次操作並返回切片,那麼人們編寫這樣的內容並不罕見:
func processstuff(input []sometypes) []resulttypes {
data := []resulttypes{}
for _, in := range input {
data = append(data, processt(in))
}
return data
}透過將程式碼變更為以下內容可以輕鬆優化:
func processstuff(input []sometypes) []resulttypes {
data := make([]resulttypes, 0, len(input)) // set cap
for _, in := range input {
data = append(data, processt(in))
}
return data
}第一個實作中發生的情況是,您使用 len 和 cap 為 0 建立一個切片。第一次呼叫 append 時,您超出了切片的當前容量,這將導致運行時分配記憶體。正如此處所解釋的,新容量的計算相當簡單,記憶體被分配,資料被分配複製過來:
t := make([]byte, len(s), (cap(s)+1)*2) copy(t, s)
本質上,每次當要附加的切片已滿時(即len == cap)呼叫append 時,您將分配一個可容納: (len 1) * 2 元素的新切片。知道在第一個範例中 data 以 len 和 cap == 0 開頭,讓我們看看這意味著什麼:
1st iteration: append creates slice with cap (0+1) *2, data is now len 1, cap 2 2nd iteration: append adds to data, now has len 2, cap 2 3rd iteration: append allocates a new slice with cap (2 + 1) *2, copies the 2 elements from data to this slice and adds the third, data is now reassigned to a slice with len 3, cap 6 4th-6th iterations: data grows to len 6, cap 6 7th iteration: same as 3rd iteration, although cap is (6 + 1) * 2, everything is copied over, data is reassigned a slice with len 7, cap 14
如果切片中的資料結構較大(即許多嵌套結構、大量間接尋址等),那麼這種頻繁的重新分配和複製可能會變得相當昂貴。如果您的程式碼包含大量此類循環,它將開始顯示在 pprof 中(您將開始看到花費大量時間呼叫 gcmalloc)。此外,如果您正在處理 15 個輸入值,您的資料切片最終將如下所示:
dataslice {
len: 15
cap: 30
data underlying_array[30]
}這意味著您將為 30 個值分配內存,而您只需要 15 個值,並且您將將該內存分配為 4 個逐漸增大的區塊,並在每次重新分配時複製資料。
相較之下,第二個實作將在循環之前分配一個如下所示的資料片:
data {
len: 0
cap: 15
data underlying_array[15]
}它是一次性分配的,因此不需要重新分配和複製,並且返回的切片將佔用一半的記憶體空間。從這個意義上說,我們首先在開始時分配更大的記憶體區塊,以減少稍後所需的增量分配和複製呼叫的數量,這總體上會降低運行時成本。
如果我不知道需要多少内存怎么办
这是一个公平的问题。这个例子并不总是适用。在这种情况下,我们知道需要多少个元素,并且可以相应地分配内存。有时,世界并不是这样运作的。如果您不知道最终需要多少数据,那么您可以:
- 做出有根据的猜测:gc 很困难,而且与您不同的是,编译器和 go 运行时缺乏模糊逻辑,人们必须提出现实、合理的猜测。有时它会像这样简单:“嗯,我从该数据源获取数据,我们只存储最后 n 个元素,所以最坏的情况下,我将处理 n 个元素”,有时它有点模糊,例如:您正在处理包含 sku、产品名称和库存数量的 csv。您知道 sku 的长度,可以假设库存数量为 1 到 5 位数字之间的整数,产品名称平均为 2-3 个单词长。英文单词的平均长度为 6 个字符,因此您可以粗略地了解 csv 行由多少字节组成:假设 sku == 10 个字符,80 个字节,产品描述 2.5 * 6 * 8 = 120 个字节,以及 ~ 4 个字节表示库存计数 + 2 个逗号和一个换行符,平均预期行长度为 207 个字节,为了谨慎起见,我们将其称为 200。统计输入文件,将其大小(以字节为单位)除以 200,您应该对行数有一个可用的、稍微保守的估计。在该代码末尾添加一些日志记录,比较上限与估计值,然后您可以相应地调整您的预测计算。
- 分析您的代码。有时,您会发现自己正在开发新功能或全新项目,而您没有历史数据可以依靠进行猜测。在这种情况下,您可以简单地猜测,运行一些测试场景,或者启动一个测试环境来提供您的代码生产数据版本并分析代码。当您正在主动分析一两个切片/映射的内存使用/运行时成本时,我必须强调这是优化。仅当这是瓶颈或明显问题时(例如,运行时内存分配阻碍了整体分析),您才应该在这方面花费时间。在绝大多数情况下,这种级别的优化将牢牢地属于微优化的范畴。 坚持80-20原则
回顾
不,将一个简单的切片变量设置为 nil 在 99% 的情况下不会产生太大影响。创建和附加到地图/切片时,更可能产生影响的是通过使用 make() + 指定合理的 cap 值来减少无关分配。其他可以产生影响的事情是使用指针类型/接收器,尽管这是一个需要深入研究的更复杂的主题。现在,我只想说,我一直在开发一个代码库,该代码库必须对远远超出典型 uint64 范围的数字进行操作,不幸的是,我们必须能够以更精确的方式使用小数比 float64 将允许。我们通过使用像 holiman/uint256 这样的东西解决了 uint64 问题,它使用指针接收器,并解决shopspring/decimal 的十进制问题,它使用值接收器并复制所有内容。在花费大量时间优化代码之后,我们已经达到了使用小数时不断复制值的性能影响已成为问题的地步。看看这些包如何实现加法等简单操作,并尝试找出哪个操作成本更高:
// original a, b := 1, 2 a += b // uint256 version a, b := uint256.NewUint(1), uint256.NewUint(2) a.Add(a, b) // decimal version a, b := decimal.NewFromInt(1), decimal.NewFromInt(2) a = a.Add(b)
这些只是我在最近的工作中花时间优化的几件事,但从中得到的最重要的一点是:
过早的优化是万恶之源
当您处理更复杂的问题/代码时,您需要花费大量精力来研究切片或映射的分配周期,因为潜在的瓶颈和优化需要付出很大的努力。您可以而且可以说应该采取措施避免过于浪费(例如,如果您知道所述切片的最终长度是多少,则设置切片上限),但您不应该浪费太多时间手工制作每一行,直到该代码的内存占用尽可能小。成本将是:代码更脆弱/更难以维护和阅读,整体性能可能会恶化(说真的,你可以相信 go 运行时会做得很好),大量的血、汗和泪水,以及急剧下降在生产力方面。
以上是從大物件釋放記憶體的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)





 nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查詢協助高效端對端自動駕駛!


 只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
只要250美元,Hugging Face技術主管手把手教你微調Llama 3
May 06, 2024 pm 03:52 PM
只要250美元,Hugging Face技術主管手把手教你微調Llama 3
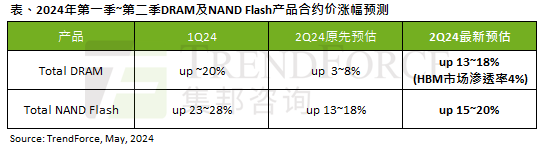 AI 潮影響明顯,TrendForce 上修本季 DRAM 記憶體、NAND 快閃記憶體合約價漲幅預測
May 07, 2024 pm 09:58 PM
AI 潮影響明顯,TrendForce 上修本季 DRAM 記憶體、NAND 快閃記憶體合約價漲幅預測
May 07, 2024 pm 09:58 PM
AI 潮影響明顯,TrendForce 上修本季 DRAM 記憶體、NAND 快閃記憶體合約價漲幅預測
