

linux組調度淺析

Linux系統是一種支援多任務並發執行的作業系統,它可以同時運行多個進程,從而提高系統的使用率和效率。但是,要讓Linux系統發揮最佳效能,就需要了解並掌握它的進程調度方法。進程調度是指作業系統根據一定的演算法和策略,動態地分配處理器資源給不同的進程,從而實現多任務並發執行的功能。 Linux系統中的進程調度方法有很多,其中之一就是群組調度。群組調度是一種基於群組的進程調度方法,它可以讓不同的進程組按照一定的比例共享處理器資源,從而實現公平性和效率的平衡。本文將淺析linux組調度的方法,包括組調度的原理、實作、配置和優缺點等面向。
cgroup與群組調度
#linux核心實作了control group功能(cgroup,since linux 2.6.24),可以支援將進程分組,然後按群組來劃分各種資源。例如:group-1擁有30%的CPU和50%的磁碟IO、group-2擁有10%的CPU和20%的磁碟IO等等。具體參閱cgroup相關文章。
cgroup支援許多資源的劃分,CPU資源就是其中之一,這就引出了群組調度。
linux核心中,傳統的調度程式是基於行程來調度的。假設使用者A和B共用一台機器,這台機器主要用來編譯程式。我們可能希望A和B能公平的分享CPU資源,但如果使用者A使用make -j8(8個執行緒並行make)、而使用者B直接使用make的話(假設他們的make程式都使用了預設的優先權) ,A用戶的make程式將產生8倍於B用戶的進程數,從而佔用(大致)8倍於B用戶的CPU。因為調度程序是基於進程的,A用戶的進程越多,被調度的機率就越大,就越有CPU的競爭力。
如何保證A、B用戶公平分享CPU呢?組調度就能做到這一點。將屬於使用者A和B的進程各分為一組,調度程式將先從兩個群組中選擇一個群組,再從選取的群組中選擇一個進程來執行。如果兩組被選中的機率相當,那麼用戶A和B將各佔有約50%的CPU。
相關資料結構
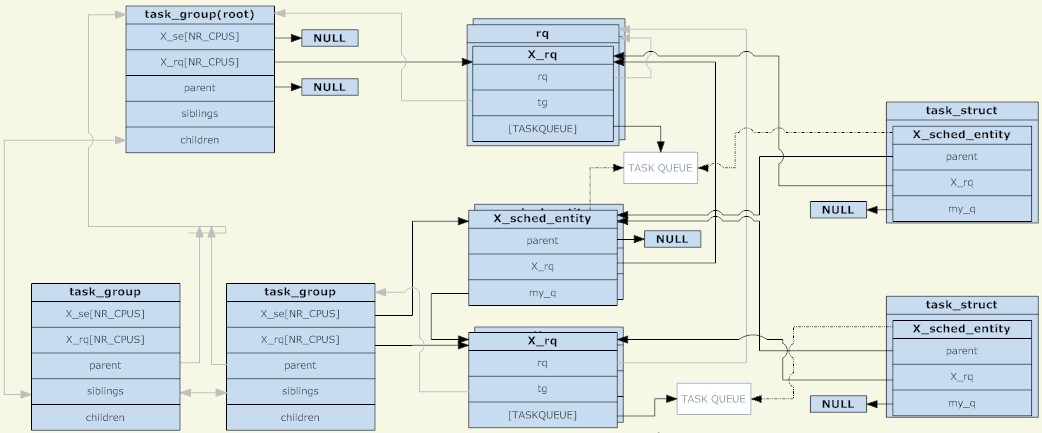
在linux核心中,使用task_group結構來管理群組調度的群組。所有存在的task_group組成一個樹型結構(與cgroup的目錄結構相對應)。
一個task_group可以包含具有任意調度類別的進程(具體來說是即時進程和普通進程兩個類別),於是task_group需要為每一種調度策略提供一組調度結構。這裡所說的一組調度結構主要包括兩個部分,調度實體和運行佇列(兩者都是每CPU一份的)。調度實體會被加入到運行隊列中,對於一個task_group,它的調度實體會被加入到其父task_group的運行隊列。
為什麼要有調度實體這樣的東西呢?因為被調度的物件有task_group和task兩種,所以需要一個抽象的結構來代表它們。如果調度實體代表task_group,則它的my_q欄位指向這個調度組對應的運行佇列;否則my_q欄位為NULL,調度實體代表task。在調度實體中與my_q相對的是X_rq(具體是針對普通進程的cfs_rq和針對實時進程的rt_rq),前者指向這個組自己的運行隊列,裡面會放入它的子節點;後者指向這個組的父節點的運行佇列,也就是這個調度實體應該被放入的運行隊列。
於是,調度實體和運行佇列又組成了另一個樹型結構,它的每一個非葉子節點都跟task_group的樹型結構是相對應的,而葉子節點都對應到具體的task。就像非TASK_RUNNING狀態的進程不會被放入運行佇列一樣,如果一個群組中不存在TASK_RUNNING狀態的進程,則這個群組(對應的調度實體)也不會被放入它的上一級運行隊列。明確一點,只要調度組創建了,其對應的task_group就肯定存在於由task_group組成的樹型結構中;而其對應的調度實體是否存在於由運行隊列和調度實體組成的樹型結構中,要取決於這個群組中是否存在TASK_RUNNING狀態的進程。
作為根節點的task_group是沒有調度實體的,調度程序總是從它的運行隊列出發,來選擇下一個調度實體(根節點必定是第一個被選中的,沒有其他候選者,所以根節點不需要調度實體)。根節點task_group所對應的運行隊列被包裝在一個rq結構中,裡面除了包含具體的運行隊列以外,還有一些全域統計資料等欄位。
調度發生的時候,調度程式從根task_group的運行佇列中選擇一個調度實體。如果這個調度實體代表一個task_group,則調度程式需要從這個群組對應的運行佇列繼續選擇一個調度實體。如此遞歸下去,直到選取一個行程。除非根task_group的運行隊列為空,否則遞歸下去一定能找到一個進程。因為如果一個task_group對應的運行隊列為空,它對應的調度實體就不會被加入到其父節點對應的運行隊列中。
最後,對於一個task_group來說,它的調度實體和運行隊列都是每CPU一份的,一個(task_group對應的)調度實體只會被加入到相同CPU所對應的運行隊列。而對於task來說,它的調度實體則只有一份(沒有按CPU劃分),調度程序的負載平衡功能可能會將(task對應的)調度實體從不同CPU所對應的運行隊列移來移去。
群組的調度策略
#組調度的主要資料結構已經理清了,這裡還有一個很重要的問題。我們知道task擁有其對應的優先權(靜態優先權 or 動態優先權),調度程序根據優先權來選擇運行佇列中的進程。那麼,既然task_group和task一樣,都被抽象成調度實體,接受同樣的調度,task_group的優先權又該如何定義呢?這個問題需要具體到調度類別來解答(不同的調度類別,其優先級定義方式不一樣),具體來說就是rt(實時調度)和cfs(完全公平調度)兩種類別。
即時進程的群組調度
#從《linux進程調度淺析》一文可以看到,即時進程是對CPU有著即時性要求的進程,它的優先權是跟具體任務相關的,完全由用戶來定義的。調度器總是會選擇優先順序最高的即時進程來運作。
發展到群組調度,群組的優先權就被定義為「群組內最高優先權的進程所擁有的優先權」。例如組內有三個優先權分別為10、20、30的進程,則組的優先權就是10(數值越小優先權越大)。
組的優先順序如此定義,引出了一個有趣的現象。當task入隊或出隊時,要把它的所有祖先節點都先出隊,然後再重新由底向上依序入隊。因為群組節點的優先權是依賴它的子節點的,task的入隊和出隊將影響它的每一個祖先節點。
於是,當調度程式從根節點的task_group出發選擇調度實體時,總是能沿著正確的路徑,找到所有TASK_RUNNING狀態的即時進程中優先順序最高的那一個。這個實作似乎理所當然,但是仔細想想,這樣一來,將即時進程分組還有什麼意義呢?無論分組與否,調度程式要做的事情都是「在所有TASK_RUNNING狀態的即時進程中選擇優先順序最高的那一個」。這裡似乎還缺了什麼…
現在需要先介紹一下linux系統中的兩個proc檔案:/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us。這兩個文件規定了,在以sched_rt_period_us為一個週期的時間內,所有實時進程的運行時間總和不超過sched_rt_runtime_us。這兩個檔案的預設值是1s和0.95s,表示每秒種為一個週期,在這個週期中,所有即時進程運行的總時間不超過0.95秒,剩下的至少0.05秒會留給普通進程。也就是說,即時進程佔有不超過95%的CPU。而在這兩個檔案出現之前,即時進程的運作時間是沒有限制的,如果一直有處於TASK_RUNNING狀態的即時進程,則普通進程會一直無法運作。相當於sched_rt_runtime_us等於sched_rt_period_us。
為什麼要有sched_rt_runtime_us和sched_rt_period_us兩個變數呢?直接使用一個表示CPU佔有百分比的變數不可以麼?我想這應該是由於很多即時進程其實都是週期性地在做某件事情,例如某語音程式每20ms發送一個語音包、某視訊程式每40ms刷新一幀、等等。週期是很重要的,僅使用一個宏觀的CPU佔有比無法準確描述即時進程需求。
而即時進程的分組就把sched_rt_runtime_us和sched_rt_period_us的概念擴展了,每個task_group都有自己的sched_rt_runtime_us和sched_rt_period_us,保證自己群組內的進程在以sched_rt_period_us) 最多為週期的時間多時間。 CPU佔有比為sched_rt_runtime_us/sched_rt_period_us。
對於根節點的task_group,它的sched_rt_runtime_us和sched_rt_period_us就等於上面兩個proc檔案中的值。而對於一個task_group節點來說,假設它下面有n個調度子組和m個TASK_RUNNING狀態的進程,它的CPU佔有比為A、這n個子組的CPU佔有比為B,則B必須小於等於A ,而A-B剩下的CPU時間將分給那m個TASK_RUNNING狀態的進程。 (這裡討論的是CPU佔有比,因為每個調度組可能有不同的週期值。)
為了實現sched_rt_runtime_us和sched_rt_period_us的邏輯,核心在更新進程的運行時間的時候(例如由週期性的時脈中斷觸發的時間更新)會給當前程序的調度實體及其所有祖先節點都增加相應的runtime 。如果一個調度實體達到了sched_rt_runtime_us所限定的時間,則將其從對應的運行佇列中剔除,並將對應的rt_rq置throttled狀態。在這個狀態下,這個rt_rq對應的調度實體不會再進入運行佇列。而每個rt_rq都會維護一個週期性的定時器,定時週期為sched_rt_period_us。每次定時器觸發,其對應的回呼函數就會將rt_rq的runtime減去一個sched_rt_period_us單位的值(但要保持runtime不小於0),然後將rt_rq從throttled狀態中恢復回來。
還有一個問題,前面說到,預設情況下,系統中每秒即時進程的運行時間不超過0.95秒。如果實時進程實際對CPU的需求不足0.95秒(大於等於0秒、小於0.95秒),則剩下的時間都會分配給普通進程。而如果即時進程的對CPU的需求大於0.95秒,它也只能夠運作0.95秒,剩下的0.05秒就會分給其他普通進程。但是,如果這0.05秒內沒有任何普通進程需要使用CPU(一直沒有TASK_RUNNING狀態的普通進程)呢?這種情況下既然普通進程對CPU沒有需求,即時進程是否可以運作超過0.95秒呢?不能。在剩下的0.05秒核心寧可讓CPU一直閒著,也不讓即時進程使用。可見sched_rt_runtime_us和sched_rt_period_us是很有強制性的。
最後還有多CPU的問題,前面也提到,對於每一個task_group,它的調度實體和運行隊列是每CPU維護一份的。而sched_rt_runtime_us和sched_rt_period_us是作用在調度實體上的,所以如果系統中有N個CPU,實時進程實際佔有CPU的上限是N*sched_rt_runtime_us/sched_rt_period_us。也就是說,儘管預設限制了每秒鐘之內,即時進程只能運行0.95秒。但對於某個即時的進程來說,如果CPU有兩個核,也還是能滿足它100%佔有CPU的需求(例如執行死循環)。然後,照道理說,這個即時進程佔有的100%的CPU應該是由兩個部分組成的(每個CPU佔有一部分,但都不超過95%)。但實際上,為了避免流程在CPU間的遷移導致上下文切換、快取失效等一系列問題,一個CPU上的調度實體可以向另一個CPU上對應的調度實體借用時間。結果就是,宏觀上既滿足了sched_rt_runtime_us的限制,又避免了進程的遷移。
普通程序的群組調度
#文章一開頭提到了希望A、B兩個用戶在進程數不相同的情況下也能平分CPU的需求,但是上面關於實時進程的組調度策略好像與此不太相干,其實這就是普通進程的組調度所要幹的事。
相比即時進程,普通進程的群組調度就沒有這麼多講究。群組被視為跟進程幾乎完全相同的實體,它擁有自己的靜態優先權、調度程序也動態地調整它的優先權。對於一個組來說,組內程序的優先順序並不影響組的優先級,只有當這個組被調度程序選中時,這些程序的優先順序才會被考慮。
為了設定群組的優先權,每個task_group都有一個shares參數(跟前面提到的sched_rt_runtime_us和sched_rt_period_us兩個參數並列)。 shares並不是優先級,而是調度實體的權重(這是CFS調度器的玩法),這個權重和優先級是有一一對應的關係的。普通進程的優先權也會被轉換成其對應調度實體的權重,所以可以說shares代表了優先權。
shares的預設值跟普通進程預設優先權對應的權重是一樣的。所以在預設情況下,群組和進程是平分CPU的。
範例
(環境:ubuntu 10.04,kernel 2.6.32,Intel Core2 雙核心)
掛載一個只分割CPU資源的cgroup,並建立grp_a和grp_b兩個子群組:
kouu@kouu-one:~$ sudo mkdir /dev/cgroup/cpu -p
kouu@kouu-one:~$ sudo mount -t cgroup cgroup -o cpu /dev/cgroup/cpu
kouu@kouu-one:/dev/cgroup/cpu$ cd /dev/cgroup/cpu/
kouu@kouu-one:/dev/cgroup/cpu$ mkdir grp_{a,b}
kouu@kouu-one:/dev/cgroup/cpu$ ls *
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release release_agent tasks
grp_a:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
grp_b:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
分別開三個shell,第一個加入grp_a,後兩個加入grp_b:
kouu@kouu-one:~/test/rtproc$ cat ttt.sh echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。) kouu@kouu-one:~/test1$ echo $$ 6740 kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a kouu@kouu-one:~/test2$ echo $$ 9410 kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b kouu@kouu-one:~/test3$ echo $$ 9425 kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks 6740 kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks 9410 9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
\#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out 19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out 19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out ......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
\#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh \# echo 300000 > grp_a/cpu.rt_runtime_us \# exit kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_* 1000000 300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out ......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
本文浅析了linux组调度的方法,包括组调度的原理、实现、配置和优缺点等方面。通过了解和掌握这些知识,我们可以深入理解Linux进程调度的高级知识,从而更好地使用和优化Linux系统。
以上是linux組調度淺析的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)
熱門話題



 Linux的5支支柱:了解他們的角色
Apr 11, 2025 am 12:07 AM
Linux的5支支柱:了解他們的角色
Apr 11, 2025 am 12:07 AM
Linux系統的五大支柱是:1.內核,2.系統庫,3.Shell,4.文件系統,5.系統工具。內核管理硬件資源並提供基本服務;系統庫為應用程序提供預編譯函數;Shell是用戶與系統交互的接口;文件系統組織和存儲數據;系統工具用於系統管理和維護。
 oracle如何查看實例名
Apr 11, 2025 pm 08:18 PM
oracle如何查看實例名
Apr 11, 2025 pm 08:18 PM
在 Oracle 中查看實例名的方法有三種:命令行中使用 "sqlplus" 和 "select instance_name from v$instance;" 命令。在 SQL*Plus 中使用 "show instance_name;" 命令。通過操作系統的任務管理器、Oracle Enterprise Manager 或檢查環境變量 (Linux 上的 ORACLE_SID)。
 Linux實際上有什麼好處?
Apr 12, 2025 am 12:20 AM
Linux實際上有什麼好處?
Apr 12, 2025 am 12:20 AM
Linux適用於服務器、開發環境和嵌入式系統。 1.作為服務器操作系統,Linux穩定高效,常用於部署高並發應用。 2.作為開發環境,Linux提供高效的命令行工具和包管理系統,提升開發效率。 3.在嵌入式系統中,Linux輕量且可定制,適合資源有限的環境。
 oracle數據庫卸載教程
Apr 11, 2025 pm 06:24 PM
oracle數據庫卸載教程
Apr 11, 2025 pm 06:24 PM
要卸載 Oracle 數據庫:停止 Oracle 服務,移除 Oracle 實例,刪除 Oracle 主目錄,清除註冊表項(僅限 Windows),刪除環境變量(僅限 Windows)。卸載前請備份數據。
 將Docker與Linux一起使用:綜合指南
Apr 12, 2025 am 12:07 AM
將Docker與Linux一起使用:綜合指南
Apr 12, 2025 am 12:07 AM
在Linux上使用Docker可以提高開發和部署效率。 1.安裝Docker:使用腳本在Ubuntu上安裝Docker。 2.驗證安裝:運行sudodockerrunhello-world。 3.基本用法:創建Nginx容器dockerrun--namemy-nginx-p8080:80-dnginx。 4.高級用法:創建自定義鏡像,使用Dockerfile構建並運行。 5.優化與最佳實踐:使用多階段構建和DockerCompose,遵循編寫Dockerfile的最佳實踐。
 oracle安裝之後如何使用
Apr 11, 2025 pm 07:51 PM
oracle安裝之後如何使用
Apr 11, 2025 pm 07:51 PM
安裝 Oracle 後,可通過以下步驟使用:創建數據庫實例。連接到數據庫。創建用戶。創建表。插入數據。查詢數據。導出數據。導入數據。
 apache80端口被佔用怎麼辦
Apr 13, 2025 pm 01:24 PM
apache80端口被佔用怎麼辦
Apr 13, 2025 pm 01:24 PM
當 Apache 80 端口被佔用時,解決方法如下:找出佔用該端口的進程並關閉它。檢查防火牆設置以確保 Apache 未被阻止。如果以上方法無效,請重新配置 Apache 使用不同的端口。重啟 Apache 服務。
 apache怎麼啟動
Apr 13, 2025 pm 01:06 PM
apache怎麼啟動
Apr 13, 2025 pm 01:06 PM
啟動 Apache 的步驟如下:安裝 Apache(命令:sudo apt-get install apache2 或從官網下載)啟動 Apache(Linux:sudo systemctl start apache2;Windows:右鍵“Apache2.4”服務並選擇“啟動”)檢查是否已啟動(Linux:sudo systemctl status apache2;Windows:查看服務管理器中“Apache2.4”服務的狀態)啟用開機自動啟動(可選,Linux:sudo systemctl
