

Linux 進程組調度機制:如何對進程進行分組和調度

進程組是 Linux 系統中一種對進程進行分類和管理的方式,它可以將具有相同特徵或關係的進程放在一起,形成一個邏輯上的單元。進程組的作用是方便對進程進行控制、通訊和資源分配,以提高系統的效率和安全性。進程組調度是 Linux 系統中一種對進程組進行調度的機制,它可以根據進程組的屬性和需求,並分配適當的 CPU 時間和資源,從而提高系統的並發性和回應性。但是,你真的了解 Linux 進程組調度機制嗎?你知道如何在 Linux 下建立和管理進程組嗎?你知道如何在 Linux 下使用和配置進程組調度機制嗎?本文將為你詳細介紹 Linux 進程組調度機制的相關知識,讓你在 Linux 下更能運用並理解這個強大的核心功能。

#又碰到一個神奇的進程調度問題,在系統重啟過程中,發現系統掛住了,過了30s後才重新復位,真正係統復位的原因是硬體看門狗重啟的系統,而非原來正常的reboot流程。硬體狗記錄的重設時間,將不餵狗的時間向前推30s分析串口記錄日誌,當時的日誌就印了一句話:「sched: RT throttling activated」。
從linux-3.0.101-0.7.17版本核心程式碼可以看出,sched_rt_runtime_exceeded印了這句話。在核心進程組調度過程中,即時進程調度受rt_rq->rt_throttled 的限制,下面便具體說一下涉及到的linux中進程組調度機制。
進程組調度機制
#群組調度是cgroup裡面的概念,指將N個進程視為一個整體,參與系統中的調度過程,具體體現在範例中:A任務有8個進程或線程,B任務有2個進程或線程,仍然有其他的進程或線程存在,就需要控制A任務的CPU佔用率不高於40%,B任務的CPU佔用率不高於40%,其他任務佔用率不少於20%,那麼就有對cgroup閥值的設置,cgroup A設定為200,cgroup B設定為200,其他任務預設為100,如此便實現了CPU控制的功能。
在核心中,進程組由task_group進行管理,其中涉及的內容很多都是cgroup控制機制 ,另外開闢單元在寫,此處指重點描述組調度的部分,具體見如下註釋。
struct task_group {
struct cgroup_subsys_state css;
//下面是普通进程调度使用
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
//普通进程调度单元,之所以用调度单元,因为被调度的可能是一个进程,也可能是一组进程
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
//公平调度队列
struct cfs_rq **cfs_rq;
//下面就是如上示例的控制阀值
unsigned long shares;
atomic_t load_weight;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程调度单元
struct sched_rt_entity **rt_se;
//实时进程调度队列
struct rt_rq **rt_rq;
//实时进程占用CPU时间的带宽(或者说比例)
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
//task_group呈树状结构组织,有父节点,兄弟链表,孩子链表,内核里面的根节点是root_task_group
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
調度單元有兩種,即普通調度單元和即時進程調度單元。
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
//当前调度单元归属于某个父调度单元
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
//当前调度单元归属的父调度单元的调度队列,即当前调度单元插入的队列
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
//当前调度单元的调度队列,即管理子调度单元的队列,如果调度单元是task_group,my_q才会有值
//如果当前调度单元是task,那么my_q自然为NULL
struct cfs_rq *my_q;
#endif
void *suse_kabi_padding;
};
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned int time_slice;
int nr_cpus_allowed;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程的管理和普通进程类似,下面三项意义参考普通进程
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
};
下面看一下調度隊列,因為即時調度和普通調度隊列需要說明的選項差不多,以即時隊列為例:
struct rt_rq {
struct rt_prio_array active;
unsigned long rt_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
#ifdef CONFIG_SMP
int next; /* next highest */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory;
unsigned long rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif
//当前队列的实时调度是否受限
int rt_throttled;
//当前队列的累计运行时间
u64 rt_time;
//当前队列的最大运行时间
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
//当前实时调度队列归属调度队列
struct rq *rq;
struct list_head leaf_rt_rq_list;
//当前实时调度队列归属的调度单元
struct task_group *tg;
#endif
};
透過以上3個結構體分析,可以得到下圖(點擊看大圖):
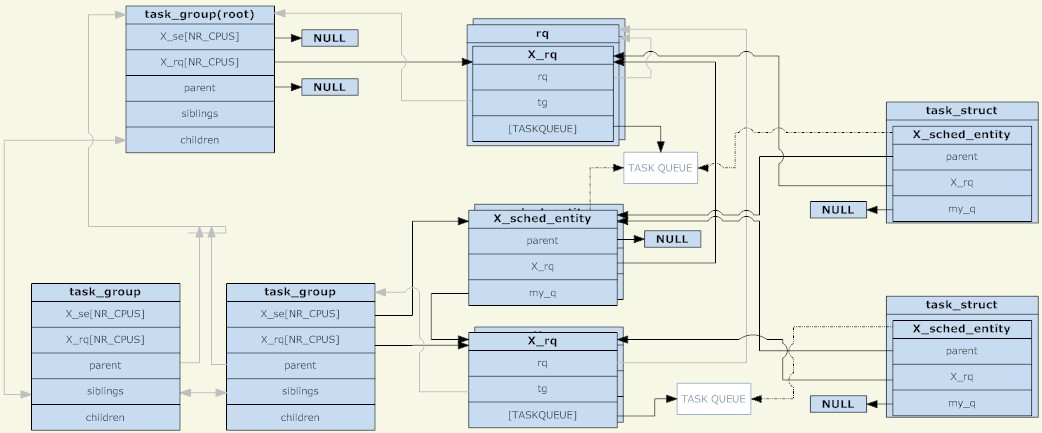
task_group
#從圖上可以看出,調度單元和調度佇列組合一個樹節點,又是另一個單獨樹結構存在,只是需要注意的是,只有調度單元裡面有TASK_RUNNING的進程時,調度單元才會被放到調度隊列中。
另外一點是,在沒有組調度前,每個CPU上只有一個調度隊列,當時可以理解成所有的進程在一個調度組裡面,現在則是每個調度組在每個CPU上都有調度隊列。在調度過程中,原來是系統選擇一個進程運行,目前則是選擇一個調度單元運行,調度發生時,schedule進程從root_task_group開始尋找由調度策略決定的調度單元,當調度單元是task_group,則進入task_group的運行隊列選擇一個合適的調度單元,最後找一個合適的task調度單元。整個過程就是樹的遍歷,擁有TASK_RUNNING進程的task_group是樹的節點,task調度單元則是樹的葉子。
群組進程調度策略
#群組進程調度要實現的目的和原來沒有差別,就是完成即時進程調度和普通進程調度,即rt和cfs調度。
CFS组调度策略:
文章前面示例中提到的任务分配CPU,说的就是cfs调度,对于CFS调度而言,调度单元和普通调度进程没有多大区别,调度单元由自己的调度优先级,而且不受调度进程的影响,每个task_group都有一个shares,share并非我们说的进程优先级,而是调度权重,这个是cfs调度管理的概念,但在cfs中最终体现到调度优先排序上。shares值默认都是相同的,所有没有设置权重的值,CPU都是按旧有的cfs管理分配的。总结的说,就是cfs组调度策略没变化。具体到cgroup的CPU控制机制上再说。
RT组调度策略:
实时进程的优先级是设置固定,调度器总是选择优先级最高的进程运行。而在组调度中,调度单元的优先级则是组内优先级最高的调度单元的优先级值,也就是说调度单元的优先级受子调度单元影响,如果一个进程进入了调度单元,那么它所有的父调度单元的调度队列都要重排。实际上我们看到的结果是,调度器总是选择优先级最高的实时进程调度,那么组调度对实时进程控制机制是怎么样的?
在前面的rt_rq实时进程运行队列里面提到rt_time和rt_runtime,一个是运行累计时间,一个是最大运行时间,当运行累计时间超过最大运行时间的时候,rt_throttled则被设置为1,见sched_rt_runtime_exceeded函数。
if (rt_rq->rt_time > runtime) {
rt_rq->rt_throttled = 1;
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}
设置为1意味着实时队列中被限制了,如__enqueue_rt_entity函数,不能入队。
static inline int rt_rq_throttled(struct rt_rq *rt_rq)
{
return rt_rq->rt_throttled && !rt_rq->rt_nr_boosted;
}
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
.....
}
其实还有一个隐藏的时间概念,即sched_rt_period_us,意味着sched_rt_period_us时间内,实时进程可以占用CPU rt_runtime时间,如果实时进程每个时间周期内都没有调度,则在do_sched_rt_period_timer定时器函数中将rt_time减去一个周期,然后比较rt_runtime,恢复rt_throttled。
//overrun来自对周期时间定时器误差的校正 rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime); if (rt_rq->rt_throttled && rt_rq->rt_time rt_throttled = 0; enqueue = 1;
则对于cgroup控制实时进程的占用比则是通过rt_runtime实现的,对于root_task_group,也即是所有进程在一个cgroup下,则是通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us接口设置的,默认值是1s和0.95s。这么看以为实时进程只能占用95%CPU,那么实时进程占用CPU100%导致进程挂死的问题怎么出现了?
原来实时进程所在的CPU占用超时了,实时进程的rt_runtime可以向别的cpu借用,将其他CPU剩余的rt_runtime-rt_time的值借过来,如此rt_time可以最大等于rt_runtime,造成事实上的单核CPU达到100%。这样做的目的自然规避了实时进程缺少CPU时间而向其他核迁移的成本,未绑核的普通进程自然也可以迁移其他CPU上,不会得不到调度,当然绑核进程仍然是个杯具。
static int do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
int i, weight, more = 0;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/
if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/
diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
more = 1;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
return more;
}
通过本文,你应该对 Linux 进程组调度机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了进程组调度机制的作用和影响,以及如何在 Linux 下正确地使用和配置进程组调度机制。我们建议你在使用 Linux 系统时,使用进程组调度机制来提高系统的效率和安全性。同时,我们也提醒你在使用进程组调度机制时要注意一些潜在的问题和挑战,如进程组类型、优先级、限制等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受进程组调度机制的优势和便利。
以上是Linux 進程組調度機制:如何對進程進行分組和調度的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux系統的五個基本組件是:1.內核,2.系統庫,3.系統實用程序,4.圖形用戶界面,5.應用程序。內核管理硬件資源,系統庫提供預編譯函數,系統實用程序用於系統管理,GUI提供可視化交互,應用程序利用這些組件實現功能。
 git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
要查看 Git 倉庫地址,請執行以下步驟:1. 打開命令行並導航到倉庫目錄;2. 運行 "git remote -v" 命令;3. 查看輸出中的倉庫名稱及其相應的地址。
 notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
雖然 Notepad 無法直接運行 Java 代碼,但可以通過借助其他工具實現:使用命令行編譯器 (javac) 編譯代碼,生成字節碼文件 (filename.class)。使用 Java 解釋器 (java) 解釋字節碼,執行代碼並輸出結果。
 sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
sublime寫好代碼後如何運行
Apr 16, 2025 am 08:51 AM
在 Sublime 中運行代碼的方法有六種:通過熱鍵、菜單、構建系統、命令行、設置默認構建系統和自定義構建命令,並可通過右鍵單擊項目/文件運行單個文件/項目,構建系統可用性取決於 Sublime Text 的安裝情況。
 laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
laravel安裝代碼
Apr 18, 2025 pm 12:30 PM
要安裝 Laravel,需依序進行以下步驟:安裝 Composer(適用於 macOS/Linux 和 Windows)安裝 Laravel 安裝器創建新項目啟動服務訪問應用程序(網址:http://127.0.0.1:8000)設置數據庫連接(如果需要)
 Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要用途包括:1.服務器操作系統,2.嵌入式系統,3.桌面操作系統,4.開發和測試環境。 Linux在這些領域表現出色,提供了穩定性、安全性和高效的開發工具。

 VSCode怎麼用
Apr 15, 2025 pm 11:21 PM
VSCode怎麼用
Apr 15, 2025 pm 11:21 PM
Visual Studio Code (VSCode) 是一款跨平台、開源且免費的代碼編輯器,由微軟開發。它以輕量、可擴展性和對眾多編程語言的支持而著稱。要安裝 VSCode,請訪問官方網站下載並運行安裝程序。使用 VSCode 時,可以創建新項目、編輯代碼、調試代碼、導航項目、擴展 VSCode 和管理設置。 VSCode 適用於 Windows、macOS 和 Linux,支持多種編程語言,並通過 Marketplace 提供各種擴展。它的優勢包括輕量、可擴展性、廣泛的語言支持、豐富的功能和版
