
進程調度是作業系統的核心功能之一,它決定了哪些進程可以獲得CPU的執行時間,以及要獲得多少時間。在Linux系統中,有多種進程調度演算法,其中最重要且最常用的一種是完全公平調度演算法(CFS),它是從Linux 2.6.23版本開始引入的。 CFS的目標是讓每個行程都能依照自己的權重和需求,獲得合理且公平的CPU時間分配,進而提升系統的整體效能和反應速度。本文將介紹CFS的基本原理、資料結構、實作細節與優缺點,幫助你深入理解Linux進程排程的完全公平。
Linux 調度器簡史
早期的 Linux 調度器使用了最低的設計,它顯然不關注具有很多處理器的大型架構,更不用說是超線程了。 1.2 Linux 調度器使用了環形佇列用於可運行的任務管理,使用循環調度策略。此調度器新增和刪除進程效率很高(具有保護結構的鎖定)。簡而言之,該調度器並不複雜但是簡單且快速。
Linux 版本 2.2 引入了調度類別的概念,允許針對即時任務、非搶佔式任務、非即時任務的調度策略。 2.2 調度器還包括對稱多處理 (SMP) 支援。
2.4 核心包含了相對簡單的調度器,按 O(N) 的時間間隔運行(在調度事件期間它會迭代每個任務)。 2.4 調度器將時間分割成 epoch,每個 epoch 中,每個任務允許執行到其時間切片用完。如果某個任務沒有使用其所有的時間切片,那麼 剩餘時間切片的一半將被添加到新時間切片使其在下個 epoch 中可以執行更長時間。調度器只是迭代任務,應用 goodness 函數(指標)決定下面要執行哪個任務。儘管這種方法比較簡單,但是卻比較低效、缺乏可擴展性而且不適合用在即時系統中。它還缺少利用新硬體架構(例如多核心處理器)的能力。
早期的2.6 調度器,稱為O(1) 調度器,它旨在解決2.4 調度器存在的問題— 此調度器不需要迭代整個任務列表來確定要調度的下一個任務(因此得名O(1) ,這意味著它效率更高,擴展性更好)。 O(1) 調度器追蹤運行佇列中可運行的任務(實際上,每個優先權等級有兩個運行佇列— 一個用於活動任務,一個用於過期任務), 這表示要確定接下來執行的任務,調度器只需按優先順序將下一個任務從特定活動的運行隊列中取出)。 O(1) 調度器擴展性更好且包含交互性,提供了大量啟示用於確定任務是受 I/O 限制還是受處理器限制。但是 O(1) 調度器在核心中很笨拙。需要大量程式碼計算啟示,難以管理並且對於純粹主義者而言未能體現演算法的本質。
為了解決 O(1) 調度器面臨的問題以及應對其他外部壓力, 需要改變某些東西。這個改變來自 Con Kolivas 的核心補丁,其中包括他的 Rotating Staircase Deadline Scheduler (RSDL), 這包含了他在 staircase 調度器方面的早期工作。這些工作的成果就是一個設計簡單的調度器,包含了公平性和界限內延遲。 Kolivas 的調度器吸引了許多人(而且許多人呼籲將其納入目前的 2.6.21 主流核心中),很顯然調度器的變革即將發生。 Ingo Molnar,O(1) 調度器的創造者,然後圍繞 Kolivas 的一些思想開發了基於 CFS 的調度器。讓我們來剖析 CFS,從較高的層次來看看它是如何運作的。
——————————————————————————————————————————
#CFS 背後的主要想法是維護為任務提供處理器時間方面的平衡(公平性)。這意味著應給進程分配相當數量的處理器。分給某個任務的時間失去平衡時(意味著一個或多個任務相對於其他任務而言未被給予相當數量的時間),應給予失去平衡的任務分配時間,讓其執行。
要實現平衡,CFS 在稱為虛擬運行時 的地方維持提供給某個任務的時間量。任務的虛擬運行時越小, 表示任務被允許存取伺服器的時間越短 — 其對處理器的需求越高。 CFS 還包含睡眠公平概念以便確保那些目前沒有運行的 任務(例如,等待 I/O)在其最終需要時獲得相當份額的處理器。
但是與先前的 Linux 調度器不同,它沒有將任務維護在運行佇列中,CFS 維護了一個以時間為順序的紅黑樹(請參閱圖 1)。紅黑樹 是一個樹,具有許多有趣、有用的屬性。首先,它是自平衡的,這意味著樹上沒有路徑比其他路徑長兩倍以上。第二,樹上的運行是根據 O(log n) 時間發生(其中 n 是樹中節點的數量)。這意味著您可以快速且有效率地插入或刪除任務。
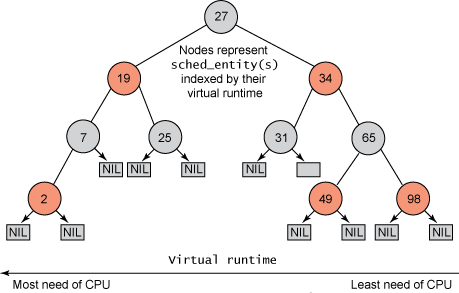
任務儲存在以時間為順序的紅黑樹中(由sched_entity 物件表示),對處理器需求最多的任務(最低虛擬執行時間)儲存在樹的左側,處理器需求最少的任務(最高虛擬執行時間)儲存在樹的右側。為了公平,調度器然後選取紅黑樹最左端的節點調度為下一個以便保持公平性。任務透過將其運行時間新增至虛擬運行時, 說明其佔用 CPU 的時間,然後如果可運行,再插回樹中。這樣,樹左側的任務就被給予時間運行了,樹的內容從右側遷移到左側以保持公平。因此,每個可運行的任務都會追趕其他任務以維持整個可運行任務集合的執行平衡。
——————————————————————————————————————————
#Linux 內的所有任務都由稱為 task_struct 的任務結構表示。該結構(以及其他相關內容)完整地描述了任務並包含了任務的當前狀態、其堆疊、進程標識、優先順序(靜態和動態)等等。您可以在 ./linux/include/linux/sched.h 中找到這些內容以及相關結構。但因為不是所有任務都是可運行的,您在 task_struct 中不會發現任何與 CFS 相關的欄位。相反,會建立一個名為 sched_entity 的新結構來追蹤調度資訊(請參閱圖 2)。
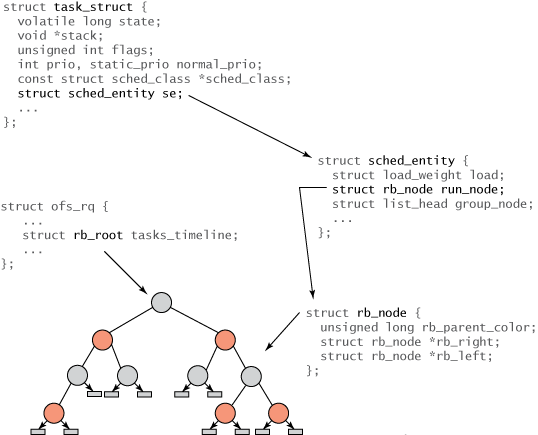
#各種結構的關係如 圖 2 所示。樹的根透過 rb_root 元素透過 cfs_rq 結構(在 ./kernel/sched.c 中)引用。紅黑樹的葉子不包含訊息,但是內部節點代表一個或多個可運行的任務。紅黑樹的每個節點都由 rb_node 表示,它只包含子參考和父物件的顏色。 rb_node 包含在sched_entity 結構中,該結構包含 rb_node 引用、負載權重以及各種統計資料。最重要的是, sched_entity 包含 vruntime(64 位元欄位),它表示任務運行的時間量,並作為紅黑樹的索引。最後,task_struct 位於頂端,它完整地描述任務並包含 sched_entity 結構。
就 CFS 部分而言,調度函數非常簡單。在./kernel/sched.c 中,您會看到通用schedule() 函數,它會先搶佔當前運行任務(除非它透過yield() 程式碼先搶佔自己)。注意 CFS 沒有真正的時間切片概念用於搶佔,因為搶佔時間是可變的。目前運行任務(現在被搶佔的任務)透過對 put_prev_task 呼叫(透過調度類別)返回紅黑樹。當 schedule 函數開始確定下一個要調度的任務時,它會呼叫 pick_next_task函數。此函數也是通用的(在 ./kernel/sched.c 中),但它會透過調度器類別呼叫 CFS 調度器。 CFS 中的 pick_next_task 函數可以在 ./kernel/sched_fair.c(稱為 pick_next_task_fair())中找到。此函數只是從紅黑樹中取得最左端的任務並傳回相關 sched_entity。透過此引用,一個簡單的 task_of() 呼叫確定傳回的 task_struct 引用。通用調度器最後為此任務提供處理器。
——————————————————————————————————————————
CFS 不直接使用優先權而是將其用作允許任務執行的時間的衰減係數。低優先級任務具有較高的衰減係數,而高優先級任務具有較低的衰減係數。這意味著與高優先級任務相比,低優先級任務允許任務執行的時間消耗得更快。這是一個絕妙的解決方案,可以避免維護優先調度的運行佇列。
CFS 另一個有趣的地方是群組調度 概念(在 2.6.24 核心中引入)。組調度是另一種為調度帶來公平性的方式,尤其是在處理產生許多其他任務的任務時。假設一個產生了許多任務的伺服器要並行化進入的連線(HTTP 伺服器的典型架構)。不是所有任務都會被統一公平對待, CFS 引入了群組來處理這種行為。產生任務的伺服器程序在整個群組中(在一個層次結構中)共用它們的虛擬運行時,而單一任務則維持其自己獨立的虛擬執行時間。這樣單一任務會收到與組別大致相同的調度時間。您會發現 /proc 介面用於管理進程層次結構,讓您對群組的形成方式有完全的控制。使用此配置,您可以跨使用者、跨進程或其變體分配公平性。
與 CFS 一起引入的是調度類別概念(可以回顧 圖 2)。每個任務都屬於一個調度類,這決定了任務將如何調度。調度類別定義一個通用函數集(透過 sched_class),函數集定義調度器的行為。例如,每個調度器提供一種方式, 新增要調度的任務、調出要運行的下一個任務、提供給調度器等等。每個調度器類別都在一對一連接的清單中彼此相連,使類別可以迭代(例如, 要啟用給定處理器的停用)。一般結構如圖 3 所示。注意,將任務函數加入佇列或脫離佇列只需從特定調度結構中加入或移除任務。函數 pick_next_task 選擇要執行的下一個任務(取決於調度類別的具體策略)。

但不要忘了調度類別是任務結構本身的一部分(參見 圖 2)。這一點簡化了任務的操作,無論其調度類別為何。例如, 下列函數以./kernel/sched.c 中的新任務搶佔目前執行任務(其中 curr 定義了目前執行任務,rq 代表CFS 紅黑樹而p 是下一個要調度的任務):
static inline void check_preempt( struct rq *rq, struct task_struct *p )
{
rq->curr->sched_class->check_preempt_curr( rq, p );
}
如果此任務正使用公平調度類,則 check_preempt_curr() 將解析為 check_preempt_wakeup()。您可以在 ./kernel/sched_rt.c, ./kernel/sched_fair.c 和 ./kernel/sched_idle.c 中查看這些關係。
調度類別是調度發生變化的另一個有趣的地方,但是隨著調度域的增加,功能也在增加。這些網域可讓您出於負載平衡和隔離的目的將一個或多個處理器按層次關係分組。一個或多個處理器能夠共享調度策略(並在其之間保持負載平衡)或實現獨立的調度策略從而故意隔離任務。
#繼續研究調度,您將發現正在開發中的調度器將會突破性能和擴展性的界限。 Con Kolivas 沒有被他的 Linux 經驗羈絆,他開發出了另一個 Linux 調度器,其縮寫為:BFS。該調度器據說在 NUMA 系統以及行動裝置上具有更好的性能, 並且被引入了 Android 作業系統的一款衍生產品中。
透過本文,你應該對CFS有了一個基本的了解,它是Linux系統中最先進和最高效的進程調度演算法之一,它透過使用紅黑樹來儲存可運行進程佇列,透過計算虛擬運行時間來衡量進程的公平性,透過實現喚醒搶佔特性來提高互動式進程的反應速度,從而實現了進程調度的完全公平。當然,CFS也不是完美無缺的,它有一些潛在的問題和限制,例如對主動休眠進程的過度補償、對實時進程的不足支持、對多核處理器的不充分利用等,需要在未來的版本中進行改進和優化。總之,CFS是Linux系統中不可或缺的一個元件,值得你深入學習與掌握。
以上是Linux CFS:如何實現進程調度的完全公平的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















