

Linux記憶體模型:深入理解記憶體管理

你是否曾經遇到過在Linux系統中出現的各種記憶體問題?例如記憶體洩漏、記憶體碎片等等。這些問題都可以透過深入理解Linux記憶體模型來解決。
一、前言
#在linux核心中支援3中記憶體模型,分別是flat memory model,Discontiguous memory model和sparse memory model。所謂memory model,其實就是從cpu的角度看,其實體記憶體的分佈情況,在linux kernel中,使用什麼的方式來管理這些物理記憶體。另外,需要說明的是:本文主要focus在share memory的系統,也就是說所有的CPUs共享一片實體位址空間的。
本文的內容安排如下:為了能夠清楚的解析記憶體模型,我們對一些基本的術語進行了描述,這在第二章。第三章則對三種記憶體模型的工作原理進行闡述,最後一章是程式碼解析,程式碼來自4.4.6內核,對於體系結構相關的程式碼,我們採用ARM64進行分析。
二、和記憶體模型相關的術語
1、什麼是page frame?
作業系統最重要的作用之一就是管理電腦系統中的各種資源,做為最重要的資源:內存,我們必須管理起來。在linux作業系統中,實體記憶體是依照page size來管理的,具體page size是多少是和硬體以及linux系統配置相關的,4k是最經典的設定。因此,對於物理內存,我們將其分成一個個按page size排列的page,每一個物理內存中的page size的內存區域我們稱為page frame。我們針對每一個物理的page frame建立一個struct page的資料結構來追蹤每一個實體頁面的使用情況:是用於內核的正文段?還是用於進程的頁表?是用於各種file cache還是處於free狀態…
每一個page frame有一個一一對應的page資料結構,系統中定義了page_to_pfn和pfn_to_page的巨集用來在page frame number和page資料結構之間進行轉換,具體如何轉換是和memory modle相關,我們會在第三章詳細描述linux kernel中的3個記憶體模型。
2、什麼是PFN?
對於一個電腦系統,其整個實體位址空間應該是從0開始,到實際系統能支援的最大實體空間為止的一段位址空間。在ARM系統中,假設實體位址是32個bit,那麼其實體位址空間就是4G,在ARM64系統中,如果支援的實體位址bit數目是48個,那麼其實體位址空間就是256T。當然,實際上這麼大的實體位址空間並不是都用於內存,有些也屬於I/O空間(當然,有些cpu arch有自己獨立的io address space)。因此,記憶體所佔據的實體位址空間應該是一個有限的區間,不可能涵蓋整個實體位址空間。不過,現在由於記憶體越來越大,對於32位元系統,4G的實體位址空間已經無法滿足記憶體的需求,因此會有high memory這個概念,後續會詳細描述。
PFN是page frame number的縮寫,所謂page frame,就是針對實體記憶體而言的,把實體記憶體分成一個個的page size的區域,並且給每一個page 編號,這個號碼就是PFN。假設實體記憶體從0位址開始,那麼PFN等於0的那個頁幀就是0位址(物理位址)開始的那個page。假設實體記憶體從x位址開始,那麼第一個頁幀號碼就是(x>>PAGE_SHIFT)。
3、什麼是NUMA?
在為multiprocessors系統設計記憶體架構的時候有兩種選擇:一種是UMA(Uniform memory access),系統中的所有的processor共享一個統一的,一致的物理記憶體空間,無論從哪一個processor發起訪問,對記憶體位址的訪問時間都是一樣的。 NUMA(Non-uniform memory access)和UMA不同,對某個記憶體位址的存取是和該memory與processor之間的相對位置有關的。例如,對以某個節點(node)上的processor而言,訪問local memory要比訪問那些remote memory花的時間長。
三、Linux 核心中的三種memory model
1、什麼是FLAT memory model?
如果從系統中任一個processor的角度來看,當它存取物理記憶體的時候,物理位址空間是一個連續的,沒有空洞的位址空間,那麼這種電腦系統的記憶體模型就是Flat memory。在這個記憶體模型下,物理記憶體的管理比較簡單,每個實體頁幀都會有一個page資料結構來抽象,因此系統中存在一個struct page的陣列(mem_map),每個陣列條目指向一個實際的物理頁幀(page frame)。在flat memory的情況下,PFN(page frame number)和mem_map陣列index的關係是線性的(有一個固定偏移,如果記憶體對應的物理位址等於0,那麼PFN就是陣列index)。因此從PFN到對應的page資料結構是非常容易的,反之亦然,具體可以參考page_to_pfn和pfn_to_page的定義。此外,對於flat memory model,節點(struct pglist_data)只有一個(為了和Discontiguous Memory Model採用同樣的機制)。下面的圖片描述了flat memory的情況:
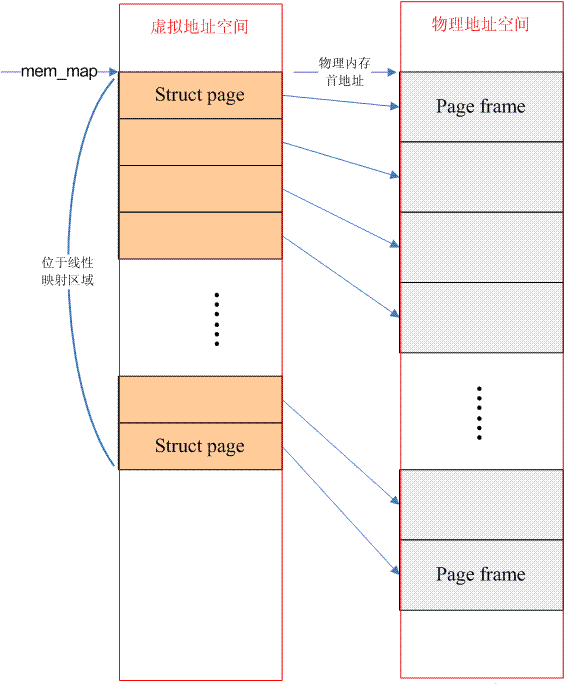
需要強調的是struct page所佔用的記憶體位於直接映射(directly mapped)區間,因此作業系統不需要再為其建立page table。
2、什麼是Discontiguous Memory Model?
如果cpu在存取實體記憶體的時候,其位址空間有一些空洞,是不連續的,那麼這種電腦系統的記憶體模型就是Discontiguous memory。一般而言,NUMA架構的電腦系統的memory model都是選擇Discontiguous Memory,不過,這兩個概念其實是不同的。 NUMA強調的是memory和processor的位置關係,和記憶體模型其實是沒有關係的,只不過,由於同一node上的memory和processor有更緊密的耦合關係(訪問更快),因此需要多個node來管理。 Discontiguous memory本質上是flat memory內存模型的擴展,整個物理內存的address space大部分是成片的大塊內存,中間會有一些空洞,每一個成片的memory address space屬於一個node(如果局限在一個node內部,其記憶體模型為flat memory)。下面的圖片描述了Discontiguous memory的情況:
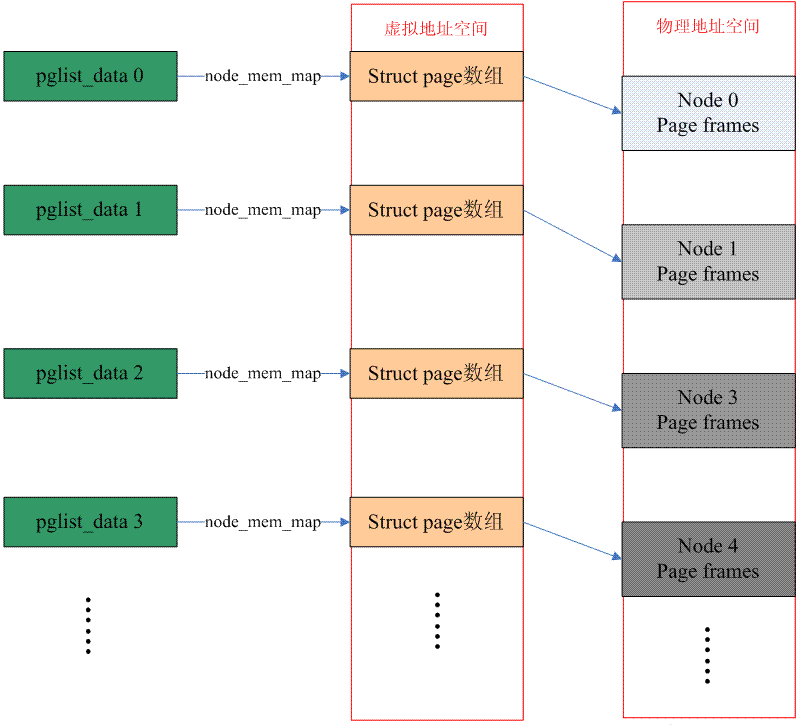
因此,在這個記憶體模型下,節點資料(struct pglist_data)有多個,巨集定義NODE_DATA可以得到指定節點的struct pglist_data。而,每個節點管理的實體記憶體保存在struct pglist_data 資料結構的node_mem_map成員中(概念類似flat memory中的mem_map)。這時候,從PFN轉換到具體的struct page會稍微複雜一點,我們首先要從PFN得到node ID,然後根據這個ID找到對於的pglist_data 資料結構,也就找到了對應的page數組,之後的方法就類似flat memory了。
3、什麼是Sparse Memory Model?
Memory model也是一個演進過程,剛開始的時候,使用flat memory去抽像一個連續的記憶體位址空間(mem_maps[]),出現NUMA之後,整個不連續的記憶體空間被分成若干個node,每個node上是連續的記憶體位址空間,也就是說,原來的單一的一個mem_maps[]變成了若干個mem_maps[]了。一切看起來已經完美了,但是memory hotplug的出現讓原來完美的設計變得不完美了,因為即便是一個node中的mem_maps[]也有可能是不連續了。其實,在出現了sparse memory之後,Discontiguous memory記憶體模型已經不是那麼重要了,按理說sparse memory最終可以替代Discontiguous memory的,這個替代過程正在進行中,4.4的核心仍然是有3中記憶體模型可以選擇。
為什麼說sparse memory最後可以取代Discontiguous memory呢?實際上在sparse memory記憶體模型下,連續的位址空間按照SECTION(例如1G)被分成了一段的,其中每一section都是hotplug的,因此sparse memory下,記憶體位址空間可以被切分的更細,支援更離散的Discontiguous memory。此外,在sparse memory沒有出現之前,NUMA和Discontiguous memory總是剪不斷,理還亂的關係:NUMA並沒有規定其內存的連續性,而Discontiguous memory系統也並非一定是NUMA系統,但是這兩種配置都是multi node的。有了sparse memory之後,我們終於可以把記憶體的連續性和NUMA的概念剝離開來:一個NUMA系統可以是flat memory,也可以是sparse memory,而一個sparse memory系統可以是NUMA,也可以是UMA的。
下面的圖片說明了sparse memory是如何管理page frame的(配置了SPARSEMEM_EXTREME):
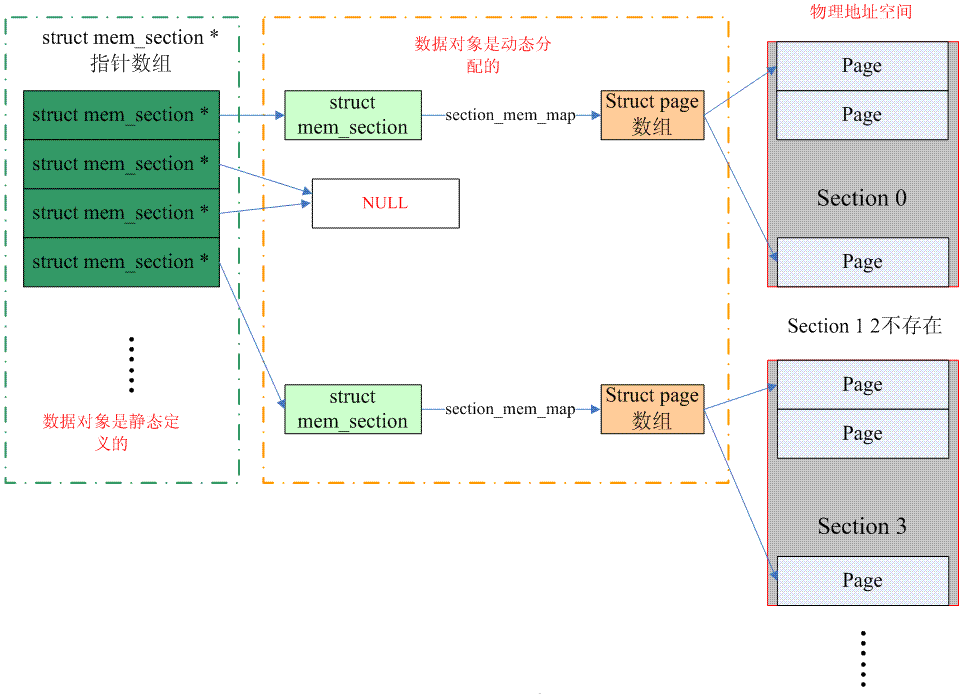
(注意:上圖中的一個mem_section指標應該指向一個page,而一個page有若干個struct mem_section資料單元)
整個連續的物理位址空間是依照一個section一個section來切斷的,每一個section內部,其memory是連續的(即符合flat memory的特徵),因此,mem_map的page數組依附在section結構(struct mem_section)而不是node結構了(struct pglist_data)。當然,無論哪一種memory model,都需要處理PFN和page之間的對應關係,只不過sparse memory多了一個section的概念,讓轉換變成了PFNSectionpage。
我們先來看看如何從PFN到page結構的轉換:kernel中靜態定義了一個mem_section的指標數組,一個section往往包含多個page,因此需要透過右移將PFN轉換成section number,用section number做為index在mem_section指標陣列可以找到該PFN對應的section資料結構。找到section之後,沿著其section_mem_map就可以找到對應的page資料結構。順便一提的是,在開始的時候,sparse memory使用了一維的memory_section數組(不是指針數組),這樣的實現對於特別稀疏(CONFIG_SPARSEMEM_EXTREME)的系統非常浪費內存。此外,保存指針對hotplug的支援是比較方便的,指標等於NULL就表示該section不存在。上面的圖片描述的是一維mem_section指標數組的情況(配置了SPARSEMEM_EXTREME),對於非SPARSEMEM_EXTREME配置,概念是類似的,具體操作大家可以自行閱讀程式碼。
從page到PFN稍微有點麻煩,實際上PFN分成兩個部分:一部分是section index,另外一個部分是page在該section的偏移。我們需要先從page得到section index,也得到對應的memory_section,知道了memory_section也就知道該page在section_mem_map,也就知道了page在該section的偏移,最後可以合成PFN。 page到section index的轉換,sparse memory有2種方案,我們先來看看經典的方案,也就是儲存在page->flags中(配置了SECTION_IN_PAGE_FLAGS)。這種方法的最大的問題是page->flags中的bit數目不一定夠用,因為這個flag中承載了太多的信息,各種page flag,node id,zone id現在又增加一個section id,在不同的architecture中無法實現一致性的演算法,有沒有一種通用的演算法呢?這就是CONFIG_SPARSEMEM_VMEMMAP。具體的演算法可以參考下圖:
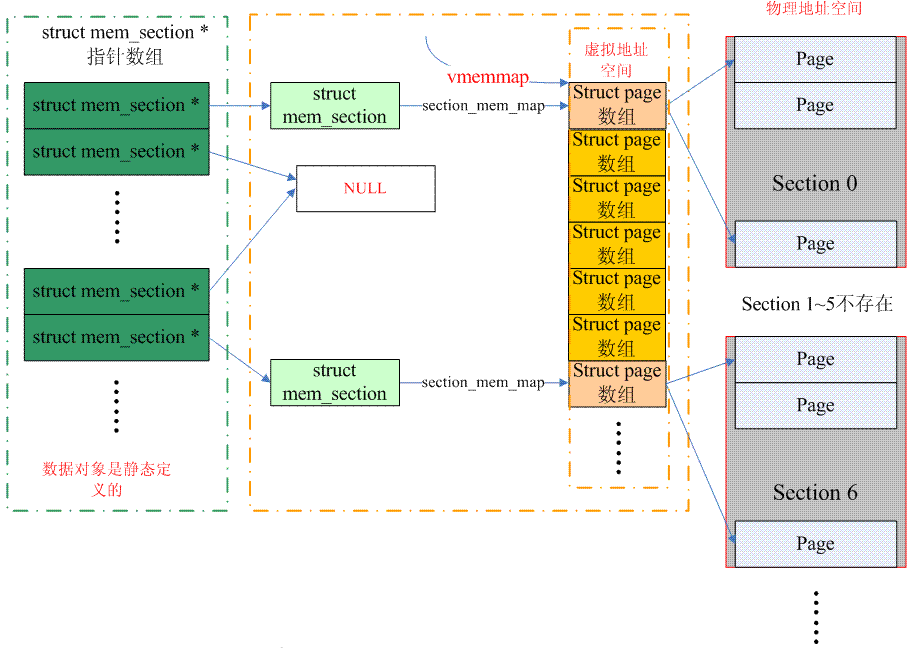
(上面的圖片有一點問題,vmemmap只有在PHYS_OFFSET等於0的情況下才指向第一個struct page數組,一般而言,應該有一個offset的,不過,懶得改了,哈哈)
對於經典的sparse memory模型,一個section的struct page陣列所佔用的記憶體來自directly mapped區域,頁表在初始化的時候就建立好了,分配了page frame也就是分配了虛擬位址。但是,對於SPARSEMEM_VMEMMAP而言,虛擬位址一開始就分配好了,是vmemmap開始的一段連續的虛擬位址空間,每個page都有一個對應的struct page,當然,只有虛擬位址,沒有實體位址。因此,當一個section被發現後,可以立刻找到對應的struct page的虛擬位址,當然,還需要分配一個物理的page frame,然後建立頁表什麼的,因此,對於這種sparse memory,開銷會稍微大一些(多了個建立映射的過程)。
四、程式碼分析
我們的程式碼分析主要是透過include/asm-generic/memory_model.h展開的。
1、flat memory。程式碼如下:
「
#\#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET)) \#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)登入後複製」
#由程式碼可知,PFN和struct page陣列(mem_map)index是線性關係,有一個固定的偏移就是ARCH_PFN_OFFSET,這個偏移是和估計的architecture有關。對於ARM64,定義在arch/arm/include/asm/memory.h檔案中,當然,這個定義是和記憶體所佔據的物理位址空間有關(也就是和PHYS_OFFSET的定義有關)。
2、Discontiguous Memory Model。程式碼如下:
“
\#define __pfn_to_page(pfn) \ ({ unsigned long __pfn = (pfn); \ unsigned long __nid = arch_pfn_to_nid(__pfn); \ NODE_DATA(__nid)->node_mem_map + arch_local_page_offset(__pfn, __nid);\ }) \#define __page_to_pfn(pg) \ ({ const struct page *__pg = (pg); \ struct pglist_data *__pgdat = NODE_DATA(page_to_nid(__pg)); \ (unsigned long)(__pg - __pgdat->node_mem_map) + \ __pgdat->node_start_pfn; \ })登入後複製”
Discontiguous Memory Model需要获取node id,只要找到node id,一切都好办了,比对flat memory model进行就OK了。因此对于__pfn_to_page的定义,可以首先通过arch_pfn_to_nid将PFN转换成node id,通过NODE_DATA宏定义可以找到该node对应的pglist_data数据结构,该数据结构的node_start_pfn记录了该node的第一个page frame number,因此,也就可以得到其对应struct page在node_mem_map的偏移。__page_to_pfn类似,大家可以自己分析。
3、Sparse Memory Model。经典算法的代码我们就不看了,一起看看配置了SPARSEMEM_VMEMMAP的代码,如下:
“
\#define __pfn_to_page(pfn) (vmemmap + (pfn)) \#define __page_to_pfn(page) (unsigned long)((page) - vmemmap)登入後複製”
简单而清晰,PFN就是vmemmap这个struct page数组的index啊。对于ARM64而言,vmemmap定义如下:
“
\#define vmemmap ((struct page *)VMEMMAP_START - \ SECTION_ALIGN_DOWN(memstart_addr >> PAGE_SHIFT))登入後複製”
毫无疑问,我们需要在虚拟地址空间中分配一段地址来安放struct page数组(该数组包含了所有物理内存跨度空间page),也就是VMEMMAP_START的定义。
总之,Linux内存模型是一个非常重要的概念,可以帮助你更好地理解Linux系统中的内存管理。如果你想了解更多关于这个概念的信息,可以查看本文提供的参考资料。
以上是Linux記憶體模型:深入理解記憶體管理的詳細內容。更多資訊請關注PHP中文網其他相關文章!

熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

Video Face Swap
使用我們完全免費的人工智慧換臉工具,輕鬆在任何影片中換臉!

熱門文章
熱工具

記事本++7.3.1
好用且免費的程式碼編輯器

SublimeText3漢化版
中文版,非常好用

禪工作室 13.0.1
強大的PHP整合開發環境

Dreamweaver CS6
視覺化網頁開發工具

SublimeText3 Mac版
神級程式碼編輯軟體(SublimeText3)



 vscode需要什麼電腦配置
Apr 15, 2025 pm 09:48 PM
vscode需要什麼電腦配置
Apr 15, 2025 pm 09:48 PM
VS Code 系統要求:操作系統:Windows 10 及以上、macOS 10.12 及以上、Linux 發行版處理器:最低 1.6 GHz,推薦 2.0 GHz 及以上內存:最低 512 MB,推薦 4 GB 及以上存儲空間:最低 250 MB,推薦 1 GB 及以上其他要求:穩定網絡連接,Xorg/Wayland(Linux)
 Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux體系結構:揭示5個基本組件
Apr 20, 2025 am 12:04 AM
Linux系統的五個基本組件是:1.內核,2.系統庫,3.系統實用程序,4.圖形用戶界面,5.應用程序。內核管理硬件資源,系統庫提供預編譯函數,系統實用程序用於系統管理,GUI提供可視化交互,應用程序利用這些組件實現功能。
 vscode終端使用教程
Apr 15, 2025 pm 10:09 PM
vscode終端使用教程
Apr 15, 2025 pm 10:09 PM
vscode 內置終端是一個開發工具,允許在編輯器內運行命令和腳本,以簡化開發流程。如何使用 vscode 終端:通過快捷鍵 (Ctrl/Cmd ) 打開終端。輸入命令或運行腳本。使用熱鍵 (如 Ctrl L 清除終端)。更改工作目錄 (如 cd 命令)。高級功能包括調試模式、代碼片段自動補全和交互式命令歷史。
 git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
git怎麼查看倉庫地址
Apr 17, 2025 pm 01:54 PM
要查看 Git 倉庫地址,請執行以下步驟:1. 打開命令行並導航到倉庫目錄;2. 運行 "git remote -v" 命令;3. 查看輸出中的倉庫名稱及其相應的地址。
 notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
notepad怎麼運行java代碼
Apr 16, 2025 pm 07:39 PM
雖然 Notepad 無法直接運行 Java 代碼,但可以通過借助其他工具實現:使用命令行編譯器 (javac) 編譯代碼,生成字節碼文件 (filename.class)。使用 Java 解釋器 (java) 解釋字節碼,執行代碼並輸出結果。
 vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
vscode在哪寫代碼
Apr 15, 2025 pm 09:54 PM
在 Visual Studio Code(VSCode)中編寫代碼簡單易行,只需安裝 VSCode、創建項目、選擇語言、創建文件、編寫代碼、保存並運行即可。 VSCode 的優點包括跨平台、免費開源、強大功能、擴展豐富,以及輕量快速。
 Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要目的是什麼?
Apr 16, 2025 am 12:19 AM
Linux的主要用途包括:1.服務器操作系統,2.嵌入式系統,3.桌面操作系統,4.開發和測試環境。 Linux在這些領域表現出色,提供了穩定性、安全性和高效的開發工具。
 vscode終端命令不能用
Apr 15, 2025 pm 10:03 PM
vscode終端命令不能用
Apr 15, 2025 pm 10:03 PM
VS Code 終端命令無法使用的原因及解決辦法:未安裝必要的工具(Windows:WSL;macOS:Xcode 命令行工具)路徑配置錯誤(添加可執行文件到 PATH 環境變量中)權限問題(以管理員身份運行 VS Code)防火牆或代理限制(檢查設置,解除限制)終端設置不正確(啟用使用外部終端)VS Code 安裝損壞(重新安裝或更新)終端配置不兼容(嘗試不同的終端類型或命令)特定環境變量缺失(設置必要的環境變量)
