
#系統記憶體是硬體系統中不可或缺的部分,定期查看系統記憶體資源的運作情況,可以幫助我們及時發現記憶體資源是否有異常佔用,確保業務穩定運作。
例如:定期查看公司網站伺服器的記憶體使用情況,可以確保伺服器資源是否充足,或者發現伺服器記憶體被異常佔用可以及時解決,避免因記憶體不足導致無法存取網站或存取速度慢的問題。
因此,對於 Linux 管理員來說,在日常工作中能夠熟練地在 Linux 系統下檢查記憶體運行狀況就變得非常重要!
查看記憶體運行狀態並不難,但是如何針對不同情況使用正確的方式查看呢?
一口君整理了幾個非常實用的 Linux 記憶體檢視方法:
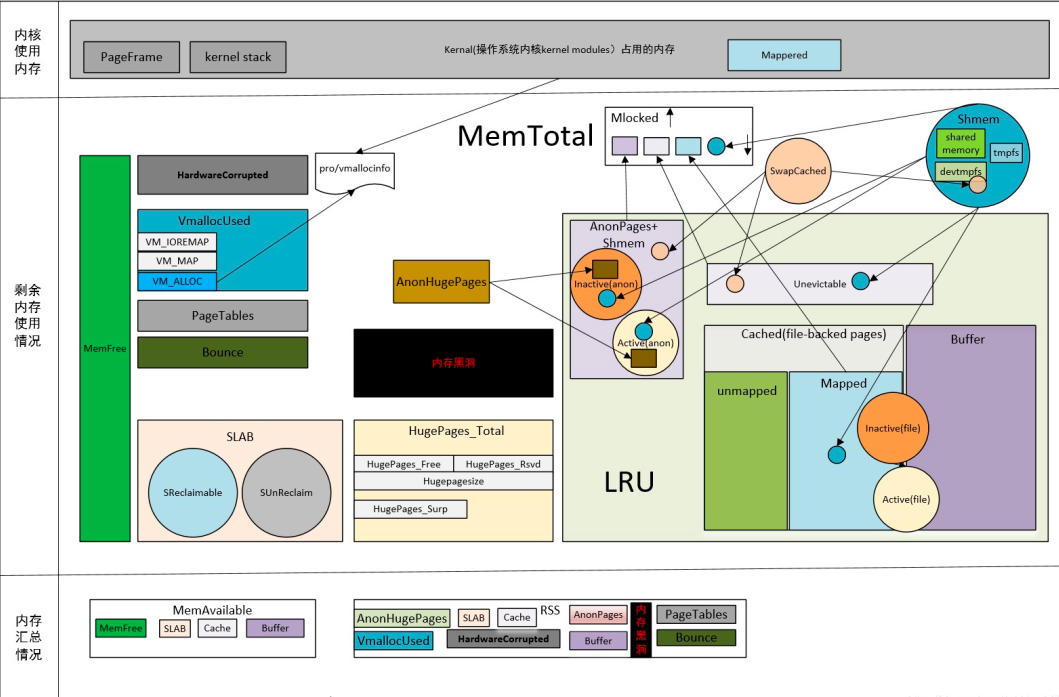
#該圖很好的描述了OS記憶體的使用和分配等詳細資訊。建議大家配合該圖一起學習和理解記憶體的一些概念。
#free 指令可以顯示目前系統未使用的和已使用的記憶體數目,也可以顯示被核心使用的記憶體緩衝區。
free [options]
free 指令選項:
-b # 以Byte为单位显示内存使用情况; -k # 以KB为单位显示内存使用情况; -m # 以MB为单位显示内存使用情况; -g # 以GB为单位显示内存使用情况。 -o # 不显示缓冲区调节列; -s # 持续观察内存使用状况; -t # 显示内存总和列; -V # 显示版本信息。
free -t # 以总和的形式显示内存的使用信息 free -h -s 10 # 周期性的查询内存使用信息,每10s 执行一次命令 free -h -c 10 #输出10次 在版本 v3.2.8,就是输出一次!需要配合 -s 使用。 在版本 v3.3.10,不加-s,就默认1秒输出一次。 free -V #查看版本号
v3.2.8

v3.3.10

#下面先解釋一下輸出的內容:
| 內容 | #意義 |
|---|---|
| Mem | 行(第二行)是記憶體的使用情況 |
| Swap | 行(第三行)是交換空間的使用情況 |
| total | 總可用物理記憶體。一般是總實體記憶體會除去一些預留的和作業系統本身的記憶體佔用,是作業系統可以支配的記憶體大小。這個在v3.2.8和v3.3.10一樣。這個值是/proc/meminfo中MemTotal的值。 |
| used | 列顯示已經被使用的實體記憶體和交換空間。在v3.2.8,這個值是(total – free)得出來的。可以說是系統已經被系統分配,但是實際上並不一定正在被真正的使用,其空間可以被回收再分配的。在v3.3.10,這個值是(total – free – cache – buffers)得出來的,是真正目前正在被使用的記憶體。 |
| free | 系統還未使用的實體記憶體。這個值是/proc/meminfo中MemFree的值 |
| shared | 共享記憶體的空間。這個值是/proc/meminfo中Shmem的值 |
| buff/cache | 列顯示被 buffer 和 cache 使用的物理記憶體大小 |
| available | ##v3.3.10中的項。看起來這個值是可以使用的內存,不過(available used) |
| -/ buffers/cache | ##v3.2.8有這一行,v3.3.10 沒有。其中,used 這一項是(used – buffers – cached)的值,即(total – free – buffers – cached)的值,是真正在使用的記憶體的值。 free 這一項是(free buffers cached)的值,是真正未使用的記憶體的值。個人覺得有 -/ buffers/cache,這一欄看的挺習慣。 。不過新版v3.3.10的used更明確。相信有不少人跟我一樣,剛剛看到v3.2.8裡面的used佔了這麼多內存的時候,有點摸不著頭腦。 |
vmstat命令是最常见的Linux/Unix监控工具,用于查看系统的内存存储信息,是一个报告虚拟内存统计信息的小工具,属于sysstat包。
vmstat 命令报告包括:进程、内存、分页、阻塞 IO、中断、磁盘、CPU。
可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
vmstat -s(参数)
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@local:~# vmstat 2 1 procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
这表示vmstat每2秒采集数据,按下ctrl + c结束程序,这里采集了3次数据我就结束了程序。
| 類別 | 專案 | 意義 | 說明 |
|---|---|---|---|
| Procs****(行程) | #r | 等待執行的任務數 | #展示了正在執行和等待cpu資源的任務個數。當這個值超過了cpu個數,就會出現cpu瓶頸。 |
| B | 等待IO的进程数量 | ||
| Memory(内存) | swpd | 正在使用虚拟的内存大小,单位k | |
| free | 空闲内存大小 | ||
| buff | 已用的buff大小,对块设备的读写进行缓冲 | ||
| cache | 已用的cache大小,文件系统的cache | ||
| inact | 非活跃内存大小,即被标明可回收的内存,区别于free和active | 具体含义见:概念补充(当使用-a选项时显示) | |
| active | 活跃的内存大小 | 具体含义见:概念补充(当使用-a选项时显示) | |
| Swap | si | 每秒从交换区写入内存的大小(单位:kb/s) | |
| so | 每秒从内存写到交换区的大小 | ||
| IO | bi | 每秒读取的块数(读磁盘) | 块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes |
| bo | 每秒写入的块数(写磁盘) | 块设备每秒发送的块数量,单位是block | |
| system | in | 每秒中断数,包括时钟中断 | 这两个值越大,会看到由内核消耗的cpu时间sy会越多 秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目 |
| cs | 每秒上下文切换数 | ||
| CPU****(以百分比表示) | us | 用户进程执行消耗cpu时间(user time) | us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
| sy | 系統程序消耗cpu時間(system time) | sys的值過高時,表示系統核心消耗的cpu資源多,這不是良性的表現,我們應該檢查原因。 這裡us sy的參考值為80%,若us sy 大於 80%說明可能有CPU不足 | |
| Id | 空閒時間(包括IO等待時間) | 一般來說 us sy id=100 | |
| wa | 等待IO時間 | wa過高時,表示io等待比較嚴重,這可能是由於磁碟大量隨機存取造成的,也有可能是磁碟的頻寬出現瓶頸。 |
常见问题及解决方法
当发生以上问题的时候请先调整应用程序对CPU的占用情况.使得应用程序能够更有效的使用CPU.同时可以考虑增加更多的CPU. 关于CPU的使用情况还可以结合mpstat, ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间.一般情况下,应用程序的问题会比较大一些.比如一些sql语句不合理等等都会造成这样的现象.
内存的瓶颈是由scan rate (sr)来决定的.scan rate是通过每秒的始终算法来进行页扫描的.如果scan rate(sr)连续的大于每秒200页则表示可能存在内存缺陷.同样的如果page项中的pi和po这两栏表示每秒页面的调入的页数和每秒调出的页数.如果该值经常为非零值,也有可能存在内存的瓶颈,当然,如果个别的时候不为0的话,属于正常的页面调度这个是虚拟内存的主要原理.
解决办法:
关于内存的使用情况还可以结ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的内存的使用情况,和那些进程在占用大量的内存.
一般情况下,如果内存的占用率比较高,但是,CPU的占用很低的时候,可以考虑是有很多的应用程序占用了内存没有释放,但是,并没有占用CPU时间,可以考虑应用程序,对于未占用CPU时间和一些后台的程序,释放内存的占用。
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。
这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。
top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
IO/CPU/men连锁反应
1.free急剧下降 2.buff和cache被回收下降,但也无济于事 3.依旧需要使用大量swap交换分区swpd 4.等待进程数,b增多 5.读写IO,bi bo增多 6.si so大于0开始从硬盘中读取 7.cpu等待时间用于 IO等待,wa增加
内存不足
1.开始使用swpd,swpd不为0 2.si so大于0开始从硬盘中读取
io瓶颈
1.读写IO,bi bo增多超过2000 2.cpu等待时间用于 IO等待,wa增加 超过20 3.sy 系统调用时间长,IO操作频繁会导致增加 >30% 4.wa io等待时间长 iowait% 50% 5.进一步使用iostat观察
CPU瓶颈:load,vmstat中r列
1.反应为CPU队列长度 2.一段时间内,CPU正在处理和等待CPU处理的进程数之和,直接反应了CPU的使用和申请情况。 3.理想的load average:核数*CPU数*0.7 CPU个数:grep 'physical id' /proc/cpuinfo | sort -u 核数:grep 'core id' /proc/cpuinfo | sort -u | wc -l 4.超过这个值就说明已经是CPU瓶颈了
用途:用于从/proc文件系统中提取与内存相关的信息。这些文件包含有 系统和内核的内部信息。其实 free 命令中的信息都来自于 /proc/meminfo 文件。/proc/meminfo 文件包含了更多更原始的信息,只是看起来不太直观。
cat /proc/meminfo
peng@ubuntu:~$ cat /proc/meminfo MemTotal: 2017504 kB //所有可用的内存大小, 物理内存减去预留位和内核使用。系统从加电开始到引导完成,firmware/BIOS要预留一 些内存,内核本身要占用一些内存,最后剩下可供内核支配的内存就是MemTotal。这个值 在系统运行期间一般是固定不变的,重启会改变。 MemFree: 511052 kB //表示系统尚未使用的内存。 MemAvailable: 640336 kB //真正的系统可用内存, 系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab都有一部分可 以回收,所以这部分可回收的内存加上MemFree才是系统可用的内存 Buffers: 114348 kB //用来给块设备做缓存的内存,(文件系统的 metadata、pages) Cached: 162264 kB //分配给文件缓冲区的内存,例如vi一个文件,就会将未保存的内容写到该缓冲区 SwapCached: 3032 kB //被高速缓冲存储用的交换空间(硬盘的swap)的大小 Active: 555484 kB //经常使用的高速缓冲存储器页面文件大小 Inactive: 295984 kB //不经常使用的高速缓冲存储器文件大小 Active(anon): 381020 kB //活跃的匿名内存 Inactive(anon): 244068 kB //不活跃的匿名内存 Active(file): 174464 kB //活跃的文件使用内存 Inactive(file): 51916 kB //不活跃的文件使用内存 Unevictable: 48 kB //不能被释放的内存页 Mlocked: 48 kB //系统调用 mlock SwapTotal: 998396 kB //交换空间总内存 SwapFree: 843916 kB //交换空间空闲内存 Dirty: 128 kB //等待被写回到磁盘的 Writeback: 0 kB //正在被写回的 AnonPages: 572776 kB //未映射页的内存/映射到用户空间的非文件页表大小 Mapped: 119816 kB //映射文件内存 Shmem: 50212 kB //已经被分配的共享内存 Slab: 113700 kB //内核数据结构缓存 SReclaimable: 68652 kB //可收回slab内存 SUnreclaim: 45048 kB //不可收回slab内存 KernelStack: 8812 kB //内核消耗的内存 PageTables: 27428 kB //管理内存分页的索引表的大小 NFS_Unstable: 0 kB //不稳定页表的大小 Bounce: 0 kB //在低端内存中分配一个临时buffer作为跳转,把位 于高端内存的缓存数据复制到此处消耗的内存 WritebackTmp: 0 kB //FUSE用于临时写回缓冲区的内存 CommitLimit: 2007148 kB //系统实际可分配内存 Committed_AS: 3567280 kB //系统当前已分配的内存 VmallocTotal: 34359738367 kB //预留的虚拟内存总量 VmallocUsed: 0 kB //已经被使用的虚拟内存 VmallocChunk: 0 kB //可分配的最大的逻辑连续的虚拟内存 HardwareCorrupted: 0 kB //表示“中毒页面”中的内存量 即has failed的内存(通常由ECC标记). ECC代表“纠错码”. ECC memory能够纠正小错误并检测较大错误; 在具有非ECC内存的典型PC上,内存错误未被检测到.如果使用ECC检测到无法纠正的错误(在内存或缓存中, 具体取决于系统的硬件支持),则Linux内核会将相应的页面标记为中毒. AnonHugePages: 0 kB //匿名大页 【/proc/meminfo的AnonHugePages==所有进程的/proc//smaps中AnonHugePages之和】 ShmemHugePages: 0 kB //用于共享内存的大页 ShmemPmdMapped: 0 kB CmaTotal: 0 kB //连续内存区管理总量 CmaFree: 0 kB //连续内存区管理空闲量 HugePages_Total: 0 //预留HugePages的总个数 HugePages_Free: 0 //池中尚未分配的 HugePages 数量, 真正空闲的页数等于HugePages_Free - HugePages_Rsvd HugePages_Rsvd: 0 //表示池中已经被应用程序分配但尚未使用的 HugePages 数量 HugePages_Surp: 0 //这个值得意思是当开始配置了20个大页,现在修改配置为16,那么这个参数就会显示为4,一般不修改配置,这个值都是0 Hugepagesize: 2048 kB //大内存页的size //指直接映射(direct mapping)的内存大小,从代码上来看,值记录管理页表占用的内存,就是描述线性映射空间中,有多个空间分别使用了2M/4K/1G页映射 DirectMap4k: 96128 kB DirectMap2M: 2000896 kB DirectMap1G: 0 kB
“
- 注意这个文件显示的单位是kB而不是KB,1kB=1000B,但是实际上应该是KB,1KB=1024B
- 还可以使用命令 less /proc/meminfo 直接读取该文件。通过使用 less 命令,可以在长长的输出中向上和向下滚动,找到你需要的内容。
”
从中我们可以很清晰明了的看出内存中的各种指标情况,例如 MemFree的空闲内存和SwapFree中的交换内存。
负责输出/proc/meminfo的源代码是:
fs/proc/meminfo.c : meminfo_proc_show()
static int meminfo_proc_show(struct seq_file *m, void *v)
{
struct sysinfo i;
unsigned long committed;
long cached;
long available;
unsigned long pages[NR_LRU_LISTS];
int lru;
si_meminfo(&i);
si_swapinfo(&i);
committed = percpu_counter_read_positive(&vm_committed_as);
cached = global_node_page_state(NR_FILE_PAGES) -
total_swapcache_pages() - i.bufferram;
if (cached for (lru = LRU_BASE; lru "MemTotal: ", i.totalram);
show_val_kb(m, "MemFree: ", i.freeram);
show_val_kb(m, "MemAvailable: ", available);
show_val_kb(m, "Buffers: ", i.bufferram);
show_val_kb(m, "Cached: ", cached);
show_val_kb(m, "SwapCached: ", total_swapcache_pages());
show_val_kb(m, "Active: ", pages[LRU_ACTIVE_ANON] +
pages[LRU_ACTIVE_FILE]);
show_val_kb(m, "Inactive: ", pages[LRU_INACTIVE_ANON] +
pages[LRU_INACTIVE_FILE]);
show_val_kb(m, "Active(anon): ", pages[LRU_ACTIVE_ANON]);
show_val_kb(m, "Inactive(anon): ", pages[LRU_INACTIVE_ANON]);
show_val_kb(m, "Active(file): ", pages[LRU_ACTIVE_FILE]);
show_val_kb(m, "Inactive(file): ", pages[LRU_INACTIVE_FILE]);
show_val_kb(m, "Unevictable: ", pages[LRU_UNEVICTABLE]);
show_val_kb(m, "Mlocked: ", global_zone_page_state(NR_MLOCK));
#ifdef CONFIG_HIGHMEM
show_val_kb(m, "HighTotal: ", i.totalhigh);
show_val_kb(m, "HighFree: ", i.freehigh);
show_val_kb(m, "LowTotal: ", i.totalram - i.totalhigh);
show_val_kb(m, "LowFree: ", i.freeram - i.freehigh);
#endif
#ifndef CONFIG_MMU
show_val_kb(m, "MmapCopy: ",
(unsigned long)atomic_long_read(&mmap_pages_allocated));
#endif
show_val_kb(m, "SwapTotal: ", i.totalswap);
show_val_kb(m, "SwapFree: ", i.freeswap);
show_val_kb(m, "Dirty: ",
global_node_page_state(NR_FILE_DIRTY));
show_val_kb(m, "Writeback: ",
global_node_page_state(NR_WRITEBACK));
show_val_kb(m, "AnonPages: ",
global_node_page_state(NR_ANON_MAPPED));
show_val_kb(m, "Mapped: ",
global_node_page_state(NR_FILE_MAPPED));
show_val_kb(m, "Shmem: ", i.sharedram);
show_val_kb(m, "Slab: ",
global_node_page_state(NR_SLAB_RECLAIMABLE) +
global_node_page_state(NR_SLAB_UNRECLAIMABLE));
show_val_kb(m, "SReclaimable: ",
global_node_page_state(NR_SLAB_RECLAIMABLE));
show_val_kb(m, "SUnreclaim: ",
global_node_page_state(NR_SLAB_UNRECLAIMABLE));
seq_printf(m, "KernelStack: %8lu kB\n",
global_zone_page_state(NR_KERNEL_STACK_KB));
show_val_kb(m, "PageTables: ",
global_zone_page_state(NR_PAGETABLE));
#ifdef CONFIG_QUICKLIST
show_val_kb(m, "Quicklists: ", quicklist_total_size());
#endif
show_val_kb(m, "NFS_Unstable: ",
global_node_page_state(NR_UNSTABLE_NFS));
show_val_kb(m, "Bounce: ",
global_zone_page_state(NR_BOUNCE));
show_val_kb(m, "WritebackTmp: ",
global_node_page_state(NR_WRITEBACK_TEMP));
show_val_kb(m, "CommitLimit: ", vm_commit_limit());
show_val_kb(m, "Committed_AS: ", committed);
seq_printf(m, "VmallocTotal: %8lu kB\n",
(unsigned long)VMALLOC_TOTAL >> 10);
show_val_kb(m, "VmallocUsed: ", 0ul);
show_val_kb(m, "VmallocChunk: ", 0ul);
#ifdef CONFIG_MEMORY_FAILURE
seq_printf(m, "HardwareCorrupted: %5lu kB\n",
atomic_long_read(&num_poisoned_pages) #endif
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
show_val_kb(m, "AnonHugePages: ",
global_node_page_state(NR_ANON_THPS) * HPAGE_PMD_NR);
show_val_kb(m, "ShmemHugePages: ",
global_node_page_state(NR_SHMEM_THPS) * HPAGE_PMD_NR);
show_val_kb(m, "ShmemPmdMapped: ",
global_node_page_state(NR_SHMEM_PMDMAPPED) * HPAGE_PMD_NR);
#endif
#ifdef CONFIG_CMA
show_val_kb(m, "CmaTotal: ", totalcma_pages);
show_val_kb(m, "CmaFree: ",
global_zone_page_state(NR_FREE_CMA_PAGES));
#endif
hugetlb_report_meminfo(m);
arch_report_meminfo(m);
return 0;
}
用途:用于打印系统中的CPU和内存使用情况。输出结果中,可以很清晰的看出已用和可用内存的资源情况。top 最好的地方之一就是发现可能已经失控的服务的进程 ID 号(PID)。有了这些 PID,你可以对有问题的任务进行故障排除(或 kill)。
top [-] [d delay] [q] [c] [S] [s] [i] [n] [b]
d : 改变显示的更新速度,或是在交谈式指令列( interactive command)按 s q : 没有任何延迟的显示速度,如果使用者是有 superuser 的权限,则 top 将会以最高的优先序执行 c : 切换显示模式,共有两种模式,一是只显示执行档的名称,另一种是显示完整的路径与名称 S : 累积模式,会将己完成或消失的子进程 ( dead child process ) 的 CPU time 累积起来 s : 安全模式,将交谈式指令取消, 避免潜在的危机 i : 不显示任何闲置 (idle) 或无用 (zombie) 的进程 n : 更新的次数,完成后将会退出 top b : 批次档模式,搭配 "n" 参数一起使用,可以用来将 top 的结果输出到档案内
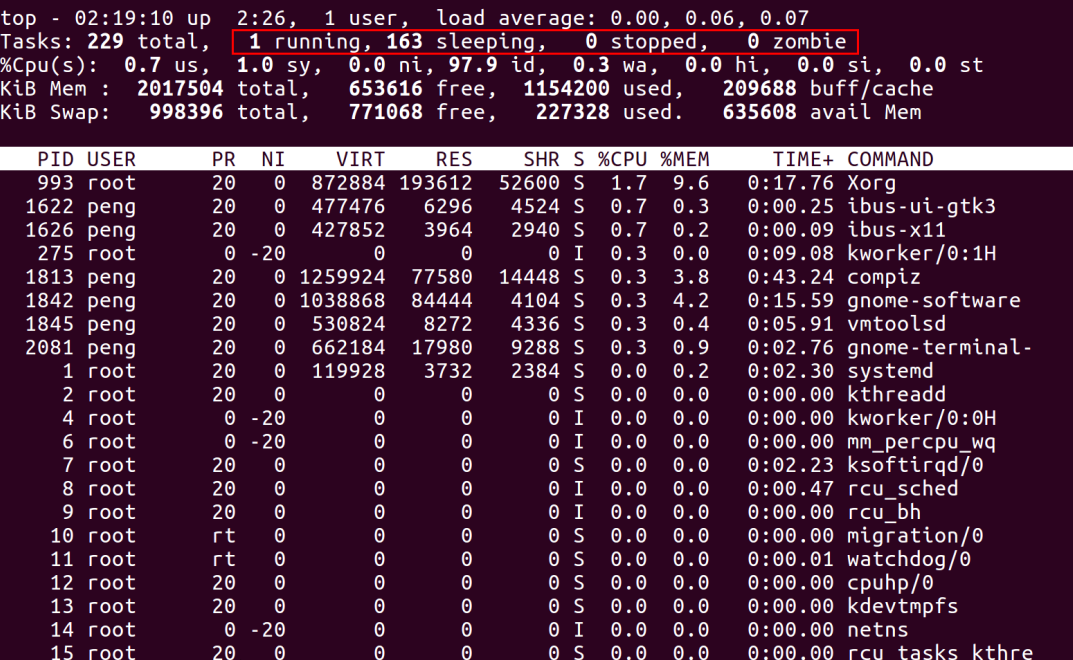
第一行,任务队列信息,同 uptime 命令的执行结果
“
系统时间:02:19:10 运行时间:up 2:26 min, 当前登录用户:1 user 负载均衡(uptime) load average: 0.00, 0.06, 0.07 average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
”
第二行,Tasks — 任务(进程)
“
總進程:229 total, 運行:1 running, 休眠:163 sleeping, 停止: 0 stopped, 殭屍進程: 0 zombie
」
#第三行,cpu狀態資訊
「
#0.7%us【user space】— 使用者空間佔用CPU的百分比。 1.0%sy【sysctl】— 核心空間佔用CPU的百分比。 0.0%ni【】— 改變過優先權的程序佔用CPU的百分比97.9%id【idolt】— 空閒CPU百分比0.3%wa【wait】— IO等待佔用CPU的百分比0.0%hi【Hardware IRQ】— 硬中斷佔用CPU的百分比0.0%si【Software Interrupts】— 軟中斷佔用CPU的百分比
」
#第四行,記憶體狀態
「
#2017504 total, 653616 free, 1154200 used, 209688 buff/cache【快取的記憶體量】
」
#第五行,swap交換分割區資訊
「
#998396 total, 771068 free, 227328 used. 635608 avail Mem
」
#第七行以下:各行程(任務)的狀態監控
「
#PID — 進程id USER — 進程擁有者 PR — 進程優先權 NI — nice值。負值表示高優先權,正值表示低優先權 VIRT — 行程使用的虛擬記憶體總量,單位kb。 VIRT=SWAP RES RES — 進程使用的、未被換出的實體記憶體大小,單位kb。 RES=CODE DATA SHR — 共享記憶體大小,單位kb S —進程狀態。 D=不可中斷的睡眠狀態R=運行S=睡眠T=追蹤/停止Z=殭屍進程%CPU — 上次更新到現在的CPU時間佔用百分比%MEM — 進程使用的實體記憶體百分比TIME — 進程使用的CPU時間總計,單位1/100秒COMMAND — 程序名稱(命令名稱/命令列)
”
# top
# top -c
# top -b
# top -S
top -n 2
//表示更新两次后终止更新显示
# top -d 3
//表示更新周期为3秒
# top -p 139
//显示进程号为139的进程信息,CPU、内存占用率等
top -n 10
htop 它类似于 top 命令,但可以让你在垂直和水平方向上滚动,所以你可以看到系统上运行的所有进程,以及他们完整的命令行。
可以不用输入进程的 PID 就可以对此进程进行相关的操作 (killing, renicing)。
htop快照: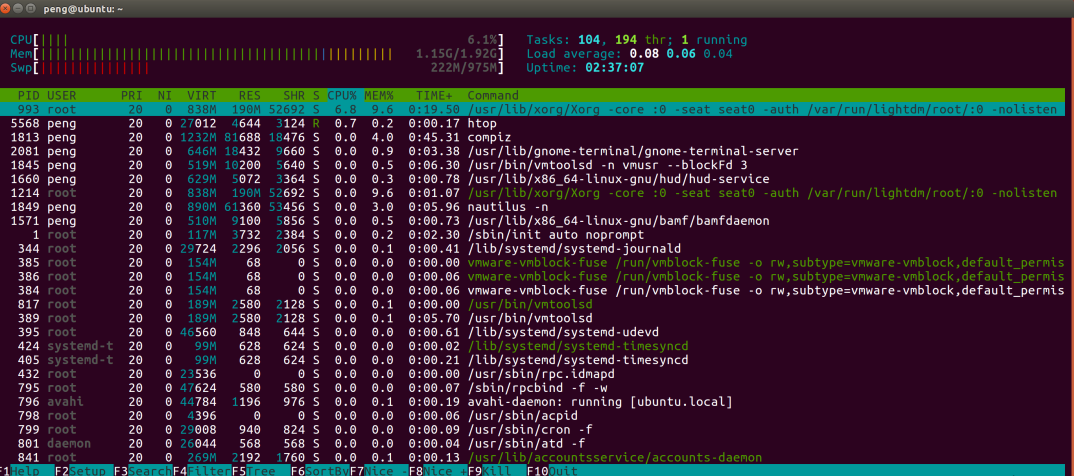
可以使用快捷键
F1,h,?:查看htop使用说明, F2,s :设置选项 F3,/ :搜索进程 F4,\ :过滤器,输入关键字搜索 F5,t :显示属性结构 F6,:选择排序方式 F7, [,:减少进程的优先级(nice) F8,] :增加进程的优先级(nice) F9,k :杀掉选中的进程 F10,q:退出htop u:显示所有用户,并可以选中某一特定用户的进程 U:取消标记所有的进程
第1行-第4行:显示CPU当前的运行负载,有几核就有几行,我的是1核
Mem:显示内存的使用情况,3887M大概是3.8G,此时的Mem不包含buffers和cached的内存,所以和free -m会不同Swp:显示交换空间的使用情况,交换空间是当内存不够和其中有一些长期不用的数据时,ubuntu会把这些暂时放到交换空间中
其他信息可以参考top命令说明。
“
PS:如果你终端没安装 htop,先通过指令来安装。sudo apt-get update sudo apt install htop
”
通过/proc/procid/status查看进程内存
peng@ubuntu:~$ cat /proc/4398/status Name: kworker/0:0 //进程名 Umask: 0000 State: I (idle) //进程的状态 //R (running)", "S (sleeping)", "D (disk sleep)", "T (stopped)", "T(tracing stop)", "Z (zombie)", or "X (dead)" Tgid: 4398 //线程组的ID,一个线程一定属于一个线程组(进程组). Ngid: 0 Pid: 4398 //进程的ID,更准确的说应该是线程的ID. PPid: 2 //当前进程的父进程 TracerPid: 0 //跟踪当前进程的进程ID,如果是0,表示没有跟踪 Uid: 0 0 0 0 Gid: 0 0 0 0 FDSize: 64 //当前分配的文件描述符,该值不是上限,如果打开文件超过64个文件描述符,将以64进行递增 Groups: //启动这个进程的用户所在的组 NStgid: 4398 NSpid: 4398 NSpgid: 0 NSsid: 0 Threads: 1 SigQ: 0/7640 SigPnd: 0000000000000000 ShdPnd: 0000000000000000 SigBlk: 0000000000000000 SigIgn: ffffffffffffffff SigCgt: 0000000000000000 CapInh: 0000000000000000 CapPrm: 0000003fffffffff CapEff: 0000003fffffffff CapBnd: 0000003fffffffff CapAmb: 0000000000000000 NoNewPrivs: 0 Seccomp: 0 Speculation_Store_Bypass: vulnerable Cpus_allowed: 00000000,00000000,00000000,00000001 Cpus_allowed_list: 0 Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001 Mems_allowed_list: 0 voluntary_ctxt_switches: 5 nonvoluntary_ctxt_switches: 0
确定内存使用情况是Linux运维工程师必要的技能,尤其是某个应用程序变得异常和占用系统内存时。当发生这种情况时,知道有多种工具可以帮助你进行故障排除十分方便的。
以上是Linux記憶體佔用分析的幾個方法,你知道幾個?的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















